Entwickeln, Ausführen und Verwalten von Microsoft Fabric-Notebooks
Ein Microsoft Fabric-Notebook ist ein primäres Programmierelement für die Entwicklung von Apache Spark-Aufträgen und Machine Learning-Experimenten. Es handelt sich um eine webbasierte interaktive Oberfläche, die von Data Scientists und Data Engineers verwendet wird, um Code zu schreiben. Dabei profitieren diese von umfangreichen Visualisierungen und Markdown-Text. In diesem Artikel wird erläutert, wie Notebooks mit Codezellenvorgängen entwickelt und ausgeführt werden.
Entwickeln von Notebooks
Notebooks bestehen aus Zellen, bei denen es sich um einzelne Code- oder Textblöcke handelt, die unabhängig oder als Gruppe ausgeführt werden können.
Wir bieten umfangreiche Vorgänge zum Entwickeln von Notebooks:
- Hinzufügen einer Zelle
- Festlegen einer primären Sprache
- Verwenden mehrerer Sprachen
- IDE-artiges IntelliSense
- Codeausschnitte
- Einfügen von Codeschnipseln per Drag & Drop
- Einfügen von Bildern per Drag & Drop
- Textzelle mit Symbolleisten-Schaltflächen formatieren
- Rückgängigmachen oder Wiederholen von Zellenvorgängen
- Verschieben einer Zelle
- Löschen einer Zelle
- Reduzieren einer Zelleneingabe
- Reduzieren einer Zellenausgabe
- Zellenausgabesicherheit
- Sperren oder Einfrieren einer Zelle
- Notebookinhalte
- Markdown-Faltung
- Suchen und Ersetzen
Hinzufügen einer Zelle
Es gibt mehrere Möglichkeiten, um Ihrem Notebook eine neue Zelle hinzuzufügen.
Zeigen Sie mit dem Mauszeiger auf den Bereich zwischen zwei Zellen, und wählen Sie Code oder Markdown aus.
Verwenden Sie Tastenkombinationen im Befehlsmodus. Drücken Sie A, um eine Zelle oberhalb der aktuellen Zelle einzufügen. Drücken Sie B, um eine Zelle unterhalb der aktuellen Zelle einzufügen.
Festlegen einer primären Sprache
Fabric-Notebooks unterstützen derzeit vier Apache Spark-Sprachen:
- PySpark (Python)
- Spark (Scala)
- Spark SQL
- SparkR
Sie können die primäre Sprache für neu hinzugefügte Zellen in der Dropdownliste in der oberen Befehlsleiste festlegen.
Verwenden mehrerer Sprachen
Sie können in einem Notebook mehrere Sprachen verwenden, indem Sie den Magic-Befehl für die Sprache am Anfang einer Zelle angeben. Sie können die Zellensprache auch über die Sprachauswahl umstellen. In der folgenden Tabelle sind die Magic-Befehle zum Wechseln von Zellensprachen aufgelistet.

| Magic-Befehl | Sprache | Beschreibung |
|---|---|---|
| %%pyspark | Python | Eine Python-Abfrage im Apache Spark-Kontext ausführen. |
| %%spark | Scala | Eine Scala-Abfrage im Apache Spark-Kontext ausführen. |
| %%sql | SparkSQL | Eine SparkSQL-Abfrage im Apache Spark-Kontext ausführen. |
| %%html | Html | Eine HTML-Abfrage im Apache Spark-Kontext ausführen. |
| %%sparkr | R | Eine R-Abfrage im Apache Spark-Kontext ausführen. |
IDE-artiges IntelliSense
Fabric-Notebooks sind in den Monaco-Editor integriert, um den Zellen-Editor mit IntelliSense im IDE-Stil auszustatten. Syntaxhervorhebung, Fehlermarkierungen und automatische Codevervollständigungen helfen Ihnen dabei, schnell Code zu schreiben und Probleme zu erkennen.
Die IntelliSense-Funktionen befinden sich in unterschiedlichen Stadien der Entwicklung für verschiedene Sprachen. Die folgende Tabelle zeigt die von Fabric unterstützten Features:
| Sprachen | Syntaxhervorhebung | Syntaxfehlermarkierungen | Codevervollständigung für Syntax | Codevervollständigung für Variablen | Codevervollständigung für Systemfunktionen | Codevervollständigung für Benutzerfunktionen | Intelligenter Einzug | Codefaltung |
|---|---|---|---|---|---|---|---|---|
| PySpark (Python) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
| Spark (Scala) | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
| SparkSQL | Ja | Ja | Ja | Ja | Ja | Keine | Ja | Ja |
| SparkR | Ja | Ja | Ja | Ja | Ja | Ja | Ja | Ja |
Hinweis
Sie müssen über eine aktive Apache Spark-Sitzung verfügen, um IntelliSense-Codevervollständigung verwenden zu können.
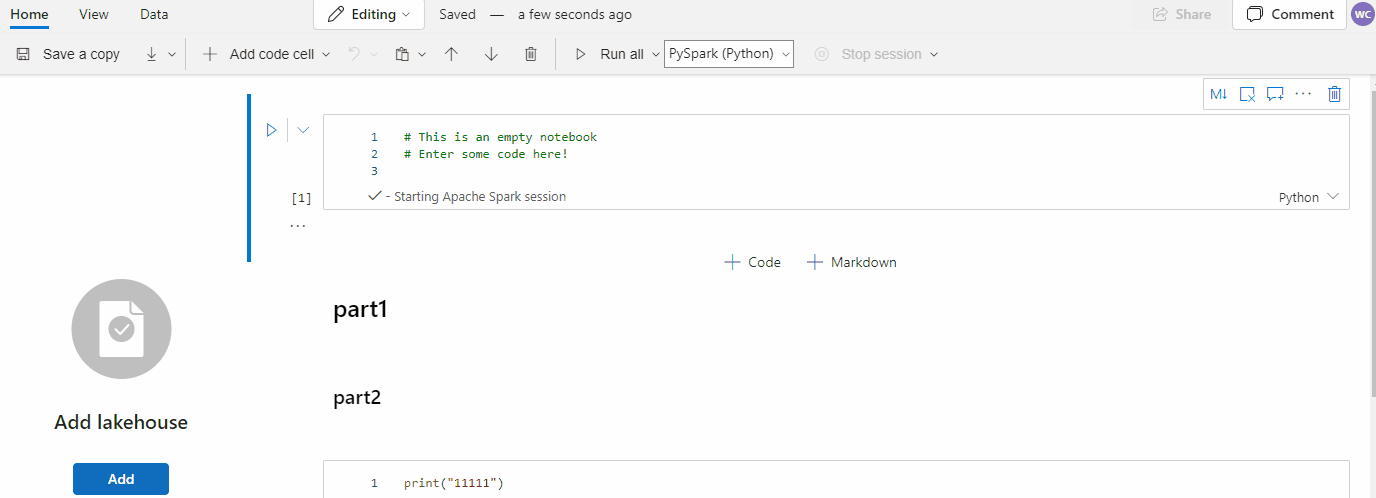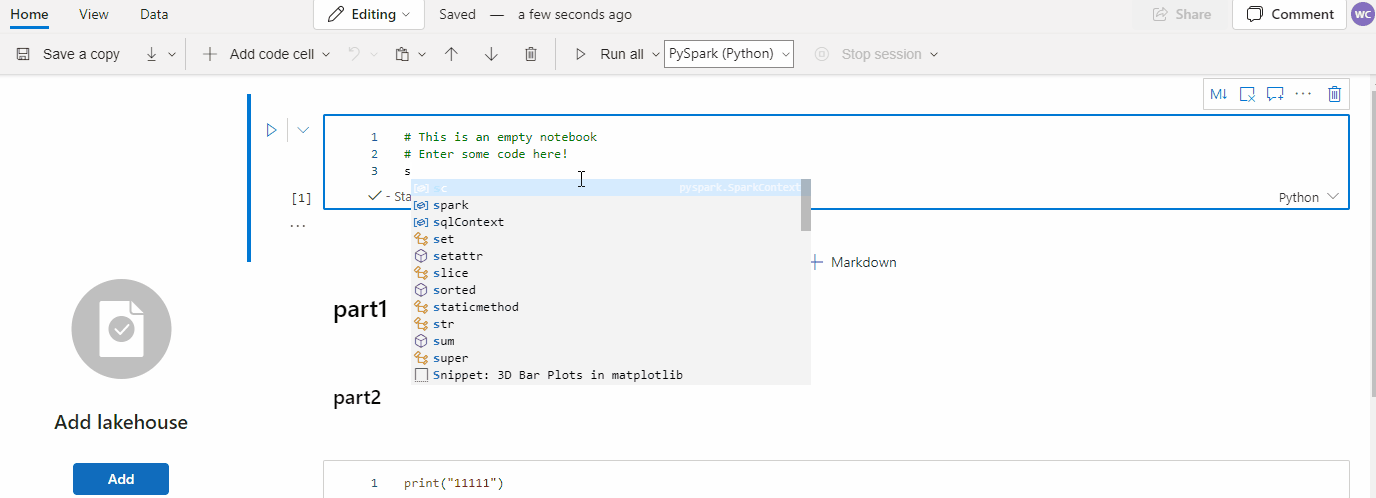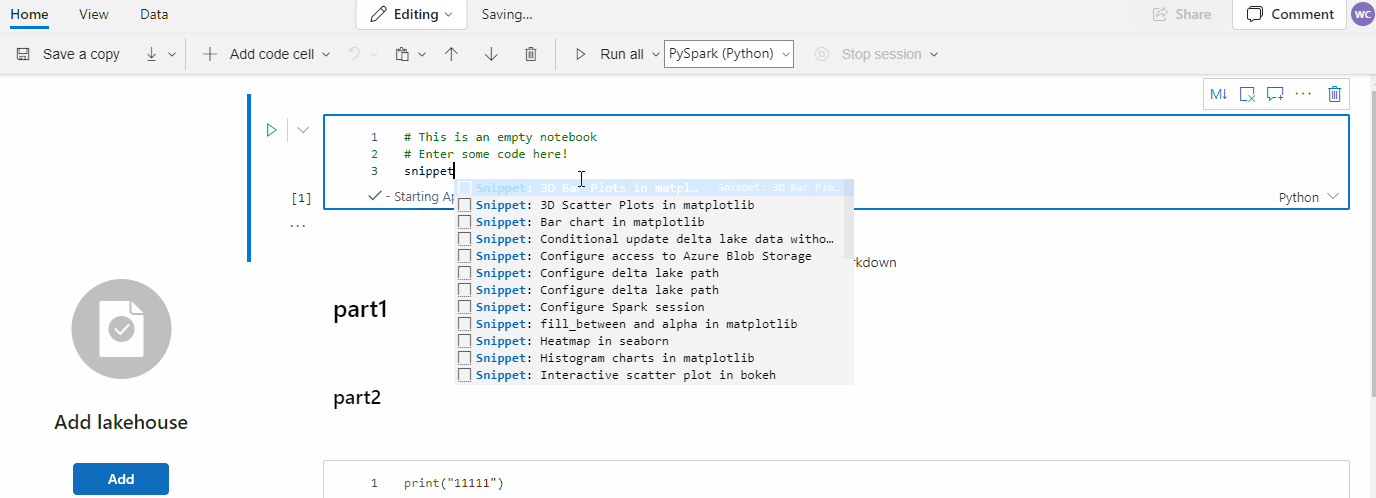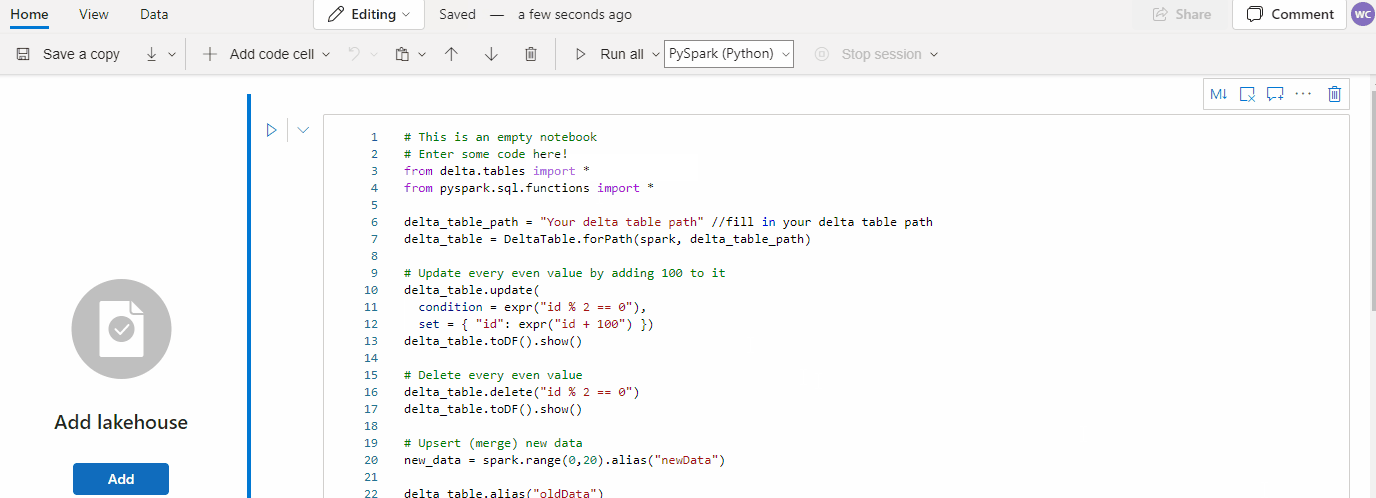
Codeausschnitte
Fabric-Notebooks enthalten Codeschnipsel, mit denen Sie häufig verwendete Codemuster einfach schreiben können, darunter:
- Lesen von Daten als Apache Spark-Dataframe
- Zeichnen von Diagrammen mit Matplotlib
Codeausschnitte werden in Tastaturkurzbefehlen im IDE Stil in IntelliSense gemeinsam mit anderen Vorschlägen angezeigt. Der Inhalt der Codeschnipsel richtet sich nach der Codezellensprache. Sie können verfügbare Codeschnipsel anzeigen, indem Sie Codeschnipsel eingeben. Sie können auch ein beliebiges Schlüsselwort eingeben, um eine Liste relevanter Codeschnipsel anzuzeigen. Wenn Sie beispielsweise read eingeben, wird eine Liste der Codeschnipsel zum Lesen von Daten aus verschiedenen Datenquellen angezeigt.
Einfügen von Codeschnipseln per Drag & Drop
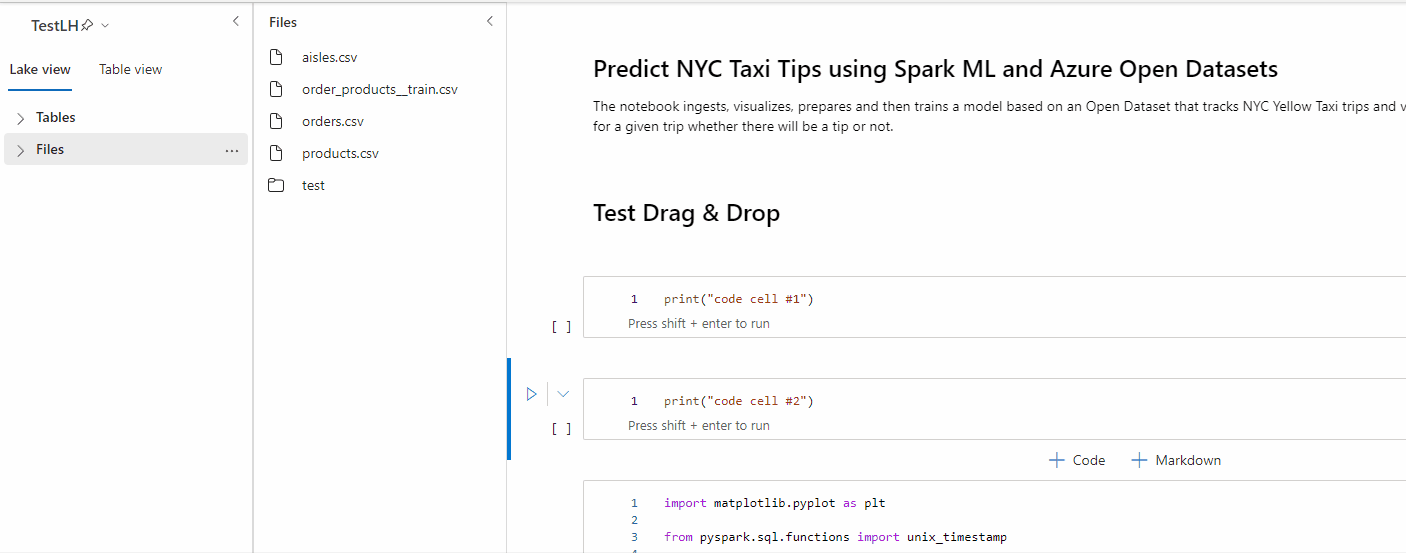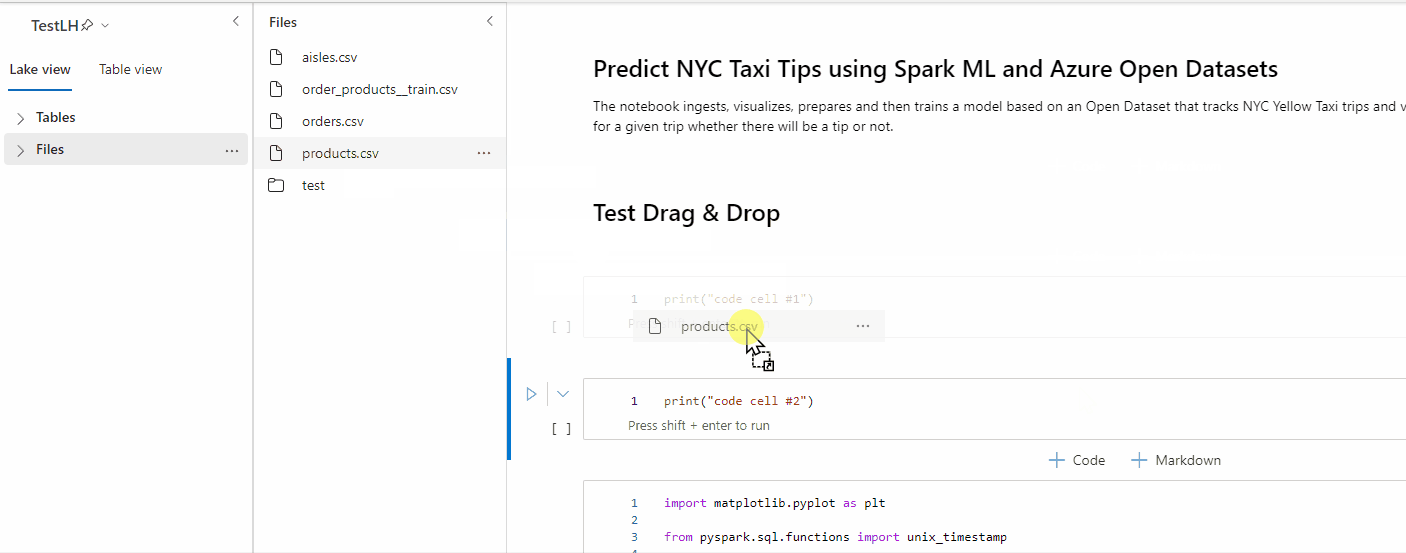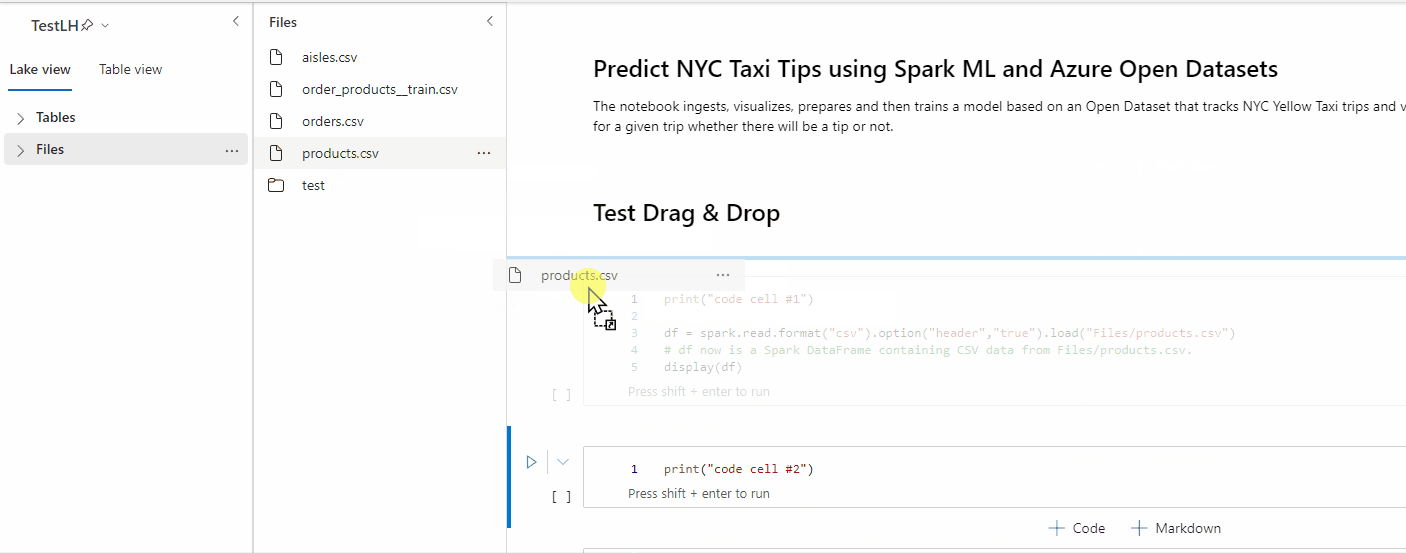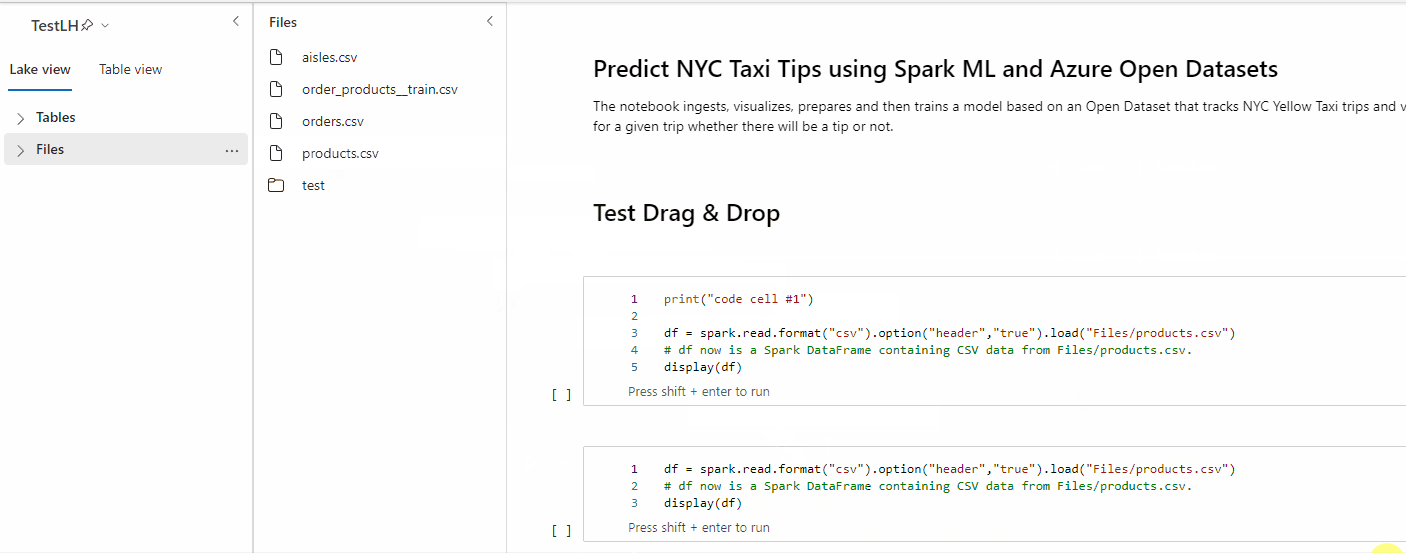
Verwenden Sie das Drag & Drop-Feature, um Daten bequem aus dem Lakehouse-Explorer zu lesen. Hier werden mehrere Dateitypen unterstützt, darunter Textdateien, Tabellen und Bilder. Sie können Daten entweder in eine vorhandene Zelle oder eine neue Zelle einfügen. Das Notebook generiert den Codeschnipsel entsprechend, um eine Vorschau der Daten anzuzeigen.
Einfügen von Bildern per Drag & Drop
Verwenden Sie das Drag & Drop-Feature, um Bilder aus dem Browser oder von Ihrem lokalen Computer bequem in eine Markdown-Zelle einzufügen.
Textzelle mit Symbolleisten-Schaltflächen formatieren
Verwenden Sie die Formatschaltflächen auf der Textzellen-Symbolleiste, um allgemeine Markdown-Aktionen auszuführen.

Rückgängigmachen oder Wiederholen von Zellenvorgängen
Wählen Sie Rückgängig oder Wiederholen aus, oder drücken Sie Z oder UMSCHALT+Z, um die letzten Zellenvorgänge rückgängig zu machen. Sie können maximal die zehn letzten Zellenvorgänge rückgängig machen oder wiederholen.

Unterstützte Rückgängig-Zellenvorgänge:
- Zelle einfügen oder löschen. Sie können die gelöschten Vorgänge rückgängig machen, indem Sie Rückgängig auswählen (der Textinhalt wird zusammen mit der Zelle beibehalten).
- Eine Zelle neu anordnen.
- Umschalten von Parametern.
- Konvertieren zwischen der Codezelle und der Markdown-Zelle.
Hinweis
Textvorgänge in der Zelle und die Kommentare in Codezellen können nicht rückgängig gemacht werden. Sie können maximal die zehn letzten Zellenvorgänge rückgängig machen oder wiederholen.
Verschieben einer Zelle
Sie können den leeren Teil einer Zelle auswählen und die Zelle an die gewünschte Position ziehen.
Sie können die ausgewählte Zelle auch mithilfe der Menübandoptionen Nach oben und Nach unten verschieben.

Löschen einer Zelle
Wählen Sie zum Löschen einer Zelle die Schaltfläche „Löschen“ auf der rechten Seite der Zelle aus.
Sie können auch Tastenkombinationen im Befehlsmodus verwenden. Drücken Sie UMSCHALT+D, um die aktuelle Zelle zu löschen.
Reduzieren einer Zelleneingabe
Wählen Sie auf der Zellensymbolleiste die Auslassungspunkte für Weitere Befehle (...) und dann Eingabe ausblenden aus, um die Eingabe der aktuellen Zelle zu reduzieren. Wenn Sie sie wieder erweitern möchten, wählen Sie Eingabe anzeigen aus, während die Zelle reduziert ist.
Reduzieren einer Zellenausgabe
Wählen Sie auf der Zellensymbolleiste die Auslassungspunkte für Weitere Befehle (...) und dann Ausgabe ausblenden aus, um die Ausgabe der aktuellen Zelle zu reduzieren. Wenn Sie sie wieder erweitern möchten, wählen Sie Ausgabe anzeigen aus, während die Zellenausgabe reduziert ist.
Zellenausgabesicherheit
Mithilfe von OneLake-Datenzugriffsrollen (Vorschau) können Benutzer den Zugriff auf bestimmte Ordner in einem Lakehouse während Notebook-Abfragen konfigurieren. Benutzern ohne Zugriff auf einen Ordner oder eine Tabelle wird bei der Abfrageausführung eine Fehlermeldung 'Keine Berechtigung' angezeigt.
Wichtig
Die Sicherheit gilt nur während der Abfrageausführung. Notebook-Zellen, die Abfrageergebnisse enthalten, können von Benutzern aufgerufen werden, die nicht dazu berechtigt sind, Abfragen direkt für die Daten auszuführen.
Sperren oder Einfrieren einer Zelle
Durch das Sperren und Einfrieren von Zellen können Sie Zellen schreibgeschützt machen oder die Ausführung einzelner Zellen verhindern.

Zusammenführen und Teilen von Zellen
Sie können Mit vorheriger Zelle verknüpfen oder Mit nächster Zelle verknüpfen verwenden, um verwandte Zellen bequem zusammenzuführen.
Wenn Sie Zelle teilen auswählen, können Sie irrelevante Anweisungen auf mehrere Zellen aufteilen. Der Vorgang teilt den Code entsprechend der Zeilenposition des Cursors auf.

Notebookinhalte
Durch Auswählen von „Gliederung“ oder „Inhaltsverzeichnis“ wird der erste Markdown-Header einer beliebigen Markdown-Zelle in einem Randleistenfenster dargestellt, damit Sie schnell zu diesem navigieren können. Die Gliederungsrandleiste ist in der Größe veränderbar und reduzierbar, damit sie optimal an den Bildschirm angepasst werden kann. Wählen Sie die Schaltfläche Inhalt auf der Notebookbefehlsleiste aus, um die Randleiste ein- oder auszublenden.

Markdown-Faltung
Mit der Option für die Markdown-Faltung können Sie Zellen unter einer Markdown-Zelle ausblenden, die eine Überschrift enthält. Die Markdown-Zelle und die zugehörigen ausgeblendeten Zellen werden beim Ausführen von Zellvorgängen wie mehrere zusammenhängende, ausgewählte Zellen behandelt.
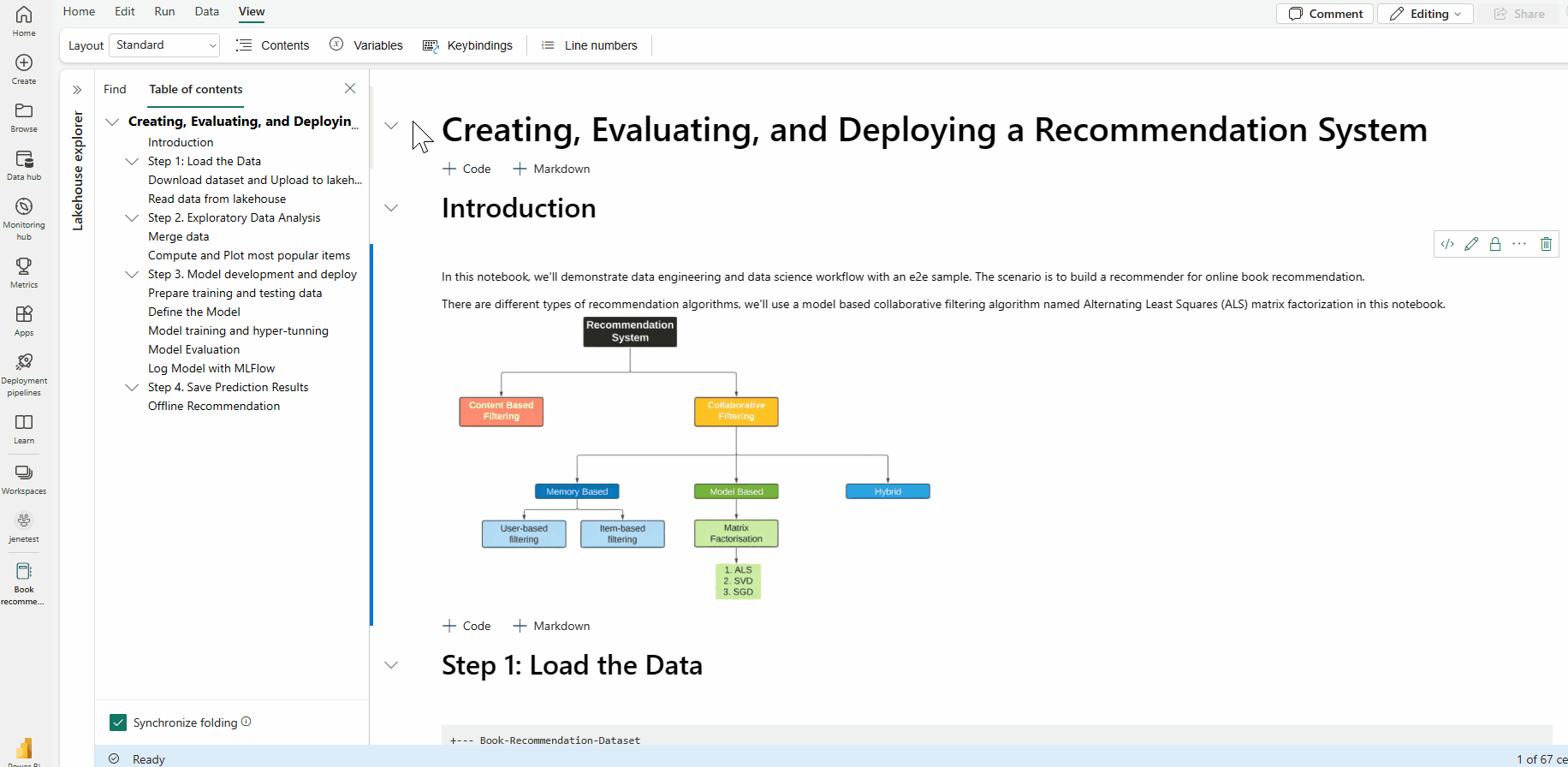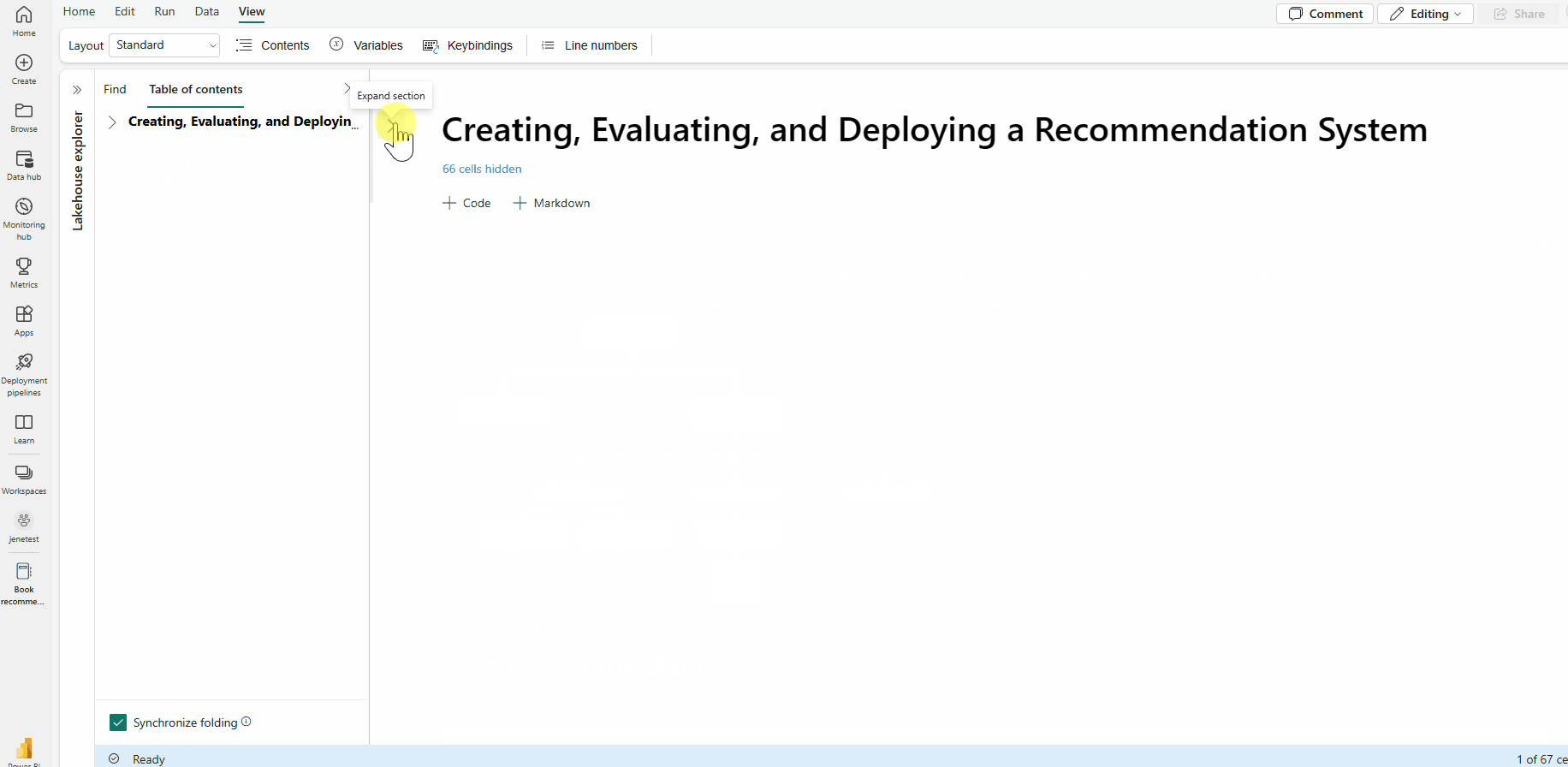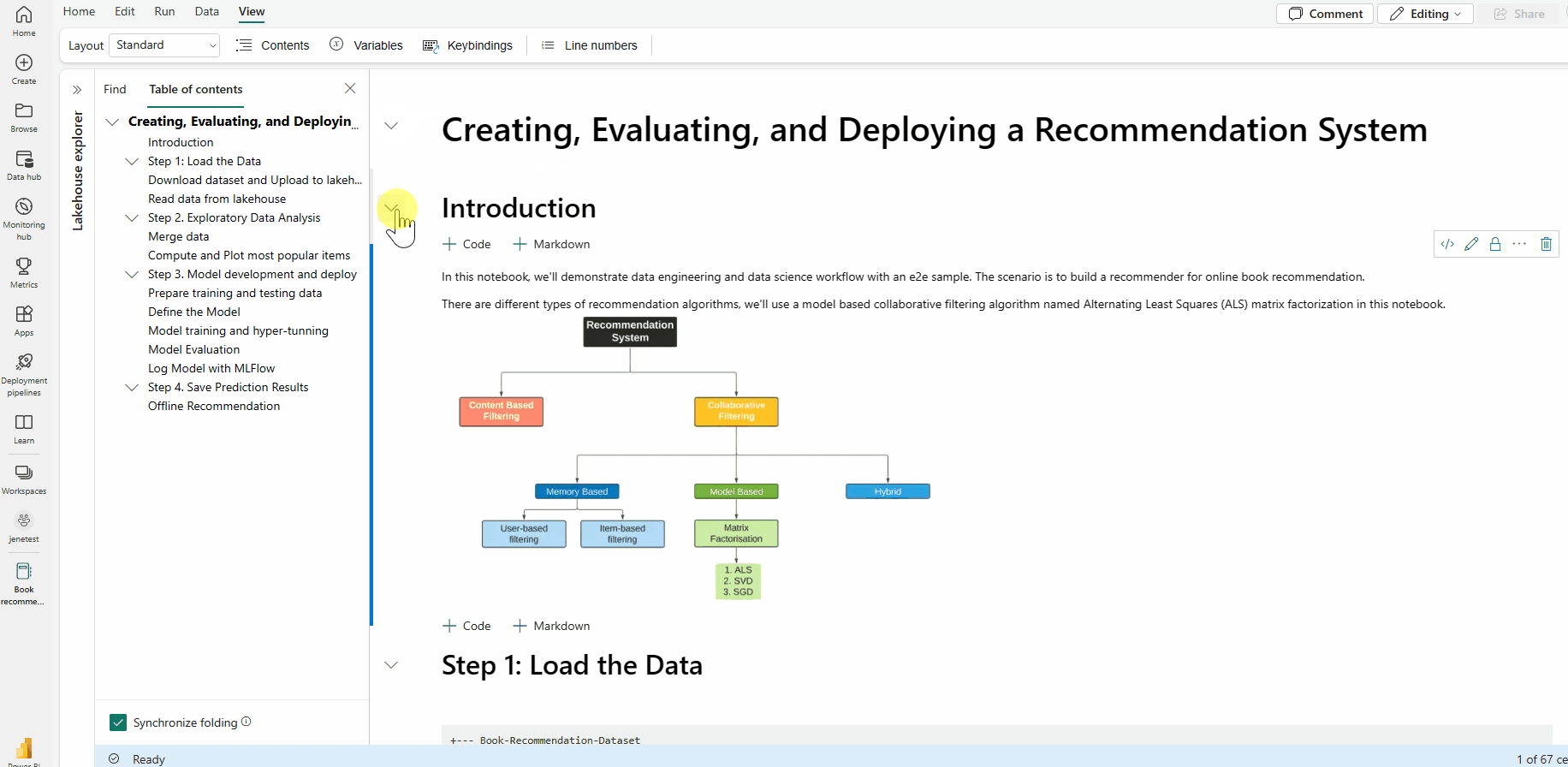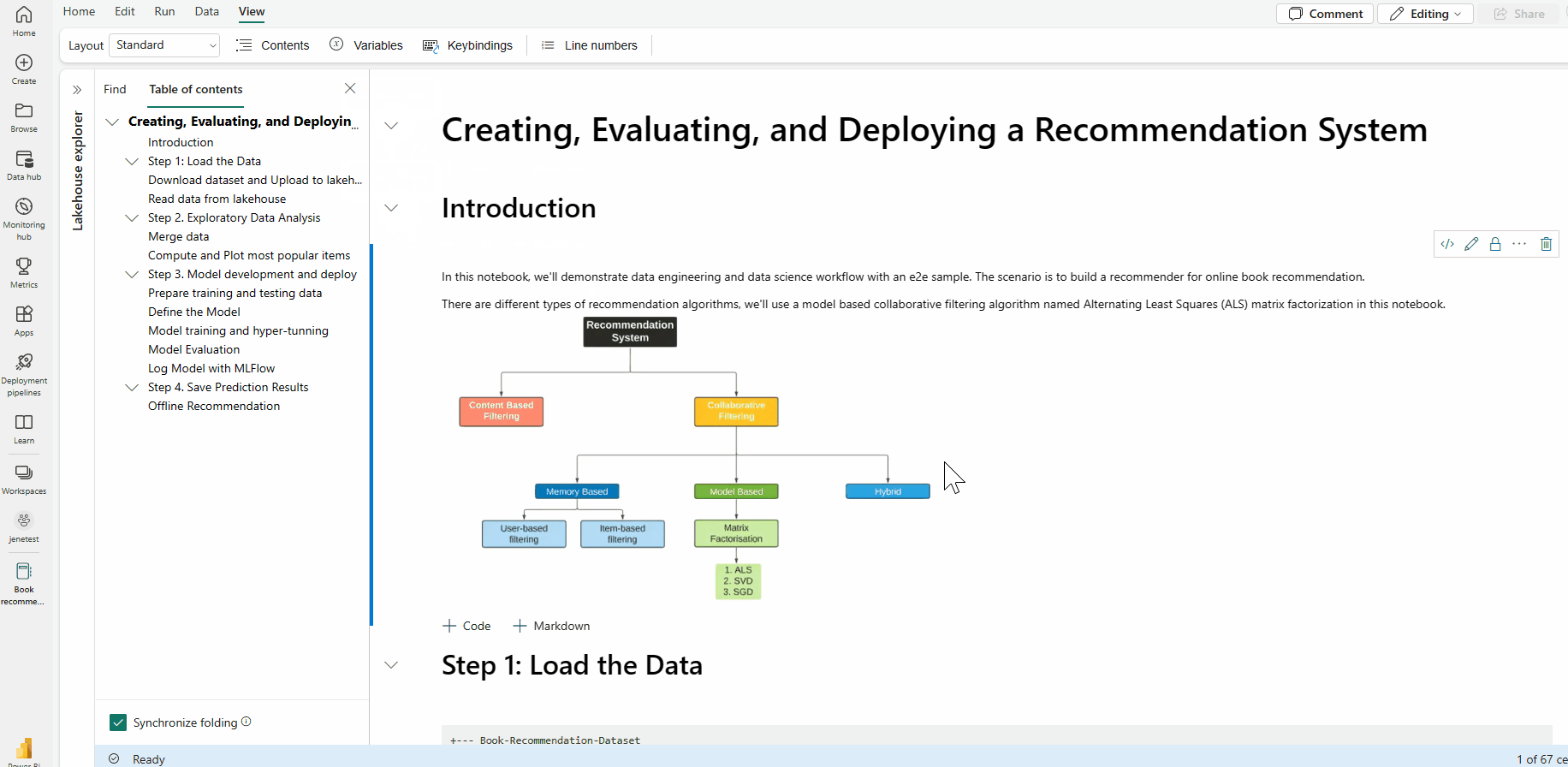
Suchen und Ersetzen
Mit der Option „Suchen und Ersetzen“ können Sie Schlüsselwörter oder Ausdrücke im Notebook-Inhalt abgleichen und suchen. Sie können die Zielzeichenfolge auch ganz einfach durch eine neue Zeichenfolge ersetzen.

Ausführen von Notebooks
Sie können die Codezellen in Ihrem Notebook einzeln oder alle gleichzeitig ausführen. Status und Fortschritt jeder Zelle werden im Notebook dargestellt.
Ausführen einer Zelle
Es gibt mehrere Methoden, um den Code in einer Zelle auszuführen.
Zeigen Sie mit dem Mauszeiger auf die Zelle, die Sie ausführen möchten, und wählen Sie die Schaltfläche Zelle ausführen aus, oder drücken Sie STRG+EINGABE.
Verwenden Sie Tastenkombinationen im Befehlsmodus. Drücken Sie UMSCHALT+EINGABE, um die aktuelle Zelle auszuführen und die nächste Zelle auszuwählen. Drücken Sie ALT+EINGABE, um die aktuelle Zelle auszuführen und eine neue Zelle einzufügen.
Ausführen aller Zellen
Wählen Sie die Schaltfläche Alle ausführen aus, um alle Zellen im aktuellen Notebook nacheinander auszuführen.
Ausführen aller darüber- oder darunterliegenden Zellen
Erweitern Sie die Dropdownliste über die Schaltfläche Alle ausführen, und wählen Sie dann Zellen oberhalb ausführen aus, um alle Zellen oberhalb der aktuellen Zelle nacheinander auszuführen. Wählen Sie Zellen unterhalb ausführen aus, um die aktuelle Zelle und alle Zellen unterhalb der aktuellen nacheinander auszuführen.

Abbrechen aller ausgeführten Zellen
Wählen Sie Alle abbrechen aus, um die ausgeführten oder in der Warteschlange wartenden Zellen abzubrechen.
Beenden der Sitzung
Die Option Sitzung beenden bricht die laufenden und wartenden Zellen ab und beendet die aktuelle Sitzung. Sie können eine neue Sitzung starten, indem Sie die Option „Ausführen“ erneut auswählen.

Referenzausführung
Referenzausführung eines Notebooks
Neben der notebookutils-Verweisausführungs-API können Sie auch den Magic-Befehl %run <notebook name> verwenden, um auf ein anderes Notebook im Kontext des aktuellen Notebooks zu verweisen. Alle im Referenznotebook definierten Variablen sind im aktuellen Notebook verfügbar. Der Magic-Befehl %run unterstützt geschachtelte Aufrufe, aber keine rekursiven Aufrufe. Es wird eine Ausnahme angezeigt, wenn die Anweisungstiefe größer als fünf ist.
Beispiel: %run Notebook1 { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }.
Notebookverweise funktionieren sowohl im interaktiven Modus als auch in der Pipeline.
Hinweis
- Der Befehl
%rununterstützt derzeit nur Verweise auf Notebooks, die sich im selben Arbeitsbereich wie das aktuelle Notebook befinden. - Der Befehl
%rununterstützt derzeit nur bis zu vier Parameterwerttypen:int,float,boolundstring. Der Vorgang zum Ersetzen von Variablen wird nicht unterstützt. - Der Befehl
%rununterstützt keine geschachtelten Verweise mit einer Tiefe größer als fünf.
Referenzausführung eines Skripts
Mit dem Befehl %run können Sie außerdem Python- oder SQL-Dateien ausführen, die in den integrierten Ressourcen des Notebooks gespeichert sind, damit Sie die Quellcodedateien bequem im Notebook ausführen können.
%run [-b/--builtin -c/--current] [script_file.py/.sql] [variables ...]
Optionen:
- -b/--builtin: Diese Option gibt an, dass der Befehl die angegebene Skriptdatei aus den integrierten Ressourcen des Notizbuchs findet und ausführt.
- -c/--current: Mit dieser Option wird sichergestellt, dass der Befehl immer die integrierten Ressourcen des aktuellen Notebooks nutzt, auch wenn das aktuelle Notebook von anderen Notebooks referenziert wird.
Beispiele:
Zum Ausführen von script_file.py über die integrierten Ressourcen:
%run -b script_file.pyZum Ausführen von script_file.sql über die integrierten Ressourcen:
%run -b script_file.sqlZum Ausführen von script_file.py über die integrierten Ressourcen mit spezifischen Variablen:
%run -b script_file.py { "parameterInt": 1, "parameterFloat": 2.5, "parameterBool": true, "parameterString": "abc" }
Hinweis
Wenn -b/–builtin im Befehl nicht enthalten ist, erfolgt die Suche und Ausführung des Notebookelements im selben Arbeitsbereich statt in den integrierten Ressourcen.
Nutzungsbeispiel für geschachtelte Ausführung:
- Angenommen, wir haben zwei Notebooks.
- Notebook1: Enthält script_file1.py in den integrierten Ressourcen.
- Notebook2: Enthält script_file2.py in den integrierten Ressourcen.
- Notebook1 soll als Stammnotebook mit folgendem Inhalt dienen:
%run Notebook2. - Dann lautet die Nutzungsanweisung in Notebook2 wie folgt:
- Um script_file1.py in Notebook1(das Stammnotizbuch) auszuführen, lautet der Code:
%run -b script_file1.py - Um script_file2.py in Notebook2(dem aktuellen Notizbuch) auszuführen, lautet der Code:
%run -b -c script_file2.py
- Um script_file1.py in Notebook1(das Stammnotizbuch) auszuführen, lautet der Code:
Variablen-Explorer
Fabric-Notebooks verfügen über einen integrierten Variablen-Explorer, in dem die Liste der Variablennamen, -typen, -längen und -werte in der aktuellen Spark-Sitzung für PySpark-Zellen (Python) angezeigt werden. Weitere Variablen werden automatisch angezeigt, wenn sie in den Codezellen definiert werden. Durch Klicken auf die einzelnen Spaltenüberschriften werden die Variablen in der Tabelle sortiert.
Wählen Sie die Schaltfläche Variablen im Menüband Ansicht des Notebooks aus, um den Variablen-Explorer ein- oder auszublenden.

Hinweis
Der Variablen-Explorer unterstützt nur Python.
Zellenstatusindikator
Unterhalb der Zelle wird ein schrittweiser Zellenausführungsstatus angezeigt, damit Sie den aktuellen Fortschritt verfolgen können. Nachdem die Ausführung der Zelle abgeschlossen wurde, wird eine Ausführungszusammenfassung mit Gesamtdauer und Endzeit angezeigt, die zur späteren Verwendung dort gespeichert wird.

Inlineindikator für Apache Spark-Aufträge
Das Fabric-Notebook basiert auf Apache Spark. Codezellen werden remote im Apache Spark-Cluster ausgeführt. Eine Spark-Auftragsstatusanzeige wird mit einem Statusbalken in Echtzeit angezeigt, um Ihnen den Status der Auftragsausführung zu verdeutlichen. Anhand der Anzahl der Aufgaben pro Auftrag oder Phase können Sie die parallele Ebene Ihres Spark-Auftrags identifizieren. Sie können außerdem die Spark-Benutzeroberfläche eines spezifischen Auftrags (oder einer Phase) erweitern, indem Sie den Link im Auftragsnamen (oder Phasennamen) auswählen.
Neben dem Statusindikator finden Sie auch das Echtzeitprotokoll auf Zellenebene, und der Bereich Diagnose kann Ihnen nützliche Vorschläge liefern, um den Code zu optimieren und zu debuggen.

Unter Weitere Aktionen können Sie ganz einfach zur Seite Spark-Anwendungsdetails und zur Seite Spark-Webbenutzeroberfläche navigieren.

Geheimnisbearbeitung
Um zu verhindern, dass Anmeldeinformationen beim Ausführen von Notebooks versehentlich offengelegt werden, unterstützen Fabric-Notebook die Geheimnisbearbeitung, um die in der Zellenausgabe angezeigten Geheimwerte durch [REDACTED] zu ersetzen. Die Geheimnisbearbeitung ist für Python, Scala und R verfügbar.

Magic-Befehle in einem Notebook
Integrierte Magic-Befehle
Sie können bekannte IPython-Magic-Befehle in Fabric-Notebooks verwenden. In der folgenden Liste finden Sie die derzeit verfügbaren Magic-Befehle.
Hinweis
Nur die folgenden Magic-Befehle werden in einer Fabric-Pipeline unterstützt: %%pyspark, %%spark, %%csharp, %%sql, %%configure.
Verfügbare Magic-Befehle für Zeilen: %lsmagic, %time, %timeit, %history, %run, %load, %alias, %alias_magic, %autoawait, %autocall, %automagic, %bookmark, %cd, %colors, %dhist, %dirs, %doctest_mode, %killbgscripts, %load_ext, %logoff, %logon, %logstart, %logstate, %logstop, %magic, %matplotlib, %page, %pastebin, %pdef, %pfile, %pinfo, %pinfo2, %popd, %pprint, %precision, %prun, %psearch, %psource, %pushd, %pwd, %pycat, %quickref, %rehashx, %reload_ext, %reset, %reset_selective, %sx, %system, %tb, %unalias, %unload_ext, %who, %who_ls, %whos, %xdel und %xmode.
Das Fabric-Notizbuch unterstützt auch die verbesserten Befehle %pip und %conda für die Bibliotheksverwaltung. Weitere Informationen zur Verwendung finden Sie unter Verwalten von Apache Spark-Bibliotheken in Microsoft Fabric.
Verfügbare Magic-Befehle für Zellen: %%time, %%timeit, %%capture, %%writefile, %%sql, %%pyspark, %%spark, %%csharp, %%configure, %%html, %%bash, %%markdown, %%perl, %%script, %%sh.
Benutzerdefinierte Magic-Befehle
Sie können auch weitere benutzerdefinierte Magic-Befehle erstellen, um Ihre spezifischen Anforderungen zu erfüllen. Hier sehen Sie ein Beispiel:
Erstellen Sie ein Notebook mit dem Namen MyLakehouseModule.

Verweisen Sie in einem anderen Notebook auf MyLakehouseModule und die Magic-Befehle. Mit diesem Prozess können Sie Ihr Projekt bequem mit Notebooks organisieren, die unterschiedliche Sprachen verwenden.



IPython-Widgets
IPython-Widgets sind ereignisbehaftete Python-Objekte mit einer Darstellung im Browser. Sie können IPython-Widgets als Low-Code-Steuerelemente (z. B. für Schieberegler oder Textfelder) in Ihrem Notebook verwenden, genau wie in Jupyter Notebook. Dies funktioniert derzeit nur in einem Python-Kontext.
So verwenden Sie IPython-Widgets
Importieren Sie zuerst das Modul ipywidgets, um das Jupyter-Widgetframework zu verwenden.
import ipywidgets as widgetsVerwenden Sie die globale Funktion display, um ein Widget zu rendern, oder einen Ausdruck vom Typ widget in der letzten Zeile der Codezelle.
slider = widgets.IntSlider() display(slider)Führen Sie die Zelle aus. Das Widget wird im Ausgabebereich angezeigt.
slider = widgets.IntSlider() display(slider)
Verwenden Sie mehrere display()-Aufrufe, um dieselbe Widgetinstanz mehrmals zu rendern. Sie bleiben miteinander synchronisiert.
slider = widgets.IntSlider() display(slider) display(slider)
Um zwei Widgets unabhängig voneinander zu rendern, erstellen Sie zwei Widgetinstanzen:
slider1 = widgets.IntSlider() slider2 = widgets.IntSlider() display(slider1) display(slider2)



Unterstützte Widgets
| Widgettyp | Widgets |
|---|---|
| Numerische Widgets | IntSlider, FloatSlider, FloatLogSlider, IntRangeSlider, FloatRangeSlider, IntProgress, FloatProgress, BoundedIntText, BoundedFloatText, IntText, FloatText |
| Boolesche Widgets | ToggleButton, Checkbox, Valid |
| Auswahlwidgets | Dropdown, RadioButtons, Select, SelectionSlider, SelectionRangeSlider, ToggleButtons, SelectMultiple |
| Zeichenfolgenwidgets | Text, Text area, Combobox, Password, Label, HTML, HTML Math, Image, Button |
| Wiedergabewidgets (Animation) | Date picker, Color picker, Controller (Datumsauswahl, Farbauswahl, Controller) |
| Container- oder Layoutwidgets | Box, HBox, VBox, GridBox, Accordion, Tabs, Stacked |
Bekannte Einschränkungen
Die folgenden Widgets werden noch nicht unterstützt. Die folgenden Problemumgehungen sind verfügbar:
Funktionalität Problemumgehung Output-Widget Sie können stattdessen die print()-Funktion verwenden, um Text in stdout zu schreiben. widgets.jslink() Sie können die widgets.link()-Funktion verwenden, um zwei ähnliche Widgets zu verknüpfen. FileUpload-Widget Wird noch nicht unterstützt. Die globale Fabric-Funktion display unterstützt das Anzeigen mehrerer Widgets in einem Aufruf nicht (z. B. display(a, b)). Dieses Verhalten unterscheidet sich von der IPython-Funktion display.
Wenn Sie ein Notebook schließen, das ein IPython-Widget enthält, können Sie es erst anzeigen oder damit interagieren, wenn Sie die entsprechende Zelle erneut ausführen.
Die Interaktionsfunktion (ipywidgets.interact) wird nicht unterstützt.
Integrieren eines Notebooks
Festlegen einer Parameterzelle
Um Ihr Notebook zu parametrisieren, wählen Sie die Auslassungspunkte (...) aus, um auf der Zellensymbolleiste weitere Befehle auszuklappen. Klicken Sie dann auf Parameterzelle umschalten, um die Zelle als Parameterzelle festzulegen.

Die Parameterzelle ist nützlich für die Integration eines Notebooks in eine Pipeline. Die Pipelineaktivität sucht nach der Parameterzelle und behandelt diese Zelle als Standard für die Parameter, die zur Ausführungszeit übermittelt werden. Die Ausführungs-Engine fügt eine neue Zelle mit Eingabeparametern unterhalb der Parameterzelle hinzu, um die Standardwerte zu überschreiben.
Zuweisen von Parameterwerten über eine Pipeline
Sobald Sie ein Notebook mit Parametern erstellt haben, können Sie dieses über eine Pipeline mit der Fabric-Notebookaktivität ausführen. Nachdem Sie die Aktivität zu Ihrer Pipelinecanvas hinzugefügt haben, können Sie die Parameterwerte auf der Registerkarte Einstellungen im Abschnitt Basisparameter festlegen.

Beim Zuweisen von Parameterwerten können Sie die Pipelineausdruckssprache oder Funktionen und Variablen verwenden.
Magic-Befehl für Spark-Sitzungskonfiguration
Sie können Ihre Spark-Sitzung mit dem Magic-Befehl %%configure personalisieren. Ein Fabric-Notebook unterstützt angepasste virtuelle Kerne, Arbeitsspeicher für den Treiber und Executor, Apache Spark-Eigenschaften, Bereitstellungspunkte, Pools und das Standard-Lakehouse der Notebook-Sitzung. Sie können sowohl in interaktiven Notebook- als auch in Pipeline-Notebook-Aktivitäten verwendet werden. Es wird empfohlen, den Befehl %%configure am Anfang ihres Notebooks auszuführen. Andernfalls müssen Sie die Spark-Sitzung neu starten, damit die Einstellungen wirksam werden.
%%configure
{
// You can get a list of valid parameters to config the session from https://github.com/cloudera/livy#request-body.
"driverMemory": "28g", // Recommended values: ["28g", "56g", "112g", "224g", "400g"]
"driverCores": 4, // Recommended values: [4, 8, 16, 32, 64]
"executorMemory": "28g",
"executorCores": 4,
"jars": ["abfs[s]: //<file_system>@<account_name>.dfs.core.windows.net/<path>/myjar.jar", "wasb[s]: //<containername>@<accountname>.blob.core.windows.net/<path>/myjar1.jar"],
"conf":
{
// Example of customized property, you can specify count of lines that Spark SQL returns by configuring "livy.rsc.sql.num-rows".
"livy.rsc.sql.num-rows": "3000",
"spark.log.level": "ALL"
},
"defaultLakehouse": { // This overwrites the default lakehouse for current session
"name": "<lakehouse-name>",
"id": "<(optional) lakehouse-id>",
"workspaceId": "<(optional) workspace-id-that-contains-the-lakehouse>" // Add workspace ID if it's from another workspace
},
"mountPoints": [
{
"mountPoint": "/myMountPoint",
"source": "abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path>"
},
{
"mountPoint": "/myMountPoint1",
"source": "abfs[s]://<file_system>@<account_name>.dfs.core.windows.net/<path1>"
},
],
"environment": {
"id": "<environment-id>",
"name": "<environment-name>"
},
"sessionTimeoutInSeconds": 1200,
"useStarterPool": false, // Set to true to force using starter pool
"useWorkspacePool": "<workspace-pool-name>"
}
Hinweis
- Es wird empfohlen, denselben Wert für „DriverMemory“ und „ExecutorMemory“ in „%%configure“ festzulegen. Die Werte „driverCores“ und „executorCores“ sollten ebenfalls identisch sein.
- „defaultLakehouse“ überschreibt Ihr angeheftetes Lakehouse im Lakehouse-Explorer, dies funktioniert jedoch nur in Ihrer aktuellen Notebook-Sitzung.
- Sie können „%%configure“ in Fabric-Pipelines verwenden, aber wenn es nicht in der ersten Codezelle festgelegt wird, schlägt die Pipelineausführung fehl, weil die Sitzung nicht neu gestartet werden kann.
- Der in „notebooktutils.notebook.run“ verwendete %%configure-Befehl wird ignoriert, aber in „%run notebook“ weiterhin ausgeführt.
- Die Spark-Standardkonfigurationseigenschaften müssen im „conf“-Text verwendet werden. Fabric unterstützt keine Verweise auf oberster Ebene für die Spark-Konfigurationseigenschaften.
- Einige spezielle Spark-Eigenschaften wie „spark.driver.cores“, „spark.executor.cores“, „spark.driver.memory“, „spark.executor.memory“ und „spark.executor.instances“ werden im conf-Text nicht wirksam.
Parametrisierte Sitzungskonfiguration aus einer Pipeline
Mit der parametrisierten Sitzungskonfiguration können Sie den Wert im Magic-Befehl „%%configure“ durch Parameter der Notebook-Aktivität für die Pipelineausführung ersetzen. Beim Vorbereiten der „%%configure“-Codezelle können Sie Standardwerte (im folgenden Beispiel auch konfigurierbar, 4 und „2000“) mit einem Objekt wie dem folgenden überschreiben:
{
"parameterName": "paramterNameInPipelineNotebookActivity",
"defaultValue": "defaultValueIfNoParamterFromPipelineNotebookActivity"
}
%%configure
{
"driverCores":
{
"parameterName": "driverCoresFromNotebookActivity",
"defaultValue": 4
},
"conf":
{
"livy.rsc.sql.num-rows":
{
"parameterName": "rows",
"defaultValue": "2000"
}
}
}
Ein Notebook verwendet den Standardwert, wenn es direkt im interaktiven Modus ausgeführt wird oder die Notebook-Aktivität der Pipeline keinen Parameter angibt, der „activityParameterName“ entspricht.
Während einer Pipelineausführung können Sie die Einstellungen für die Notebook-Aktivität der Pipeline wie folgt konfigurieren:

Wenn Sie die Sitzungskonfiguration ändern möchten, sollte der Name der Notebook-Aktivitätsparameter der Pipeline mit dem Namen von parameterName im Notebook identisch sein. In diesem Beispiel für die Ausführung einer Pipeline wird driverCores in „%%configure“ durch 8 und livy.rsc.sql.num-rows durch 4000 ersetzt.
Hinweis
- Wenn die Ausführung einer Pipeline aufgrund der Verwendung des Magic-Befehls „%%configure“ fehlgeschlagen ist, können Sie weitere Fehlerinformationen überprüfen, indem Sie die Magic-Zelle „%%configure“ im interaktiven Modus des Notebooks ausführen.
- Geplante Notebook-Ausführungen unterstützen keine parametrisierte Sitzungskonfiguration.
Python-Protokollierung in einem Notebook
Informationen zum Auffinden der Python-Protokolle und zum Festlegen verschiedener Protokollebenen und -formate können Sie dem folgenden Beispielcode entnehmen:
import logging
# Customize the logging format for all loggers
FORMAT = "%(asctime)s - %(name)s - %(levelname)s - %(message)s"
formatter = logging.Formatter(fmt=FORMAT)
for handler in logging.getLogger().handlers:
handler.setFormatter(formatter)
# Customize log level for all loggers
logging.getLogger().setLevel(logging.INFO)
# Customize the log level for a specific logger
customizedLogger = logging.getLogger('customized')
customizedLogger.setLevel(logging.WARNING)
# logger that use the default global log level
defaultLogger = logging.getLogger('default')
defaultLogger.debug("default debug message")
defaultLogger.info("default info message")
defaultLogger.warning("default warning message")
defaultLogger.error("default error message")
defaultLogger.critical("default critical message")
# logger that use the customized log level
customizedLogger.debug("customized debug message")
customizedLogger.info("customized info message")
customizedLogger.warning("customized warning message")
customizedLogger.error("customized error message")
customizedLogger.critical("customized critical message")
Anzeigen des Verlaufs von Eingabebefehlen
Das Fabric-Notebook unterstützt den Magic-Befehl %history zum Drucken des Verlaufs der Eingabebefehle, die in der aktuellen Sitzung ausgeführt wurden. Im Vergleich zum standardmäßigen Jupyter Ipython-Befehl funktioniert %history für verschiedene Sprachenkontext im Notebook.
%history [-n] [range [range ...]]
Optionen:
- -n: Drucken der Ausführungsnummer.
Dafür möglicher Bereich:
- N: Drucken des Codes der N-ten ausgeführten Zelle.
- M-N: Drucken des Code der M-ten bis N-ten ausgeführten Zelle.
Beispiel:
- Drucken des Eingabeverlaufs der 1. bis 2. ausgeführten Zelle:
%history -n 1-2
Tastenkombinationen
Ähnlich wie Jupyter-Notebooks verfügen Fabric-Notebooks über eine modale Benutzeroberfläche. Mit der Tastatur werden unterschiedliche Aktionen ausgeführt, je nachdem, in welchem Modus sich die Notebook-Zelle befindet. Fabric-Notebooks unterstützen die folgenden zwei Modi für eine bestimmte Codezelle: Befehlsmodus und Bearbeitungsmodus.
Eine Zelle befindet sich im Befehlsmodus, wenn Sie nicht durch einen Textcursor zur Eingabe aufgefordert werden. Wenn sich eine Zelle im Befehlsmodus befindet, können Sie das Notebook als Ganzes bearbeiten, aber keine Eingaben in einzelne Zellen vornehmen. Sie wechseln in den Befehlsmodus, indem Sie die ESC-TASTE drücken oder mit der Maus außerhalb des Editor-Bereichs einer Zelle klicken.

Der Bearbeitungsmodus ist durch einen Textcursor erkennbar, der Sie zur Eingabe im Editor-Bereich auffordert. Wenn sich eine Zelle im Bearbeitungsmodus befindet, können Sie etwas in diese eingeben. Sie wechseln in den Bearbeitungsmodus, indem Sie die EINGABETASTE drücken oder mit der Maus den Editor-Bereich einer Zelle auswählen.



Tastenkombinationen im Befehlsmodus
| Aktion | Tastenkombinationen für Notebooks |
|---|---|
| Aktuelle Zelle ausführen und die darunter auswählen | UMSCHALT+EINGABE |
| Aktuelle Zelle ausführen und darunter einfügen | ALT+EINGABE |
| Aktuelle Zelle ausführen | STRG+EINGABE |
| Zelle darüber auswählen | Nach oben |
| Zelle darunter auswählen | Nach unten |
| Vorherige Zelle auswählen | K |
| Nächste Zelle auswählen | J |
| Zelle oberhalb einfügen | Ein |
| Zelle unterhalb einfügen | B |
| Ausgewählte Zellen löschen | UMSCHALT+D |
| In den Bearbeitungsmodus wechseln | EINGABETASTE |
Tastenkombinationen im Bearbeitungsmodus
Mithilfe der folgenden Tastenkombinationen können Sie in Fabric-Notebooks unkompliziert navigieren und Code ausführen, die sich im Bearbeitungsmodus befinden.
| Aktion | Tastenkombinationen für Notebooks |
|---|---|
| Cursor nach oben verschieben | Nach oben |
| Cursor nach unten verschieben | Nach unten |
| Rückgängig | STRG+Z |
| Wiederholen | STRG+Y |
| Auskommentieren oder Auskommentierung aufheben | STRG+/ Kommentar: STRG+K+C Auskommentierung aufheben: STRG+K+U |
| Wort davor löschen | STRG+RÜCKTASTE |
| Wort danach löschen | STRG+DELETE |
| Zum Anfang der Zelle wechseln | STRG+POS1 |
| Zum Ende der Zelle wechseln | STRG+ENDE |
| Ein Wort nach links wechseln | STRG+NACH-LINKS |
| Ein Wort nach rechts wechseln | STRG+NACH-RECHTS |
| Alle auswählen | STRG+A |
| Einziehen | STRG+] |
| Einzug entfernen | STRG+[ |
| In den Befehlsmodus wechseln | Esc |
Wählen Sie zum Ermitteln aller Tastenkombinationen Ansicht auf dem Menüband des Notebooks und dann Tastenzuordnungen aus.