Verbessern der Leistung für NFS Azure-Dateifreigaben
In diesem Artikel wird erläutert, wie Sie die Leistung von NFS-Azure-Dateifreigaben für das Netzwerkdateisystem (Network File System, NFS) verbessern können.
Gilt für:
| Dateifreigabetyp | SMB | NFS |
|---|---|---|
| Standard-Dateifreigaben (GPv2), LRS/ZRS | ||
| Standard-Dateifreigaben (GPv2), GRS/GZRS | ||
| Premium-Dateifreigaben (FileStorage), LRS/ZRS |
Erhöhen der Vorauslesegröße zur Verbesserung des Lesedurchsatzes
Der Kernelparameter read_ahead_kb in Linux steht für die Datenmenge, die während eines sequenziellen Lesevorgangs „vorausgelesen“ oder vorab abgerufen werden soll. Linux-Kernelversionen vor 5.4 legen den Vorauslesewert auf das Äquivalent von 15 Mal der rsize des bereitgestellten Dateisystems fest, was der clientseitigen Bereitstellungsoption für die Größe des Lesepuffers entspricht. Dadurch wird der Vorauslesewert hoch genug festgelegt, um den sequenziellen Lesedurchsatz des Clients in den meisten Fällen zu verbessern.
Ab Linux Kernel Version 5.4 verwendet der Linux NFS-Client jedoch einen Standardwert von 128 KiB für read_ahead_kb. Dieser kleine Wert kann den Lesedurchsatz für große Dateien verringern. Bei Kunden, die ein Upgrade von Linux-Versionen mit dem größeren Vorauslesewert auf Releases mit dem Standardwert 128 KiB durchführen, kann es zu einer Abnahme der sequenziellen Leseleistung führen.
Für Linux-Kernel ab 5.4 empfehlen wir, den read_ahead_kb-Wert dauerhaft auf 15 MiB festzulegen, um die Leistung zu verbessern.
Um diesen Wert zu ändern, legen Sie die Vorauslesegröße fest, indem Sie eine Regel in udev, einem Linux-Kernelgerätemanager, hinzufügen. Führen Sie folgende Schritte aus:
Erstellen Sie in einem Text-Editor die Datei /etc/udev/rules.d/99-nfs.rules, indem Sie den folgenden Text eingeben und speichern:
SUBSYSTEM=="bdi" \ , ACTION=="add" \ , PROGRAM="/usr/bin/awk -v bdi=$kernel 'BEGIN{ret=1} {if ($4 == bdi) {ret=0}} END{exit ret}' /proc/fs/nfsfs/volumes" \ , ATTR{read_ahead_kb}="15360"Wenden Sie in einer Konsole die udev-Regel an, indem Sie den Befehl udevadm als Superuser ausführen und die Regeldateien und andere Datenbanken neu laden. Sie müssen diesen Befehl nur einmal ausführen, um udev auf die neue Datei aufmerksam zu machen.
sudo udevadm control --reload
Nconnect
Nconnect ist eine clientseitige Linux-Einbindungsoption, die die Leistung im großen Stil erhöht, indem sie die Verwendung von mehr TCP-Verbindungen (Transmission Control-Protokoll) zwischen dem Linux-Client und dem Azure Files Premium-Dienst für NFSv4.1 ermöglicht.
Vorteile von nconnect
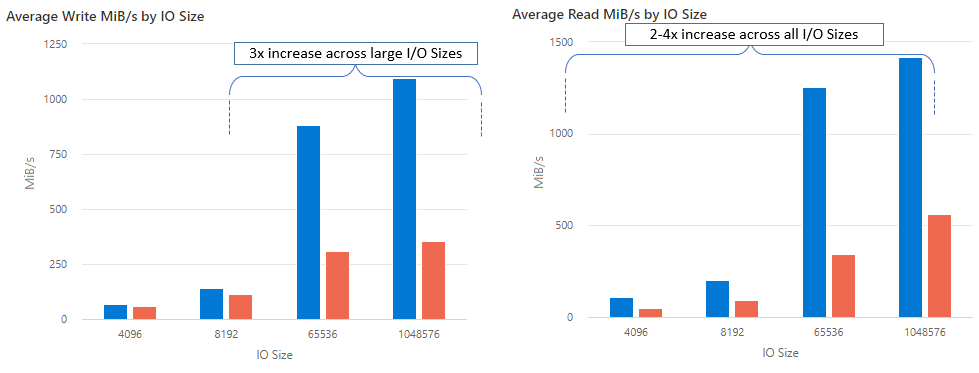
Mit nconnect können Sie die Leistung im großen Stil steigern, indem Sie weniger Clientcomputer verwenden und so die Gesamtkosten senken. Nconnect erhöht die Leistung durch die Verwendung mehrerer TCP-Kanäle auf einer oder mehreren Netzwerkschnittstellen für einen einzelnen oder mehrere Clients. Ohne nconnect würden Sie etwa 20 Clientcomputer benötigen, um die Bandbreitenskalierungslimits (10 GiB/s) zu erreichen, die die größte Bereitstellungsgröße für Premium-Azure-Dateifreigaben bietet. Mit nconnect können Sie diese Grenzwerte nur mit 6-7 Clients erreichen, die Berechnungskosten um fast 70 % reduzieren und gleichzeitig erhebliche Verbesserungen bei E/A-Vorgängen pro Sekunde (IOPS) und Durchsatz im großen Stil erzielen. Siehe folgende Tabelle.
| Metrik (Vorgang) | E/A-Größe | Verbesserung der Leistung |
|---|---|---|
| IOPS (Schreiben) | 64 KB, 1.024 KB | 3x |
| IOPS (Lesen) | Alle E/A-Größen | 2 – 4-fach |
| Durchsatz (Schreiben) | 64 KB, 1.024 KB | 3x |
| Durchsatz (Lesen) | Alle E/A-Größen | 2 – 4-fach |
Voraussetzungen
- Die aktuellen Linux-Distributionen unterstützen
nconnectvollständig. Stellen Sie bei älteren Linux-Distributionen sicher, dass die Linux-Kernelversion 5.3 oder höher ist. - Die Konfiguration pro Einbindung wird nur unterstützt, wenn eine einzelne Dateifreigabe pro Speicherkonto über einen privaten Endpunkt verwendet wird.
Auswirkungen von nconnect auf die Leistung
Bei der Verwendung der Einbindungsoption nconnect mit NFS-Azure-Dateifreigaben auf Linux-Clients im großen Stil haben wir die folgenden Leistungsergebnisse erzielt. Weitere Informationen dazu, wie wir diese Ergebnisse erzielt haben, finden Sie unter Konfiguration des Leistungstests.

Empfehlungen für nconnect
Befolgen Sie diese Empfehlungen, um die besten Ergebnisse mit nconnect zu erzielen.
nconnect=4 festlegen
Obwohl Azure Files die Einrichtung von nconnect bis zur maximalen Einstellung von 16 unterstützt, empfehlen wir, die Einbindungsoptionen mit der optimalen Einstellung von nconnect=4 zu konfigurieren. Derzeit bietet die Verwendung von mehr als vier Kanälen keine Vorteile für die Azure Files-Implementierung von nconnect. Werden mehr als vier Kanäle zu einer einzelnen Azure-Dateifreigabe von einem einzelnen Client verwendet, kann sich dies aufgrund der Überlastung des TCP-Netzwerks sogar negativ auf die Leistung auswirken.
Sorgfältige Dimensionierung von VMs
Es ist wichtig, die virtuellen Clientcomputer (Client-VMs) entsprechend Ihren Workloadanforderungen richtig zu dimensionieren, damit die erwartete Netzwerkbandbreite nicht zu Einschränkungen führt. Sie benötigen nicht mehrere NICs (Network Interface Controller), um den erwarteten Netzwerkdurchsatz zu erreichen. Obwohl es üblich ist, universelle VMs mit Azure Files zu verwenden, stehen je nach Workloadanforderungen und regionaler Verfügbarkeit verschiedene VM-Typen zur Auswahl. Weitere Informationen finden Sie unter Azure-VM-Auswahl.
Beschränken der Warteschlangentiefe auf maximal 64
Die Warteschlangentiefe ist die Anzahl ausstehender E/A-Anforderungen, die eine Speicherressource verarbeiten kann. Es wird nicht empfohlen, die optimale Warteschlangentiefe von 64 zu überschreiten, da Sie dadurch keine weiteren Leistungsgewinne erzielen. Weitere Informationen finden Sie unter Warteschlangentiefe.
Nconnect-Konfiguration pro Einbindung
Wenn eine Workload das Einbinden mehrerer Freigaben mit einem oder mehreren Speicherkonten mit unterschiedlichen nconnect-Einstellungen auf einem einzelnen Client erfordert, können wir nicht garantieren, dass diese Einstellungen beim Einbinden über den öffentlichen Endpunkt beibehalten werden. Die Konfiguration pro Einbindung wird nur unterstützt, wenn wie in Szenario 1 beschrieben eine einzelne Azure-Dateifreigabe pro Speicherkonto über den privaten Endpunkt verwendet wird.
Szenario 1: nconnect-Konfiguration pro Einbindung über einen privaten Endpunkt mit mehreren Speicherkonten (unterstützt)
- StorageAccount.file.core.windows.net = 10.10.10.10
- StorageAccount2.file.core.windows.net = 10.10.10.11
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Szenario 2: nconnect-Konfiguration pro Einbindung über einen öffentlichen Endpunkt (nicht unterstützt)
- StorageAccount.file.core.windows.net = 52.239.238.8
- StorageAccount2.file.core.windows.net = 52.239.238.7
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount2.file.core.windows.net:/StorageAccount2/FileShare1
Hinweis
Selbst wenn das Speicherkonto in eine andere IP-Adresse aufgelöst wird, können wir nicht garantieren, dass die Adresse beibehalten wird, da es sich bei öffentlichen Endpunkten nicht um statische Adressen handelt.
Szenario 3: nconnect-Konfiguration pro Einbindung über einen privaten Endpunkt mit mehreren Freigaben in einem einzelnen Speicherkonto (nicht unterstützt)
- StorageAccount.file.core.windows.net = 10.10.10.10
Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare1 nconnect=4Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare2Mount StorageAccount.file.core.windows.net:/StorageAccount/FileShare3
Leistungstestkonfiguration
Wir haben die folgenden Ressourcen und Benchmarktools verwendet, um die in diesem Artikel beschriebenen Ergebnisse zu erzielen und zu messen.
- Einzelner Client: Azure-VM (DSv4-Serie) mit einer einzelnen NIC
- Betriebssystem: Linux (Ubuntu 20.40)
- NFS-Speicher: Azure Files Premium-Dateifreigabe (30 TiB bereitgestellt,
nconnect=4festgelegt)
| Größe | vCPU | Arbeitsspeicher | Temporärer Speicher (SSD) | Max. Anzahl Datenträger | Maximale Anzahl NICs | Erwartete Netzwerkbandbreite |
|---|---|---|---|---|---|---|
| Standard_D16_v4 | 16 | 64GiB | Nur Remotespeicher | 32 | 8 | 12.500 MBit/s |
Benchmarktools und -tests
Wir haben Flexible I/O Tester (FIO) verwendet, ein kostenloses Open-Source-Datenträger-E/A-Tool, das sowohl für Benchmarktests als auch für Belastungs-/Hardwareüberprüfungen eingesetzt wird. Gehen Sie wie im Abschnitt „Binary Packages“ (Binäre Pakete) der FIO-Infodatei beschrieben vor, um FIO auf der Plattform Ihrer Wahl zu installieren.
Diese Tests konzentrieren sich auf zufällige E/A-Zugriffsmuster, bei sequenziellen E/A-Zugriffen erhalten Sie jedoch ähnliche Ergebnisse.
Hohe IOPS-Rate: 100 % Lesevorgänge
E/A-Größe 4 KB – zufälliger Lesevorgang – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
E/A-Größe 8 KB – zufälliger Lesevorgang – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Hoher Durchsatz: 100 % Lesevorgänge
E/A-Größe 64 KB – zufälliger Lesevorgang – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
E/A-Größe 1.024 KB – zufälliger Lesevorgang (100 %) – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randread --group_reporting --ramp_time=300
Hohe IOPS-Rate: 100 % Schreibvorgänge
E/A-Größe 4 KB – zufälliger Schreibvorgang (100 %) – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=4k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
E/A-Größe 8 KB – zufälliger Schreibvorgang (100 %) – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=8k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Hoher Durchsatz: 100 % Schreibvorgänge
E/A-Größe 64 KB – zufälliger Schreibvorgang (100 %) – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=64k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
E/A-Größe 1.024 KB – zufälliger Schreibvorgang (100 %) – Warteschlangentiefe 64
fio --ioengine=libaio --direct=1 --nrfiles=4 --numjobs=1 --runtime=1800 --time_based --bs=1024k --iodepth=64 --filesize=4G --rw=randwrite --group_reporting --ramp_time=300
Leistungsüberlegungen für nconnect
Wenn Sie die Einbindungsoption nconnect verwenden, sollten Sie Workloads mit den folgenden Eigenschaften genau bewerten:
- Latenzempfindliche Schreibworkloads mit einem einzelnen Thread und/oder einer geringen Warteschlangentiefe (kleiner als 16)
- Latenzempfindliche Leseworkloads mit einem einzelnen Thread und/oder einer geringen Warteschlangentiefe in Kombination mit kleinen E/A-Größen
Nicht alle Workloads erfordern eine hohe IOPS-Rate oder einen hohen Durchsatz. Für kleinere Workloads ist die Verwendung von nconnect möglicherweise nicht sinnvoll. Verwenden Sie die folgende Tabelle, um zu entscheiden, ob nconnect für Ihre Workload von Vorteil ist. Empfohlene Szenarien sind grün hervorgehoben, nicht empfohlene Szenarien rot. Szenarien mit gelber Hervorhebung sind neutral.
