Optimieren der Leistung durch ein Upgrade des dedizierten SQL-Pools (früher SQL DW) in Azure Synapse Analytics
Führen Sie ein Upgrade Ihres dedizierten SQL-Pools (früher SQL DW) auf die Azure-Hardware und -Speicherarchitektur der neuesten Generation durch.
Gründe für ein Upgrade
In unterstützten Regionen können Sie jetzt im Azure-Portal ein Upgrade auf die Stufe „Optimiert für Compute Gen2“ für dedizierte SQL-Pools (früher SQL DW) nahtlos durchführen. Wenn Ihre Region kein Selbstupgrade unterstützt, können Sie ein Upgrade auf eine unterstützte Region durchführen oder warten, bis das Selbstupgrade in Ihrer Region verfügbar wird. Aktualisieren Sie jetzt, um die neueste Generation der Azure-Hardware sowie eine erweiterte Speicherarchitektur mit schnellerer Leistung, höherer Skalierbarkeit und unbegrenztem spaltenorientiertem Speicher zu nutzen.
Wichtig
Dieses Upgrade gilt in unterstützten Regionen für dedizierte SQL-Pools (früher SQL DW) der Stufe „Für Compute optimiert Gen1“.
Voraussetzungen
Überprüfen Sie, ob Ihre Region für die Migration von GEN1 zu GEN2 unterstützt wird. Beachten Sie die Datumsangaben für die automatische Migration. Um Konflikte mit dem automatisierten Vorgang zu vermeiden, planen Sie Ihre manuelle Migration vor dem Startdatum für den automatisierten Prozess.
Wenn Sie sich in einer Region befinden, die noch nicht unterstützt wird, prüfen Sie weiterhin, ob Ihre Region zwischenzeitlich hinzugefügt wurde, oder führen Sie das Upgrade durch Wiederherstellung in einer unterstützten Region durch.
Wenn Ihre Region unterstützt wird, führen Sie das Upgrade über das Azure-Portal durch.
Wählen Sie die vorgeschlagene Leistungsstufe für den dedizierten SQL-Pool (früher SQL DW) basierend auf Ihrer aktuellen Leistungsstufe für „Optimiert für Compute Gen1“ aus. Verwenden Sie dafür die folgende Zuordnung:
Stufe „Optimiert für Compute Gen 1“ Stufe „Optimiert für Compute Gen 2“ DW100 DW100c DW200 DW200c DW300 DW300c DW400 DW400c DW500 DW500c DW600 DW500c DW1000 DW1000c DW1200 DW1000c DW1500 DW1500c DW2000 DW2000c DW3000 DW3000c DW6000 DW6000c
Hinweis
Die vorgeschlagenen Leistungsstufen sind kein direkter Wechsel. Beispielsweise empfehlen wir die Umstellung von DW600 auf DW500c.
Upgrade in einer unterstützten Region über das Azure-Portal
- Die Migration von Gen1 zu Gen2 über das Azure-Portal ist dauerhaft. Es gibt keinen Vorgang für die Rückkehr zu Gen1.
- Für die Migration zu Gen2 muss der dedizierte SQL-Pool (früher SQL DW) ausgeführt werden.
Voraussetzungen
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
- Melden Sie sich beim Azure-Portal an.
- Stellen Sie sicher, dass der dedizierte SQL-Pool (früher SQL DW) ausgeführt wird. Dies ist erforderlich, damit er zu Gen2 migriert werden kann.
PowerShell-Upgradebefehle
Wenn der zu aktualisierende dedizierte SQL-Pool (früher SQL DW) der Stufe „Optimiert für Compute Gen1“ angehalten wird, setzen Sie den dedizierten SQL-Pool (früher SQL DW) fort.
Es tritt eine Ausfallzeit von einigen Minuten auf.
Identifizieren Sie alle Codeverweise auf die Leistungsebene „Optimiert für Compute Gen 1“, und ändern Sie sie in die entsprechende Leistungsebene „Optimiert für Compute Gen 2“. Nachstehend finden Sie zwei Beispiele, in denen Sie Codeverweise vor dem Upgrade aktualisieren sollten:
Ursprünglicher PowerShell-Befehl für Gen 1:
Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -DatabaseName "mySampleDataWarehouse" -ServerName "mynewserver-20171113" -RequestedServiceObjectiveName "DW300"Geändert in:
Set-AzSqlDatabase -ResourceGroupName "myResourceGroup" -DatabaseName "mySampleDataWarehouse" -ServerName "mynewserver-20171113" -RequestedServiceObjectiveName "DW300c"Hinweis
-RequestedServiceObjectiveName "DW300" wird geändert in: RequestedServiceObjectiveName "DW300c"
Ursprünglicher T-SQL-Befehl für Gen 1:
ALTER DATABASE mySampleDataWarehouse MODIFY (SERVICE_OBJECTIVE = 'DW300') ;Geändert in:
ALTER DATABASE mySampleDataWarehouse MODIFY (SERVICE_OBJECTIVE = 'DW300c') ;Hinweis
SERVICE_OBJECTIVE = 'DW300' wird geändert in: SERVICE_OBJECTIVE = 'DW300c'
Starten des Upgrades
Wechseln Sie im Azure-Portal zu Ihrem dedizierten SQL-Pool (früher SQL DW) der Stufe „Optimiert für Compute Gen1“. Wenn der zu aktualisierende dedizierte SQL-Pool (früher SQL DW) der Stufe „Optimiert für Compute Gen1“ angehalten wird, setzen Sie den dedizierten SQL-Pool fort.
Wählen Sie auf der Registerkarte Aufgaben die Karte Führen Sie ein Upgrade auf Gen2 durch! aus:
Hinweis
Wenn die Karte Upgrade auf Gen2 unter der Registerkarte „Aufgaben“ nicht angezeigt wird, ist Ihr Abonnementtyp in der aktuellen Region beschränkt. Senden Sie ein Supportticket, um Ihr Abonnement genehmigen zu lassen.
Stellen Sie sicher, dass die Ausführung Ihrer Workload abgeschlossen ist und die Workload stillgelegt wurde, bevor Sie das Upgrade durchführen. Bevor Ihr dedizierter SQL-Pool (früher SQL DW) wieder als dedizierter SQL-Pool (früher SQL DW) der Stufe „Optimiert für Compute Gen2“ online geschaltet wird, kommt es zu einer Downtime von einigen Minuten.
Wählen Sie Upgrade aus.
Überwachen Sie Ihr Upgrade, indem Sie den Status im Azure-Portal prüfen. Ihnen wird wahrscheinlich ein Banner mit der Meldung „Dieses Data Warehouse wird zurzeit auf Gen2 aktualisiert.“ angezeigt.
Der erste Schritt des Upgradeprozesses erfolgt im Skalierungsvorgang („Upgrade – Offline“), in dem alle Sitzungen gelöscht und Verbindungen getrennt werden.
Der zweite Schritt des Upgradeprozesses ist die Datenmigration („Upgrade – Online“). Die Datenmigration ist ein nach und nach im Hintergrund ausgeführter Onlineprozess. Bei diesem Vorgang werden spaltenbasierte Daten langsam aus der alten Speicherarchitektur über einen lokalen SSD-Cache in die neue Speicherarchitektur verschoben. Während dieser Zeit ist Ihr dedizierter SQL-Pool (früher SQL DW) für Abfrage- und Ladevorgänge online. Ihre Daten stehen für Abfragen zur Verfügung, unabhängig davon, ob sie bereits migriert wurden oder nicht. Die Datenmigration erfolgt mit wechselnder Geschwindigkeit je nach Größe Ihrer Daten, Ihrer Leistungsstufe und der Anzahl Ihrer Columnstore-Segmente.
Optionale Empfehlung: Sobald der Skalierungsvorgang abgeschlossen ist, können Sie den Hintergrundvorgang der Datenmigration beschleunigen. Sie können die Datenverschiebung erzwingen, indem Sie ALTER INDEX ... REBUILD für alle primären Columnstore-Tabellen ausführen, die Sie bei einer höheren SLO- und Ressourcenklasse abfragen würden. Dieser Vorgang erfolgt offline und beeinträchtigt oder blockiert andere Abfragen. Gleichzeitig wird er aber schneller abgeschlossen als der allmählich im Hintergrund ausgeführte Prozess, der je nach Anzahl und Größe Ihrer Tabellen Stunden dauern kann. Allerdings verläuft die Datenmigration nach Abschluss des Vorgangs möglicherweise viel schneller aufgrund der neuen erweiterten Speicherarchitektur mit hochwertigen Zeilengruppen.
Hinweis
ALTER INDEX REBUILD ist ein Offlinevorgang, und die Tabellen stehen erst dann zur Verfügung, wenn die Wiederherstellung abgeschlossen ist.
Die folgende Abfrage generiert die erforderlichen ALTER INDEX ... REBUILD-Befehle, um die Datenmigration zu beschleunigen:
SELECT 'ALTER INDEX [' + idx.NAME + '] ON ['
+ Schema_name(tbl.schema_id) + '].['
+ Object_name(idx.object_id) + '] REBUILD ' + ( CASE
WHEN (
(SELECT Count(*)
FROM sys.partitions
part2
WHERE part2.index_id
= idx.index_id
AND
idx.object_id =
part2.object_id)
> 1 ) THEN
' PARTITION = '
+ Cast(part.partition_number AS NVARCHAR(256))
ELSE ''
END ) + '; SELECT ''[' +
idx.NAME + '] ON [' + Schema_name(tbl.schema_id) + '].[' +
Object_name(idx.object_id) + '] ' + (
CASE
WHEN ( (SELECT Count(*)
FROM sys.partitions
part2
WHERE
part2.index_id =
idx.index_id
AND idx.object_id
= part2.object_id) > 1 ) THEN
' PARTITION = '
+ Cast(part.partition_number AS NVARCHAR(256))
+ ' completed'';'
ELSE ' completed'';'
END )
FROM sys.indexes idx
INNER JOIN sys.tables tbl
ON idx.object_id = tbl.object_id
LEFT OUTER JOIN sys.partitions part
ON idx.index_id = part.index_id
AND idx.object_id = part.object_id
WHERE idx.type_desc = 'CLUSTERED COLUMNSTORE';
Upgrade über eine geografische Azure-Region mit der Wiederherstellung über das Azure-Portal
Erstellen eines benutzerdefinierten Wiederherstellungspunkts im Azure-Portal
- Melden Sie sich beim Azure-Portal an.
- Navigieren Sie zu dem dedizierten SQL-Pool (früher SQL DW), für den Sie einen Wiederherstellungspunkt erstellen möchten.
- Wählen Sie in der Symbolleiste der Seite Übersicht die Option + Neuer Wiederherstellungspunkt aus.
- Geben Sie einen Namen für Ihren Wiederherstellungspunkt an.
Wiederherstellen einer aktiven oder angehaltenen Datenbank im Azure-Portal
Melden Sie sich beim Azure-Portal an.
Navigieren Sie zu dem dedizierten SQL-Pool (früher SQL DW), mit dem Sie die Wiederherstellung durchführen möchten.
Wählen Sie in der Symbolleiste des Abschnitts Übersicht die Option Wiederherstellen aus.
Wählen Sie eine der Optionen Automatische Wiederherstellungspunkte oder Benutzerdefinierte Wiederherstellungspunkte aus. Wenn Sie sich für benutzerdefinierte Wiederherstellungspunkte entschieden haben, wählen Sie den gewünschten benutzerdefinierten Wiederherstellungspunkt aus, oder erstellen Sie einen neuen benutzerdefinierten Wiederherstellungspunkt. Wählen Sie für den Server Neu erstellen und dann einen Server in einer unterstützten geografischen Gen2-Region aus.
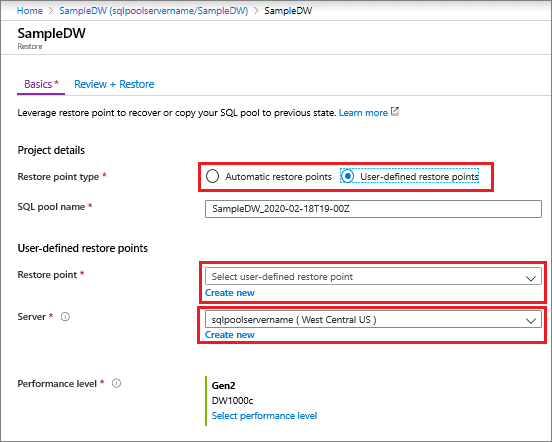
Wiederherstellen von einer geografischen Azure-Region aus mithilfe von PowerShell
Hinweis
Es wird empfohlen, das Azure Az PowerShell-Modul für die Interaktion mit Azure zu verwenden. Informationen zu den ersten Schritten finden Sie unter Installieren von Azure PowerShell. Informationen zum Migrieren zum Az PowerShell-Modul finden Sie unter Migrieren von Azure PowerShell von AzureRM zum Az-Modul.
Verwenden Sie das Cmdlet Restore-AzSqlDatabase, um eine Datenbank wiederherzustellen.
Hinweis
Sie können eine Geowiederherstellung nach Gen2 durchführen! Geben Sie zu diesem Zweck als optionalen Parameter einen ServiceObjectiveName-Wert für Gen2 ein (z.B. DW1000c).
- Öffnen Sie Windows PowerShell.
- Stellen Sie eine Verbindung mit Ihrem Azure-Konto her, und listen Sie alle Abonnements auf, die Ihrem Konto zugeordnet sind.
- Wählen Sie das Abonnement aus, in dem die wiederherzustellende Datenbank enthalten ist.
- Rufen Sie die Datenbank ab, die Sie wiederherstellen möchten.
- Erstellen Sie die Wiederherstellungsanforderung für die Datenbank, indem Sie einen Gen2-ServiceObjectiveName angeben.
- Überprüfen Sie den Status der mittels Geowiederherstellung wiederhergestellten Datenbank.
Connect-AzAccount
Get-AzSubscription
Select-AzSubscription -SubscriptionName "<Subscription_name>"
# Get the database you want to recover
$GeoBackup = Get-AzSqlDatabaseGeoBackup -ResourceGroupName "<YourResourceGroupName>" -ServerName "<YourServerName>" -DatabaseName "<YourDatabaseName>"
# Recover database
$GeoRestoredDatabase = Restore-AzSqlDatabase –FromGeoBackup -ResourceGroupName "<YourResourceGroupName>" -ServerName "<YourTargetServer>" -TargetDatabaseName "<NewDatabaseName>" –ResourceId $GeoBackup.ResourceID -ServiceObjectiveName "<YourTargetServiceLevel>" -RequestedServiceObjectiveName "DW300c"
# Verify that the geo-restored database is online
$GeoRestoredDatabase.status
Hinweis
Informationen zum Konfigurieren der Datenbank nach Abschluss der Wiederherstellung finden Sie unter Konfigurieren der Datenbank nach der Wiederherstellung.
Für die wiederhergestellte Datenbank ist TDE aktiviert, wenn für die Quelldatenbank TDE aktiviert ist.
Wenn bei Ihrem dedizierten SQL-Pool Probleme auftreten, können Sie eine Supportanfrage erstellen und als möglichen Grund „Gen2-Upgrade“ angeben.
Ihr aktualisierter dedizierter SQL-Pool (früher SQL DW) ist online. Um die Vorteile der erweiterten Architektur nutzen zu können, sollten Sie sich eingehender mit Ressourcenklassen beschäftigen.