Tests mit Unit-Tests nach links verschieben
Testen hilft sicherzustellen, dass der Code wie erwartet funktioniert, aber die Zeit und der Aufwand für die Erstellung von Tests nimmt Zeit von anderen Aufgaben wie der Entwicklung von Funktionen weg. Angesichts dieser Kosten ist es wichtig, den größtmöglichen Nutzen aus den Tests zu ziehen. In diesem Artikel werden DevOps-Testprinzipien erörtert, wobei der Schwerpunkt auf dem Wert von Unit-Tests und einer Shift-Links-Teststrategie liegt.
Früher schrieben dedizierte Tester die meisten Tests, und viele Produktentwickler haben nicht gelernt, Unit-Tests zu schreiben. Das Schreiben von Tests kann als zu schwierig oder als zu viel Arbeit erscheinen. Man kann skeptisch sein, ob eine Unit-Test-Strategie funktioniert, schlechte Erfahrungen mit schlecht geschriebenen Unit-Tests machen oder befürchten, dass Unit-Tests funktionale Tests ersetzen werden.

Bei der Umsetzung einer DevOps-Teststrategie müssen Sie pragmatisch vorgehen und sich darauf konzentrieren, eine Dynamik aufzubauen. Obwohl Sie auf Unit-Tests für neuen Code oder bestehenden Code, der sauber refaktorisiert werden kann, bestehen können, kann es für eine Legacy-Codebasis sinnvoll sein, eine gewisse Abhängigkeit zuzulassen. Wenn wesentliche Teile des Produktcodes SQL verwenden, könnte es ein kurzfristiger Ansatz sein, Unit-Tests die Abhängigkeit vom SQL-Ressourcenanbieter zu erlauben, anstatt mocking diese Schicht zu nutzen.
Je reifer DevOps-Organisationen werden, desto einfacher wird es für die Führung, Prozesse zu verbessern. Auch wenn es einen gewissen Widerstand gegen Veränderungen geben mag, schätzen agile Organisationen Veränderungen, die sich eindeutig auszahlen. Es sollte einfach sein, die Vision von schnelleren Testläufen mit weniger Fehlern zu verkaufen, denn das bedeutet mehr Zeit, um in die Schaffung neuer Werte durch die Entwicklung von Funktionen zu investieren.
DevOps-Test-Taxonomie
Die Definition einer Testtaxonomie ist ein wichtiger Aspekt des DevOps-Testprozesses. Eine DevOps-Testtaxonomie klassifiziert einzelne Tests nach ihren Abhängigkeiten und der Zeit, die sie zur Ausführung benötigen. Die Entwickler müssen wissen, welche Arten von Tests in den verschiedenen Szenarien zu verwenden sind und welche Tests für die verschiedenen Teile des Prozesses erforderlich sind. Die meisten Organisationen kategorisieren die Tests in vier Stufen:
- L0 und L1 Tests sind Einheitstests oder Tests, die von Code in der zu testenden Baugruppe abhängen und von nichts anderem. L0 ist eine breite Klasse von schnellen, speicherinternen Einheitstests.
- L2 sind Funktionstests, die die Baugruppe und andere Abhängigkeiten, wie SQL oder das Dateisystem, erfordern können.
- L3 Funktionstests laufen gegen testbare Dienstbereitstellungen. Diese Testkategorie erfordert eine Dienstbereitstellung, kann aber stubs für wichtige Dienstabhängigkeiten verwenden.
- L4 Tests sind eine eingeschränkte Klasse von Integrationstests, die gegen die Produktion laufen. L4-Tests erfordern eine vollständige Produktbereitstellung.
Es wäre zwar ideal, wenn alle Tests zu jeder Zeit laufen würden, aber das ist nicht möglich. Teams können auswählen, an welcher Stelle des DevOps-Prozesses jeder Test ausgeführt werden soll, und shift-left oder shift-right Strategien verwenden, um verschiedene Testtypen früher oder später im Prozess zu verschieben.
Zum Beispiel könnte die Erwartung sein, dass Entwickler immer L2-Tests durchlaufen, bevor sie ein Commit machen, dass eine Pull-Anfrage automatisch fehlschlägt, wenn der L3-Testlauf fehlschlägt, und dass das Deployment blockiert wird, wenn L4-Tests fehlschlagen. Die spezifischen Regeln können von Organisation zu Organisation variieren, aber die Durchsetzung der Erwartungen für alle Teams innerhalb einer Organisation bringt alle auf die gleichen Ziele der Qualitätsvision.
Leitlinien für Einheitstests
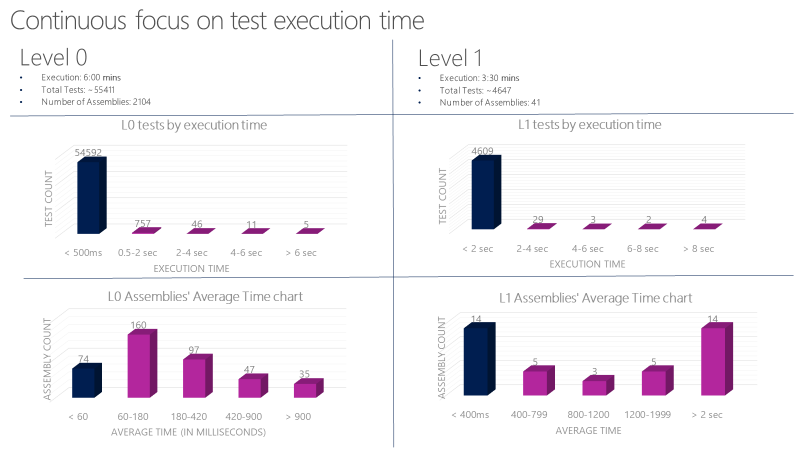
Legen Sie strenge Richtlinien für L0- und L1-Unit-Tests fest. Diese Tests müssen sehr schnell und zuverlässig sein. Zum Beispiel sollte die durchschnittliche Ausführungszeit pro L0-Test in einer Baugruppe weniger als 60 Millisekunden betragen. Die durchschnittliche Ausführungszeit pro L1-Test in einer Baugruppe sollte weniger als 400 Millisekunden betragen. Kein Test auf dieser Stufe sollte länger als 2 Sekunden dauern.
Ein Microsoft-Team führt über 60.000 Unit-Tests parallel in weniger als sechs Minuten durch. Ihr Ziel ist es, diese Zeit auf weniger als eine Minute zu reduzieren. Das Team verfolgt die Ausführungszeit von Unit-Tests mit Tools wie dem folgenden Diagramm und registriert Fehler bei Tests, die die zulässige Zeit überschreiten.
Leitlinien für Funktionsprüfungen
Die Funktionstests müssen unabhängig sein. Das Schlüsselkonzept für L2-Tests ist die Isolierung. Ordnungsgemäß isolierte Tests können in beliebiger Reihenfolge zuverlässig ablaufen, da sie die vollständige Kontrolle über die Umgebung haben, in der sie ausgeführt werden. Der Zustand muss zu Beginn der Prüfung bekannt sein. Wenn ein Test Daten erstellt und in der Datenbank belässt, kann dies den Lauf eines anderen Tests stören, der sich auf einen anderen Datenbankzustand stützt.
Ältere Tests, die eine Benutzeridentität benötigen, haben möglicherweise externe Authentifizierungsanbieter aufgerufen, um die Identität zu erhalten. Diese Praxis bringt mehrere Herausforderungen mit sich. Die externe Abhängigkeit könnte unzuverlässig oder vorübergehend nicht verfügbar sein, wodurch der Test unterbrochen würde. Diese Praxis verstößt auch gegen das Prinzip der Testisolierung, da ein Test den Zustand einer Identität, wie z. B. einer Berechtigung, ändern könnte, was zu einem unerwarteten Standardzustand für andere Tests führt. Erwägen Sie, diese Probleme zu vermeiden, indem Sie in die Identitätsunterstützung innerhalb des Test-Frameworks investieren.
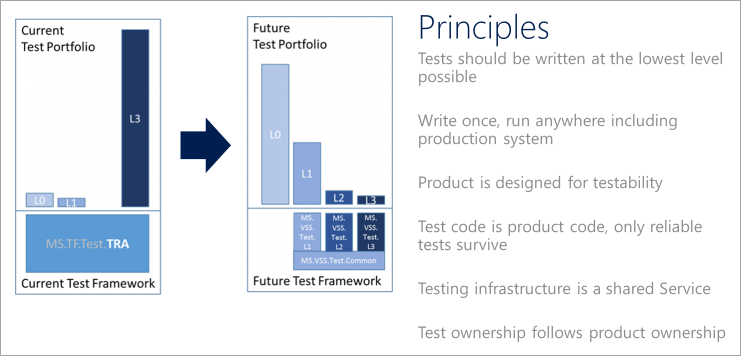
DevOps-Prinzipien
Um die Umstellung eines Testportfolios auf moderne DevOps-Prozesse zu unterstützen, muss eine Qualitätsvision formuliert werden. Teams müssen bei der Festlegung und Umsetzung einer DevOps-Teststrategie die folgenden Testprinzipien beachten.
Nach links schieben, um früher zu testen
Die Durchführung von Tests kann lange dauern. Mit zunehmender Projektgröße nehmen Anzahl und Art der Tests erheblich zu. Wenn die Fertigstellung von Testsuiten Stunden oder Tage in Anspruch nimmt, können sie in die Zukunft verschoben werden, bis sie im letzten Moment ausgeführt werden. Die Vorteile des Testens für die Codequalität werden erst lange nach der Übergabe des Codes erkannt.
Langlaufende Tests können auch zu Fehlern führen, deren Untersuchung zeitaufwändig ist. Teams können eine Fehlertoleranz aufbauen, insbesondere zu Beginn eines Sprints. Diese Toleranz untergräbt den Wert von Tests als Einblick in die Qualität der Codebasis. Langwierige, in letzter Minute durchgeführte Tests machen auch die Erwartungen an das Ende des Sprints unvorhersehbar, da eine unbekannte Menge an technischen Schulden bezahlt werden muss, damit der Code ausgeliefert werden kann.
Das Ziel der Verlagerung des Testens nach links ist es, die Qualität nach oben zu verlagern, indem Testaufgaben früher in der Pipeline durchgeführt werden. Durch eine Kombination von Test- und Prozessverbesserungen reduziert die Linksverschiebung sowohl die Zeit, die für die Durchführung von Tests benötigt wird, als auch die Auswirkungen von Fehlern in späteren Phasen des Zyklus. Die Verschiebung nach links stellt sicher, dass die meisten Tests abgeschlossen sind, bevor eine Änderung in den Hauptzweig übergeht.
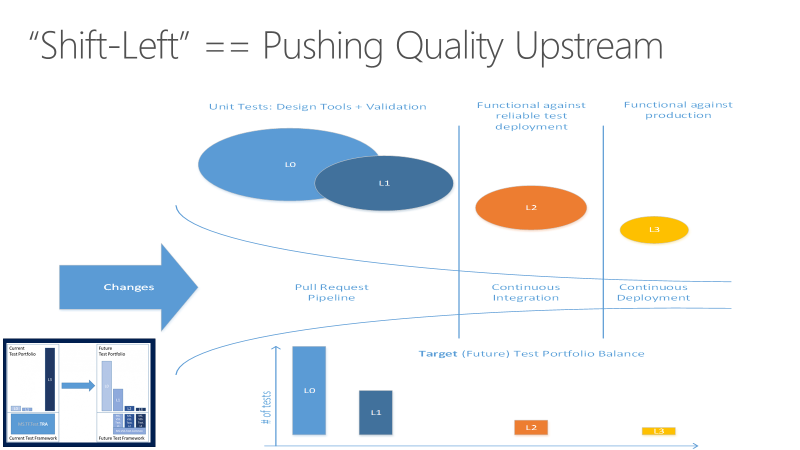
Teams können nicht nur bestimmte Testaufgaben nach links verlagern, um die Codequalität zu verbessern, sondern auch andere Testaspekte nach rechts oder später im DevOps-Zyklus, um das Endprodukt zu verbessern. Weitere Informationen finden Sie unter „Shift Right to test in production“.
Schreiben Sie Tests auf der niedrigstmöglichen Ebene
Schreiben Sie mehr Unit-Tests. Bevorzugen Sie Tests mit den wenigsten externen Abhängigkeiten, und konzentrieren Sie sich darauf, die meisten Tests als Teil des Builds auszuführen. Stellen Sie sich ein paralleles Build-System vor, das Einheitstests für eine Baugruppe ausführen kann, sobald die Baugruppe und die zugehörigen Tests abgelegt werden. Es ist nicht möglich, jeden Aspekt eines Dienstes auf dieser Ebene zu testen, aber das Prinzip ist, leichtere Unit-Tests zu verwenden, wenn sie die gleichen Ergebnisse liefern können wie schwerere funktionale Tests.
Zuverlässigkeit der Tests anstreben
Ein unzuverlässiger Test ist organisatorisch teuer in der Wartung. Ein solcher Test läuft dem Ziel der technischen Effizienz direkt zuwider, da er es schwierig macht, Änderungen mit Zuversicht vorzunehmen. Die Entwickler müssen in der Lage sein, überall Änderungen vorzunehmen und schnell die Gewissheit zu erlangen, dass nichts kaputt gegangen ist. Halten Sie die Messlatte für Zuverlässigkeit hoch. Von der Verwendung von UI-Tests ist abzuraten, da sie in der Regel unzuverlässig sind.
Funktionstests schreiben, die überall ausgeführt werden können
Für die Tests können spezielle Integrationspunkte verwendet werden, die speziell für die Durchführung von Tests entwickelt wurden. Ein Grund für diese Praxis ist die mangelnde Testbarkeit des Produkts selbst. Leider hängen solche Tests oft von internem Wissen ab und verwenden Implementierungsdetails, die aus Sicht der Funktionstests nicht von Bedeutung sind. Diese Tests sind auf Umgebungen beschränkt, die über die für die Durchführung der Tests erforderlichen Geheimnisse und Konfigurationen verfügen, was in der Regel Produktionsumgebungen ausschließt. Funktionstests müssen nur die öffentliche API des Produkts verwenden.
Produkte für die Testbarkeit entwerfen
Unternehmen, die sich in einem ausgereiften DevOps-Prozess befinden, haben eine umfassende Vorstellung davon, was es bedeutet, ein Qualitätsprodukt in einer Cloud-Kadenz zu liefern. Um das Gleichgewicht zugunsten von Unit-Tests gegenüber funktionalen Tests zu verschieben, müssen die Teams Design- und Implementierungsentscheidungen treffen, die die Testbarkeit unterstützen. Es gibt unterschiedliche Vorstellungen darüber, was gut konzipierten und gut implementierten Code für die Testbarkeit ausmacht, ebenso wie es unterschiedliche Codierungsstile gibt. Das Prinzip ist, dass die Entwicklung von Testbarkeit ein primärer Bestandteil der Diskussion über Design und Codequalität werden muss.
Testcode wie Produktcode behandeln
Die ausdrückliche Feststellung, dass Testcode Produktcode ist, macht deutlich, dass die Qualität des Testcodes für die Auslieferung ebenso wichtig ist wie die des Produktcodes. Teams müssen den Testcode genauso behandeln wie den Produktcode und bei der Entwicklung und Implementierung von Tests und Test-Frameworks die gleiche Sorgfalt walten lassen. Dieser Aufwand ist vergleichbar mit der Verwaltung von Konfiguration und Infrastruktur als Code. Um vollständig zu sein, sollte eine Codeüberprüfung den Testcode berücksichtigen und ihn an die gleichen Qualitätsstandards halten wie den Produktcode.
Gemeinsame Testinfrastruktur nutzen
Legen Sie die Messlatte für die Nutzung der Testinfrastruktur zur Erzeugung zuverlässiger Qualitätssignale niedriger. Betrachten Sie das Testen als eine gemeinsame Dienstleistung für das gesamte Team. Speichern Sie den Unit-Test-Code zusammen mit dem Produktcode und erstellen Sie ihn zusammen mit dem Produkt. Tests, die als Teil des Build-Prozesses ausgeführt werden, müssen auch unter Entwicklungstools wie Azure DevOps laufen. Wenn Tests in jeder Umgebung von der lokalen Entwicklung bis zur Produktion laufen können, haben sie die gleiche Zuverlässigkeit wie der Produktcode.
Verantwortliche für das Testen des Codes
Der Testcode sollte sich neben dem Produktcode in einem Repo befinden. Bei Code, der an einer Komponentengrenze getestet werden soll, sollte die Verantwortung für das Testen der Person übertragen werden, die den Komponentencode schreibt. Verlassen Sie sich beim Testen des Bauteils nicht auf andere.
Fallstudie: Linksverschiebung bei Einheitstests
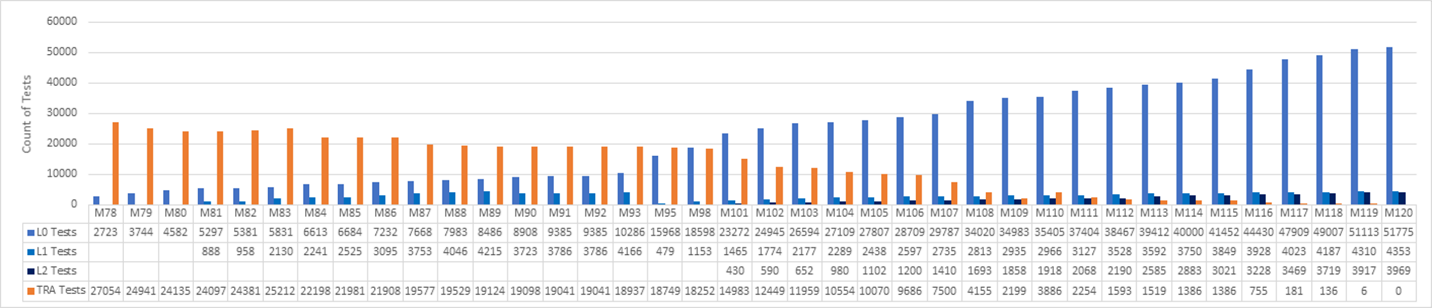
Ein Microsoft-Team beschloss, seine veralteten Testsuiten durch moderne DevOps-Unit-Tests und einen Shift-Links-Prozess zu ersetzen. Das Team verfolgte den Fortschritt in dreiwöchigen Sprints, wie in der folgenden Grafik dargestellt. Das Diagramm deckt die Sprints 78-120 ab, was 42 Sprints über 126 Wochen oder etwa zweieinhalb Jahre Arbeit bedeutet.
Das Team begann mit 27K Legacy-Tests in Sprint 78 und erreichte Null Legacy-Tests in S120. Ein Satz von L0- und L1-Unit-Tests ersetzte die meisten der alten Funktionstests. Einige der Tests wurden durch neue L2-Tests ersetzt, und viele der alten Tests wurden gestrichen.
Bei einer Softwareentwicklung, die über zwei Jahre dauert, kann man viel aus dem Prozess selbst lernen. Insgesamt war der Aufwand, das Testsystem über zwei Jahre hinweg komplett neu zu gestalten, eine gewaltige Investition. Nicht alle Feature-Teams haben die Arbeit zur gleichen Zeit erledigt. Viele Teams in der gesamten Organisation investierten Zeit in jeden Sprint, und in einigen Sprints war dies der größte Teil der Arbeit des Teams. Obwohl es schwierig ist, die Kosten der Umstellung zu messen, war sie eine nicht verhandelbare Voraussetzung für die Qualitäts- und Leistungsziele des Teams.
Erste Schritte
Zu Beginn ließ das Team die alten funktionalen Tests, die so genannten TRA-Tests, in Ruhe. Das Team wollte, dass sich die Entwickler mit der Idee anfreunden, Unit-Tests zu schreiben, insbesondere für neue Funktionen. Der Schwerpunkt lag darauf, die Erstellung von L0- und L1-Tests so einfach wie möglich zu gestalten. Das Team musste diese Fähigkeit erst entwickeln und eine Dynamik aufbauen.
Das vorstehende Diagramm zeigt, dass die Anzahl der Unit-Tests schon früh zunahm, als das Team den Nutzen der Erstellung von Unit-Tests erkannte. Unit-Tests waren einfacher zu pflegen, schneller auszuführen und hatten weniger Fehler. Es war einfach, Unterstützung für die Durchführung aller Unit-Tests im Pull-Request-Flow zu gewinnen.
Das Team konzentrierte sich bis zum Sprint 101 nicht auf das Schreiben neuer L2-Tests. In der Zwischenzeit ging die Zahl der TRA-Tests von 27.000 auf 14.000 zurück, von Sprint 78 auf Sprint 101. Einige der TRA-Tests wurden durch neue Einheitstests ersetzt, aber viele wurden einfach gestrichen, nachdem das Team ihre Nützlichkeit analysiert hatte.
Die TRA-Tests stiegen im Sprint 110 von 2100 auf 3800, weil mehr Tests im Quellcodebaum entdeckt und dem Diagramm hinzugefügt wurden. Es stellte sich heraus, dass die Tests schon immer gelaufen waren, aber nicht richtig verfolgt wurden. Es handelte sich nicht um eine Krise, aber es war wichtig, ehrlich zu sein und bei Bedarf eine Neubewertung vorzunehmen.
Schneller werden
Sobald das Team ein fortlaufendes Integrations- (CI)--Signal hatte, das extrem schnell und zuverlässig war, wurde es zu einem zuverlässigen Indikator für die Produktqualität. Der folgende Screenshot zeigt die Pull-Request- und CI-Pipeline in Aktion und die Zeit, die für das Durchlaufen der verschiedenen Phasen benötigt wird.
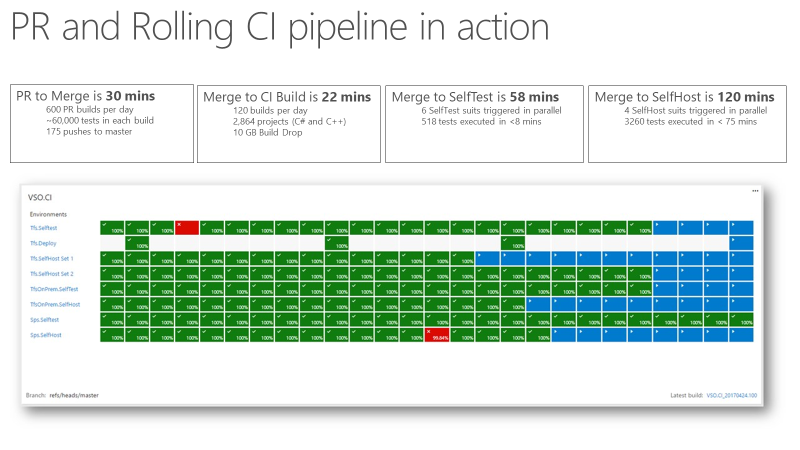
Es dauert etwa 30 Minuten, um von einer Pull-Anfrage zu einem Merge zu gelangen, was die Durchführung von 60.000 Unit-Tests beinhaltet. Von der Codezusammenführung bis zum CI-Build vergehen etwa 22 Minuten. Das erste Qualitätssignal von CI, SelfTest, kommt nach etwa einer Stunde. Dann wird der größte Teil des Produkts mit der vorgeschlagenen Änderung getestet. Innerhalb von zwei Stunden von Merge zu SelfHost ist das gesamte Produkt getestet und die Änderung kann in die Produktion gehen.
Verwenden von Metriken
Das Team verfolgt eine Scorecard wie das folgende Beispiel. Auf einer hohen Ebene verfolgt die Scorecard zwei Arten von Metriken: Gesundheit oder Schulden und Schnelligkeit.
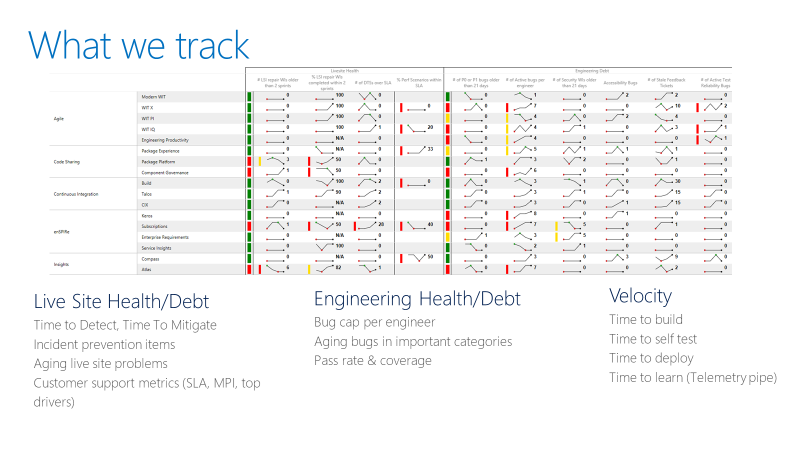
Bei den Live-Kennzahlen für den Zustand der Website verfolgt das Team die Zeit bis zur Entdeckung, die Zeit bis zur Schadensbegrenzung und die Anzahl der Reparaturen, die ein Team durchführt. Ein Reparaturpunkt ist eine Arbeit, die das Team in einer Live-Site-Retrospektive identifiziert, um zu verhindern, dass sich ähnliche Vorfälle wiederholen. Die Scorecard zeigt auch, ob die Teams die Reparaturen innerhalb eines angemessenen Zeitrahmens abschließen.
Für die technischen Kennzahlen verfolgt das Team aktive Fehler pro Entwickler. Wenn ein Team mehr als fünf Fehler pro Entwickler hat, muss das Team die Behebung dieser Fehler vor der Entwicklung neuer Funktionen priorisieren. Das Team verfolgt auch alternde Bugs in speziellen Kategorien wie Sicherheit.
Die technischen Geschwindigkeitsmetriken messen die Geschwindigkeit in verschiedenen Teilen der kontinuierlichen Integration und der kontinuierlichen Bereitstellung (CI/CD). Das übergeordnete Ziel ist es, die Geschwindigkeit der DevOps-Pipeline zu erhöhen: Von der Idee über die Umsetzung des Codes in die Produktion bis hin zur Rückmeldung von Kunden.