Abfragebeschleunigung für Azure Data Lake Storage
Die Abfragebeschleunigung ermöglicht es Anwendungen und Analyseframeworks, die Datenverarbeitung drastisch zu optimieren. Dabei werden nur die Daten abgerufen, die für die Durchführung eines bestimmten Vorgangs erforderlich sind. So werden weniger Zeit und Verarbeitungsleistung benötigt, um wichtige Einblicke in gespeicherte Daten zu erhalten.
Übersicht
Die Abfragebeschleunigung unterstützt das Filtern von Prädikaten und Spaltenprojektionen. So können Anwendungen Zeilen und Spalten zu dem Zeitpunkt filtern, zu dem die Daten vom Datenträger gelesen werden. Nur die Daten, die die Bedingungen eines Prädikats erfüllen, werden über das Netzwerk an die Anwendung übertragen. Dies reduziert die Netzwerklatenz und die Computekosten.
Sie können SQL verwenden, um die Zeilenfilterprädikate und Spaltenprojektionen in einer Abfragebeschleunigungsanforderung anzugeben. Von einer Anforderung wird jeweils nur eine Datei verarbeitet. Daher werden erweiterte relationale SQL-Funktionen, z. B. Joins und GROUP BY-Aggregate, nicht unterstützt. Die Abfragebeschleunigung unterstützt CSV- und JSON-formatierte Daten als Eingabe für die einzelnen Anforderungen.
Die Abfragebeschleunigung ist nicht auf Data Lake Storage beschränkt (Speicherkonten, für die der hierarchische Namespace aktiviert wurde). Die Abfragebeschleunigung ist kompatibel mit den Blobs in Speicherkonten, für die kein hierarchischer Namespace aktiviert wurde. Dies bedeutet, dass sich die Netzwerklatenz und die Computekosten genauso reduzieren lassen, wenn Sie Daten verarbeiten, die bereits als Blobs in Speicherkonten gespeichert wurden.
Ein Beispiel für die Verwendung der Abfragebeschleunigung in einer Clientanwendung finden Sie unter Filtern von Daten mithilfe der Abfragebeschleunigung für Azure Data Lake Storage.
Datenfluss
Im folgenden Diagramm wird veranschaulicht, wie eine typische Anwendung die Abfragebeschleunigung verwendet, um Daten zu verarbeiten.
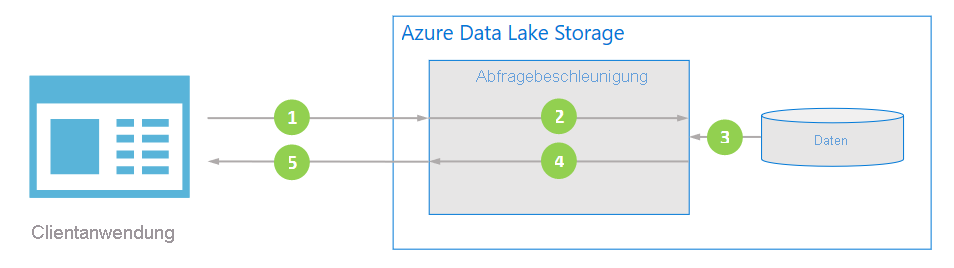
Die Clientanwendung fordert Dateidaten an, indem sie Prädikate und Spaltenprojektionen angibt.
Bei der Abfragebeschleunigung wird die angegebene SQL-Abfrage analysiert. Anschließend wird die Arbeitslast für das Analysieren und Filtern von Daten verteilt.
Die Daten werden von Prozessoren vom Datenträger gelesen, unter Verwendung des geeigneten Formats analysiert und dann gefiltert, indem die angegebenen Prädikate und Spaltenprojektionen angewendet werden.
Bei der Abfragebeschleunigung werden die Antwortshards kombiniert, die an die Clientanwendung zurückgestreamt werden.
Die Clientanwendung empfängt und analysiert die gestreamte Antwort. Die Anwendung muss keine weiteren Daten filtern und kann die gewünschte Berechnung oder Transformation direkt anwenden.
Bessere Leistung zu geringeren Kosten
Die Abfragebeschleunigung optimiert die Leistung, indem die Menge der Daten reduziert wird, die übertragen und von Ihrer Anwendung verarbeitet wird.
Um einen aggregierten Wert zu berechnen, rufen Anwendungen in der Regel alle Daten aus einer Datei ab und verarbeiten und filtern die Daten dann lokal. Eine Analyse der Eingabe-/Ausgabemuster für Analyseworkloads zeigt, dass Anwendungen in der Regel nur 20 % der gelesenen Daten benötigen, um die jeweilige Berechnung durchzuführen. Diese Statistik gilt selbst dann, wenn Techniken wie Partition Pruning angewendet wurden. Das bedeutet, dass 80 % dieser Daten unnötigerweise von Anwendungen über das Netzwerk übertragen, analysiert und gefiltert werden. Dieses Muster, das dafür konzipiert wurde, nicht benötigte Daten auszuschließen, verursacht erhebliche Computekosten.
Obwohl Azure sowohl im Hinblick auf den Durchsatz als auch auf die Latenz ein branchenführendes Netzwerk bietet, wirkt sich die unnötige Übertragung von Daten über dieses Netzwerk immer noch negativ auf die Anwendungsleistung aus. Durch die Abfragebeschleunigung werden diese negativen Auswirkungen beseitigt, da unerwünschte Daten während der Speicheranforderung herausgefiltert werden.
Außerdem muss Ihre Anwendung durch die CPU-Last, die zum Analysieren und Filtern nicht benötigter Daten erforderlich ist, mehr und größere VMS bereitstellen, um die Arbeit zu bewältigen. Da diese Computelast von der Abfragebeschleunigung übernommen wird, können Anwendungen beträchtliche Kosteneinsparungen erzielen.
Anwendungen, die von der Abfragebeschleunigung profitieren können
Die Abfragebeschleunigung wurde für Frameworks für verteilte Analysen und Datenverarbeitungsanwendungen konzipiert.
Frameworks für verteilte Analysen wie Apache Spark und Apache Hive bieten eine Speicherabstraktionsschicht innerhalb des Frameworks. Diese Engines verfügen auch über Abfrageoptimierer, die Informationen zu den Fähigkeiten des zugrunde liegenden E/A-Diensts berücksichtigen können, wenn ein optimaler Abfrageplan für Benutzerabfragen ermittelt wird. Die Abfragebeschleunigung wird bereits in die ersten Frameworks integriert. Infolgedessen profitieren Benutzer*innen dieser Frameworks von einer verbesserten Abfragelatenz und geringeren Gesamtkosten, ohne Änderungen an den Abfragen vornehmen zu müssen.
Die Abfragebeschleunigung ist auch für Datenverarbeitungsanwendungen geeignet. Diese Anwendungstypen führen in der Regel umfangreiche Datentransformationen aus, die u. U. keine direkten analytischen Erkenntnisse liefern. Daher nutzen sie nicht immer etablierte Frameworks für verteilte Analysen. Die Anwendungen verfügen häufig über eine direktere Beziehung zu dem zugrunde liegenden Speicherdienst, sodass sie direkt von Features wie der Abfragebeschleunigung profitieren können.
Ein Beispiel für die Integration der Abfragebeschleunigung in eine Anwendung finden Sie unter Filtern von Daten mithilfe der Abfragebeschleunigung für Azure Data Lake Storage.
Preise
Aufgrund der höheren Computelast innerhalb des Azure Data Lake Storage-Diensts unterscheidet sich das Preismodell für die Verwendung der Abfragebeschleunigung vom normalen Azure Data Lake Storage-Transaktionsmodell. Bei der Abfragebeschleunigung werden Kosten für die Menge der überprüften Daten sowie für die an den Aufrufer zurückgegebene Datenmenge berechnet. Weitere Informationen finden Sie unter Azure Data Lake Storage Gen2: Preise.
Trotz des geänderten Abrechnungsmodells ist das Preismodell für die Abfragebeschleunigung so angelegt, dass die Gesamtkosten für eine Workload geringer ausfallen, da die wesentlich höheren Kosten für VMs gesenkt werden.