Empfehlungen für die Reaktion auf Sicherheitsvorfälle
Gilt für die Empfehlung der Sicherheitsprüfliste für Azure Well-Architected Framework:
| SE:12 | Definieren und testen Sie effektive Verfahren zur Reaktion auf Vorfälle, die ein Spektrum von Vorfällen abdecken, von lokalisierten Problemen bis hin zur Notfallwiederherstellung. Definieren Sie eindeutig, welches Team oder welche Person ein Verfahren ausführt. |
|---|
In diesem Leitfaden werden die Empfehlungen für die Implementierung einer Reaktion auf Sicherheitsvorfälle für eine Workload beschrieben. Wenn es eine Sicherheitskompromittierung für ein System gibt, hilft ein systematischer Vorfallreaktionsansatz, die Zeit zu reduzieren, die es benötigt, um Sicherheitsvorfälle zu identifizieren, zu verwalten und zu mindern. Diese Vorfälle können die Vertraulichkeit, Integrität und Verfügbarkeit von Softwaresystemen und -daten gefährden.
Die meisten Unternehmen verfügen über ein zentrales Sicherheitsbetriebsteam (auch als Security Operations Center (SOC) oder SecOps bezeichnet. Die Verantwortung des Sicherheitsbetriebsteams besteht darin, potenzielle Angriffe schnell zu erkennen, zu priorisieren und zu triagen. Das Team überwacht außerdem sicherheitsbezogene Telemetriedaten und untersucht Sicherheitsverletzungen.
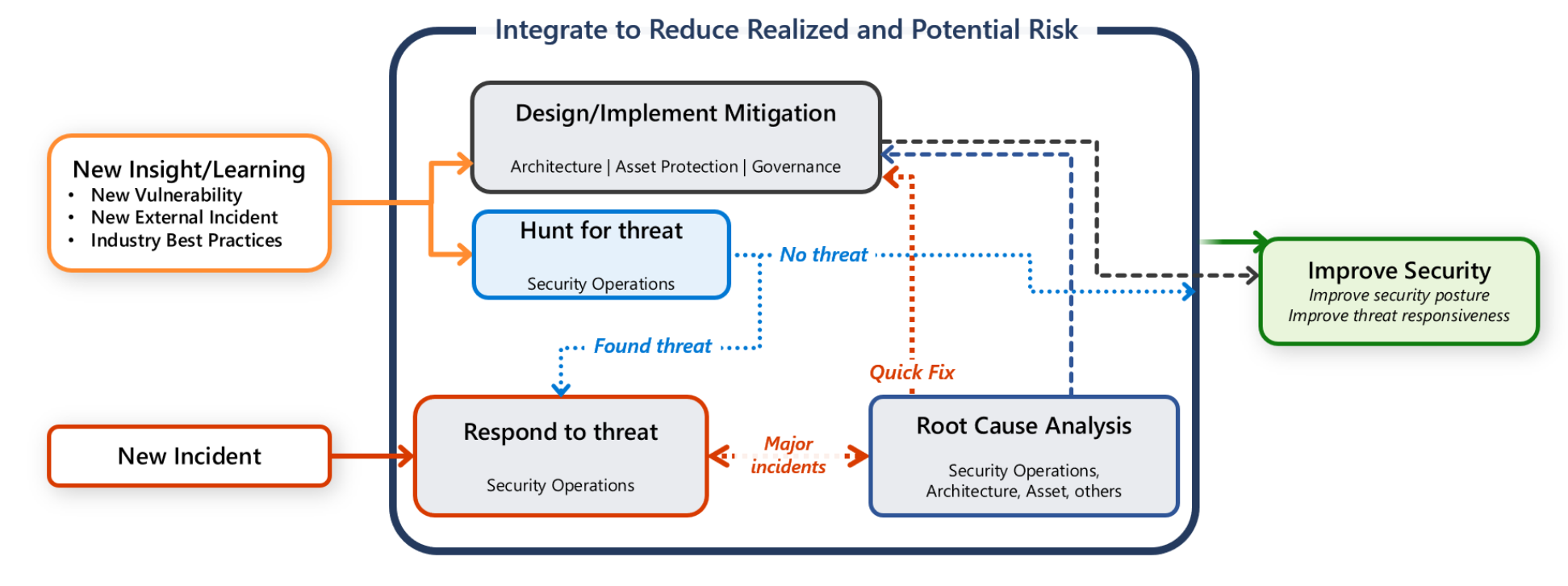
Sie haben jedoch auch die Verantwortung, Ihre Arbeitsauslastung zu schützen. Es ist wichtig, dass alle Kommunikations-, Untersuchungs- und Suchaktivitäten eine gemeinsame Arbeit zwischen Workload-Team und SecOps-Team sind.
Dieser Leitfaden enthält Empfehlungen für Sie und Ihr Workload-Team, damit Sie Angriffe schnell erkennen, triagen und untersuchen können.
Definitionen
| Begriff | Definition |
|---|---|
| Warnung | Eine Benachrichtigung, die Informationen zu einem Vorfall enthält. |
| Warnungstreue | Die Genauigkeit der Daten, die eine Warnung bestimmen. Warnungen mit hoher Genauigkeit enthalten den Sicherheitskontext, der erforderlich ist, um sofortige Maßnahmen zu ergreifen. Warnungen mit geringer Genauigkeit fehlen Informationen oder enthalten Rauschen. |
| Falsch positiv | Eine Warnung, die auf einen Vorfall hinweist, der nicht aufgetreten ist. |
| Vorfall | Ein Ereignis, das nicht autorisierten Zugriff auf ein System angibt. |
| Reaktion auf Incidents | Ein Prozess, der Risiken erkennt, reagiert und verringert, die mit einem Vorfall verbunden sind. |
| Eingrenzung | Ein Vorfallreaktionsvorgang, der Sicherheitsprobleme analysiert und deren Entschärfung priorisiert. |
Wichtige Entwurfsstrategien
Sie und Ihr Team führen Vorfallreaktionsvorgänge durch, wenn ein Signal oder eine Warnung für einen potenziellen Kompromiss vorhanden ist. Warnungen mit hoher Genauigkeit enthalten einen ausreichenden Sicherheitskontext, der es Analysten leicht macht, Entscheidungen zu treffen. Warnungen mit hoher Genauigkeit führen zu einer geringen Anzahl falsch positiver Ergebnisse. In diesem Leitfaden wird davon ausgegangen, dass ein Warnungssystem Signale mit geringer Genauigkeit filtert und sich auf Warnungen mit hoher Genauigkeit konzentriert, die auf einen echten Vorfall hinweisen können.
Festlegen von Kontakten für Vorfallbenachrichtigungen
Sicherheitswarnungen müssen die entsprechenden Personen in Ihrem Team und in Ihrer Organisation erreichen. Richten Sie einen bestimmten Kontaktpunkt in Ihrem Workloadteam ein, um Vorfallbenachrichtigungen zu erhalten. Diese Benachrichtigungen sollten so viele Informationen wie möglich über die Ressource enthalten, die kompromittiert ist, und das System. Die Warnung muss die nächsten Schritte enthalten, damit Ihr Team Aktionen beschleunigen kann.
Es wird empfohlen, Vorfallbenachrichtigungen und -aktionen mithilfe spezieller Tools zu protokollieren und zu verwalten, die einen Überwachungspfad beibehalten. Mithilfe von Standardtools können Sie Nachweise erhalten, die möglicherweise für potenzielle rechtliche Untersuchungen erforderlich sind. Suchen Sie nach Möglichkeiten zur Implementierung der Automatisierung, die Benachrichtigungen basierend auf den Verantwortlichkeiten verantwortlicher Parteien senden kann. Sorgen Sie für eine klare Kommunikationskette und Berichterstellung während eines Vorfalls.
Nutzen Sie die Von Ihrer Organisation bereitgestellten Lösungen für die Sicherheitsinformationsereignisverwaltung (Security Information Event Management, SIEM) und lösungen für die automatisierte Reaktion (Automated Response, SOAR). Alternativ können Sie Tools für die Vorfallverwaltung erwerben und Ihre Organisation ermutigen, sie für alle Workloadteams zu standardisieren.
Untersuchen mit einem Triageteam
Das Teammitglied, das eine Vorfallbenachrichtigung empfängt, ist für die Einrichtung eines Triageprozesses verantwortlich, bei dem die entsprechenden Personen basierend auf den verfügbaren Daten beteiligt sind. Das Triage-Team, das oft als Brückenteam bezeichnet wird, muss sich auf den Modus und den Prozess der Kommunikation einigen. Erfordert dieser Vorfall asynchrone Diskussionen oder Brückenanrufe? Wie sollte das Team den Fortschritt der Untersuchungen nachverfolgen und kommunizieren? Wo kann das Team auf Vorfallressourcen zugreifen?
Die Reaktion auf Vorfälle ist ein wichtiger Grund, die Dokumentation auf dem neuesten Stand zu halten, z. B. das Architekturlayout des Systems, Informationen auf Komponentenebene, Datenschutz oder Sicherheitsklassifizierung, Besitzer und wichtige Kontaktpunkte. Wenn die Informationen ungenau oder veraltet sind, verschwendet das Brückenteam wertvolle Zeit, um zu verstehen, wie das System funktioniert, wer für jeden Bereich verantwortlich ist und welche Auswirkungen das Ereignis haben könnte.
Für weitere Untersuchungen sind die entsprechenden Personen beteiligt. Sie können einen Vorfallmanager, Sicherheitsbeauftragten oder workloadorientierte Leads einschließen. Um die Triage fokussiert zu halten, schließen Sie Personen aus, die sich außerhalb des Umfangs des Problems befinden. Manchmal untersuchen separate Teams den Vorfall. Möglicherweise gibt es ein Team, das das Problem zunächst untersucht und versucht, den Vorfall zu mindern, und ein weiteres spezialisiertes Team, das forensische Forensik für eine umfassende Untersuchung durchführen kann, um große Probleme zu ermitteln. Sie können die Workloadumgebung unter Quarantäne stellen, damit das forensische Team ihre Untersuchungen durchführen kann. In einigen Fällen kann dasselbe Team die gesamte Untersuchung behandeln.
In der Anfangsphase ist das Triageteam für die Ermittlung des potenziellen Vektors und seiner Auswirkungen auf die Vertraulichkeit, Integrität und Verfügbarkeit (auch als CIA bezeichnet) des Systems verantwortlich.
Weisen Sie in den Kategorien der CIA einen anfänglichen Schweregrad zu, der die Tiefe des Schadens und die Dringlichkeit der Behebung angibt. Diese Ebene wird voraussichtlich im Laufe der Zeit geändert, da weitere Informationen in den Ebenen der Triage ermittelt werden.
In der Ermittlungsphase ist es wichtig, einen unmittelbaren Handlungs- und Kommunikationsplan zu ermitteln. Gibt es Änderungen am zustand des Systems? Wie kann der Angriff eingedämmt werden, um weitere Ausbeutung zu stoppen? Muss das Team interne oder externe Kommunikation senden, z. B. eine verantwortungsvolle Offenlegung? Erwägen Sie die Erkennungs- und Antwortzeit. Möglicherweise sind Sie gesetzlich verpflichtet, einige Arten von Verstößen innerhalb eines bestimmten Zeitraums an eine Regulierungsbehörde zu melden, was häufig Stunden oder Tage ist.
Wenn Sie sich entscheiden, das System herunterzufahren, führen die nächsten Schritte zum Notfallwiederherstellungsprozess (Disaster Recovery, DR) der Workload.
Wenn Sie das System nicht herunterfahren, bestimmen Sie, wie der Vorfall behoben werden kann, ohne dass sich dies auf die Funktionalität des Systems auswirkt.
Wiederherstellung aus einem Vorfall
Behandeln Sie einen Sicherheitsvorfall wie eine Katastrophe. Wenn für die Wartung eine vollständige Wiederherstellung erforderlich ist, verwenden Sie die richtigen DR-Mechanismen aus Sicherheitsgründen. Der Wiederherstellungsvorgang muss die Wahrscheinlichkeit einer Wiederholung verhindern. Andernfalls wird das Problem von einer beschädigten Sicherung wiederhergestellt. Die erneute Bereitstellung eines Systems mit derselben Sicherheitsanfälligkeit führt zu demselben Vorfall. Überprüfen Sie Failover- und Failbackschritte und -prozesse.
Wenn das System weiterhin funktioniert, bewerten Sie die Auswirkungen auf die ausgeführten Teile des Systems. Überwachen Sie das System weiterhin, um sicherzustellen, dass andere Zuverlässigkeits- und Leistungsziele erfüllt oder durch die Implementierung ordnungsgemäßer Beeinträchtigungsprozesse angepasst werden. Kompromittieren Sie den Datenschutz aufgrund von Gegenmaßnahmen nicht.
Die Diagnose ist ein interaktiver Prozess, bis der Vektor und ein potenzieller Fix und Fallback identifiziert werden. Nach der Diagnose arbeitet das Team an der Behebung, die den erforderlichen Fix innerhalb eines akzeptablen Zeitraums identifiziert und anwendet.
Wiederherstellungsmetriken messen, wie lange es dauert, um ein Problem zu beheben. Im Falle eines Herunterfahrens kann es eine Dringlichkeit hinsichtlich der Wartungszeiten geben. Um das System zu stabilisieren, dauert es Zeit, Korrekturen, Patches und Tests anzuwenden und Updates bereitzustellen. Bestimmen Sie Eindämmungsstrategien, um weitere Schäden und die Ausbreitung des Vorfalls zu verhindern. Entwickeln Sie Ausrottungsverfahren, um die Bedrohung vollständig aus der Umgebung zu entfernen.
Kompromiss: Es gibt einen Kompromiss zwischen Zuverlässigkeitszielen und Wartungszeiten. Während eines Vorfalls ist es wahrscheinlich, dass Sie keine anderen nicht funktionsfähigen oder funktionalen Anforderungen erfüllen. Sie müssen beispielsweise Teile Ihres Systems deaktivieren, während Sie den Vorfall untersuchen, oder Sie müssen das gesamte System sogar offline schalten, bis Sie den Umfang des Vorfalls bestimmen. Entscheidungsträger von Unternehmen müssen explizit entscheiden, was die zulässigen Ziele während des Vorfalls sind. Geben Sie eindeutig die Person an, die für diese Entscheidung verantwortlich ist.
Aus einem Vorfall lernen
Ein Vorfall entdeckt Lücken oder anfällige Punkte in einem Entwurf oder einer Implementierung. Es handelt sich um eine Verbesserungschance, die durch Lektionen in technischen Designaspekten, Automatisierung, Produktentwicklungsprozessen, die Tests und die Effektivität des Vorfallreaktionsprozesses beinhalten, gesteuert wird. Verwalten Sie detaillierte Vorfalldatensätze, einschließlich ausgeführter Aktionen, Zeitachsen und Ergebnisse.
Es wird dringend empfohlen, strukturierte Überprüfungen nach dem Vorfall durchzuführen, z. B. Ursachenanalyse und Retrospektive. Verfolgen und priorisieren Sie das Ergebnis dieser Rezensionen, und überlegen Sie, was Sie in zukünftigen Arbeitsauslastungsdesigns lernen.
Verbesserungspläne sollten Updates für Sicherheits drills und Tests enthalten, z. B. Business Continuity and Disaster Recovery (BCDR)-Drills. Verwenden Sie Sicherheitskompromittierung als Szenario zum Ausführen eines BCDR-Drilldowns. Drills können überprüfen, wie die dokumentierten Prozesse funktionieren. Es sollte nicht mehrere Playbooks für die Reaktion auf Vorfälle geben. Verwenden Sie eine einzelne Quelle, die Sie basierend auf der Größe des Vorfalls anpassen können und wie weit verbreitet oder lokalisiert der Effekt ist. Drills basieren auf hypothetischen Situationen. Führen Sie Drills in einer Umgebung mit geringem Risiko durch, und schließen Sie die Lernphase in die Drills ein.
Führen Sie überprüfungen nach vorfällen oder postmortems durch, um Schwachstellen im Reaktionsprozess und verbesserungsrelevante Bereiche zu identifizieren. Basierend auf den Lektionen, die Sie aus dem Vorfall lernen, aktualisieren Sie den Plan zur Reaktion auf Vorfälle (Incident Response Plan, IRP) und die Sicherheitskontrollen.
Definieren eines Kommunikationsplans
Implementieren Sie einen Kommunikationsplan, um Die Benutzer über eine Unterbrechung zu informieren und interne Projektbeteiligte über die Behebung und Verbesserungen zu informieren. Andere Personen in Ihrer Organisation müssen über Änderungen an den Sicherheitsgrundwerten der Workload benachrichtigt werden, um zukünftige Vorfälle zu verhindern.
Generieren Sie Vorfallberichte für die interne Verwendung und gegebenenfalls zur Einhaltung gesetzlicher Vorschriften oder rechtlicher Zwecke. Übernehmen Sie außerdem einen Standardformatbericht (eine Dokumentvorlage mit definierten Abschnitten), den das SOC-Team für alle Vorfälle verwendet. Stellen Sie sicher, dass jedem Vorfall ein Bericht zugeordnet ist, bevor Sie die Untersuchung schließen.
Azure-Erleichterung
Microsoft Sentinel ist eine SIEM- und SOAR-Lösung. Es ist eine Einzellösung für Warnungserkennung, Einblicke in Bedrohungen, proaktives Hunting und die Reaktion auf Bedrohungen. Weitere Informationen finden Sie unter "Was ist Microsoft Sentinel?
Stellen Sie sicher, dass das Azure-Registrierungsportal Administratorkontaktinformationen enthält, damit Sicherheitsvorgänge direkt über einen internen Prozess benachrichtigt werden können. Weitere Informationen finden Sie unter Aktualisieren von Benachrichtigungseinstellungen.
Weitere Informationen zum Einrichten eines bestimmten Kontaktpunkts, der Azure-Vorfallbenachrichtigungen von Microsoft Defender für Cloud empfängt, finden Sie unter Konfigurieren von E-Mail-Benachrichtigungen für Sicherheitswarnungen.
Organisationsausrichtung
Cloud Adoption Framework für Azure bietet Anleitungen zur Planung von Vorfällen und Sicherheitsvorgängen. Weitere Informationen finden Sie unter "Sicherheitsvorgänge".
Verwandte Links
- Automatisches Erstellen von Incidents aus Microsoft-Sicherheitswarnungen
- Durchführen der End-to-End-Bedrohungssuche mithilfe der Suchfunktion
- Konfigurieren von E-Mail-Benachrichtigungen für Sicherheitswarnungen
- Übersicht über die Reaktion auf Vorfälle
- Bereitschaft für Vorfälle von Microsoft Azure
- Navigieren und Untersuchen von Incidents mit Microsoft Sentinel
- Sicherheitskontrolle: Reaktion auf Vorfälle
- SOAR-Lösungen in Microsoft Sentinel
- Schulung: Einführung in die Azure-Vorfallbereitschaft
- Aktualisieren Azure-Portal Benachrichtigungseinstellungen
- Was ist ein SOC?
- Was ist Microsoft Sentinel?
Checkliste für die Sicherheit
Lesen Sie den vollständigen Satz von Empfehlungen.