Über die Netezza-Migration hinaus: Implementieren eines modernen Data Warehouse in Microsoft Azure
Dieser Artikel ist Teil 7 einer siebenteiligen Serie, die einen Leitfaden zum Migrieren von Netezza zu Azure Synapse Analytics bereitstellt. Dieser Artikel konzentriert sich auf bewährte Methoden für die Implementierung moderner Data Warehouses.
Über die Data Warehouse-Migration zu Azure hinaus
Ein wichtigster Grund für die Migration Ihres vorhandenen Data Warehouse zu Azure Synapse Analytics besteht darin, eine global sichere, skalierbare, kostengünstige, cloudnative, nutzungsbasierte Analysedatenbank zu nutzen. Mit Azure Synapse können Sie Ihr migriertes Data Warehouse mit dem vollständigen Analyse-Ökosystem von Microsoft Azure integrieren. Dadurch können Sie die Vorteile anderer Microsoft-Technologien nutzen und Ihr migriertes Data Warehouse modernisieren. Diese Technologien umfassen:
Azure Data Lake Storage für kostengünstige(s) Datenerfassung, -staging, -bereinigung, und -transformation. Data Lake Storage kann die Datenlagerkapazität freigeben, die von schnell wachsenden Stagingtabellen belegt ist.
Azure Data Factory zur Datenintegration von IT und Self-Service für die Zusammenarbeit mit Connectors für cloudbasierte und lokale Datenquellen sowie Streamingdaten.
Common Data Model zum technologieübergreifenden Freigeben konsistenter vertrauenswürdiger Daten, einschließlich:
- Azure Synapse
- Azure Synapse Spark
- Azure HDInsight
- Power BI
- Adobe Customer Experience Platform
- Azure IoT
- ISV-Partner von Microsoft
Data Science-Technologien von Microsoft, einschließlich:
- Azure Machine Learning Studio
- Azure Machine Learning
- Azure Synapse Spark (Spark-as-a-Service)
- Jupyter Notebook
- RStudio
- ML.NET
- .NET für Apache Spark, womit Data Scientists Azure Synapse-Daten verwenden können, um skalierbare Modelle für maschinelles Lernen zu trainieren.
Azure HDInsight zur Verarbeitung großer Datenmengen und um Big Data mit Azure Synapse-Daten durch Erstellen eines logischen Data Warehouse mithilfe von PolyBase zu verknüpfen.
Azure Event Hubs, Azure Stream Analytics und Apache Kafka um Livestreamingdaten aus Azure Synapse zu integrieren.
Das Wachstum von Big Data hat zu einer hohen Nachfrage nach maschinellem Lernen geführt, um benutzerdefinierte, trainierte Machine Learning-Modelle für die Verwendung in Azure Synapse zu ermöglichen. Durch Machine Learning-Modelle kann die Datenbankanalyse skalierbar im Batch ausgeführt werden – auf ereignisgesteuerter Basis und bedarfsgesteuert. Die Möglichkeit den Vorteil der Datenbankanalysen in Azure Synapse von mehreren BI-Tools und Anwendungen aus zu nutzen, garantiert auch konsistente Vorhersagen und Empfehlungen.
Darüber hinaus können Sie Azure Synapse mit Microsoft-Partnertools in Azure integrieren, um die Amortisationszeit zu verkürzen.
Sehen wir uns genauer an, wie Sie die Technologien im Analyse-Ökosystem von Microsoft nutzen können, um Ihr Data Warehouse nach der Migration zu Azure Synapse zu modernisieren.
Auslagern des Daten-Staging und der ETL-Verarbeitung in Data Lake Storage und Data Factory
Die digitale Transformation hat eine große Herausforderung für Unternehmen geschaffen, indem neue Daten für die Erfassung und Analyse generiert werden. Ein gutes Beispiel hierfür sind Transaktionsdaten, die dadurch erstellt werden, dass Online-Transaktionsverarbeitungssysteme (OLTP) für den Service-Zugriff über mobile Geräte geöffnet werden. Viele dieser Daten finden ihren Weg in Data Warehouses, und OLTP-Systeme sind die Hauptquelle. Da aktuell Kunden – anstelle von Mitarbeitern – Transaktionsraten bestimmen, ist das Datenvolumen in Data Warehouse-Stagingtabellen schnell angestiegen.
Mit dem schnellen Zustrom von Daten in das Unternehmen – zusammen mit neuen Datenquellen wie dem Internet der Dinge (IoT) – müssen Unternehmen neue Wege finden, um die Datenintegration ETL-Verarbeitung hochzuskalieren. Eine Methode ist das Auslagern der Erfassung, Datenbereinigung, Transformation und Integration in einen Data Lake. Dort werden die Daten dann skalierbar im Rahmen eines Data Warehouse-Modernisierungsprogramms verarbeitet.
Nachdem Sie Ihr Data Warehouse zu Azure Synapse migriert haben, kann Microsoft Ihre ETL-Verarbeitung durch die Erfassung und das Staging von Daten in Data Lake Storage modernisieren. Anschließend können Sie Ihre Daten mithilfe von Data Factory bereinigen, transformieren und integrieren, bevor Sie sie parallel mit PolyBase in Azure Synapse laden.
Bei ELT-Strategien sollten Sie die ELT-Verarbeitung an Data Lake Storage auslagern. Dadurch ist eine einfache Skalierung möglich, wenn Ihr Datenvolumen oder Ihre Datenfrequenz ansteigt.
Microsoft Azure Data Factory
Azure Data Factory ist ein hybrider Datenintegrationsdienst mit nutzungsbasierter Zahlung für hochgradig skalierbare ETL- und ELT-Verarbeitungen. Data Factory bietet eine webbasierte Benutzeroberfläche zum Erstellen von Datenintegrationspipelines ohne Code. Mit Data Factory haben Sie folgende Möglichkeiten:
skalierbare Datenintegrationspipelines ohne Code erstellt werden können.
Rufen Sie Daten einfach und skalierbar ab.
Sie zahlen nur für wirklich genutzte Ressourcen.
Herstellen eine Verbindung mit lokalen, Cloud- und SaaS-basierten Datenquellen.
Cloud- und lokale Daten im großen Stil erfasst, verschoben, bereinigt, transformiert, integriert und analysiert werden können.
problemlos Pipelines erstellt, überwacht und verwaltet werden können, die sowohl lokale als auch Cloud-Datenspeicher umfassen.
Eine horizontale Skalierung mit nutzungsbasierter Bezahlung entsprechend dem Kundenwachstum möglich ist.
Sie können diese Features verwenden, ohne Code zu schreiben, oder Sie können benutzerdefinierten Code zu Data Factory-Pipelines hinzufügen. Der folgende Screenshot zeigt ein Beispiel für eine Data Factory-Pipeline.

Tipp
Mit Data Factory können Sie ohne Code skalierbare Datenintegrationspipelines erstellen.
Sie können die Data Factory-Pipeline von mehreren Orten aus entwickeln, einschließlich:
Microsoft Azure-Portal.
Microsoft Azure PowerShell.
Programmgesteuert von .NET und Python mit einem mehrsprachigen SDK.
ARM-Vorlagen (Azure Resource Manager)
REST-APIs
Tipp
Data Factory kann mit lokalen Daten sowie Cloud- und SaaS-Daten verbunden werden.
Entwickler und Data Scientists, die es vorziehen, Code zu schreiben, können Data Factory-Pipelines in Java, Python und .NET problemlos mithilfe der für diese Programmiersprachen verfügbaren Softwareentwicklungskits (SDKs) erstellen. Data Factory-Pipelines können hybride Datenpipelines sein, da sie Daten in lokalen Rechenzentren, Microsoft Azure, anderen Clouds und SaaS-Angeboten verbinden, erfassen, bereinigen, transformieren und analysieren können.
Nachdem Sie Data Factory-Pipelines entwickelt haben, um Daten zu integrieren und zu analysieren, können Sie diese Pipelines global bereitstellen und für die Ausführung im Batch planen. Sie können sie bei Bedarf als Dienst aufrufen oder in Echtzeit auf ereignisgesteuerter Basis ausführen. Eine Data Factory-Pipeline kann auch auf einem oder mehreren Ausführungsmodulen ausgeführt werden und die Ausführung überwachen, um Leistung zu gewährleisten und Fehler nachzuverfolgen.
Tipp
In Azure Data Factory können Pipelines die Integration und Analyse von Daten steuern. Data Factory ist eine Datenintegrationssoftware auf Unternehmensniveau, die für IT-Experten vorgesehen ist und über Data Wrangling-Funktionalität für Geschäftsbenutzer verfügt.
Anwendungsfälle
Data Factory unterstützt mehrere Anwendungsfälle, z. B.:
Vorbereiten, Integrieren und Anreichern von Daten aus Cloud-Datenquellen und lokalen Datenquellen, um Ihr migriertes Data Warehouse und Ihre Data Marts auf Microsoft Azure Synapse aufzufüllen.
Vorbereiten, Integrieren und Anreichern von Daten aus Cloud-Datenquellen und lokalen Datenquellen, um Trainingsdaten für die Entwicklung von Modellen für maschinelles Lernen und für das erneute Training analytischer Modelle zu erstellen.
Orchestrieren der Datenvorbereitung und -analyse, um prädiktive und präskriptive analytische Pipelines für die Verarbeitung und Analyse von Daten im Batch zu erstellen, z. B. Stimmungsanalysen. Handeln Sie entweder auf die Ergebnisse der Analyse oder füllen Sie Ihr Data Warehouse mit den Ergebnissen auf.
Vorbereiten, Integrieren und Anreichern von Daten für datengesteuerte Geschäftsanwendungen, die über operativen Datenspeichern z. B. Azure Cosmos DB in der Azure-Cloud ausgeführt werden.
Tipp
Erstellen Sie Trainingsdatasets in der Data Science, um Machine Learning-Modelle zu entwickeln.
Datenquellen
Bei Data Factory können Sie Connectors aus cloudbasierten und lokalen Datenquellen verwenden. Agentsoftware, bekannt als selbstgehostete Integration Runtime, greift sicher auf lokale Datenquellen zu und sorgt für eine sichere, skalierbare Datenübertragung.
Transformieren von Daten mit Azure Data Factory
In einer Data Factory-Pipeline können Sie alle Arten von Daten aus diesen Quellen erfassen, bereinigen, transformieren, integrieren und analysieren. Daten können strukturiert, halbstrukturiert wie JSON oder Avro oder unstrukturiert sein.
Ohne Code zu schreiben, können professionelle ETL-Entwickler Data Factory-Zuordnungsdatenflüsse verwenden, um Daten zu filtern, zu teilen, mehrere Typen zu verknüpfen, zu suchen, zu pivotieren, entzupivotieren, zu sortieren, zu vereinigen und zu aggregieren. Darüber hinaus unterstützt Data Factory Ersatzschlüssel, mehrere Schreibverarbeitungsoptionen z. B. Einfügen, Upsert, Aktualisieren, Tabellenneuerstellung und -kürzung sowie verschiedene Arten von Zieldatenspeichern – auch als Senken bezeichnet. ETL-Entwickler können auch Aggregationen erstellen, einschließlich Zeitreihenaggregationen, für die ein Fenster in Datenspalten platziert werden muss.
Tipp
Professionelle ETL-Entwickler (Extrahieren, Transformieren und Laden) können Daten mithilfe von Data Factory-Zuordnungsdatenflüssen bereinigen, transformieren und integrieren, ohne Code schreiben zu müssen.
Sie können Zuordnungsdatenflüsse ausführen, die Daten als Aktivitäten in einer Data Factory-Pipeline transformieren, und wenn erforderlich, können Sie mehrere Zuordnungsdatenflüsse in eine einzelne Pipeline einschließen. Auf diese Weise können Sie die Komplexität verwalten, indem Sie anspruchsvolle Datentransformations- und Integrationsaufgaben in kleinere Zuordnungsdatenströme aufteilen, die kombiniert werden können. Außerdem können Sie bei Bedarf benutzerdefinierten Code hinzufügen. Zusätzlich zu dieser Funktionalität umfassen Data Factory-Zuordnungsdatenflüsse die Möglichkeit, um:
Definieren von Ausdrücken, um Daten zu bereinigen und zu transformieren, Aggregationen zu berechnen und Daten anzureichern. Diese Ausdrücke können beispielsweise Feature Engineering in einem Datumsfeld ausführen, um sie in mehrere Felder aufzuteilen und somit Trainingsdaten während der Entwicklung von Machine Learning-Modellen zu erstellen. Sie können Ausdrücke aus einer umfangreichen Reihe von unterschiedlichen Funktionen erstellen, u. a. mathematische und temporale Funktionen, Funktionen zum Teilen, Zusammenführen, Ersetzen, für die Zeichenfolgenverkettung, für Bedingungen, den Musterabgleich u. v. m.
Automatisches Verwalten von Schemaabweichungen, damit Datentransformationspipelines nicht durch Schemaänderungen in Datenquellen beeinträchtigt werden. Diese Fähigkeit ist besonders wichtig für das Streamen von IoT-Daten, bei denen Schemaänderungen ohne Ankündigung auftreten können, wenn Geräte aktualisiert werden oder wenn Messwerte von Gatewaygeräten, die IoT-Daten sammeln, nicht erfasst werden.
Partitionieren von Daten, damit Transformationen parallel und skalierbar ausgeführt werden können.
Überprüfen von Streamingdaten, um die Metadaten eines Datenstroms anzuzeigen, den Sie transformieren.
Tipp
Mit Data Factory können Schemaänderungen in eingehenden Daten, z. B. in Streamingdaten, automatisch erkannt und verwaltet werden.
Der folgende Screenshot zeigt ein Beispiel für einen Zuordnungsdatenfluss in Data Factory.

Technische Fachkräfte können Profile für die Datenqualität erstellen und die Ergebnisse einzelner Datentransformationen anzeigen, indem sie während der Entwicklung eine Debugfunktion aktivieren.
Tipp
Data Factory kann Daten auch partitionieren, damit die ETL-Verarbeitung skalierbar ausgeführt werden kann.
Falls notwendig können Sie die Transformations- und Analysefunktionen von Data Factory erweitern, indem Sie einer Pipeline einen verknüpften Dienst hinzufügen, der Ihren Code enthält. Beispielsweise könnte ein Azure Synapse Spark-Pool-Notebook Python-Code enthalten, der ein trainiertes Modell verwendet, um über einen Zuordnungsdatenfluss integrierte Daten zu bewerten.
Sie können integrierte Daten und alle Ergebnisse aus Analysen speichern, die in einer Data Factory-Pipeline in einem oder mehreren Datenspeichern enthalten sind, z. B. Data Lake Storage, Azure Synapse oder Hive-Tabellen in HDInsight. Sie können auch andere Aktivitäten aufrufen, um auf Basis von Erkenntnissen zu handeln, die von einer Analysepipeline von Data Factory erzeugt wurden.
Tipp
Data Factory-Pipelines sind erweiterbar, da Data Factory Sie Ihren eigenen Code schreiben lässt, den Sie als Teil einer Pipeline ausführen können.
Nutzen von Spark zum Skalieren der Datenintegration
Zur Laufzeit nutzt Data Factory Azure Synapse Spark-Pools – das Spark-as-a-Service-Angebot von Microsoft – intern, um Daten in der Azure-Cloud zu bereinigen und zu integrieren. Sie können Daten mit einem hohen Volumen und einer hohen Geschwindigkeit, z. B. Clickstreamdaten, in großem Stil bereinigt, integriert und analysiert werden. Die Absicht von Microsoft besteht darin, auch Data Factory-Pipelines für andere Spark-Verteilungen auszuführen. Zusätzlich zum Ausführen von ETL-Aufträgen auf Spark kann Data Factory Pig-Skripts und Hive-Abfragen aufrufen, um auf in HDInsight gespeicherte Daten zuzugreifen und diese zu transformieren.
Verknüpfen der Self-Service-Datenvorbereitung und der ETL-Verarbeitung in Data Factory mithilfe von Wranglingdatenflüssen
Mit Data Wrangling können Geschäftsbenutzer, auch als Citizen Data Integrators und Data Engineers bezeichnet, die Plattform verwenden, um Daten visuell zu ermitteln, zu prüfen und im großen Stil vorzubereiten, ohne Code zu schreiben. Diese Data Factory-Funktion ist einfach zu verwenden und ähnelt Microsoft Excel Power Query- oder Microsoft Power BI-Datenflüssen. Self-Service-Geschäftsbenutzer verwenden dabei eine Benutzeroberfläche im Tabellenkalkulationsstil mit Dropdowntransformationen, um Daten vorzubereiten und zu integrieren. Der folgende Screenshot zeigt ein Beispiel für einen Wranglingdatenfluss in Data Factory.

Im Unterschied zu Excel und Power BI verwenden Data Factory-Wranglingdatenflüsse Power Query, um M-Code zu generieren und dann in einen massiv-parallelen In-Memory-Spark-Auftrag für die Ausführung auf Cloudebene zu übersetzen. Mit der Kombination von Zuordnungsdatenflüssen und Wranglingdatenflüssen in Data Factory können professionelle ETL-Entwickler und Geschäftsbenutzer zusammenarbeiten, um Daten für einen gemeinsamen Geschäftszweck vorzubereiten, zu integrieren und zu analysieren. Das vorherige Diagramm zu Data Factory-Zuordnungsdatenflüssen zeigt, wie sowohl Data Factory als auch Azure Synapse Spark-Pool-Notebooks in derselben Data Factory-Pipeline kombiniert werden können. Die Kombination aus Zuordnungs- und Wranglingdatenflüssen in Data Factory hilft IT- und Geschäftsbenutzern dabei, zu wissen, welche Datenflüsse jede erstellt hat, und unterstützt die Wiederverwendung des Datenflusses, um die Neubildung zu minimieren und Produktivität und Konsistenz zu maximieren.
Tipp
Data Factory unterstützt sowohl Wranglingdatenflüsse als auch Zuordnungsdatenflüsse, sodass Geschäftsbenutzer und IT-Benutzer Daten gemeinsam auf einer gemeinsamen Plattform integrieren können.
Verknüpfen von Daten und Analysen in analytischen Pipelines
Zusätzlich zur Bereinigung und Transformation von Daten kann Data Factory Datenintegrationen und Analysen in derselben Pipeline kombinieren. Sie können Data Factory verwenden, um sowohl Datenintegrations- als auch Analysepipelines zu erstellen, wobei letztere eine Erweiterung der ersteren sind. Sie können ein Analytisches Modell in eine Pipeline ablegen, um eine analytische Pipeline zu erstellen, die saubere, integrierte Daten für Vorhersagen oder Empfehlungen generiert. Anschließend können Sie sofort auf die Vorhersagen oder Empfehlungen reagieren oder diese in Ihrem Data Warehouse speichern, um neue Erkenntnisse und Empfehlungen bereitzustellen, die in BI-Tools angezeigt werden können.
Zur Batchbewertung Ihrer Daten können Sie ein analytisches Modell entwickeln, das Sie als Dienst in einer Data Factory-Pipeline aufrufen. Sie können analytische Modelle codefrei mit Azure Machine Learning Studio oder mit dem Azure Machine Learning SDK entwickeln, indem Sie Azure Synapse Spark-Poolnotebooks oder R in RStudio verwenden. Wenn Sie Spark Machine Learning-Pipelines in Azure Synapse Spark-Poolnotebooks ausführen, wird die Analyse im großen Stil ausgeführt.
Sie können integrierte Daten und analytische Pipelineergebnisse einer Data Factory in einem oder mehreren Datenspeichern enthalten sind, z. B. Data Lake Storage, Azure Synapse oder Hive-Tabellen in HDInsight. Sie können auch andere Aktivitäten aufrufen, um auf Basis von Erkenntnissen zu handeln, die von einer Analysepipeline von Data Factory erzeugt wurden.
Verwendung einer Lake-Datenbank zum Freigeben konsistenter vertrauenswürdiger Daten
Ein wichtiges Ziel des Datenintegrations-Setups ist die Möglichkeit, Daten einmal zu integrieren und überall – und nicht nur in einem Data Warehouse – wiederzuverwenden. Sie können beispielsweise integrierte Daten in der Data Science verwenden. Wenn Daten wiederverwendet werden, entfällt die Neuentwicklung. Zudem werden konsistente, leicht verständliche Daten gewährleistet, denen alle vertrauen können.
Das Common Data Model beschreibt Kerndatenentitäten, die für das gesamte Unternehmen freigegeben und wiederverwendet werden können. Um die Wiederverwendung zu erreichen, legt das Common Data Model einen Satz allgemeiner Datennamen und Definitionen fest, die logische Datenentitäten beschreiben. Beispiele für allgemeine Datennamen sind Kunden-, Konto-, Produkt-, Lieferanten- und Bestellungen, Zahlungen und Rückgaben. IT- und Geschäftsexperten können Datenintegrationssoftware verwenden, um gemeinsame Datenressourcen zu erstellen und zu speichern. So können die Ressourcen maximal wiederverwendet werden, um die Konsistenz in der gesamten Organisation zu fördern.
Azure Synapse bietet branchenspezifische Datenbankvorlagen, um Daten im Lake zu standardisieren. Lake-Datenbankvorlagen bieten Schemas für vordefinierte Geschäftsbereiche, mit denen Daten auf strukturierte Weise in eine Lake-Datenbank geladen werden können. Die Leistung kommt, wenn Sie Datenintegrationssoftware verwenden, um allgemeine Datenressourcen zu erstellen, wodurch vertrauenswürdige Daten, die von Anwendungen und analytischen Systemen genutzt werden können, selbst beschrieben werden können. Sie können allgemeine Datenressourcen in Data Lake Storage mithilfe von Data Factory erstellen.
Tipp
Data Lake Storage ist ein freigegebener Speicher, der Microsoft Azure Synapse, Azure Machine Learning, Azure Synapse Spark und HDInsight unterstützt.
Power BI, Azure Synapse Spark, Azure Synapse und Azure Machine Learning können allgemeine Datenressourcen nutzen. Das folgende Diagramm zeigt wie eine Lake-Datenbank in Azure Synapse Analytics verwendet werden kann.
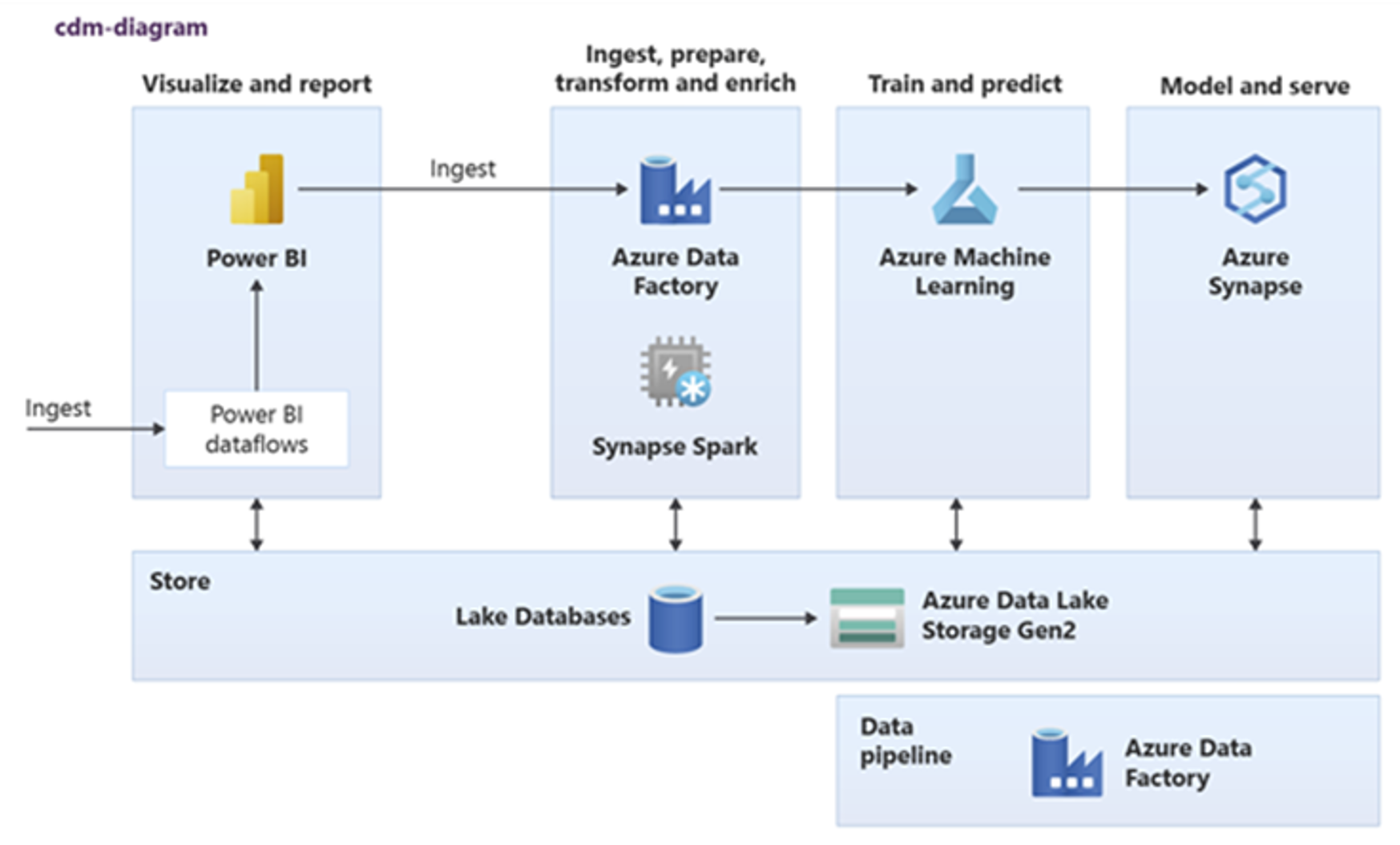
Tipp
Integrieren Sie Daten zum Erstellen logischer Entitäten der Lake-Datenbank im freigegebenen Speicher, um die Wiederverwendung gemeinsamer Datenressourcen zu maximieren.
Integration mit Microsoft Data Science-Technologien in Azure
Ein weiteres wichtiges Ziel beim Modernisieren eines Data Warehouses besteht darin, Einblicke für den Wettbewerbsvorteile zu erzeugen. Sie können Einblicke erstellen, indem Sie Ihr migriertes Data Warehouse mit Microsoft- und Drittanbieter-Data Science-Technologien in Azure integrieren. In den folgenden Abschnitten werden maschinelles Lernen und Data Science-Technologien beschrieben, die von Microsoft angeboten werden, um zu sehen, wie sie mit Azure Synapse in einer modernen Data Warehouse-Umgebung verwendet werden können.
Microsoft-Technologien für Data Science in Azure
Microsoft bietet eine Reihe von Technologien, die die Vorausanalyse unterstützen. Mit diesen Technologien können Sie prädiktive analytische Modelle mithilfe von maschinellem Lernen erstellen oder unstrukturierte Daten mithilfe von Deep Learning analysieren. Die Technologien umfassen:
Azure Machine Learning Studio
Azure Machine Learning
Azure Synapse Spark-Pool-Notebooks
ML.NET (API, CLI oder .NET Model Builder für Visual Studio)
.NET für Apache Spark
Data Scientists können anhand von RStudio (R) und Jupyter Notebooks (Python) analytische Modelle entwickeln. Alternativ können sie auch Frameworks wie Keras oder TensorFlow verwenden.
Tipp
Entwickeln Sie Machine Learning-Modelle mit einem No/Low-Code-Ansatz oder durch Verwendung von Programmiersprachen wie Python, R und .NET.
Azure Machine Learning Studio
Azure Machine Learning Studio ist ein vollständig verwalteter Clouddienst, mit dem Sie Vorhersageanalysen über eine webbasierte Drag-and-Drop-Benutzeroberfläche erstellen, bereitstellen und freigeben können. Der folgende Screenshot zeigt die Azure Machine Learning Studio-Benutzeroberfläche.

Azure Machine Learning
Azure Machine Learning bietet ein SDK und Dienste für Python, die Ihnen helfen können, Daten schnell vorzubereiten und auch Machine Learning-Modelle bereitzustellen. Sie können Azure Machine Learning in Azure-Notebooks mit Jupyter Notebook verwenden, mit Open-Source-Frameworks wie PyTorch, TensorFlow, scikit-learn oder Spark MLlib – der Machine Learning-Bibliothek für Spark.
Tipp
Azure Machine Learning bietet ein SDK für die Entwicklung von Machine Learning-Modellen mithilfe mehrerer Open-Source-Frameworks.
Mit dieser Lösung können Sie auch Azure Machine Learning verwenden, um Pipelines für maschinelles Lernen erstellen, die End-to-End-Workflows verwalten, programmgesteuert in der Cloud skalieren und Modelle sowohl in der Cloud als auch im Edge bereitstellen. Azure Machine Learning enthält Arbeitsbereiche, die logische Bereiche sind, die Sie programmgesteuert oder manuell im Azure-Portal erstellen können. In diesen Arbeitsbereichen werden Computeziele, Experimente, Datenspeicher, trainierte Machine Learning-Modelle, Docker-Images und bereitgestellte Dienste an einem zentralen Ort verwaltet, um die Zusammenarbeit von Teams zu ermöglichen. Sie können Azure Machine Learning in Visual Studio mit der Visual Studio for AI-Erweiterung verwenden.
Tipp
Organisieren und verwalten Sie verknüpfte Datenspeicher, Experimente, trainierte Modelle, Docker-Images und bereitgestellte Dienste in Arbeitsbereichen.
Azure Synapse Spark-Pool-Notebooks
Ein Azure Synapse Spark Pool-Notebook ist ein Azure-optimierter Apache Spark-Dienst. Mit Azure Synapse Spark-Pool-Notebooks:
Können Data Engineers skalierbare Datenaufbereitungsaufträge mithilfe von Azure Data Factory erstellen und ausführen.
Können Data Scientists mithilfe von Notebooks in Sprachen wie Scala, R, Python, Java und SQL im großen Stil Machine Learning-Modelle erstellen und ausführen, um Ergebnisse zu visualisieren.
Tipp
Azure Synapse Spark ist ein dynamisch skalierbares Spark-as-a-Service-Angebot von Microsoft. Spark bietet eine skalierbare Ausführung der Datenaufbereitung, Modellentwicklung und bereitgestellten Modellen.
Aufträge, die im Azure Synapse Spark-Pool-Notebook ausgeführt werden, können Daten aus Azure Blob Storage, Data Lake Storage, Azure Synapse, HDInsight und Streamingdatendiensten wie Apache Kafka im großen Stil abrufen, verarbeiten und analysieren.
Tipp
Azure Synapse Spark kann auf Daten in einer Reihe von Datenspeichern des Analyse-Ökosystems von Microsoft in Azure zugreifen.
Azure Synapse Spark-Pool-Notebooks unterstützen die automatische Skalierung und automatische Beendigung, um die Gesamtkosten des Besitzes (TCO) zu verringern. Data Scientists können das Open-Source-Framework für MLflow verwenden, um den Lebenszyklus für maschinelles Lernen zu verwalten.
ML.NET
ML.NET ist ein plattformübergreifendes Open Source-Framework für maschinelles Lernen für Windows, Linux, macOS. Microsoft hat ML.NET erstellt, damit .NET-Entwickler vorhandene Tools wie ML.NET Model Builder für Visual Studio verwenden können, um benutzerdefinierte maschinelle Lernmodelle zu entwickeln und sie in ihre .NET-Anwendungen zu integrieren.
Tipp
Microsoft hat seine Machine Learning-Funktion auf .NET-Entwickler erweitert.
.NET für Apache Spark
.NET für Apache Spark erweitert Spark-Support über R, Scala, Python und Java auf .NET und zielt darauf ab, Spark für .NET-Entwickler in allen Spark-APIs zugänglich zu machen. Während .NET für Apache Spark derzeit nur in Apache Spark in HDInsight verfügbar ist, beabsichtigt Microsoft, .NET für Apache Spark auf Azure Synapse Spark-Pool-Notebooks verfügbar zu machen.
Verwenden von Azure Synapse Analytics mit Ihrem Data Warehouse
Um Machine Learning-Modelle mit Azure Synapse zu kombinieren, können Sie:
Machine Learning-Modelle im Batchmodus oder in Echtzeit auf Streaming Daten verwenden, um neue Erkenntnisse zu erzeugen und diese Erkenntnisse zu bereits bekannten in Azure Synapse hinzuzufügen.
Daten in Azure Synapse verwenden, um neue prädiktive Modelle für die Bereitstellung an anderer Stelle zu entwickeln und zu trainieren, z. B. in anderen Anwendungen.
Machine Learning-Modelle in Azure Synapse bereitstellen, einschließlich Modelle, die an anderer Stelle trainiert wurden, um Daten in Ihrem Data Warehouse zu analysieren und neue Geschäftsvorteile zu schaffen.
Tipp
Im Azure Synapse Spark-Pool-Notebook können Sie mithilfe von Daten in Azure Synapse im großen Stil Machine Learning-Modelle trainieren, testen, bewerten und ausführen.
Data Scientists können RStudio, Jupyter Notebooks und Azure Synapse Spark-Pool-Notebooks zusammen mit Azure Machine Learning verwenden, um Machine Learning-Modelle zu entwickeln, die in Azure Synapse Spark-Pool-Notebooks im großen Stil mit Daten in Azure Synapse ausgeführt werden. Beispielsweise könnten Data Scientists ein unbeaufsichtigtes Modell erstellen, um Kunden zu segmentieren und verschiedene Marketingkampagnen zu unterstützen. Mithilfe des überwachten maschinellen Lernens können Sie ein Modell trainieren, um ein bestimmtes Ergebnis vorherzusagen. So kann beispielsweise die Abwanderungsneigung eines Kunden prognostiziert werden. Einem Kunden könnte auch das nächstbeste Angebot (Next Best Offer) empfohlen werden, um seinen Wert für das Unternehmen zu steigern. Im folgenden Diagramm sehen Sie, wie Azure Synapse für Azure Machine Learning genutzt werden kann.
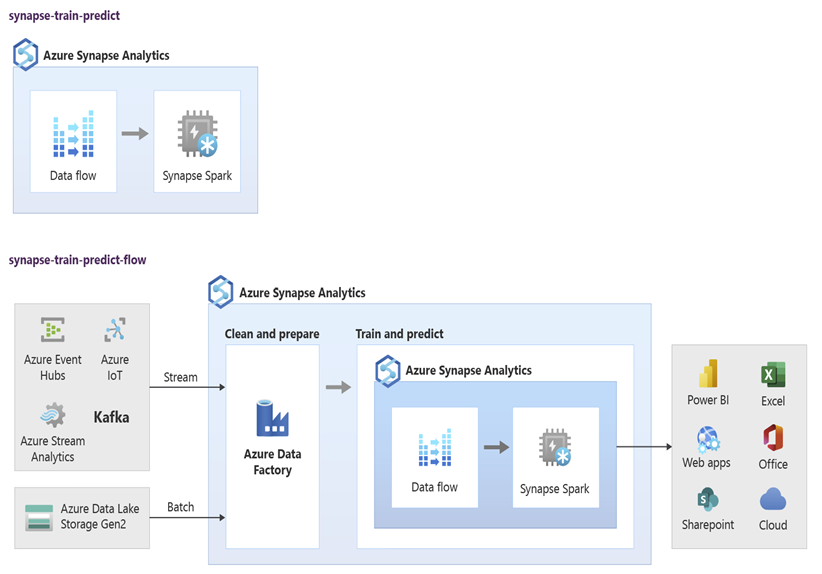
In einem anderen Szenario können Sie Daten aus sozialen Netzwerken oder von Review-Websites in Azure Data Lake Storage erfassen. Anschließend können Sie die Daten im Azure Synapse Spark-Pool-Notebook mit der Verarbeitung natürlicher Sprache im großen Stil aufbereiten und analysieren, um die Kundenstimmung zu Ihren Produkten oder Ihrer Marke einzuschätzen. Anschließend können Sie diese Bewertungen ihrem Data Warehouse hinzufügen. Mithilfe von Big Data-Analysen können Sie den Effekt negativer Stimmung auf den Produktumsatz verstehen, des Sie bereits in Ihrem Data Warehouse kennen.
Tipp
Generieren Sie neue Erkenntnisse mithilfe von maschinellem Lernen in Azure im Batch oder in Echtzeit und fügen Sie vorhandene Erkenntnisse Ihrem Data Warehouse hinzu.
Integrieren von Livestreamingdaten in Azure Synapse Analytics
Beim Analysieren von Daten in einem modernen Data Warehouse müssen Sie Streamingdaten in Echtzeit analysieren und mit historischen Daten in Ihrem Data Warehouse verknüpfen können. Ein Beispiel ist die Kombination von IoT-Daten mit Produkt- oder Objektdaten.
Tipp
Integrieren Sie Ihr Data Warehouse mit Streamingdaten aus IoT-Geräten oder Clickstreams.
Nachdem Sie Ihr Data Warehouse erfolgreich zu Azure Synapse migriert haben, können Sie die Livestreaming-Datenintegration als Teil einer Data Warehouse-Modernisierungsübung einführen, indem Sie die zusätzliche Funktionalität in Azure Synapse nutzen. Dazu erfassen Sie Streamingdaten über Event Hubs, andere Technologien wie Apache Kafka oder potenziell Ihr vorhandenes ETL-Tool, wenn es die Streamingdatenquellen unterstützt. Speichern Sie die Daten in Data Lake Storage. Erstellen Sie dann eine externe Tabelle in Azure Synapse mithilfe von PolyBase und zeigen Sie sie auf die Daten, die in Data Lake Storage übertragen werden, damit Ihr Data Warehouse jetzt neue Tabellen enthält, die Zugriff auf die Echtzeitstreamingdaten bieten. Die externe Tabelle können Sie in beliebigen BI-Tools mit Zugriff auf Azure Synapse über Standard-T-SQL abfragen, als würden sich die Daten im Data Warehouse befinden. Sie können die Streamingdaten auch mit anderen Tabellen mit historischen Daten verknüpfen, um Ansichten zu erstellen, die Livestreamingdaten mit historischen Daten verknüpfen, damit Geschäftsbenutzer leichter auf die Daten zugreifen können.
Tipp
Erfassen Sie Streamingdaten aus Azure Event Hubs oder Apache Kafka in Data Lake Storage, und greifen Sie über Azure Synapse mithilfe externer PolyBase-Tabellen auf die Daten zu.
Im folgenden Diagramm wird ein Echtzeit-Data-Warehouse in Azure Synapse mit Streamingdaten in Data Lake Storage integriert.
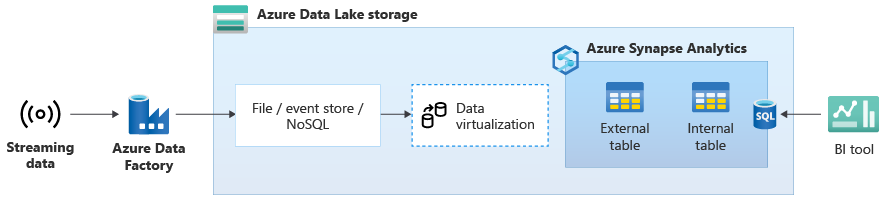
Erstellen eines logischen Data Warehouse mit PolyBase
Mit von PolyBase können Sie ein logisches Data Warehouse erstellen, um den Zugriff auf mehrere analytische Datenspeicher für Benutzer zu vereinfachen. Viele Unternehmen haben in den letzten Jahren zusätzlich zu ihren Data Warehouses „workloadoptimierte“ analytische Datenspeicher implementiert. Die analytischen Plattformen in Azure umfassen:
Azure Data Lake Storage mit Azure Synapse Spark-Pool-Notebook (Spark-as-a-Service), für Big Data-Analysen.
HDInsight (Hadoop-as-a-Service), auch für Big Data-Analysen.
NoSQL-Graphdatenbanken für die Graphanalyse, die in Azure Cosmos DB ausgeführt werden kann.
Event Hubs und Stream Analytics für die Echtzeitanalyse von Daten während der Übertragung.
Möglicherweise verfügen Sie auch über nicht-Microsoft Äquivalente dieser Plattformen oder ein Masterdatenverwaltungssystem (MDM), auf das zugegriffen werden muss, um konsistente vertrauenswürdige Daten für Kunden, Lieferanten, Produkte, Ressourcen und vieles mehr zu erhalten.
Tipp
PolyBase vereinfacht den Zugriff auf mehrere zugrunde liegende analytische Datenspeicher in Azure, um den Zugriff durch Geschäftsbenutzer zu vereinfachen.
Diese analytischen Plattformen entstanden aufgrund der Explosion neuer Datenquellen innerhalb und außerhalb des Unternehmens und der Nachfrage von Geschäftsbenutzern, die neuen Daten zu erfassen und zu analysieren. Die neuen Datenquellen umfassen:
Computergenerierte Daten, z. B. IoT-Sensordaten und Clickstreamdaten.
Von Menschen generierte Daten, z. B. Daten in sozialen Netzwerken, Daten von Review-Websites, eingehende E-Mails von Kunden, Bilder und Videos
Andere externe Daten, z. B. offen verfügbare Behördendaten und Wetterdaten.
Diese neuen Daten gehen über die strukturierten Transaktionsdaten und Hauptdatenquellen hinaus, die in der Regel Data Warehouses versorgen und häufig enthalten:
- Semistrukturierte Daten wie JSON, XML oder Avro.
- Unstrukturierte Daten wie Text, Stimme, Bild oder Video, die komplexer zu verarbeiten und zu analysieren sind.
- Daten mit großem Volumen, großer Geschwindigkeit oder beidem.
Daher sind neue Arten komplexerer Analysen entstanden, z. B. natürliche Sprachverarbeitung, Graphanalysen, Deep Learning, Streaminganalysen oder komplexe Analysen großer Mengen strukturierter Daten. Diese Analysearten werden in der Regel nicht in einem Data Warehouse durchgeführt. Daher ist es nicht überraschend, dass unterschiedliche analytische Plattformen für verschiedene Arten von Analyseworkloads verwendet werden (siehe Diagramm).
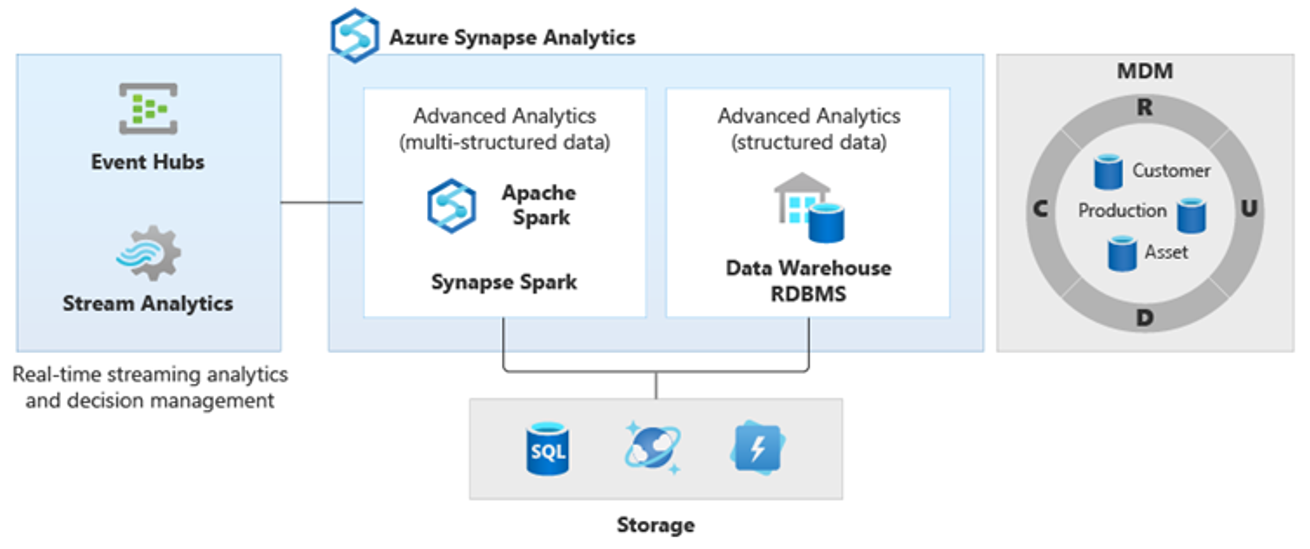
Tipp
In einer logischen Data Warehouse-Architektur können Daten aus mehreren analytischen Datenspeichern so angezeigt werden, als würden sie sich in einem einzelnen System befinden. Sie können außerdem mit Azure Synapse verknüpft werden.
Da diese Plattformen neue Erkenntnisse erzeugen, ist es normal, die neuen Erkenntnisse mit dem zu kombinieren, das Sie bereits in Azure Synapse kennen. Dies wird durch PolyBase ermöglicht.
Mithilfe der PolyBase-Datenvirtualisierung innerhalb Azure Synapse können Sie ein logisches Data Warehouse implementieren, in dem Daten in Azure Synapse daten in anderen Azure- und lokalen analytischen Datenspeichern wie HDInsight, Azure Cosmos DB oder Streamingdaten in Data Lake Storage von Stream Analytics oder Event Hubs eingebunden werden. Dieser Ansatz verringert die Komplexität für Benutzer, die auf externe Tabellen in Azure Synapse zugreifen und nicht wissen müssen, dass die Daten, auf die sie zugreifen, in mehreren zugrunde liegenden analytischen Systemen gespeichert sind. Das folgende Diagramm zeigt eine komplexe Data Warehouse-Struktur, auf die durch vergleichsweise einfachere, aber dennoch effektive Vorgehensweisen auf der Benutzeroberfläche zugegriffen werden kann.
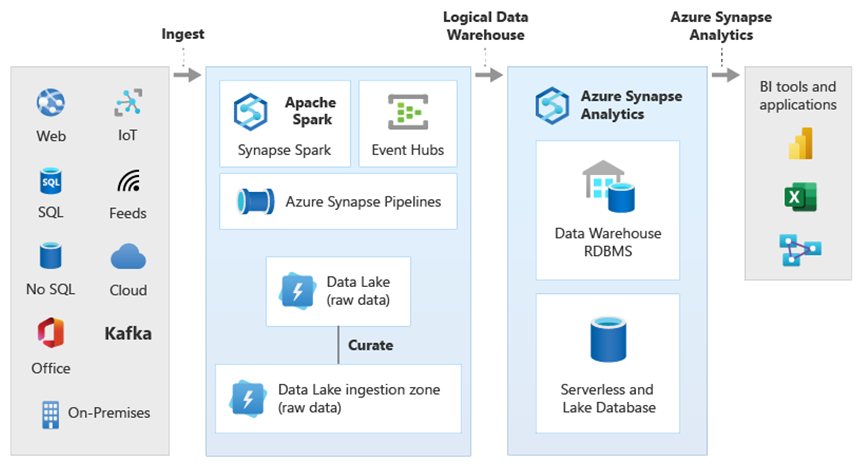
Das Diagramm zeigt, wie andere Technologien des Analyse-Ökosystems von Microsoft mit der Funktionalität der logischen Data Warehouse-Architektur in Azure Synapse kombiniert werden können. Beispielsweise können Sie Daten in Data Lake Storage erfassen und mit Data Factory zusammenstellen, um vertrauenswürdige Datenprodukte zu erstellen, die logische Datenentitäten der Microsoft Lake-Datenbank darstellen. Diese vertrauenswürdigen, leicht verständlichen Daten können dann in verschiedenen analytischen Umgebungen wie Azure Synapse, Azure Synapse Spark-Pool-Notebooks oder Azure Cosmos DB verwendet und wiederverwendet werden. Alle in diesen Umgebungen erzeugten Erkenntnisse sind über eine logische Data Warehouse-Datenvirtualisierungsebene zugänglich, die von PolyBase bereitgestellt wird.
Tipp
Durch eine logische Data Warehouse-Architektur wird der Zugriff von Geschäftsbenutzern auf Daten vereinfacht. Bestehende Erkenntnissen in Ihrem Data Warehouse erhalten einen neuen Mehrwert.
Zusammenfassung
Nachdem Sie Ihr Data Warehouse zu Azure Synapse Analytics migriert haben, können Sie die Vorteile anderer Technologien im Analyse-Ökosystem von Microsoft nutzen. Dadurch modernisieren Sie nicht nur Ihr Data Warehouse, sondern Sie bringen auch Erkenntnisse aus anderen analytischen Azure-Datenspeichern in einer integrierten analytischen Architektur zusammen.
Sie können Ihre ETL-Verarbeitung erweitern, um Daten aller Art in Data Lake Storage zu erfassen und diese dann im großen Stil mit Data Factory vorzubereiten und zu integrieren, um vertrauenswürdige, allgemein verstandene Datenressourcen zu erzeugen. Diese Ressourcen können von Ihrem Data Warehouse aufgenommen und von Data Scientists und anderen Anwendungen abgerufen werden. Sie können echtzeit- und batchorientierte Analysepipelines sowie Machine Learning-Modelle erstellen, die im Batch, in Echtzeit für Streamingdaten und bedarfsgesteuert als Dienst ausgeführt werden können.
Sie können mit PolyBase oder COPY INTO die Grenzen Ihres Data Warehouse überschreiten, um den Zugriff auf Erkenntnisse mehrerer zugrunde liegender Analyseplattformen in Azure zu vereinfachen. Hierzu erstellen Sie ganzheitliche integrierte Sichten in einem logischen Data Warehouse, um Streaming, Big Data und herkömmliche Data Warehouse-Einblicke aus BI-Tools und -Anwendungen zu unterstützen.
Indem Sie Ihr Data Warehouse zu Azure Synapse migrieren, können Sie das umfassende analytische Ökosystem von Microsoft nutzen, das auf Azure ausgeführt wird, um neuen Wert in Ihrem Unternehmen zu fördern.
Nächste Schritte
Weitere Informationen finden Sie unter Migrieren eines Data Warehouse zu einem dedizierten SQL-Pool in Azure Synapse Analytics.