Einführung in die Mount/Unmount-APIs in Azure Synapse Analytics
Das Azure Synapse Studio-Team hat zwei neue Mount/Unmount-APIs im Microsoft Spark Utilities- (mssparkutils) Paket erstellt. Sie können diese APIs verwenden, um Remotespeicher (Azure Blob Storage oder Azure Data Lake Storage Gen2) an alle funktionierenden Knoten (Treiberknoten oder Arbeiterknoten) anzuhängen. Wenn der Speicher vorhanden ist, können Sie die lokale Datei-API verwenden, um auf Daten zuzugreifen, als ob sie im lokalen Dateisystem gespeichert ist. Weitere Informationen finden Sie unter Einführung in Microsoft Spark-Hilfsprogramme.
Der Artikel zeigt, wie Sie Mount/Unmount-APIs in Ihrem Arbeitsbereich verwenden. Sie lernen Folgendes:
- Einbinden von Data Lake Storage Gen2 oder Blob Storage.
- Zugreifen auf Dateien unter einem Bereitstellungspunkt über die lokale Dateisystem-API.
- Zugreifen auf Dateien unter einem Bereitstellungspunkt über die
mssparktuils fs-API. - Zugreifen auf Dateien unter einem Bereitstellungspunkt über die Spark-Lese-API.
- Aufheben der Einbindung eines Bereitstellungspunkts
Warnung
Die Bereitstellung von Azure-Dateifreigaben ist vorübergehend deaktiviert. Sie können stattdessen Data Lake Storage Gen2 oder Azure Blob Storage Montage verwenden, wie im nächsten Abschnitt beschrieben.
Data Lake Storage Gen1 wird nicht unterstützt. Sie können zu Data Lake Storage Gen2 migrieren, indem Sie der Migrationsanleitungen von Azure Data Lake Storage Gen1 zu Gen2 folgen, bevor Sie die Bereitstellungs-APIs verwenden.
Speicher einbinden
In diesem Abschnitt wird als Beispiel veranschaulicht, wie Sie Data Lake Storage Gen2 Schritt für Schritt einbinden. Das Einbinden von Blob Storage funktioniert ähnlich.
Im Beispiel wird davon ausgegangen, dass Sie über ein Data Lake Storage Gen2-Konto mit dem Namen storegen2 verfügen. Das Konto verfügt über einen Container mit dem Namen mycontainer, den Sie für /test in Ihrem Spark-Pool bereitstellen möchten.
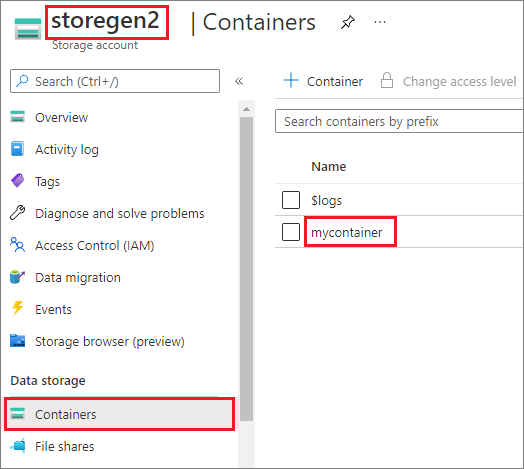
Zum Einbinden des Containers namens mycontainer muss mssparkutils zuerst überprüfen, ob Sie über die Berechtigung zum Zugreifen auf den Container verfügen. Derzeit unterstützt Azure Synapse Analytics drei Authentifizierungsmethoden für den Trigger-Mount-Vorgang: linkedService, accountKeyund sastoken.
Einbinden mithilfe eines verknüpften Dienstes (empfohlen)
Es wird empfohlen, eine Trigger-Bereitstellung über einen verknüpften Dienst zu erstellen. Diese Methode verhindert Sicherheitslecks, da mssparkutils selbst keine Geheimnis- oder Authentifizierungswerte speichert. Stattdessen ruft mssparkutils immer Authentifizierungswerte vom verknüpften Dienst ab, um Blob-Daten aus einem Remotespeicher anzufordern.
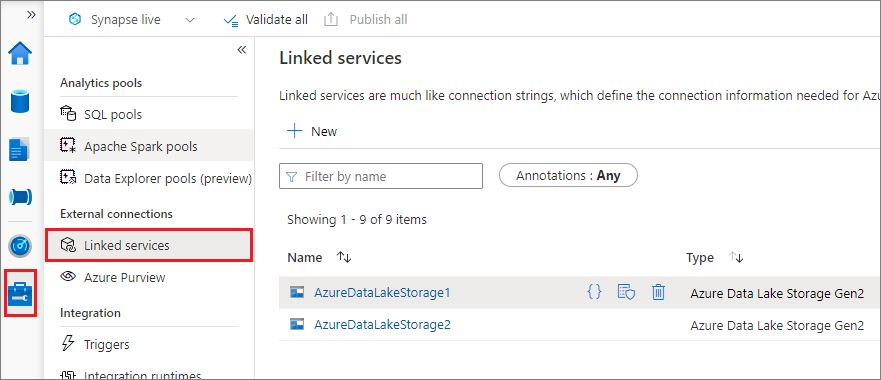
Sie können einen verknüpften Dienst für Data Lake Storage Gen2 oder Blob Storage erstellen. Derzeit unterstützt Azure Synapse Analytics zwei Authentifizierungsmethoden, wenn Sie einen verknüpften Dienst erstellen:
Erstellen eines verknüpften Diensts mithilfe eines Kontoschlüssels

Erstellen eines verknüpften Diensts mithilfe einer vom System zugewiesenen verwalteten Identität
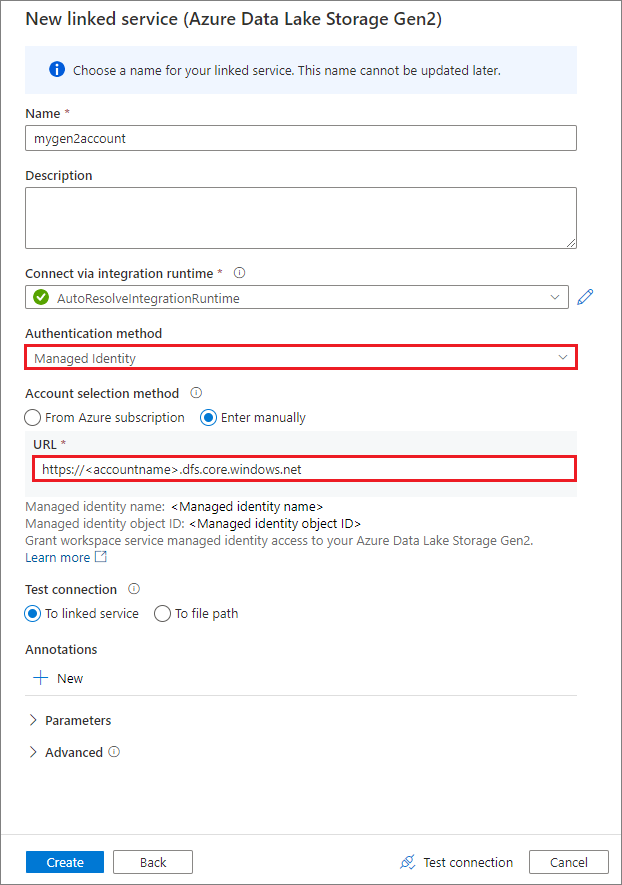
Wichtig
- Wenn der oben erstellte verknüpfte Dienst für Azure Data Lake Storage Gen2 einen verwalteten privaten Endpunkt (mit einem dfs-URI) verwendet, müssen wir einen weiteren sekundären verwalteten privaten Endpunkt mithilfe der Option „Azure Blob Storage“ (mit einem BLOB-URI) erstellen, um sicherzustellen, dass der interne fsspec/adlfs-Code eine Verbindung mithilfe der BlobServiceClient-Schnittstelle herstellen kann.
- Falls der sekundäre verwaltete private Endpunkt nicht ordnungsgemäß konfiguriert ist, wird eine Fehlermeldung wie ServiceRequestError: Es kann keine Verbindung mit dem Host [storageaccountname].blob.core.windows.net:443 ssl:True hergestellt werden [Name oder Dienst nicht bekannt] angezeigt.
Hinweis
Wenn Sie einen verknüpften Dienst mithilfe einer verwalteten Identität als Authentifizierungsmethode erstellen, müssen Sie sicherstellen, dass die Arbeitsbereichs-MSI über die Rolle „Mitwirkender an Storage-Blobdaten“ für den eingebundenen Container verfügt.
Nachdem Sie den verknüpften Dienst erfolgreich erstellt haben, können Sie den Container ganz einfach mit dem folgenden Python-Code in Ihren Spark-Pool einbinden.
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService": "mygen2account"}
)
Hinweis
Möglicherweise müssen Sie mssparkutils importieren, wenn es noch nicht verfügbar ist:
from notebookutils import mssparkutils
Es wird nicht empfohlen, einen Stammordner bereitzustellen, unabhängig davon, welche Authentifizierungsmethode Sie verwenden.
Einbindungsparameter:
- fileCacheTimeout: Blobs werden standardmäßig 120 Sekunden lang im lokalen temporären Ordner zwischengespeichert. Während dieser Zeit prüft BlobFuse nicht, ob die Datei aktuell ist. Der Parameter kann so festgelegt werden, dass die Standardtimeoutzeit geändert wird. Wenn mehrere Clients gleichzeitig Dateien ändern, empfiehlt es sich, die Cachezeit zu verkürzen oder sogar auf 0 zu ändern und immer die neuesten Dateien vom Server abzurufen, um Inkonsistenzen zwischen lokalen Dateien und Remotedateien zu vermeiden.
- Timeout: Das Timeout des Einbindungsvorgangs beträgt standardmäßig 120 Sekunden. Der Parameter kann so festgelegt werden, dass die Standardtimeoutzeit geändert wird. Wenn zu viele Executors vorhanden sind oder bei der Einbindung ein Timeout auftritt, empfiehlt es sich, den Wert zu erhöhen.
- scope: Der scope-Parameter wird verwendet, um den Einbindungsbereich anzugeben. Der Standardwert ist „job“. Wenn der Bereich auf „job“ festgelegt ist, ist die Einbindung nur für den aktuellen Cluster sichtbar. Ist der Bereich auf „workspace“ festgelegt, ist die Einbindung für alle Notebooks im aktuellen Arbeitsbereich sichtbar, und der Bereitstellungspunkt wird automatisch erstellt, sofern er nicht vorhanden ist. Fügen Sie der API zum Aufheben der Einbindung dieselben Parameter hinzu, um die Einbindung des Bereitstellungspunkts aufzuheben. Die Einbindung auf Arbeitsbereichsebene wird nur für die verknüpfte Dienstauthentifizierung unterstützt.
Sie können diese Parameter wie folgt verwenden:
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"linkedService":"mygen2account", "fileCacheTimeout": 120, "timeout": 120}
)
Einbinden über SAS-Token (Shared Access Signature) oder Kontoschlüssel
Zusätzlich zur Einbindung über einen verknüpften Dienst unterstützt mssparkutils die explizite Übergabe eines Kontoschlüssels oder eines SAS-Tokens (Shared Access Signature) als Parameter zum Einbinden des Ziels.
Aus Sicherheitsgründen empfehlen wir, Kontoschlüssel oder SAS-Token in Azure Key Vault zu speichern (wie im folgenden Beispiel gezeigt). Sie können sie dann mithilfe der mssparkutil.credentials.getSecret-API abrufen. Weitere Informationen finden Sie unter Verwalten von Speicherkontoschlüsseln mit Key Vault und der Azure-Befehlszeilenschnittstelle (Legacy).
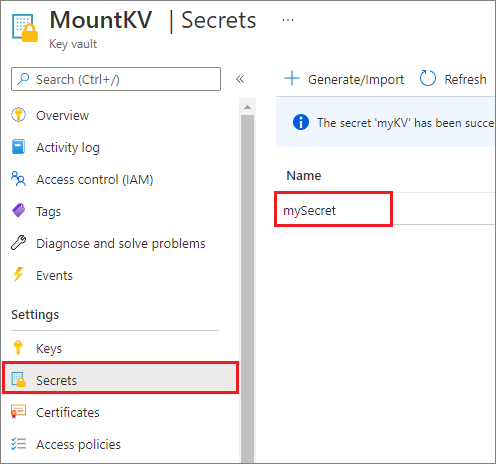
Sehen Sie sich den Beispielcode an:
from notebookutils import mssparkutils
accountKey = mssparkutils.credentials.getSecret("MountKV","mySecret")
mssparkutils.fs.mount(
"abfss://mycontainer@<accountname>.dfs.core.windows.net",
"/test",
{"accountKey":accountKey}
)
Hinweis
Speichern Sie aus Sicherheitsgründen keine Anmeldeinformationen im Code.
Zugreifen auf Dateien unter dem Bereitstellungspunkt mithilfe der mssparktuils fs-API
Der Hauptzweck des Einbindungsvorgangs ist, Kunden den Zugriff auf Daten zu ermöglichen, die in einem Remotespeicherkonto gespeichert sind, indem sie eine lokale Dateisystem-API verwenden. Sie können auch auf die Daten zugreifen, indem Sie die mssparkutils fs-API mit einem bereitgestellten Pfad als Parameter verwenden. Das hier verwendete Pfadformat weicht davon etwas ab.
Angenommen, Sie haben den Data Lake Storage Gen2-Container mycontainer mithilfe der Bereitstellungs-API in /test bereitgestellt. Beim Zugriff auf die Daten über eine lokale Dateisystem-API:
- Für Spark-Versionen kleiner als oder gleich 3.3 ist
/synfs/{jobId}/test/{filename}das Pfadformat. - Bei Spark-Versionen größer als oder gleich 3.4 ist
/synfs/notebook/{jobId}/test/{filename}das Pfadformat.
Es wird empfohlen, über mssparkutils.fs.getMountPath() den genauen Pfad abzurufen:
path = mssparkutils.fs.getMountPath("/test")
Hinweis
Wenn Sie den Speicher mit workspace Bereich bereitstellen, wird der Bereitstellungspunkt unter dem /synfs/workspace Ordner erstellt. Und Sie müssen verwenden mssparkutils.fs.getMountPath("/test", "workspace") , um den genauen Pfad zu erhalten.
Wenn Sie mithilfe der mssparkutils fs API auf die Daten zugreifen möchten, ist das Pfadformat wie folgt: synfs:/notebook/{jobId}/test/{filename} Wie Sie sehen können, wird in diesem Fall synfs anstelle eines Teils des Pfads des Bereitstellungspfads als Schema verwendet. Natürlich können Sie auch das lokale Dateisystemschema verwenden, um auf die Daten zuzugreifen. Beispiel: file:/synfs/notebook/{jobId}/test/{filename}.
In den folgenden drei Beispielen wird gezeigt, wie Sie mithilfe eines Bereitstellungspunktpfads mit mssparkutils fs auf eine Datei zugreifen.
Auflisten von Verzeichnissen:
mssparkutils.fs.ls(f'file:{mssparkutils.fs.getMountPath("/test")}')Lesen von Dateiinhalten:
mssparkutils.fs.head(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv')Erstellen eines Verzeichnisses:
mssparkutils.fs.mkdirs(f'file:{mssparkutils.fs.getMountPath("/test")}/myDir')
Zugreifen auf Dateien unter einem Bereitstellungspunkt über die Spark-Lese-API
Sie können einen Parameter bereitstellen, um über die Spark-Lese-API auf die Daten zuzugreifen. Das Pfadformat hier ist identisch, wenn Sie die mssparkutils fs API verwenden.
Lesen einer Datei aus einem bereitgestellten Data Lake Storage Gen2 Speicherkonto
Im folgenden Beispiel wird davon ausgegangen, dass ein Data Lake Storage Gen2-Speicherkonto bereits bereitgestellt wurde und Sie dann die Datei mithilfe eines Bereitstellungspfads lesen:
%%pyspark
df = spark.read.load(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.csv', format='csv')
df.show()
Hinweis
Wenn Sie den Speicher mithilfe eines verknüpften Diensts einbinden, sollten Sie die Konfiguration des verknüpften Spark-Diensts immer explizit festlegen, bevor Sie das synfs-Schema verwenden, um auf die Daten zuzugreifen. Ausführliche Informationen finden Sie unter ADLS Gen2-Speicher mit verknüpften Diensten.
Lesen einer Datei in einem eingebundenen Blob Storage-Konto
Wenn Sie ein Blob Storage-Konto eingebunden haben und dann über mssparkutils oder die Spark-API darauf zugreifen möchten, müssen Sie das SAS-Token zunächst explizit über die Spark-Konfiguration konfigurieren, bevor Sie den Container mithilfe der Bereitstellungs-API einbinden können.
Um auf ein Blob Storage-Konto mithilfe von
mssparkutilsoder der Spark API nach einem Trigger-Mount zuzugreifen, aktualisieren Sie die Spark-Konfiguration wie im folgenden Codebeispiel gezeigt. Sie können diesen Schritt umgehen, wenn Sie nach der Bereitstellung nur mithilfe der lokalen Datei-API auf die Spark-Konfiguration zugreifen möchten.blob_sas_token = mssparkutils.credentials.getConnectionStringOrCreds("myblobstorageaccount") spark.conf.set('fs.azure.sas.mycontainer.<blobStorageAccountName>.blob.core.windows.net', blob_sas_token)Erstellen Sie den verknüpften Dienst
myblobstorageaccountund binden Sie das Blob Storage-Konto mithilfe des verknüpften Diensts ein:%%spark mssparkutils.fs.mount( "wasbs://mycontainer@<blobStorageAccountName>.blob.core.windows.net", "/test", Map("linkedService" -> "myblobstorageaccount") )Binden Sie den Blob Storage-Container ein und lesen Sie dann die Datei mithilfe des Bereitstellungspfads über die lokale Datei-API:
# mount the Blob Storage container, and then read the file by using a mount path with open(mssparkutils.fs.getMountPath("/test") + "/myFile.txt") as f: print(f.read())Lesen Sie die Daten aus dem bereitgestellten Blob Storage-Container über die Spark-Lese-API:
%%spark // mount blob storage container and then read file using mount path val df = spark.read.text(f'file:{mssparkutils.fs.getMountPath("/test")}/myFile.txt') df.show()
Aufheben des Bereitstellungspunkts
Verwenden Sie den folgenden Code, um Ihren Bereitstellungspunkt (/test in diesem Beispiel) aufzuheben:
mssparkutils.fs.unmount("/test")
Bekannte Einschränkungen
Der Mechanismus für die Aufhebung der Bereitstellung ist nicht automatisch. Wenn die Ausführung der Anwendung beendet ist, müssen, Sie, um den Bereitstellungspunkt aufzuheben, um den Speicherplatz freizugeben, explizit eine Unmount-API in Ihrem Code aufrufen. Andernfalls ist der Bereitstellungspunkt weiterhin im Knoten vorhanden, nachdem die Anwendungsausführung beendet wurde.
Das Einbinden eines Data Lake Storage Gen1-Speicherkontos wird zurzeit nicht unterstützt.