Herausforderungen und Lösungen für die verteilte Datenverwaltung
Tipp
Diese Inhalte sind ein Auszug aus dem eBook „.NET Microservices Architecture for Containerized .NET Applications“, verfügbar unter .NET Docs oder als kostenlos herunterladbare PDF-Datei, die offline gelesen werden kann.

Herausforderung #1: Definieren der Grenzen der einzelnen Microservices
Das Definieren der Grenzen der Microservices stellt wahrscheinlich für jedermann die erste Herausforderung dar. Jeder Microservice muss ein Teil Ihrer Anwendung sein, sollte aber einschließlich all seiner Vor- und Nachteile autonom sein. Aber wie erkennen Sie diese Grenzen?
Zunächst müssen Sie sich auf die logischen Domänenmodelle der Anwendung und die zugehörigen Daten konzentrieren. Versuchen Sie, entkoppelte Dateninseln und unterschiedliche Kontexte innerhalb einer Anwendung zu identifizieren. Jeder Kontext weist möglicherweise eine andere Geschäftssprache (unterschiedliche Geschäftsbegriffe) auf. Die Kontexte sollten unabhängig voneinander definiert und verwaltet werden. Die in diesen unterschiedlichen Kontexten verwendeten Begriffe und Entitäten klingen unter Umständen ähnlich, aber Sie werden feststellen, dass ein Geschäftskonzept in einem bestimmten Kontext für einen anderen Zweck verwendet wird als in einem anderen Kontext und möglicherweise auch einen anderen Namen aufweist. Ein Benutzer kann beispielsweise im Kontext Identität oder Mitgliedschaft als Benutzer, im Kontext CRM als Kunde und in einem Bestellkontext als Käufer bezeichnet werden usw.
Die Methode, mit der Sie Grenzen zwischen mehreren Anwendungskontexten mit einer unterschiedlichen Domäne pro Kontext ermitteln, ist dieselbe Methode, mit der Sie auch die Grenzen für die einzelnen Unternehmensmicroservices und deren zugehörige Domänenmodelle und Daten ermitteln. Sie versuchen stets, die Kopplung zwischen diesen Microservices zu minimieren. Dieser Leitfaden befasst sich in seinem nachstehenden Abschnitt Identifying domain-model boundaries for each microservice (Identifizieren von Domänenmodell-Grenzen für jeden Microservice) eingehender mit dieser Identifizierung und dem Domänenmodell-Entwurf.
Herausforderung #2: Erstellen von Abfragen, die Daten aus mehreren Microservices abrufen
Eine zweite Herausforderung besteht darin, Abfragen zu implementieren, die Daten aus mehreren Microservices abrufen, und dabei gleichzeitig eine übermäßige Kommunikation von Remoteclient-Apps zu den Microservices zu vermeiden. Ein Beispiel hierfür ist ein einzelner Bildschirm einer mobilen App, auf dem Benutzerinformationen angezeigt werden müssen, die den Microservices Warenkorb, Katalog und Benutzeridentität gehören. Ein weiteres Beispiel wäre ein komplexer Bericht, der zahlreiche Tabellen umfasst, die sich in mehreren Microservices befinden. Die richtige Lösung hängt von der Komplexität der Abfragen ab. Sie benötigen jedoch in jedem Fall eine Möglichkeit, Informationen zu aggregieren, wenn Sie die Kommunikation Ihres Systems effizienter gestalten wollen. Am häufigsten kommen dabei die nachstehenden Lösungen zur Anwendung.
API-Gateway: Für eine einfache Datenaggregation aus mehreren Microservices, die verschiedene Datenbanken besitzen, besteht die empfohlene Vorgehensweise in einem Aggregations-Microservice, der als API-Gateway bezeichnet wird. Allerdings müssen Sie bei der Implementierung dieses Musters vorsichtig sein, da es zu einem Engpass in Ihrem System führen und gegen den Grundsatz der Autonomie der Microservices verstoßen kann. Um dieses Risiko zu mindern, können Sie mehrere abgestimmte API-Gateways verwenden, die sich jeweils auf ein vertikales „Segment“ bzw. einen Geschäftsbereich des Systems konzentrieren. Das API-Gateway-Muster wird weiter unten ausführlicher erläutert, wenn es explizit um API-Gateways geht.
GraphQL-Verbund Eine Option, die in Frage kommt, wenn Ihre Microservices bereits GraphQL nutzen, ist ein GraphQL-Verbund. Ein Verbund ermöglicht Ihnen, anhand anderer Dienste „Untergraphen“ zu definieren und sie in einem aggregierten „Supergraphen“ zusammenzustellen, der als eigenständiges Schema fungiert.
CQRS mit Abfrage-/schreibgeschützten Tabellen: Eine weitere Lösung für das Aggregieren von Daten aus mehreren Microservices ist das Muster für materialisierte Sichten. Bei diesem Ansatz generieren Sie vorab eine schreibgeschützte Tabelle mit den Daten, die mehreren Microservices gehören (d.h. Sie bereiten vor den eigentlichen Abfragen denormalisierte Daten vor). Die Tabelle weist ein für die Anforderungen der Client-App geeignetes Format auf.
Stellen Sie sich beispielsweise den Bildschirm einer mobilen App vor. Wenn Sie nur über eine Datenbank verfügen, können Sie die Daten für diesen Bildschirm vermutlich mit einer SQL-Abfrage zusammentragen, die eine komplexe Verknüpfung mit mehreren Tabellen ausführt. Wenn Sie jedoch mehrere Datenbanken haben und jede Datenbank im Besitz eines anderen Microservice ist, können Sie diese Datenbanken nicht abfragen und eine SQL-Verknüpfung erstellen. Ihre komplexe Abfrage wird zur einer Herausforderung. Diese Anforderung lässt sich mit einem CQRS-Ansatz meistern. Hierzu erstellen Sie eine denormalisierte Tabelle in einer anderen Datenbank, die nur für Abfragen verwendet wird. Die Tabelle kann speziell für die Daten konzipiert werden, die Sie für die komplexe Abfrage benötigen – mit einer 1:1-Beziehung zwischen den Feldern, die der Bildschirm Ihrer Anwendung benötigt, und den Spalten in der Abfragetabelle. Sie könnte darüber hinaus für Berichtszwecke verwendet werden.
Dieser Ansatz löst nicht nur das ursprüngliche Problem (d.h. die Wahl der Methode für Abfragen und Verknüpfungen zwischen Microservices), sondern verbessert im Vergleich zu einer komplexen Verknüpfung auch erheblich die Leistung, da die von der Anwendung benötigten Daten bereits in der Abfragetabelle vorliegen. Natürlich geht die Verwendung von CQRS (Command and Query Responsibility Segregation) mit Abfrage-/schreibgeschützten Tabellen mit zusätzlicher Entwicklungsarbeit einher, und Sie müssen die letztliche Konsistenz gewährleisten. Dennoch sollten Sie CQRS mit mehreren Datenbanken in Situationen anwenden, in denen eine hohe Leistung und Skalierbarkeit in Kooperationsszenarios (oder Konkurrenzszenarios, je nach Sichtweise) gefordert werden.
„Kalte Daten“ in zentralen Datenbanken: Für komplexe Berichte und Abfragen, die nicht unbedingt Echtzeitdaten erfordern, besteht eine gängige Methode darin, Ihre „heißen Daten“ (Transaktionsdaten aus den Microservices) als „kalte Daten“ in große Datenbanken zu exportieren, die nur für die Berichterstellung verwendet werden. Dieses zentrale Datenbanksystem kann ein auf Big Data basierendes System wie Hadoop, ein Data Warehouse etwa auf Basis von Azure SQL Data Warehouse oder sogar eine einzelne SQL-Datenbank sein, die nur für Berichte verwendet wird (sofern die Größe kein Problem darstellt).
Beachten Sie, dass diese zentrale Datenbank nur für Abfragen und Berichte verwendet würde, die keine Echtzeitdaten benötigen. Die ursprünglichen Aktualisierungen und Transaktionen als Ihre Source of Truth müssen sich in Ihren Microservices-Daten befinden. Für die Synchronisierung der Daten würden Sie entweder eine (in den nächsten Abschnitten behandelte) ereignisgesteuerte Kommunikation oder andere Import/Export-Tools für die Datenbankinfrastruktur verwenden. Bei Verwendung einer ereignisgesteuerten Kommunikation würde dieser Integrationsprozess der Methode ähneln, mit der Sie Daten übertragen (wie dies oben für CQRS-Abfragetabellen beschrieben wurde).
Wenn Ihr Anwendungsentwurf jedoch das kontinuierliche Aggregieren von Informationen aus mehreren Microservices für komplexe Abfragen umfasst, wäre dies ein Indiz für einen schlechten Entwurf, da ein Microservice möglichst von anderen Microservices isoliert sein sollte. (Dies schließt Berichte/Analysen aus, die immer zentrale Cold Data-Datenbanken verwenden sollten.) Dieses Problem kann häufig ein Grund für die Zusammenführung von Microservices sein. Sie müssen die Autonomie der Entwicklung und Bereitstellung jedes Microservices und starke Abhängigkeiten, Kohäsion und Datenaggregation gegeneinander abwägen.
Herausforderung #3: Erzielen von Konsistenz über mehrere Microservices
Wie bereits erwähnt wurde, sind die Daten, die sich im Besitz des einzelnen Microservices befinden, für diesen Microservice privat, und es kann nur mit seiner Microservice-API auf sie zugegriffen werden. Dies führt häufig zu der Herausforderung, wie sich End-to-End-Geschäftsprozesse implementieren lassen, wenn gleichzeitig die Konsistenz über mehrere Microservices gewahrt bleiben soll.
Um dieses Problem zu untersuchen, sehen wir uns ein Beispiel für die eShopOnContainers-Referenzanwendung an. Der Katalogmicroservice verwaltet Informationen zu allen Produkten, einschließlich des Produktpreises. Der Warenkorbmicroservice verwaltet zeitliche Daten über Produktartikel, die Benutzer in ihren Warenkorb legen, einschließlich des Artikelpreises zum Zeitpunkt der Aufnahme in den Warenkorb. Wenn der Preis eines Produkts im Katalog aktualisiert wird, sollte dieser Preis auch in den aktiven Warenkörben aktualisiert werden, in denen sich ebendieses Produkt befindet. Im Idealfall warnt das System den Benutzer davor, dass sich der Preis eines bestimmten Artikels geändert hat, seitdem er ihn in seinen Warenkorb gelegt hat.
In einer hypothetischen monolithischen Version dieser Anwendung, könnte das Katalogsubsystem bei Preisänderungen in der Produkttabelle eine ACID-Transaktion verwenden, um den aktuellen Preis in der Warenkorbtabelle zu aktualisieren.
In einer auf Microservices basierenden Anwendung sind die Produkt- und Warenkorbtabellen jedoch im Besitz der jeweiligen Microservices. Ein Microservice sollte niemals in seinen eigenen Transaktionen oder direkten Abfragen Tabellen/Speicher umfassen, die im Besitz eines anderen Microservices sind (s. Abbildung 4-9).
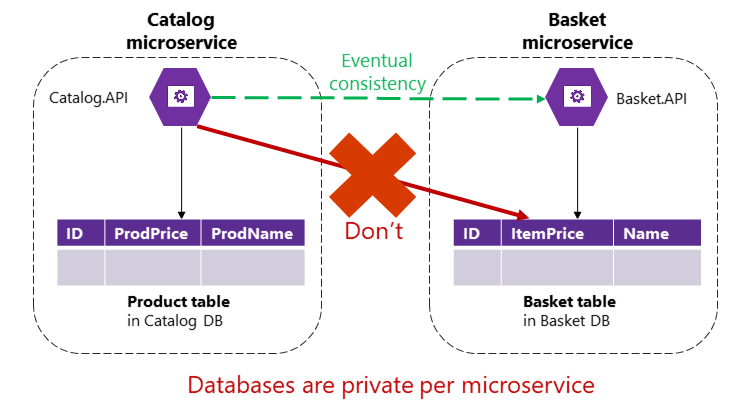
Abbildung 4-9. Ein Microservice kann nicht direkt auf eine Tabelle in einem anderen Microservice zugreifen.
Der Katalogmicroservice darf die Warenkorbtabelle nicht direkt aktualisieren, da diese Tabelle im Besitz des Warenkorbmicroservices ist. Um den Katalogmicroservice zu aktualisieren, darf der Microservice für Bestellungen stets nur eine asynchrone Kommunikation verwenden, z.B. Integrationsereignisse (nachrichten- und ereignisbasierte Kommunikation). So setzt die Referenzanwendung eShopOnContainers diese Art der Konsistenz für alle Microservices durch.
Wie aus dem CAP-Theorem hervorgeht, müssen Sie sich zwischen der Verfügbarkeit und einer starken ACID-Konsistenz entscheiden. Die meisten auf Microservices basierenden Szenarios erfordern die Verfügbarkeit und eine hohe Skalierbarkeit – und weniger eine starke Konsistenz. Unternehmenskritische Anwendungen müssen ununterbrochen verfügbar sein, und Entwickler können eine starke Konsistenz umgehen, indem sie Techniken für das Arbeiten mit schwachen oder letztlichen Konsistenzen verwenden. Dieser Ansatz wird von den meisten auf Microservices basierenden Architekturen genutzt.
Darüber hinaus verstoßen Transaktionen im ACID-Format bzw. mit Zweiphasencommit nicht nur gegen die Grundsätze von Microservices – die meisten NoSQL-Datenbanken (z.B. Microsoft Azure Cosmos DB, MongoDB) unterstützen auch keine Zweiphasencommit-Transaktionen, die i.d.R. in verteilten Datenbankszenarios vorkommen. Allerdings ist die Wahrung der Datenkonsistenz zwischen Services und Datenbanken unerlässlich. Diese Herausforderung betrifft auch die Frage, wie Änderungen in mehrere Microservices übertragen werden sollen, wenn bestimmte Daten wie der Name oder die Beschreibung des Produkts im Katalogmicroservice und im Warenkorbmicroservice redundant sein müssen.
Eine geeignete Lösung für dieses Problem ist die Verwendung einer letztlichen Konsistenz zwischen Microservices, die über eine ereignisgesteuerte Kommunikation und ein Veröffentlichen/Abonnieren-System umgesetzt wird. Diese Themen werden im Abschnitt Asynchronous event-driven communication (Asynchrone ereignisgesteuerte Kommunikation) weiter unten in diesem Leitfaden behandelt.
Herausforderung #4: Gestalten der Kommunikation über Microservicegrenzen hinweg
Die über die Grenzen von Microservices hinausgehende Kommunikation stellt eine echte Herausforderung dar. In diesem Kontext bezieht sich Kommunikation nicht darauf, welches Protokoll (HTTP und REST, AMQP, Messaging usw.) Sie verwenden sollten. Es geht vielmehr darum, welchen Kommunikationsstil Sie verwenden sollten, und insbesondere darum, wie stark Ihre Microservices gekoppelt sein sollten. Je nach dem Kopplungsgrad unterscheiden sich die Auswirkungen eines etwaigen Fehlers auf Ihr System erheblich.
In einem verteilten System wie einer auf Microservices basierenden Anwendung, in der so viele Artefakte vorhanden sind und in der Services über mehrere Server oder Hosts verteilt sind, werden irgendwann Komponenten ausfallen. Es wird zu einem Teilfehler oder sogar zu größeren Ausfällen kommen, sodass Sie Ihre Microservices und die Kommunikation zwischen ihnen unter Berücksichtigung der allgemeinen Risiken bei dieser Art von verteiltem System entwerfen müssen.
Eine beliebte Vorgehensweise besteht darin, HTTP- bzw. REST-basierte Microservices zu implementieren, die sich durch ihre Einfachheit auszeichnen. Ein HTTP-basierter Ansatz ist vollkommen akzeptabel, das Problem liegt vielmehr bei dessen Verwendung. Wenn Sie HTTP-Anforderungen und -Antworten nur für die Interaktion mit Ihren Microservices von Clientanwendungen oder API-Gateways verwenden, ist das in Ordnung. Wenn Sie jedoch lange Ketten synchroner HTTP-Aufrufe über Microservices erstellen, die über ihre Grenzen hinweg miteinander kommunizieren, als wären die Microservices Objekte in einer monolithischen Anwendung, wird es bei Ihrer Anwendung irgendwann zu Problemen kommen.
Stellen Sie sich z.B. vor, dass Ihre Clientanwendung einen HTTP-API-Aufruf für einen einzelnen Microservice wie den Microservice Bestellung tätigt. Wenn der Microservice für Bestellungen wiederum über HTTP weitere Microservices innerhalb desselben Anforderungs-/Antwortzyklus aufruft, erstellen Sie eine Kette von HTTP-Aufrufen. Dies klingt vielleicht zunächst sinnvoll. Bei dieser Vorgehensweise müssen jedoch einige wichtige Punkte berücksichtigt werden:
Blockierung und niedrige Leistung. Da sich HTTP synchron verhält, erhält die ursprüngliche Anforderung erst dann eine Antwort, wenn alle internen HTTP-Aufrufe abgeschlossen sind. Stellen Sie sich nun vor, dass die Anzahl dieser Aufrufe beträchtlich zunimmt und gleichzeitig einer der intermediären HTTP-Aufrufe eines Microservice blockiert ist. Nun ist die Leistung beeinträchtigt, und mit jeder weiteren HTTP-Anforderung ist die allgemeine Skalierbarkeit exponentiell betroffen.
Kopplung von Microservices mit HTTP. Unternehmensmicroservices sollten nicht mit anderen Unternehmensmicroservices gekoppelt werden. Im Idealfall sollten sie nichts über das Vorhandensein anderer Microservices „wissen“. Wenn Ihre Anwendung wie im Beispiel davon abhängt, dass Microservices gekoppelt werden, lässt sich eine Autonomie der einzelnen Microservices praktisch nicht realisieren.
Fehler in einem Microservice. Wenn Sie eine Kette von durch HTTP-Aufrufe verknüpften Microservices implementiert haben, führt der Ausfall eines dieser Microservices (der unweigerlich kommen wird) dazu, dass die gesamte Kette von Microservices fehlschlagen wird. Ein auf Microservices basierendes System sollte so konzipiert werden, dass es auch bei teilweisen Ausfällen so gut wie möglich weiterarbeitet. Selbst wenn Sie eine Clientlogik implementieren, die Wiederholungen mit exponentiellen Backoff- oder Trennmechanismen verwendet, wird es mit wachsender Komplexität der HTTP-Aufrufketten immer schwieriger, eine auf HTTP basierenden Fehlerstrategie zu implementieren.
Wenn Ihre internen Microservices miteinander kommunizieren, indem sie wie beschrieben Ketten von HTTP-Anforderungen erstellen, kann man in der Tat argumentieren, dass Sie zwar über eine monolithische Anwendung verfügen, diese aber auf HTTP zwischen den Prozessen anstatt auf Kommunikationsmechanismen zwischen den Prozessen basiert.
Um eine Autonomie der Microservices zu erzwingen und eine bessere Resilienz zu erhalten, sollten Sie daher die Kommunikation in Form von Anforderungs-/Antwortketten über Microservices auf ein Minimum reduzieren. Es wird empfohlen, für die Kommunikation zwischen Microservices ausschließlich eine asynchrone Interaktion zu verwenden, und zwar entweder mithilfe einer asynchronen nachrichten- und ereignisbasierten Kommunikation oder mithilfe von HTTP-Abrufen, die unabhängig vom ursprünglichen HTTP-Anforderungs-/Antwortzyklus sind.
Die Verwendung der asynchronen Kommunikation wird weiter unten in diesem Leitfaden in den Abschnitten Asynchrone Integration von Microservices erzwingt die Unabhängigkeit eines Microservices und Asynchrone nachrichtenbasierte Kommunikation mit zusätzlichen Details beschrieben.
Zusätzliche Ressourcen
CAP-Theorem
https://en.wikipedia.org/wiki/CAP_theoremLetztliche Konsistenz
https://en.wikipedia.org/wiki/Eventual_consistencyGrundlagen der Datenkonsistenz
https://video2.skills-academy.com/previous-versions/msp-n-p/dn589800(v=pandp.10)Martin Fowler. CQRS Command and Query Responsibility Segregation (CQRS: Zuständigkeitstrennung für Befehle und Abfragen)
https://martinfowler.com/bliki/CQRS.htmlMaterialisierte Sicht
https://video2.skills-academy.com/azure/architecture/patterns/materialized-viewCharles Row. ACID vs. BASE: Die pH-Verschiebung der Datenbanktransaktionsverarbeitung
https://www.dataversity.net/acid-vs-base-the-shifting-ph-of-database-transaction-processing/Ausgleichende Transaktion
https://video2.skills-academy.com/azure/architecture/patterns/compensating-transactionUdi Dahan. Service Oriented Composition (Dienstorientierte Komposition)
https://udidahan.com/2014/07/30/service-oriented-composition-with-video/