Nachrichtenreplikation und regionsübergreifender Verbund
Innerhalb von Namespaces unterstützt Azure Service Bus das Erstellen von Topologien von verketteten Warteschlangen und Themenabonnements mithilfe automatischer Weiterleitung, um die Implementierung verschiedener Routingmuster zu ermöglichen. Beispielsweise können Sie dedizierte Warteschlangen für Partner bereitstellen, für die sie über Sende- oder Empfangsberechtigungen verfügen. Diese können bei Bedarf vorübergehend angehalten und flexibel mit anderen Entitäten verbunden werden, die für die Anwendung privat sind. Sie können auch komplexe mehrstufige Routingtopologien erstellen, oder Sie können Warteschlangen im Postfachstil erstellen, die die warteschlangenähnlichen Abonnements von Themen ableiten und mehr Speicherkapazität pro Abonnent ermöglichen.
Viele anspruchsvolle Lösungen erfordern auch, dass Nachrichten über Namespacegrenzen hinweg repliziert werden, um diese und andere Muster zu implementieren. Nachrichten müssen möglicherweise zwischen Namespaces übertragen werden, die mehreren, unterschiedlichen Anwendungsmandanten oder mehreren verschiedenen Azure-Regionen zugeordnet sind.
Ihre Lösung verwaltet mehrere Service Bus-Namespaces in verschiedenen Regionen und repliziert Nachrichten zwischen Warteschlangen und Themen. Außerdem können Sie Nachrichten mit Quellen und Zielen wie Azure Event Hubs, Azure IoT Hub oder Apache Kafka austauschen.
Auf diesen Szenarien liegt der Schwerpunkt dieses Artikels.
Verbundmuster
Es gibt zahlreiche mögliche Gründe dafür, warum Sie Nachrichten zwischen Service Bus-Entitäten wie Warteschlangen oder Themen oder zwischen Service Bus und anderen Quellen und Zielen verschieben möchten.
Im Vergleich zu den ähnlichen Mustern für Event Hubs ist Verbund für warteschlangenähnliche Entitäten komplexer, da Nachrichtenwarteschlangen ihren Consumern den exklusiven Besitz jeder einzelnen Nachricht versprechen, von ihnen erwartet wird, dass sie die Ankunftsreihenfolge bei der Nachrichtenzustellung einhalten, und vom Broker erwartet wird, dass er die gerechte Verteilung von Nachrichten zwischen konkurrierenden Consumern koordiniert.
Es gibt praktische Hindernisse, einschließlich der Einschränkungen des CAP-Theorems, die es schwierig machen, eine einheitliche Ansicht einer Warteschlange bereitzustellen, die gleichzeitig in mehreren Regionen verfügbar ist und die es regional verteilten, konkurrierenden Consumern erlaubt, exklusiven Besitz von Nachrichten zu übernehmen. Eine solche geografisch verteilte Warteschlange würde eine vollständig konsistente Replikation nicht nur von Nachrichten erfordern, sondern auch den Übermittlungsstatus jeder Nachricht, bevor Nachrichten für Consumer verfügbar gemacht werden können. Ein Ziel der vollständigen Konsistenz einer hypothetischen, regional verteilten Warteschlange ist ein direkter Konflikt mit dem wichtigsten Ziel, das praktisch alle Azure Service Bus-Kunden haben, wenn Sie Verbundszenarien in Erwägung ziehen: Maximale Verfügbarkeit und Zuverlässigkeit für ihre Lösungen.
Die hier vorgestellten Muster konzentrieren sich daher auf die Verfügbarkeit und Zuverlässigkeit, während gleichzeitig die Vermeidung von Informationsverlusten und die doppelte Verarbeitung von Nachrichten vermieden werden soll.
Resilienz bei regionalen Verfügbarkeitsereignissen.
Während maximale Verfügbarkeit und Zuverlässigkeit die obersten Betriebsprioritäten für Service Bus sind, gibt es dennoch viele Möglichkeiten, bei denen ein Producer oder Consumer aufgrund von Netzwerk- oder Namensauflösungsproblemen daran gehindert werden könnte, mit dem ihm zugewiesenen „primären“ Service Bus zu kommunizieren, oder bei denen die Service Bus-Entität tatsächlich vorübergehend nicht antwortet oder Fehler zurückgibt. Der festgelegte Nachrichtenprozessor ist möglicherweise ebenfalls nicht verfügbar.
Solche Bedingungen sind nicht so „katastrophal“, dass Sie die regionale Bereitstellung ganz aufgeben würden, wie es vielleicht in einer Notfallwiederherstellungssituation der Fall wäre, aber das Geschäftsszenario einiger Anwendungen könnte bereits durch Verfügbarkeitsereignisse beeinträchtigt werden, die nicht länger als einige Minuten oder sogar Sekunden dauern. Azure Service Bus wird häufig in Hybrid Cloud-Umgebungen und mit Clients verwendet, die sich am Netzwerkedge befinden, beispielsweise in Einzelhandelsgeschäften, Restaurants, Bankfilialen, an Fertigungsstandorten, in Logistikeinrichtungen und auf Flughäfen. Es ist möglich, dass ein Netzwerkrouting- oder Überlastungsproblem die Fähigkeit eines Standorts beeinträchtigt, den ihm zugewiesenen Service Bus-Endpunkt zu erreichen, während ein sekundärer Endpunkt in einer anderen Region erreichbar sein könnte. Gleichzeitig können Systeme, die von diesen Standorten eingehende Nachrichten verarbeiten, weiterhin ungehinderten Zugriff auf den primären und den sekundären Service Bus-Endpunkt besitzen.
Es gibt viele praktische Beispiele für solche Hybrid Cloud- und Edge-Anwendungen mit einer geringen Geschäftstoleranz für die Auswirkung von Netzwerkroutingproblemen oder vorübergehenden Verfügbarkeitsproblemen einer Service Bus-Entität. Dazu gehören die Abwicklung von Zahlungen im Einzelhandel, das Boarding an den Gates von Flughäfen und Außer-Haus-Bestellungen in Restaurants über Smartphones, die immer dann sofort und vollständig zum Stillstand kommen, wenn kein zuverlässiger Kommunikationspfad verfügbar ist.
In dieser Kategorie werden drei verschiedene verteilte Muster behandelt: „Vollständig aktive“ Replikation, „Aktiv/Passiv“-Replikation und „Überlauf“replikation.
Vollständig aktive Replikation
Das Replikationsmuster „vollständig aktiv“ ermöglicht, dass ein aktives Replikat desselben logischen Themas (oder einer Warteschlange) in mehreren Namespaces (und Regionen) verfügbar ist und alle Nachrichten in allen Replikaten verfügbar werden, und zwar unabhängig davon, wo sie in die Warteschlange eingereiht wurden. Das Muster behält in der Regel die Reihenfolge der Nachrichten relativ zu einem beliebigen Herausgeber bei.
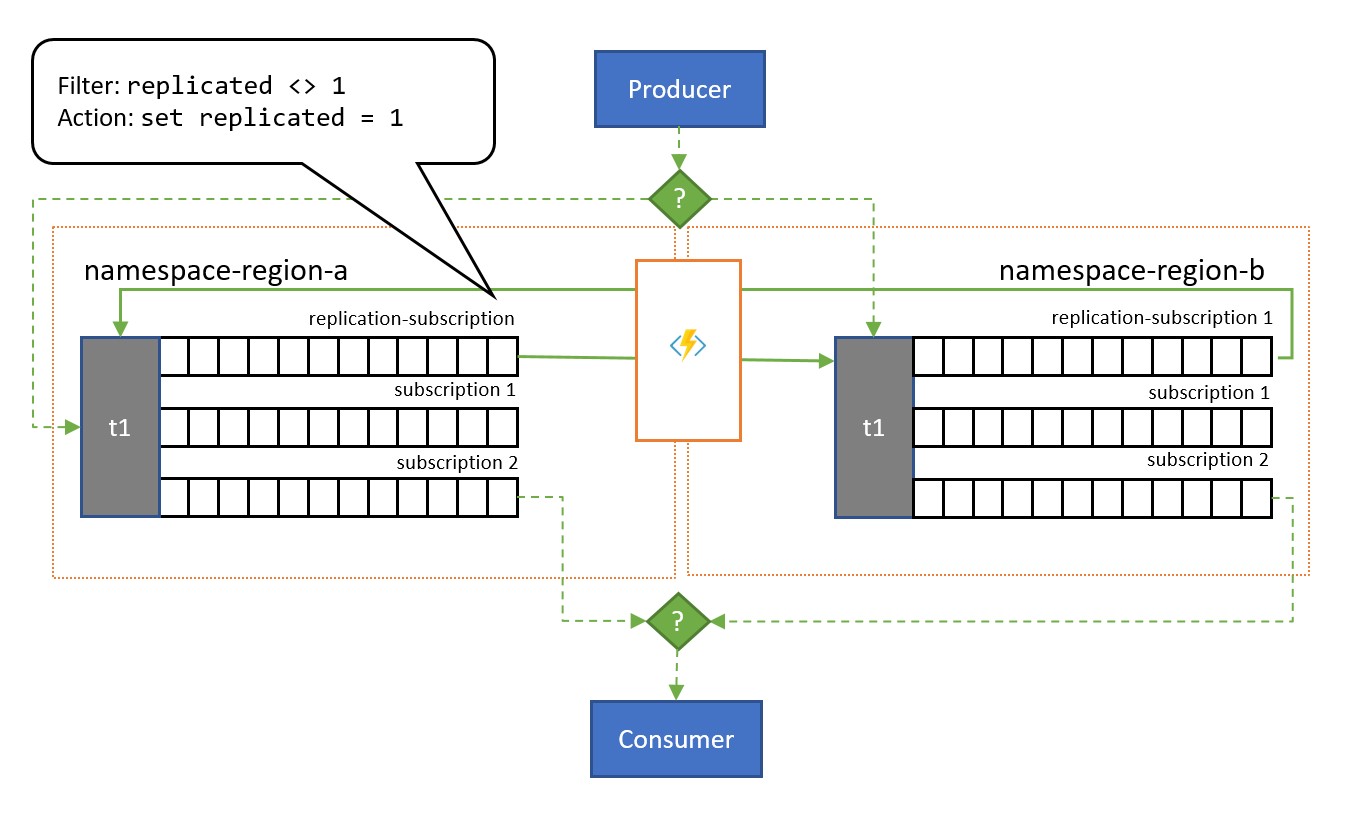
Wie in der Abbildung dargestellt, orientiert sich das Muster im Allgemeinen an Service Bus-Themen. Ein Thema für jeden Namespace, der am Replikationsschema teilnehmen soll. Jedes dieser Themen verfügt über ein „Replikationsabonnement“ für alle anderen Themen, in die Nachrichten repliziert werden sollen. In der Abbildung oben verwenden wir einfach zwei Themen und somit ein einzelnes Replikationsabonnement für das jeweils andere Thema. In einem Szenario mit drei Namespaces {n1, n2, n3} würde ein Thema in Namespace n1 über zwei Replikationsabonnements verfügen: eines für das entsprechende Thema in n2 und eines für das entsprechende Thema in n3.
Jedes Replikationsabonnement verfügt über eine Regel, die einen SQL-Filterausdruck (replicated <> 1) und eine SQL-Aktion (set replicated = 1) kombiniert. Der Filter der Regel stellt sicher, dass nur Nachrichten, bei denen die benutzerdefinierte Eigenschaft replication nicht festgelegt ist oder nicht den Wert 1 aufweist, für dieses Abonnement in Frage kommen, und die Aktion legt genau diese Eigenschaft für jede ausgewählte Nachricht gleich danach auf den Wert 1 fest. Der Effekt ist, dass die Nachricht nicht mehr für die Replikation in die entgegengesetzte Richtung in Frage kommt, wenn sie in das entsprechende Thema kopiert wird. So vermeiden wir, dass Nachrichten zwischen den Replikaten pendeln.
Ein Abonnement mit einer entsprechenden Regel kann mit der Azure CLI wie folgt einfach zu jedem Thema hinzugefügt werden.
az servicebus topic subscription rule create --resource-group myresourcegroup \
--namespace mynamespace --topic-name mytopic \
--subscription-name replication --name replication \
--action-sql-expression "set replication = 1" \
--filter-sql-expression "replication IS NULL"
Um eine Warteschlange zu modellieren, wird jedes Thema auf ein einziges reguläres Abonnement (abgesehen von den Replikationsabonnements) beschränkt, das sich alle Consumer teilen.
Das vollständig aktive Replikationsmodell legt von jeder Nachricht, die in eines der Themen gesendet wird, eine Kopie in jedem der Themen ab. Dies bedeutet, dass der Anwendungscode in jeder Region alle Nachrichten sehen und verarbeiten kann. Dieses Muster eignet sich für Szenarien, in denen Daten in mehreren Regionen freigegeben werden oder wenn im Allgemeinen redundante Verarbeitung gewünscht wird. Wenn Sie jede Nachricht nur ein Mal verarbeiten müssen (wie bei einer regulären Warteschlange), müssen Sie eines der beiden folgenden Muster in Erwägung ziehen.
Aktiv/Passiv-Replikation
Das „Aktiv/Passiv“-Replikationsmuster ist eine Variation des vorherigen Musters, bei der nur eines der Themen (das „primäre“ Thema) aktiv von der Anwendung zum Senden und Empfangen von Nachrichten verwendet wird und Nachrichten in ein sekundäres Thema repliziert werden, falls das primäre Thema nicht verfügbar wird oder nicht erreichbar ist.
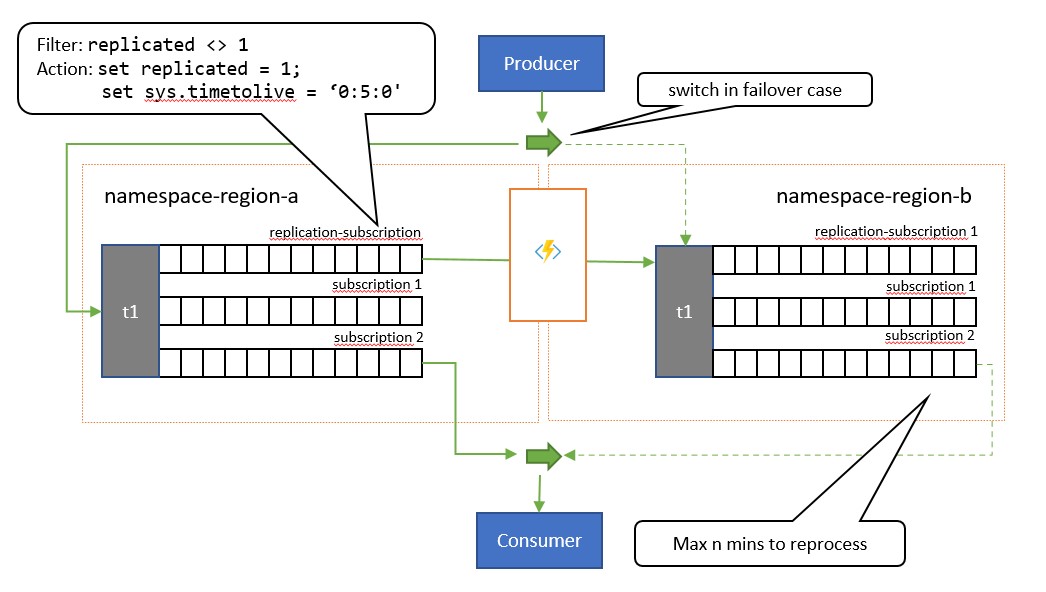
Der Hauptunterschied zwischen diesem Muster und dem vorherigen Muster besteht darin, dass die Replikation vom primären Thema zum sekundären Thema unidirektional ist. Das sekundäre Thema wird niemals zum primären Thema, sondern ist eine Sicherungsoption für den Fall, dass das primäre Thema vorübergehend unbrauchbar ist.
Der Vorteil bei der Verwendung dieses Musters besteht darin, dass versucht wird, doppelte Verarbeitung zu minimieren. Während der Replikation wird die Nachrichteneigenschaft TimeToLive auf eine Dauer für die replizierten Nachrichten festgelegt, die die erwartete Zeit angibt, während der ein Ausfall des primären Themas zu einem Failover führt. Wenn Ihr Anwendungsfallszenario z. B. ein Failover des Consumers auf das sekundäre Thema innerhalb von höchstens 1 Minute erfordert, wenn der Abruf von Nachrichten vom primären Thema Probleme aufweist, sollte das sekundäre Thema idealerweise über alle Nachrichten verfügen, auf die Sie im primären Thema nicht zugreifen konnten, aber nur über eine minimale Anzahl von Nachrichten, die Sie bereits vom primären Thema verarbeitet haben, bevor die Probleme aufgetreten sind. Wenn wir TimeToLive während der Replikation auf den doppelten Zeitraum (2 Minuten) festlegen (set sys.TimeToLive = '0:2:0' in der Regelaktion), behält das sekundäre Thema Nachrichten nur für 2 Minuten bei und verwirft ältere Nachrichten. Dies bedeutet: Wenn der Empfänger auf das sekundäre Thema umschaltet, kann er Nachrichten, die älter als die zuletzt verarbeitete Nachricht sind, schnell durchlesen und verwerfen und die Verarbeitung dann ab der ersten Nachricht durchführen, die er noch nicht gesehen hat. Die tatsächliche Beibehaltungsdauer hängt vom spezifischen Anwendungsfall und davon ab, wie schnell Sie zum sekundären Thema umschalten möchten und können. Die Einstellung TimeToLive wird im Bereich von einigen Sekunden bis hin zu Tagen berücksichtigt.
Obwohl die Anwendung das sekundäre Thema verwendet, kann sie die Veröffentlichung auch direkt im sekundären Thema vornehmen, das sich dann wie ein reguläres Thema verhält. Nach dem Wechsel zum sekundären Thema sieht der Consumer daher eine Mischung aus replizierten Nachrichten und Nachrichten, die direkt im sekundären Thema veröffentlicht werden. Die Anwendung sollte daher zunächst die Veröffentlichung zurück auf das primäre Thema umschalten und das Verarbeiten der lokal veröffentlichten Nachrichten dennoch zulassen, bevor sie den Consumer zurück auf das sekundäre Thema umschaltet. Da die Replikation automatisch fortgesetzt wird, sobald das primäre Thema wieder verfügbar ist, würde der Consumer während dieser Zeit auch neue Nachrichten im primären Thema veröffentlichen, auch wenn dafür eine etwas höhere Latenz gilt.
Dieses Muster eignet sich für Szenarien, in denen Nachrichten nur ein Mal verarbeitet werden sollen. Die Anwendung muss kooperieren, um Nachrichten nachzuverfolgen, die sie aus dem primären Thema verarbeitet hat, da sie für die Dauer des Failoverfensters im sekundären Thema Duplikate findet und beim Zurückwechseln ebenfalls Duplikate vorhanden sind. Das Deduplizierungskriterium sollte am besten eine von der Anwendung bereitgestellte
MessageIdsein. Der WertEnqueuedTimeUtcist auch als Wasserzeichenindikator geeignet, aber die Anwendung muss eine gewisse Taktabweichung (mehrere Sekunden) zwischen dem primären und dem sekundären Thema wie bei jedem verteilten System zulassen.
Überlaufreplikation
Das Replikationsmuster „Überlauf“ ermöglicht eine Aktiv/Aktiv-Verwendung mehrerer Service Bus-Entitäten in mehreren Regionen, um das Szenario abzudecken, in dem Service Bus fehlerfrei ist, aber der Consumer mit der Anzahl ausstehender Nachrichten überlastet wird oder einfach nicht verfügbar ist. Ein Grund dafür kann sein, dass eine Datenbank, die den Consumerprozess unterstützt, langsam oder nicht verfügbar ist. Dieses Muster funktioniert mit einfachen Warteschlangen und Themenabonnements.
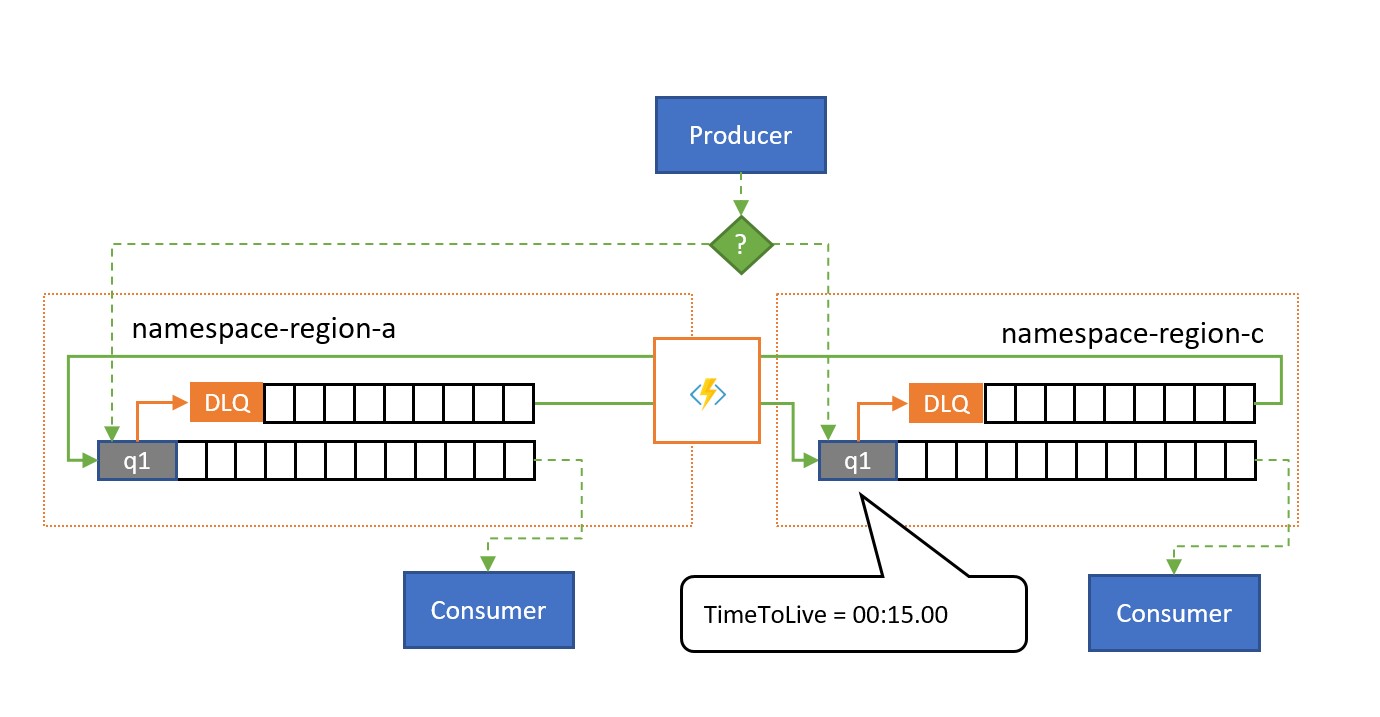
Wie in der Abbildung gezeigt, repliziert das Überlaufreplikationsmuster Nachrichten aus einer Warteschlange für unzustellbare Nachrichten, die einer Warteschlange oder einem Abonnement zugeordnet ist, in eine gekoppelte Warteschlange oder in ein Thema in einem anderen Namespace.
Ohne eine Fehlersituation werden die beiden Namespaces parallel verwendet und empfangen jeweils eine Teilmenge des gesamten Nachrichtenverkehrs, und der zugehörige Consumer verarbeitet diese Teilmenge. Sobald einer der Consumer mit der hohe Fehlerraten aufweist oder nicht mehr reagiert, werden die entsprechenden Nachrichten in der Warteschlange für unzustellbare Nachrichten gespeichert, und zwar entweder durch Überschreiten der Übermittlungsanzahl oder durch Ablauf. Die Replikationstasks übernehmen sie und reihen sie erneut in die gekoppelte Warteschlange ein, in der sie dann dem vermutlich fehlerfreien Consumer präsentiert werden.
Wenn die Verarbeitung innerhalb einer bestimmten Zeitspanne erfolgen muss, sollte TimeToLive für die Warteschlange und/oder Nachrichten so festgelegt werden, dass die Verarbeitung noch rechtzeitig durch das sekundäre Überlaufthema erfolgen kann, z. B. kann TimeToLive auf die Hälfte der zulässigen Zeit festgelegt werden.
Wie beim Muster „Vollständig aktiv“ kann die Anwendung der Nachricht einen Indikator hinzufügen, der angibt, ob die Nachricht bereits einmal repliziert wurde, sodass sie nicht zwischen den beiden Warteschlangen hin- und herpendelt, sondern in eine Hilfswarteschlange eingereiht wird, die als Warteschlange für unzustellbare Nachrichten für das zusammengesetzte Muster dient.
Dieses Muster eignet sich für Szenarien, in denen es in erster Linie darum geht, Probleme mit der Verfügbarkeit von Consumern oder Ressourcen, die Consumer verwenden, abzuwehren und außerdem Datenverkehrsspitzen auf eine der gekoppelten Warteschlangen umzuverteilen. Es bietet auch Schutz davor, dass einer der Namespaces nicht verfügbar wird, wenn Consumer aus beiden Warteschlangen lesen, die Replikationsverzögerung, die durch den Ablauf von
TimeToLiveentsteht, aber dazu führen kann, dass Nachrichten innerhalb dieses Zeitfensters im nicht verfügbaren Namespace stranden.
Latenzoptimierung
Themen werden verwendet, um Informationen an mehrere Consumer zu verteilen. In einigen Fällen (insbesondere bei Consumern mit breiter geografischer Verteilung) kann es vorteilhaft sein, Nachrichten aus einem Thema in ein Thema in einem sekundären Namespace zu replizieren, der näher an den Consumern liegt.
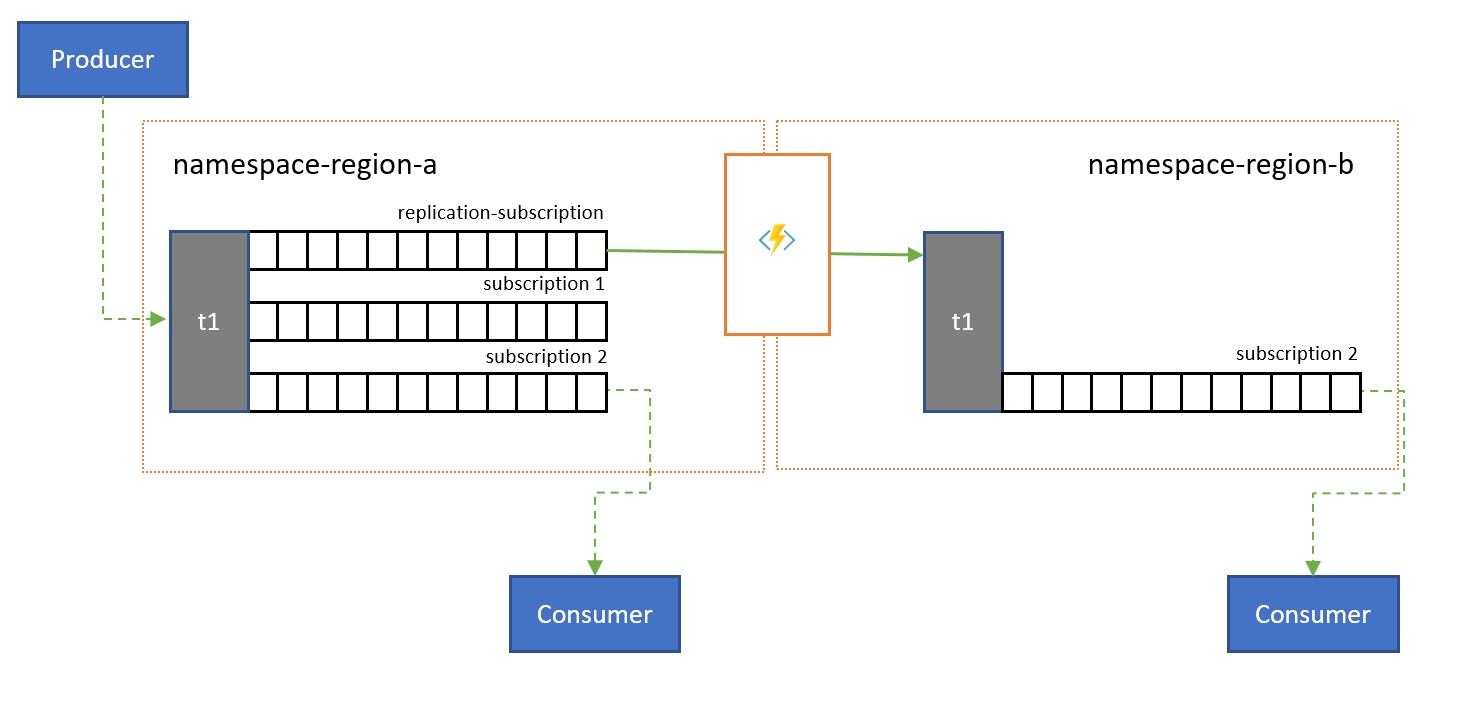
Beispielsweise ist es bei der gemeinsamen Nutzung von Daten zwischen regionalen, kontinentalen Hubs effizienter, Informationen nur ein Mal zwischen den Hubs zu übertragen, damit Consumer ihre Kopie der Daten von diesen Hubs erhalten.
Replikationsübertragungen können in Batches durchgeführt werden, die Consumer häufig abrufen. Die Nachrichten werden dann nacheinander abgewickelt. Bei einer Basisnetzwerklatenz von 100 ms etwa zwischen Nordamerika und Europa benötigt jede Nachricht 200 ms länger (im Vergleich zu einer Entität in derselben Region) für die zwei Roundtrips zu einer Remoteentität, um die Nachrichten zu erfassen und abzuwickeln.
Validierung, Reduzierung und Anreicherung
Nachrichten können von Clients außerhalb ihrer eigenen Lösung in eine Service Bus-Warteschlange oder in ein -Thema übermittelt werden.
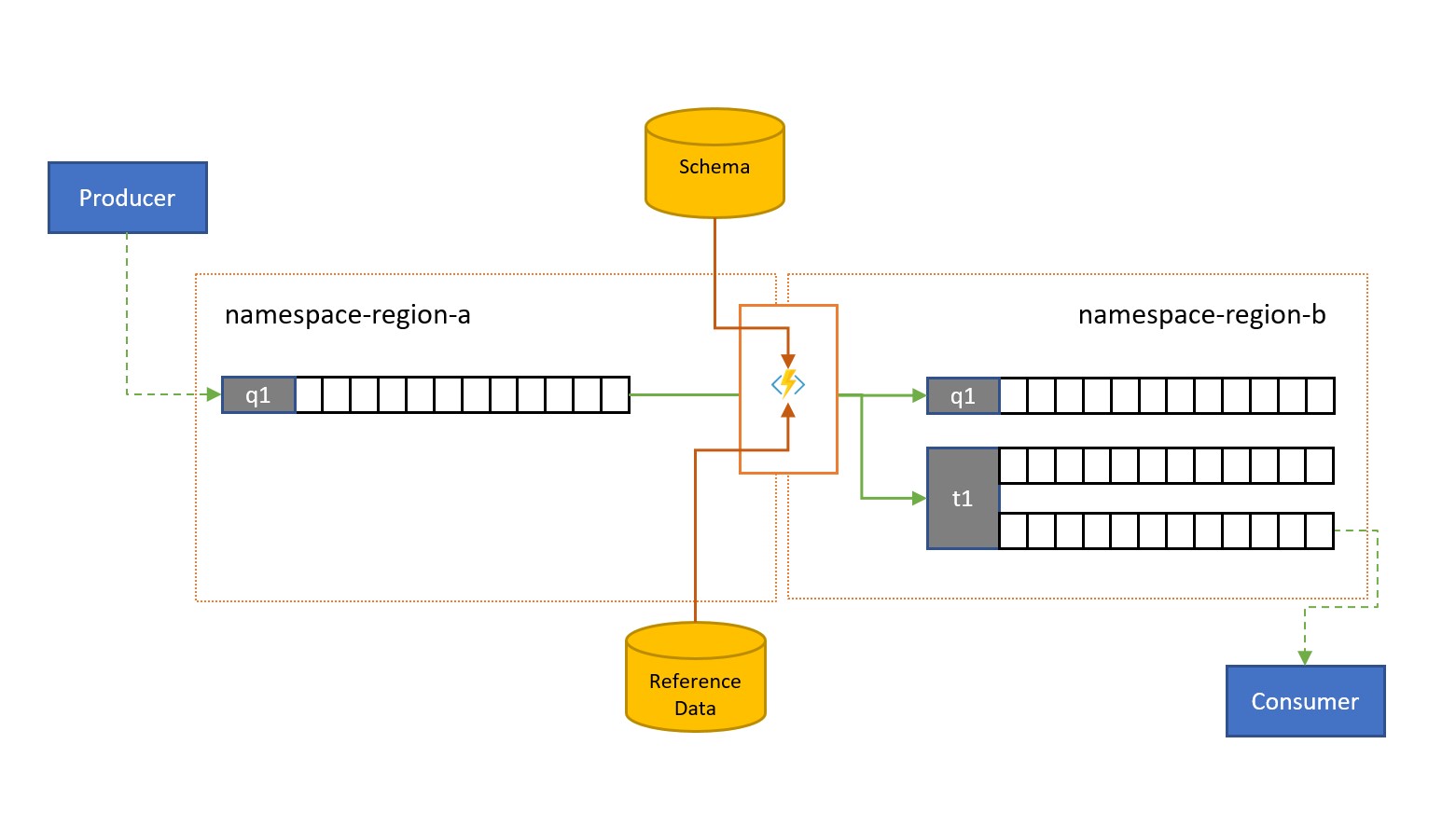
Solche Nachrichten erfordern möglicherweise die Überprüfung der Konformität mit einem bestimmten Schema.Auch müssen nicht kompatible Nachrichten ggf. gelöscht oder in die Warteschlange für unzustellbare Nachrichten verschoben werden. Einige Nachrichten müssen möglicherweise in ihrer Komplexität reduziert werden, indem Daten ausgelassen werden, und einige Nachrichten müssen angereichert werden, indem Daten auf der Grundlage von Verweisdatenlookups hinzugefügt werden. Diese Vorgänge können mit benutzerdefinierter Funktionalität im Replikationstask ausgeführt werden.
Replikation durch Streamen in Warteschlangen
Azure Event Hubs ist eine ideale Lösung für die Verarbeitung extrem großer Mengen eingehender Ereignisse. Aber weder Event Hubs noch ähnliche Engines wie Apache Kafka bieten ein durch den Dienst verwaltetes Modell konkurrierender Consumer, bei dem mehrere Consumer gleichzeitig Nachrichten aus derselben Quelle verarbeiten können, ohne eine doppelte Verarbeitung zu riskieren, und diese Nachrichten schließlich abwickeln, nachdem sie verarbeitet wurden.

Eine Replikation durch Streamen in Warteschlangen überträgt den Inhalt einer einzelnen Event Hub-Partition oder den Inhalt eines vollständigen Event Hubs in eine Service Bus-Warteschlange. Von dort aus können die Nachrichten sicher, transaktional und mit konkurrierenden Consumern verarbeitet werden. Diese Replikation ermöglicht außerdem die Verwendung aller anderen Service Bus-Funktionen für diese Nachrichten, einschließlich Routing mit Themen und sitzungsbasiertes Demultiplexing.
Konsolidierung und Normalisierung
Globale Lösungen setzen sich oft aus regionalen Ressourcen zusammen, die weitgehend unabhängig sind und auch über eigene Verarbeitungsmöglichkeiten verfügen. Überregionale und globale Perspektiven erfordern jedoch Datenintegration und damit eine zentrale Zusammenführung der gleichen Nachrichtendaten, die in den jeweiligen regionalen Ressourcen für die lokale Perspektive ausgewertet werden.

Normalisierung ist eine Variante des Konsolidierungsszenarios, bei der mindestens zwei eingehende Sequenzen von Nachrichten die gleiche Art von Informationen tragen, aber mit unterschiedlichen Strukturen oder unterschiedlichen Codierungen, und die Nachrichten müssen transcodiert oder transformiert werden, bevor sie genutzt werden können.
Normalisierung kann auch kryptografische Aufgaben beinhalten, etwa das Entschlüsseln von End-to-End-verschlüsselten Nutzlasten und das erneute Verschlüsseln mit anderen Schlüsseln und Algorithmen für die Downstreamzielgruppe der Consumer.
Aufteilung und Routing
Service Bus-Themen und deren Abonnementregeln werden häufig verwendet, um einen Nachrichtendatenstrom für eine bestimmte Zielgruppe zu filtern, und diese Zielgruppe erhält dann den gefilterten Satz aus einem Abonnement.
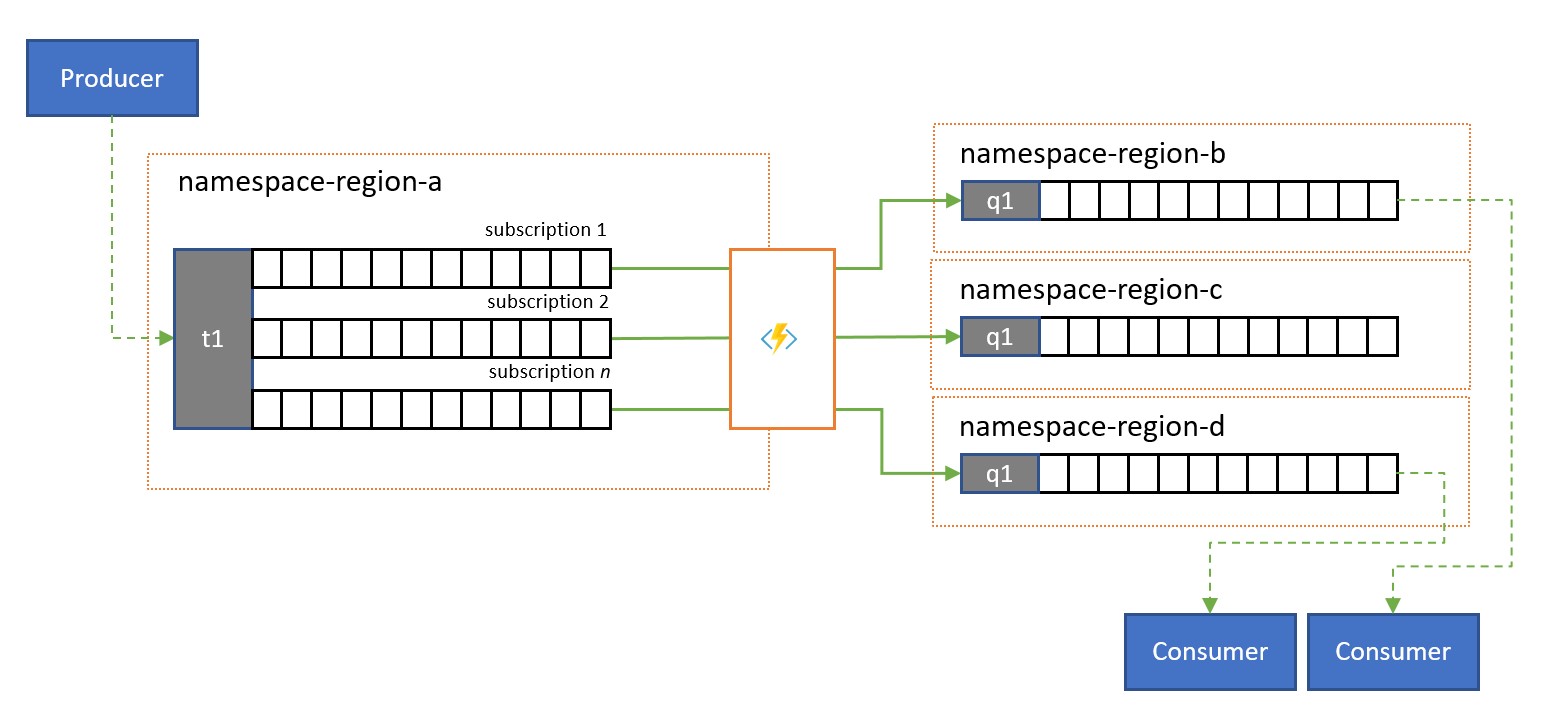
In einem globalen System, in dem die Zielgruppe für diese Nachrichten global verteilt ist oder zu verschiedenen Anwendungen gehört, kann Replikation verwendet werden, um Nachrichten aus einem solchen Abonnement an eine Warteschlange oder ein Thema in einem anderen Namespace als den Namespace zu übertragen, in dem sie genutzt werden.
Replikationsanwendungen in Azure Functions
Die Implementierung der oben genannten Muster erfordert eine skalierbare und zuverlässige Ausführungsumgebung für die Replikationstasks, die Sie konfigurieren und ausführen möchten. In Azure ist die Laufzeitumgebung, die sich am besten für zustandslose Tasks eignet, Azure Functions.
Azure Functions kann unter einer verwalteten Azure-Identität ausgeführt werden, sodass die Replikationstasks in die rollenbasierten Zugriffssteuerungsregeln der Quell- und Zieldienste integriert werden können, ohne dass Sie Geheimnisse im Replikationspfad verwalten müssen. Für Replikationsquellen und -ziele, für die explizite Anmeldeinformationen erforderlich sind, kann Azure Functions die Konfigurationswerte für diese Anmeldeinformationen in einem streng zugriffsgesteuerten Speicher in Azure Key Vault speichern.
Azure Functions ermöglicht den Replikationstasks außerdem die direkte Integration in virtuelle Azure-Netzwerke und Dienstendpunkte für alle Azure-Messagingdienste und ist bereits in Azure Monitor integriert.
Am wichtigsten ist, dass Azure Functions vordefinierte, skalierbare Trigger und Ausgabebindungen für Azure Event Hubs, Azure IoT Hub, Azure Service Bus, Azure Event Grid und Azure Queue Storage sowie benutzerdefinierte Erweiterungen für RabbitMQ und Apache Kafka bietet. Die meisten Trigger werden dynamisch an die Durchsatzanforderungen angepasst, indem die Anzahl der gleichzeitig ausgeführten Instanzen basierend auf dokumentierten Metriken zentral hoch- oder herunterskaliert wird.
Mit dem Azure Functions-Verbrauchsplan können die vordefinierten Trigger sogar auf null skaliert werden, wenn keine Nachrichten für die Replikation verfügbar sind. Dies bedeutet, dass keine Kosten verursacht werden, obwohl die Konfiguration für die erneute Hochskalierung bereit ist. Der wichtigste Nachteil bei Verwendung des Verbrauchsplans besteht darin, dass die Latenzzeit für Replikationstasks, die sich aus diesem Zustand „reaktivieren“, deutlich höher ist als bei den Hostingplänen, in denen die Infrastruktur weiterhin ausgeführt wird.
Im Gegensatz dazu müssen Sie bei den meisten gängigen Replikations-Engines für Messaging und Ereignisse (z. B. MirrorMaker von Apache Kafka) selbst eine Hostingumgebung bereitstellen und die Replikations-Engine skalieren. Das beinhaltet die Konfiguration und Integration der Sicherheits- und Netzwerkfunktionen und das Ermöglichen des Datenflusses von Überwachungsdaten. Selbst dann haben Sie immer noch keine Möglichkeit, benutzerdefinierte Replikations-Tasks in den Datenfluss zu injizieren.
Replikationsaufgaben mit Azure Logic Apps
Eine Alternative ohne Programmierung zum Ausführen der Replikation mithilfe von Functions wäre, stattdessen Logic Apps zu verwenden. Logic Apps bietet vordefinierte Replikationsaufgaben für Service Bus. Dies kann bei der Einrichtung der Replikation zwischen verschiedenen Instanzen helfen und für weitere Anpassungen konfiguriert werden.
Nächste Schritte
In diesem Artikel haben wir eine Reihe von Verbundmustern untersucht und die Rolle von Azure Functions als Ereignis- und Messaging-Replikationslaufzeit in Azure erläutert.
Als nächstes sollten Sie sich darüber informieren, wie Sie eine Replikatoranwendung mit Azure Functions einrichten und dann die Ereignisdatenflüsse zwischen Event Hubs und verschiedenen anderen Ereignis- und Messagingsystemen replizieren: