Platzierungsrichtlinien für Service Fabric-Dienste
Platzierungsrichtlinien sind zusätzliche Regeln, mit denen in einigen besonderen, nicht alltäglichen Szenarien die Dienstplatzierung gesteuert werden kann. Einige Beispiele für diese Szenarien:
- Ihr Service Fabric-Cluster erstreckt sich über geografische Entfernungen, beispielsweise mehrere lokale Rechenzentren oder Azure-Regionen.
- Ihre Umgebung erstreckt sich über mehrere geopolitische oder rechtliche Grenzen, oder ein anderer Fall, in dem politische Grenzen berücksichtigt werden müssen.
- Aufgrund großer Entfernungen oder wegen der Verwendung langsamer oder nicht besonders zuverlässiger Netzwerkverbindungen muss Leistung oder Wartezeit der Kommunikation berücksichtigt werden.
- Sie müssen bestimmte Workloads bestmöglich anordnen, entweder zusammen mit anderen Workloads oder in der Nähe von Kunden.
- Sie benötigen mehrere zustandslose Instanzen einer Partition auf einem einzelnen Knoten.
Die meisten dieser Anforderungen werden durch das physische Layout des Clusters wiedergegeben, dargestellt als Fehlerdomänen des Clusters.
Die erweiterten Platzierungsrichtlinien, mit denen diese Szenarien behandelt werden können, lauten wie folgt:
- Ungültige Domänen
- Erforderliche Domänen
- Bevorzugte Domänen
- Unterbinden einer Replikatüberlastung
- Zulassen mehrerer zustandsloser Instanzen auf einem Knoten
Die meisten der folgenden Steuerelemente können mithilfe von Knoteneigenschaften und Platzierungseinschränkungen konfiguriert werden, aber einige sind komplizierter. Zur Vereinfachung bietet der Service Fabric-Clusterressourcen-Manager diese zusätzliche Platzierungsrichtlinien. Platzierungsrichtlinien werden individuell für benannte Dienstinstanzen konfiguriert. Sie können auch dynamisch aktualisiert werden.
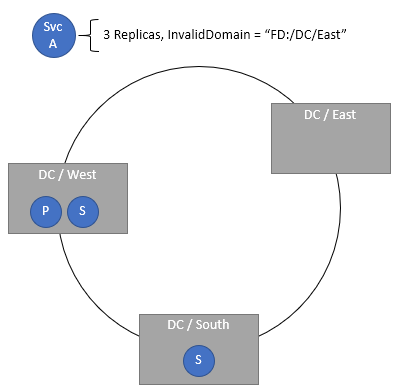
Angeben ungültiger Domänen
Die Platzierungsrichtlinie InvalidDomain ermöglicht die Angabe, dass eine bestimmte Fehlerdomäne für einen bestimmten Dienst ungültig ist. Diese Richtlinie stellt sicher, dass ein bestimmter Dienst nie in einer bestimmten Region ausgeführt wird, z. B. aus geopolitischen Gründen oder zur Einhaltung von Unternehmensrichtlinien. Über Richtlinien können mehrere ungültige Domänen angegeben werden.
Code:
ServicePlacementInvalidDomainPolicyDescription invalidDomain = new ServicePlacementInvalidDomainPolicyDescription();
invalidDomain.DomainName = "fd:/DCEast"; //regulations prohibit this workload here
serviceDescription.PlacementPolicies.Add(invalidDomain);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("InvalidDomain,fd:/DCEast”)
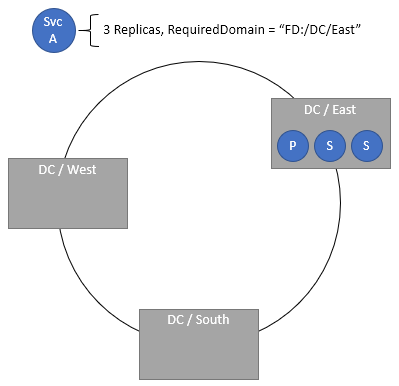
Angeben erforderlicher Domänen
Gemäß der Richtlinie für die Platzierung erforderlicher Domänen darf der Dienst nur in der angegebenen Domäne vorhanden sein. Über Richtlinien können mehrere erforderliche Domänen angegeben werden.
Code:
ServicePlacementRequiredDomainPolicyDescription requiredDomain = new ServicePlacementRequiredDomainPolicyDescription();
requiredDomain.DomainName = "fd:/DC01/RK03/BL2";
serviceDescription.PlacementPolicies.Add(requiredDomain);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("RequiredDomain,fd:/DC01/RK03/BL2")
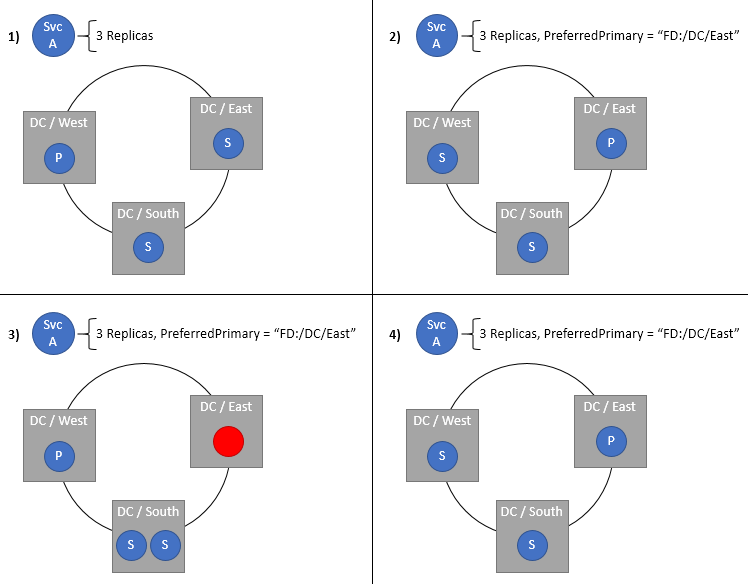
Angeben einer bevorzugten Domäne für die primären Replikate eines zustandsbehafteten Diensts
Die bevorzugte primäre Domäne ist die Standarddomäne, in der das primäre Replikat platziert werden soll. Wenn alles fehlerfrei ist, befindet sich das primäre Replikat in dieser Domäne. Wenn die Domäne oder das primäre Replikat ausfällt oder beendet wird, wird das primäre Replikat an einen anderen Ort verschoben, idealerweise in derselben Domäne. Wenn dieser neue Ort nicht die bevorzugte Domäne ist, verschiebt der Clusterressourcen-Manager das Replikat so bald wie möglich in die bevorzugte Domäne zurück. Diese Einstellung ist nur für zustandsbehaftete Dienste sinnvoll. Diese Richtlinie ist besonders hilfreich in Clustern, die sich über Azure-Regionen oder mehrere Rechenzentren erstrecken, jedoch Dienste enthalten, die bevorzugt an einem bestimmten Ort platziert werden sollen. Die Nähe von primären Replikaten zu ihren Benutzern oder anderen Diensten trägt zu einer geringeren Wartezeit bei, insbesondere für Lesevorgänge, die standardmäßig von primären Replikaten behandelt werden.
ServicePlacementPreferPrimaryDomainPolicyDescription primaryDomain = new ServicePlacementPreferPrimaryDomainPolicyDescription();
primaryDomain.DomainName = "fd:/EastUS/";
serviceDescription.PlacementPolicies.Add(primaryDomain);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("PreferredPrimaryDomain,fd:/EastUS")
Erfordern von Replikatverteilung und Unterbinden von Überlastung
Wenn der Cluster fehlerfrei ist, werden Replikate normalerweise auf Fehler- und Upgradedomänen verteilt. Es gibt jedoch Fälle, in denen mehrere Replikate für eine bestimmte Partition vorübergehend in einer einzelnen Domäne überlastet werden. Nehmen wir beispielsweise an, dass der Cluster neun Knoten in den drei Fehlerdomänen fd:/0, fd:/1 und fd:/2 aufweist. Nehmen wir außerdem an, dass der Dienst über drei Replikate verfügt. Nehmen wir ferner an, dass die Knoten, die für diese Replikate in fd:/1 und fd:/2 verwendet wurden, ausgefallen sind. Der Clusterressourcen-Manager würde normalerweise andere Knoten in diesen Fehlerdomänen bevorzugen. In diesem Fall ist jedoch, zum Beispiel aufgrund von Kapazitätsproblemen, keiner der anderen Knoten in diesen Domänen gültig. Wenn der Clusterressourcen-Manager einen Ersatz für diese Replikate erstellt, müsste er die Knoten in fd:/0 auswählen. Allerdings entsteht dadurch eine Situation, in der die Fehlerdomäneneinschränkung verletzt wird. Das Überlasten von Replikaten erhöht das Risiko eines Ausfalls oder Verlusts der gesamten Replikatgruppe.
Hinweis
Weitere Informationen zu Einschränkungen und Einschränkungsprioritäten im Allgemeinen finden Sie in diesem Thema.
Wenn Sie jemals eine Integritätsmeldung wie die Folgende gesehen haben: „The Load Balancer has detected a Constraint Violation for this Replica:fabric:/<some service name> Secondary Partition <some partition ID> is violating the Constraint: FaultDomain“, ist diese oder eine ähnliche Bedingung erfüllt. In der Regel werden nur ein oder zwei Replikate vorübergehend überlastet. Solange das Quorum der Replikate in einer bestimmten Domäne unterschritten wird, besteht kein Risiko. Eine Überlastung ist selten, kann aber auftreten. Dieser Zustand ist in der Regel vorübergehend, weil die Knoten wieder online gehen. Wenn die Knoten dauerhaft ausfallen und der Clusterressourcen-Manager diese ersetzen muss, stehen in idealen Fehlerdomänen normalerweise andere Knoten zur Verfügung.
Bei einigen Workloads soll die Zielanzahl von Replikaten nach Möglichkeit immer verfügbar sein, selbst wenn diese auf weniger Domänen verteilt sind. Durch diese Workloads werden gleichzeitige dauerhafte Totalausfälle von Domänen riskiert, und in der Regel kann der lokale Zustand wiederhergestellt werden. Bei anderen Workloads wird stattdessen früher die Downtime in Kauf genommen, als die Richtigkeit oder den Verlust von Daten zu riskieren. Die meisten Produktionsworkloads werden mit mehr als drei Replikaten, mehr als drei Fehlerdomänen und vielen gültigen Knoten pro Fehlerdomäne ausgeführt. Aus diesem Grund ermöglicht das Standardverhalten das Überlasten von Domänen. Das Standardverhalten ermöglicht das Behandeln dieser extremen Fälle durch normalen Lastenausgleich und normales Failover, auch wenn dies das vorübergehende Überlasten von Domänen erfordert.
Wenn Sie eine solche Überlastung für eine bestimmte Workload deaktivieren möchten, können Sie die Richtlinie RequireDomainDistribution für den Dienst angeben. Wenn diese Richtlinie festgelegt ist, stellt der Clusterressourcen-Manager sicher, dass keine zwei Replikate aus derselben Partition in derselben Fehler- oder Upgradedomäne ausgeführt werden.
Code:
ServicePlacementRequireDomainDistributionPolicyDescription distributeDomain = new ServicePlacementRequireDomainDistributionPolicyDescription();
serviceDescription.PlacementPolicies.Add(distributeDomain);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName –Stateful -MinReplicaSetSize 3 -TargetReplicaSetSize 3 -PartitionSchemeSingleton -PlacementPolicy @("RequiredDomainDistribution")
Wäre es auch möglich, diese Konfigurationen für Dienste in einem Cluster zu verwenden, der sich nicht über größere Entfernungen erstreckt? Es ist möglich, jedoch gibt es dafür keinen triftigen Grund. Die Konfiguration erforderlicher, ungültiger und bevorzugter Domänen sollte vermieden werden, sofern die Szenarien diese nicht erfordern. Es ist nicht sinnvoll, die Ausführung einer bestimmten Workload in einem einzigen Rack zu erzwingen oder ein bestimmtes Segment Ihres Clusters einem anderen gegenüber zu bevorzugen. Unterschiedliche Hardwarekonfigurationen sollten über Fehlerdomänen hinweg verteilt und über normale Platzierungseinschränkungen und Knoteneigenschaften verwaltet werden.
Platzieren mehrerer zustandsloser Instanzen einer Partition auf einem einzelnen Knoten
Die Platzierungsrichtlinie AllowMultipleStatelessInstancesOnNode ermöglicht die Platzierung mehrerer zustandsloser Instanzen einer Partition auf einem einzelnen Knoten. Standardmäßig können mehrere Instanzen einer einzelnen Partition nicht auf einem Knoten platziert werden. Selbst bei einem -1-Dienst ist es nicht möglich, die Anzahl der Instanzen für einen bestimmten benannten Dienst über die Anzahl der Knoten im Cluster hinaus zu skalieren. Diese Platzierungsrichtlinie entfernt diese Einschränkung und ermöglicht, dass InstanceCount höher als die Knotenanzahl angegeben werden kann.
Wenn Sie jemals eine Integritätsmeldung wie die Folgende gesehen haben: „The Load Balancer has detected a Constraint Violation for this Replica:fabric:/<some service name> Secondary Partition <some partition ID> is violating the Constraint: ReplicaExclusion“, ist diese oder eine ähnliche Bedingung erfüllt.
Aktivieren Sie die folgenden Konfigurationen, um diese Platzierungsrichtlinie auf Ihren Dienst anzuwenden:
<Section Name="Common">
<Parameter Name="AllowCreateUpdateMultiInstancePerNodeServices" Value="True" />
<Parameter Name="HostReuseModeForExclusiveStateless" Value="1" />
</Section>
Wenn Sie die AllowMultipleStatelessInstancesOnNode-Richtlinie für den Dienst angeben, kann InstanceCount über die Anzahl der Knoten im Cluster hinaus festgelegt werden.
Code:
ServicePlacementAllowMultipleStatelessInstancesOnNodePolicyDescription allowMultipleInstances = new ServicePlacementAllowMultipleStatelessInstancesOnNodePolicyDescription();
serviceDescription.PlacementPolicies.Add(allowMultipleInstances);
Mit PowerShell:
New-ServiceFabricService -ApplicationName $applicationName -ServiceName $serviceName -ServiceTypeName $serviceTypeName -Stateless –PartitionSchemeSingleton –PlacementPolicy @(“AllowMultipleStatelessInstancesOnNode”) -InstanceCount 10 -ServicePackageActivationMode ExclusiveProcess
Hinweis
Derzeit wird die Richtlinie nur für zustandslose Dienste mit dem Dienstpaket-Aktivierungsmodus „ExclusiveProcess“ unterstützt.
Warnung
Die Richtlinie wird nicht unterstützt, wenn sie mit statischen Portendpunkten verwendet wird. Wenn beides in Verbindung verwendet wird, kann dies zu einem fehlerhaften Cluster führen, weil mehrere Instanzen auf dem gleichen Knoten versuchen, eine Bindung an denselben Port herzustellen, und nicht gestartet werden können.
Hinweis
Wenn Sie einen hohen Wert für MinInstanceCount mit dieser Platzierungsrichtlinie verwenden, kann dies zum Hängen von Anwendungsupgrades führen. Wenn Sie z. B. über einen Cluster mit fünf Knoten verfügen und InstanceCount=10 festlegen, verfügen Sie über zwei Instanzen auf jedem Knoten. Wenn Sie MinInstanceCount=9 festlegen, kann ein versuchtes App-Upgrade hängen. Mit inInstanceCount=8 kann dies vermieden werden.
Nächste Schritte
- Weitere Informationen zum Konfigurieren von Diensten finden Sie unter Konfigurieren von Einstellungen des Clusterressourcen-Managers für Service Fabric-Dienste.