summarize-Operator
Gilt für: ✅Microsoft Fabric✅Azure Data Explorer✅Azure Monitor✅Microsoft Sentinel
Erzeugt eine Tabelle, die den Inhalt der Eingabetabelle aggregiert.
Syntax
T | summarize [ SummarizeParameters ] [[Column =] Aggregation [, ...]] [by [Column =] GroupExpression [, ...]]
Erfahren Sie mehr über Syntaxkonventionen.
Parameter
| Name | Type | Erforderlich | BESCHREIBUNG |
|---|---|---|---|
| Spalte | string |
Der Name der Ergebnisspalte. Nimmt standardmäßig den vom Ausdruck abgeleiteten Namen an. | |
| Aggregation | string |
✔️ | Ein Aufruf einer Aggregationsfunktion, z. B. count() oder avg(), mit Spaltennamen als Argumenten. |
| GroupExpression | Skalarwert | ✔️ | Ein Skalarausdruck, der auf die Eingabedaten verweisen kann. Die Ausgabe enthält so viele Datensätze, wie es unterschiedliche Werte aller Gruppierungsausdrücke gibt. |
| SummarizeParameters | string |
Null oder mehr durch Leerzeichen getrennte Parameter in Form von Name = Value , die das Verhalten steuern. Siehe Unterstützte Parameter. |
Hinweis
Wenn die Eingabetabelle leer ist, ist die Ausgabe davon abhängig, ob GroupExpression verwendet wird:
- Wenn GroupExpression nicht angegeben wird, ist die Ausgabe eine einzelne (leere) Zeile.
- Wenn GroupExpression angegeben wird, weist die Ausgabe keine Zeilen auf.
Unterstützte Parameter
| Name | Beschreibung |
|---|---|
hint.num_partitions |
Gibt die Anzahl der Partitionen an, die verwendet werden, um die Abfragelast auf Clusterknoten zu verteilen. Weitere Informationen finden Sie unter Shuffleabfrage |
hint.shufflekey=<key> |
Die shufflekey-Abfrage teilt die Abfragelast auf Clusterknoten auf, wobei ein Schlüssel zum Partitionieren der Daten verwendet wird. Weitere Informationen finden Sie unter Shuffleabfrage |
hint.strategy=shuffle |
Die shuffle-Strategieabfrage teilt die Abfragelast auf Clusterknoten auf, wobei jeder Knoten eine Partition der Daten verarbeitet. Weitere Informationen finden Sie unter Shuffleabfrage |
Gibt zurück
Die Eingabezeilen sind in Gruppen mit denselben Werten der by -Ausdrücke angeordnet. Anschließend werden die angegebenen Aggregationsfunktionen über jede Gruppe berechnet, dabei wird eine Zeile für jede Gruppe erzeugt. Das Ergebnis enthält die by -Spalten und auch mindestens eine Spalte für jedes berechnete Aggregat. (Einige Aggregationsfunktionen geben mehrere Spalten zurück.)
Das Ergebnis umfasst genauso viele Zeilen, wie unterschiedliche Kombinationen von by-Werten vorhanden sind (kann null sein). Wenn keine Gruppenschlüssel bereitgestellt werden, verfügt das Ergebnis über einen einzelnen Datensatz.
Um Zusammenfassungen über Bereiche von numerischen Werten hinweg zu erstellen, verwenden Sie bin(), um Bereiche auf diskrete Werte zu reduzieren.
Hinweis
- Auch wenn Sie beliebige Ausdrücke für die Aggregation und Gruppierung von Ausdrücken bereitstellen können, ist es effizienter, einfache Spaltennamen zu verwenden oder
bin()auf eine numerische Spalte anzuwenden. - Die automatischen stündlichen Bins für DateTime-Spalten werden nicht mehr unterstützt. Verwenden Sie stattdessen explizite Quantisierung. Beispiel:
summarize by bin(timestamp, 1h).
Standardwerte von Aggregationen
In der folgenden Tabelle werden die Standardwerte von Aggregationen zusammengefasst.
| Operator | Standardwert |
|---|---|
count(), countif(), dcount()sum()count_distinct()dcountif(), sumif(), , variance(), , , stdev()varianceif()stdevif() |
0 |
make_bag(), , make_bag_if()make_list(), make_list_if(), , make_set()make_set_if() |
Leeres dynamisches Array ([]) |
| Alle anderen | NULL |
Hinweis
Wenn Sie diese Aggregate auf Entitäten anwenden, die Nullwerte enthalten, werden die Nullwerte ignoriert und fließen nicht in die Berechnung ein. Beispiele finden Sie unter Aggregierte Standardwerte.
Beispiele
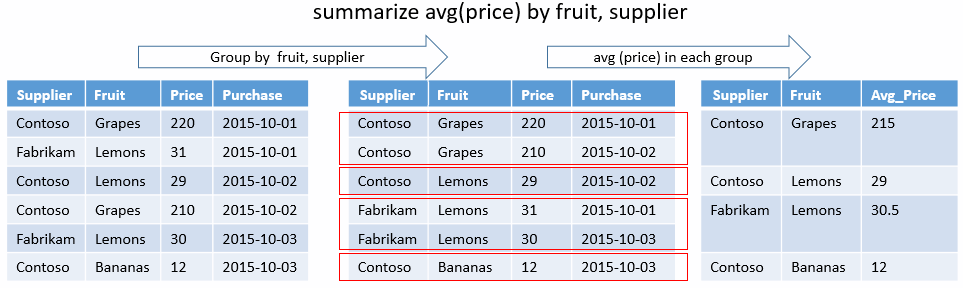
Eindeutige Kombination
Die folgende Abfrage bestimmt, welche eindeutigen Kombinationen von State und EventType für Stürme vorhanden sind, die zu direkten Verletzungen geführt haben. Es gibt keine Aggregationsfunktionen, sondern nur group-by-Schlüssel. In der Ausgabe werden nur die Spalten für diese Ergebnisse angezeigt.
StormEvents
| where InjuriesDirect > 0
| summarize by State, EventType
Ausgabe
In der folgenden Tabelle sind nur die ersten fünf Zeilen aufgeführt. Führen Sie die Abfrage aus, um die vollständige Ausgabe anzuzeigen.
| State | EventType |
|---|---|
| TEXAS | Sturm |
| TEXAS | Überschwemmung |
| TEXAS | Winterwetter |
| TEXAS | Starker Wind |
| TEXAS | Hochwasser |
| ... | ... |
Minimaler und maximaler Zeitstempel
Ermittelt die minimale und maximale Dauer schwerer Regenstürme auf Hawaii. Es gibt keine Group-By-Klausel, daher enthält die Ausgabe nur eine Zeile.
StormEvents
| where State == "HAWAII" and EventType == "Heavy Rain"
| project Duration = EndTime - StartTime
| summarize Min = min(Duration), Max = max(Duration)
Ausgabe
| Min | Max |
|---|---|
| 01:08:00 | 11:55:00 |
Distinct Count
Die folgende Abfrage berechnet die Anzahl eindeutiger Sturmereignistypen für jeden Zustand und sortiert die Ergebnisse nach der Anzahl eindeutiger Sturmtypen:
StormEvents
| summarize TypesOfStorms=dcount(EventType) by State
| sort by TypesOfStorms
Ausgabe
In der folgenden Tabelle sind nur die ersten fünf Zeilen aufgeführt. Führen Sie die Abfrage aus, um die vollständige Ausgabe anzuzeigen.
| State | TypesOfStorms |
|---|---|
| TEXAS | 27 |
| CALIFORNIA | 26 |
| PENNSYLVANIA | 25 |
| GEORGIA | 24 |
| ILLINOIS | 23 |
| ... | ... |
Histogramm
Im folgenden Beispiel wird ein Histogramm der Sturmereignistypen mit Stürmen berechnet, die länger als einen Tag dauern. Da Duration viele Werte aufweist, verwenden Sie bin(), um die Werte in Intervallen von einem Tag zu gruppieren.
StormEvents
| project EventType, Duration = EndTime - StartTime
| where Duration > 1d
| summarize EventCount=count() by EventType, Length=bin(Duration, 1d)
| sort by Length
Ausgabe
| EventType | Länge | EventCount |
|---|---|---|
| Dürre | 30.00:00:00 | 1646 |
| Wildfire | 30.00:00:00 | 11 |
| Hitze | 30.00:00:00 | 14 |
| Hochwasser | 30.00:00:00 | 20 |
| Starker Regen | 29.00:00:00 | 42 |
| ... | ... | ... |
Standardwerte von Aggregationen
Wenn die Eingabe des summarize-Operators mindestens einen leeren Group-By-Schlüssel aufweist, ist das Ergebnis ebenfalls leer.
Wenn die Eingabe des summarize-Operators keinen leeren group-by-Schlüssel aufweist, enthält das Ergebnis die Standardwerte der Aggregate, die in summarize verwendet werden. Weitere Informationen finden Sie unter Standardwerte von Aggregationen.
datatable(x:long)[]
| summarize any_x=take_any(x), arg_max_x=arg_max(x, *), arg_min_x=arg_min(x, *), avg(x), buildschema(todynamic(tostring(x))), max(x), min(x), percentile(x, 55), hll(x) ,stdev(x), sum(x), sumif(x, x > 0), tdigest(x), variance(x)
Ausgabe
| any_x | arg_max_x | arg_min_x | avg_x | schema_x | max_x | min_x | percentile_x_55 | hll_x | stdev_x | sum_x | sumif_x | tdigest_x | variance_x |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| NaN | 0 | 0 | 0 | 0 |
Das Ergebnis von avg_x(x) ist NaN aufgrund der Division durch 0.
datatable(x:long)[]
| summarize count(x), countif(x > 0) , dcount(x), dcountif(x, x > 0)
Ausgabe
| count_x | countif_ | dcount_x | dcountif_x |
|---|---|---|---|
| 0 | 0 | 0 | 0 |
datatable(x:long)[]
| summarize make_set(x), make_list(x)
Ausgabe
| set_x | list_x |
|---|---|
| [] | [] |
Das Aggregat avg addiert alle Werte ungleich null (0) und zählt nur die Werte, die an der Berechnung beteiligt waren (Werte von 0 werden nicht berücksichtigt).
range x from 1 to 4 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize sum(y), avg(y)
Ausgabe
| sum_y | avg_y |
|---|---|
| 15 | 5 |
Für die reguläre Anzahl werden NULL-Werte mitgezählt:
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize count(y)
Ausgabe
| count_y |
|---|
| 2 |
range x from 1 to 2 step 1
| extend y = iff(x == 1, real(null), real(5))
| summarize make_set(y), make_set(y)
Ausgabe
| set_y | set_y1 |
|---|---|
| [5.0] | [5.0] |