Zwischenspeichern in Data Warehousing in Fabric
Gilt für:✅ SQL-Analyseendpunkt und Warehouse in Microsoft Fabric
Das Abrufen von Daten aus dem Data Lake ist ein wichtiger Eingabe-/Ausgabevorgang (E/A) mit erheblichen Auswirkungen auf die Abfrageleistung. In Microsoft Fabric verwendet, Synapse Data Warehouse optimierte Zugriffsmuster, um die Lesevorgänge von Daten aus dem Speicher zu verbessern und die Abfrageausführungsgeschwindigkeit zu erhöhen. Darüber hinaus minimiert es intelligent die Notwendigkeit von Remotespeicherlesevorgängen, indem lokale Caches genutzt werden.
Das Zwischenspeichern ist eine Technik, die die Leistung von Datenverarbeitungsanwendungen verbessert, indem die E/A-Vorgänge reduziert werden. Beim Zwischenspeichern werden Daten und Metadaten, auf die häufig zugegriffen wird, in einer schnelleren Speicherebene gespeichert, z. B. im lokalen Arbeitsspeicher oder auf der lokalen Festplatte (SSD), so dass nachfolgende Anfragen schneller und direkt aus dem Cache bedient werden können. Wenn zuvor von einer Abfrage auf einen bestimmten Datensatz zugegriffen wurde, rufen nachfolgende Abfragen diese Daten direkt aus dem In-Memory-Cache ab. Dieser Ansatz verringert die E/A-Latenz erheblich, da lokale Speichervorgänge im Vergleich zum Abrufen von Daten aus dem Remotespeicher deutlich schneller sind.
Die Zwischenspeicherung ist für den Benutzer vollständig transparent. Unabhängig vom Ursprung, ob es sich um eine Warehouse-Tabelle, eine OneLake-Verknüpfung oder sogar um eine OneLake-Verknüpfung handelt, die auf Nicht-Azure-Dienste verweist, speichert die Abfrage alle Daten zwischen, auf die sie zugreift.
Es gibt zwei Arten von Caches, die weiter unten in diesem Artikel beschrieben werden:
- In-Memory-Cache
- Datenträgercache
In-Memory-Cache
Wenn die Abfrage auf Daten zugreift und diese aus dem Speicher abruft, führt sie einen Transformationsprozess durch, der die Daten aus dem ursprünglichen dateibasierten Format in hochoptimierte Strukturen im In-Memory-Cache transcodiert.

Daten im Cache werden in einem komprimierten spaltenbasierten Format organisiert, das für analytische Abfragen optimiert ist. Jede Datenspalte wird getrennt von den anderen Daten gespeichert, was eine bessere Komprimierung ermöglicht, da ähnliche Datenwerte zusammen gespeichert werden, was zu einem geringeren Arbeitsspeicherbedarf führt. Wenn Abfragen Vorgänge für eine bestimmte Spalte wie Aggregate oder Filterung ausführen müssen, kann die Engine effizienter arbeiten, da sie keine unnötigen Daten aus anderen Spalten verarbeiten muss.
Darüber hinaus ist dieser spaltenbasierte Speicher auch für die parallele Verarbeitung förderlich, was die Abfrageausführung für große Datasets erheblich beschleunigen kann. Die Engine kann Vorgänge für mehrere Spalten gleichzeitig ausführen und dabei die Vorteile moderner Multi-Core-Prozessoren nutzen.
Dieser Ansatz ist besonders für analytische Workloads von Vorteil, bei denen Abfragen das Scannen großer Datenmengen umfassen, um Aggregationen, Filterungen und andere Datenbearbeitungen durchzuführen.
Datenträgercache
Bestimmte Datasets sind zu groß, um in einem Speichercache untergebracht zu werden. Um eine schnelle Abfrageleistung für diese Datasets zu gewährleisten, nutzt Warehouse Speicherplatz auf dem Datenträger als ergänzende Erweiterung zum In-Memory-Cache. Alle Informationen, die in den In-Memory-Cache geladen werden, werden ebenfalls in den SSD-Cache serialisiert.
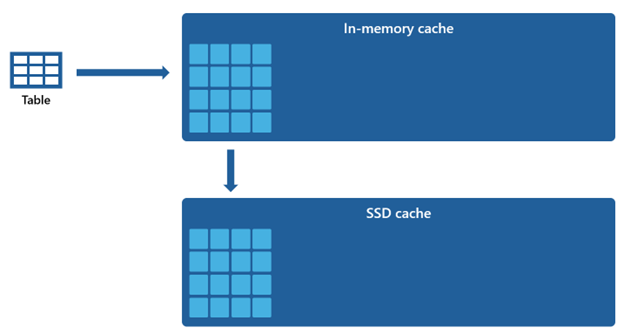
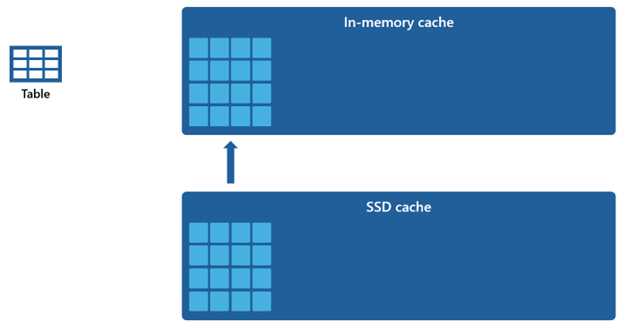
Da der In-Memory-Cache im Vergleich zum SSD-Cache eine geringere Kapazität aufweist, verbleiben Daten, die aus dem In-Memory-Cache entfernt werden, für einen längeren Zeitraum im SSD-Cache. Wenn eine nachfolgende Abfrage diese Daten anfordert, werden sie mit einer deutlich schnelleren Rate aus dem SSD-Cache in den Arbeitsspeichercache abgerufen als beim Abrufen aus dem Remotespeicher, sodass Sie letztendlich eine konsistentere Abfrageleistung erzielen.
Cacheverwaltung
Die Zwischenspeicherung bleibt konsistent aktiv und funktioniert nahtlos im Hintergrund, ohne dass Sie eingreifen müssen. Das Deaktivieren der Zwischenspeicherung ist nicht erforderlich, da dies unweigerlich zu einer spürbaren Verschlechterung der Abfrageleistung führen würde.
Der Zwischenspeicherungsmechanismus wird von Microsoft Fabric selbst orchestriert und verwaltet und bietet Benutzern nicht die Möglichkeit, den Cache manuell zu löschen.
Die vollständige Cachetransaktionskonsistenz stellt sicher, dass alle Änderungen an den Daten im Speicher, z. B. durch DML-Vorgänge (Data Manipulation Language), nach dem anfänglichen Laden in den In-Memory-Cache zu konsistenten Daten führen.
Wenn der Cache seinen Kapazitätsschwellenwert erreicht und neue Daten zum ersten Mal gelesen werden, werden Objekte, die am längsten nicht verwendet wurden, aus dem Cache entfernt. Dieser Prozess wird umgesetzt, um Platz für den Zustrom neuer Daten zu schaffen und eine optimale Nutzungsstrategie für den Cache aufrechtzuerhalten.