Erreichen von Georedundanz für Azure Stream Analytics-Aufträge
Azure Stream Analytics bietet kein automatisches geografisches Failover. Sie können jedoch Georedundanz erzielen, indem Sie in mehreren Azure-Regionen identische Stream Analytics-Aufträge bereitstellen. Jeder Auftrag stellt eine Verbindung mit lokalen Ein- und Ausgabequellen her. Die Anwendung muss sowohl Eingabedaten an die beiden regionalen Eingänge senden als auch eine Abstimmung zwischen den beiden regionalen Ausgängen durchführen. Die Stream Analytics-Aufträge sind zwei separate Entitäten.
Das folgende Diagramm zeigt ein Beispiel für eine georedundante Bereitstellung von Stream Analytics-Aufträgen mit Event Hub-Eingabe und Azure-Datenbank-Ausgabe.
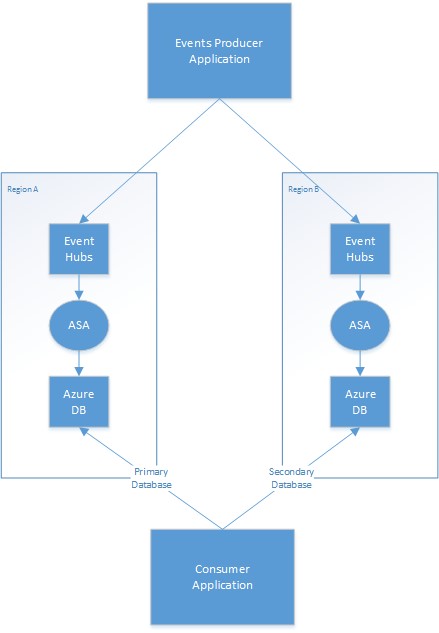
Strategie mit primärer/sekundärer Region
Die Anwendung muss verwalten, welche Ausgabedatenbank einer Region als primäre Datenbank und welche als sekundäre Datenbank betrachtet wird. Bei einem Ausfall der primären Region wechselt die Anwendung zur sekundären Datenbank und beginnt mit dem Lesen von Updates aus dieser Datenbank. Der eigentliche Mechanismus zum Minimieren doppelter Lesevorgänge ist von Ihrer Anwendung abhängig. Sie können diesen Prozess vereinfachen, indem Sie zusätzliche Informationen in die Ausgabe schreiben. Beispielsweise können Sie jeder Ausgabe einen Zeitstempel oder eine Sequenz-ID hinzufügen, damit doppelte Zeilen auf triviale Weise übersprungen werden können. Sobald die primäre Region wieder hergestellt ist, holt sie über ähnliche Mechanismen den Status der sekundären Datenbank auf.
Auch wenn verschiedene Ein- und Ausgabetypen unterschiedliche Georeplikationsoptionen zulassen, wird das in diesem Artikel beschriebene Muster empfohlen, um Georedundanz zu erreichen, da es Flexibilität und Kontrolle sowohl für Ereignisproduzenten als auch für Ereignisconsumer bietet.