Konfigurieren automatischer Aggregationen
Das Konfigurieren automatischer Aggregationen umfasst das Aktivieren von Training für ein unterstütztes DirectQuery-Semantikmodell und das Konfigurieren von geplanten Aktualisierungen. Nachdem mehrere Durchgänge der Trainings- und Aktualisierungsoperationen ausgeführt wurden, können Sie zu den Semantikmodelleinstellungen zurückkehren, um den Anteil der Berichtsabfragen zu optimieren, die den In-Memory-Aggregationscache verwenden. Bevor Sie diese Schritte ausführen, vergewissern Sie sich, dass Sie die Funktionen und Einschränkungen, die unter Automatische Aggregationen beschrieben sind, in vollem Umfang verstanden haben.
Aktivieren
Sie benötigen Besitzerberechtigungen für Semantikmodelle, um automatische Aggregationen zu aktivieren. Arbeitsbereichsadministrator*innen können Besitzerberechtigungen für Modelle übernehmen.
Erweitern Sie in den Einstellungen des Semantikmodells Geplante Aktualisierung und Leistungsoptimierung.
Schalten Sie Automatisches Aggregationstraining auf Ein. Wenn der Umschalter grau dargestellt wird, vergewissern Sie sich, dass Datenquellen-Anmeldeinformationen konfiguriert wurden und Sie angemeldet sind.

Geben Sie unter Aktualisierungszeitplan eine Aktualisierungshäufigkeit und eine Zeitzone an. Wenn die Steuerelemente des Aktualisierungszeitplans deaktiviert sind, überprüfen Sie die Konfiguration der Datenquelle, einschließlich der Gatewayverbindung (falls erforderlich) und der Datenquellen-Anmeldeinformationen.
Wählen Sie Andere Uhrzeit hinzufügen aus, und geben Sie mindestens eine Aktualisierung an.

Sie müssen mindestens eine Aktualisierung planen. Die erste Aktualisierung für die Häufigkeit, die Sie auswählen, beinhaltet sowohl einen Trainingsvorgang als auch eine Aktualisierung, bei der neue und aktualisierte Aggregationen in den In-Memory-Cache geladen werden. Planen Sie weitere Aktualisierungen, um sicherzustellen, dass Berichtsabfragen, die beim Aggregationscache eingehen, zum Abruf von Ergebnissen führen, die möglichst gut mit der Back-End-Datenquelle synchronisiert sind. Weitere Informationen finden Sie unter Aktualisierungsvorgänge.
Wählen Sie Übernehmen.
Bedarfsgesteuertes Trainieren und Aktualisieren
Der erste geplante Aktualisierungsvorgang für Ihre ausgewählte Häufigkeit umfasst einen Trainingsvorgang. Wenn dieser Trainingsvorgang nicht innerhalb des Zeitlimits von 60 Minuten abgeschlossen ist, werden beim nachfolgenden Aktualisierungsvorgang keine Aggregationen in den Cache geladen oder aktualisiert. Der nächste Trainingsvorgang wird erst dann durchgeführt, nachdem der erste Aktualisierungsvorgang gemäß der von Ihnen gewählten Häufigkeit abgeschlossen wurde.
In solchen Fällen können Sie einen oder mehrere Trainings- und Aktualisierungsvorgänge bedarfsgesteuert manuell ausführen, um das Training vollständig abzuschließen und Aggregationen in den Cache zu laden oder zu aktualisieren. Wenn Sie z. B. beim Überprüfen des Aktualisierungsverlaufs den ersten geplanten Trainings- und Aktualisierungsvorgang für den Tag (Häufigkeit) nicht innerhalb des Zeitlimits abschließen und Sie nicht auf die geplante Aktualisierung am nächsten Tag warten möchten, die einen auszuführenden Trainingsvorgang enthält, können Sie einen oder mehrere bedarfsgesteuerte Trainings- und Aktualisierungsvorgänge ausführen, um das Datenabfrageprotokoll vollständig zu verarbeiten (Training) und Aggregationen in den Cache zu laden (Aktualisierung).
Um einen bedarfsgesteuerten Trainings- und Aktualisierungsvorgang durchzuführen, wählen Sie Jetzt trainieren und aktualisieren aus. Behalten Sie den Aktualisierungsverlauf im Auge, um sicherzustellen, dass der bedarfsgesteuerte Trainingsvorgang erfolgreich abgeschlossen wird. Falls nicht, führen Sie weitere Trainings- und Aktualisierungsvorgänge durch, bis das Training erfolgreich abgeschlossen ist und die Aggregationen in den Cache geladen oder aktualisiert wurden.
Die Ausführung von Jetzt trainieren und aktualisieren kann auch für die Optimierung des Prozentsatzes der Berichtsabfragen hilfreich sein, die Aggregationen aus dem In-Memory-Cache verwenden. Indem Sie einen bedarfsgesteuerten Trainings- und Aktualisierungsvorgang durchführen, können Sie schneller feststellen, ob Ihre neue Prozenteinstellung den Abschluss des Trainingsvorgangs innerhalb des Zeitlimits ermöglicht.
Denken Sie daran, dass Trainings- und Aktualisierungsvorgänge, ob geplant oder bedarfsgesteuert, sowohl für die Datenquelle als auch für Power BI verarbeitungs- und ressourcenintensiv sind. Wählen Sie einen Zeitpunkt, an dem die Ressourcen am wenigsten belastet werden.
Feinabstimmung
Sowohl benutzerdefinierte als auch systemseitig generierte Aggregationstabellen sind Teil des Modells, tragen zu seiner Größe bei und unterliegen bestehenden Power BI-Einschränkungen zur Modellgröße. Die Aggregationsverarbeitung verbraucht ebenfalls Ressourcen und wirkt sich auf die Dauer der Modellaktualisierung aus. Eine optimale Konfiguration erzielt ein Gleichgewicht zwischen der Bereitstellung vorab aggregierter Ergebnisse aus dem In-Memory-Aggregationscache für die am häufigsten verwendeten Berichtsabfragen, während langsamere Ergebnisse für Ausreißer und Ad-hoc-Abfragen im Tausch gegen schnellere Trainings- und Aktualisierungszeiten und eine geringere Auslastung der Systemressourcen akzeptiert werden.
Anpassen des Prozentsatzes
Standardmäßig beträgt die Aggregationscache-Einstellung zur Festlegung es Prozentsatzes der Berichtsabfragen, die Aggregationen aus dem In-Memory-Cache verwenden, 75 %. Das Heraufsetzen des Prozentsatzes bewirkt, dass eine größere Anzahl von Berichtsabfragen höher eingestuft wird und daher Aggregationen für diese in den In-Memory-Aggregationscache aufgenommen werden. Ein höherer Prozentsatz kann zwar bedeuten, dass mehr Abfragen aus dem In-Memory-Cache beantwortet werden, er kann aber auch längere Trainings- und Aktualisierungszeiten mit sich bringen. Die Anpassung auf einen niedrigeren Prozentsatz kann andererseits kürzere Trainings- und Aktualisierungszeiten sowie eine geringere Ressourcenauslastung bedeuten, aber die Leistung der Berichtsvisualisierung kann abnehmen, da weniger Berichtsabfragen vom In-Memory-Aggregationscache beantwortet werden, da diese Berichtsabfragen stattdessen einen Roundtrip zur Datenquelle ausführen müssen.
Bevor das System die optimalen Aggregationen zur Aufnahme in den Cache bestimmen kann, muss es zunächst die am häufigsten verwendeten Berichtabfragemuster kennen. Achten Sie darauf, mehrere Durchläufe der Trainings-/Aktualisierungsvorgänge zuzulassen, bevor Sie den Prozentsatz der Abfragen anpassen, die den Aggregationscache verwenden. Dadurch erhält der Trainingsalgorithmus Zeit, Berichtsabfragen über einen längeren Zeitraum zu analysieren und sich entsprechend anzupassen. Wenn Sie beispielsweise Aktualisierungen mit täglicher Häufigkeit geplant haben, kann es sinnvoll sein, eine ganze Woche lang abzuwarten. Benutzerberichtsmuster unterscheiden sich an manchen Tagen möglicherweise von anderen.
So passen Sie den Prozentsatz an
Erweitern Sie in den Einstellungen des Semantikmodells Geplante Aktualisierung und Leistungsoptimierung.
Verwenden Sie in Abfrageabdeckung den Schieberegler Passen Sie den Prozentsatz der Abfragen an, die aggregierte Zwischenspeicher verwenden, um den Prozentsatz auf den gewünschten Wert zu erhöhen oder zu verringern. Beim Anpassen des Prozentsatzes werden im Prognosegütediagramm für den Einfluss auf die Abfrageleistung die geschätzten Antwortzeiten für Abfragen angezeigt.
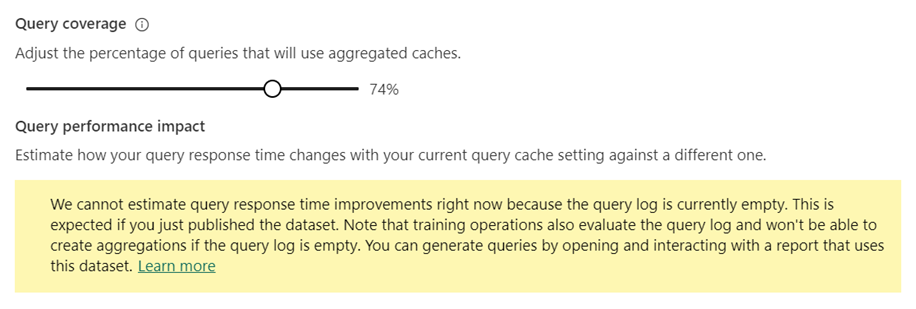
Wählen Sie Jetzt trainieren und aktualisieren oder Übernehmen aus.
Schätzen der Auswirkungen auf die Abfrageleistung
Das Prognosegütediagramm Auswirkungen auf die Abfrageleistung stellt geschätzte Ausführungszeiten für Berichtsabfragen als Funktion des Prozentsatzes der Abfragen zur Verfügung, die zwischengespeicherte Aggregationen verwenden. Das Diagramm zeigt zunächst 0,0 für alle Metriken an, bis mindestens ein Trainings-/Aktualisierungsvorgang ausgeführt wurde. Nach einem ersten Trainings-/Aktualisierungsvorgang kann Ihnen das Diagramm helfen zu bestimmen, ob sich die Abfrageantwort durch Anpassen des Prozentsatzes der Abfragen, die den In-Memory-Aggregationscache verwenden, weiter verbessern lässt.
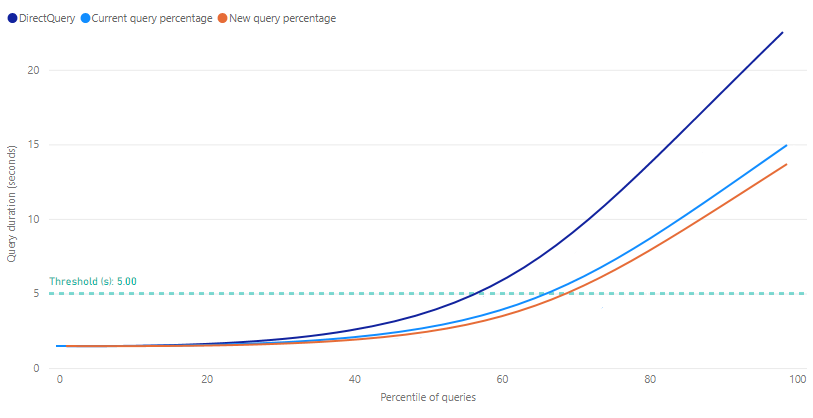
Der Schwellenwert wird im Prognosegütediagramm als Markierungslinie dargestellt und gibt die Zielantwortzeit auf Abfragen für Ihre Berichte an. Anschließend können Sie den Prozentsatz der Abfragen optimieren, die den Aggregationscache verwenden, um einen neuen Abfrageprozentsatz zu bestimmen, der den gewünschten Schwellenwert erreicht.
Metriken
DirectQuery: Eine geschätzte Dauer in Sekunden für eine Berichtsabfrage, die mithilfe von DirectQuery an die Datenquelle gesendet und von dieser zurückgegeben wird. Diese Schätzung gilt normalerweise für Abfragen, die nicht vom In-Memory-Aggregationscache beantwortet werden können.
Aktueller Abfrageprozentsatz: Eine geschätzte Dauer in Sekunden für Berichtsabfragen, die aus dem In-Memory-Aggregationscache beantwortet werden, basierend auf der Prozenteinstellung für den letzten Trainings-/Aktualisierungsvorgang.
Neuer Abfrageprozentsatz: Eine geschätzte Dauer in Sekunden für Berichtsabfragen, die aus dem In-Memory-Aggregationscache für den neu ausgewählten Prozentsatz beantwortet werden. Diese Metrik spiegelt die potenzielle Änderung wider, wenn der Prozentsatz mithilfe des Schiebereglers geändert wird.
Deaktivieren
Sie benötigen Besitzerberechtigungen für das Modell, um automatische Aggregationen zu deaktivieren. Arbeitsbereichsadministrator*innen können Besitzerberechtigungen für Modelle übernehmen.
Schalten Sie Automatisches Aggregationstraining auf Aus, um diese Funktion zu deaktivieren.
Wenn Sie das Training deaktivieren, werden Sie aufgefordert, die automatischen Aggregationstabellen zu löschen.
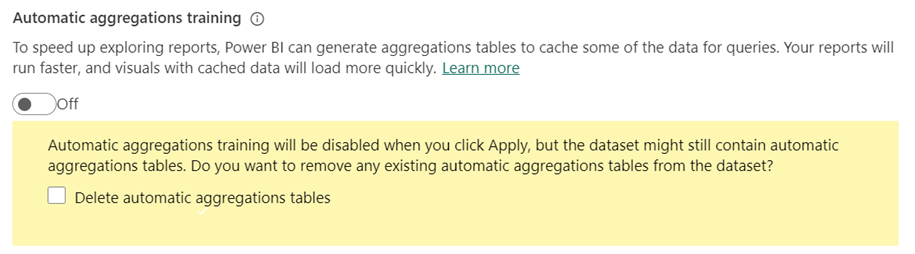
Wenn Sie vorhandene automatische Aggregationstabellen nicht löschen, verbleiben die Tabellen im Modell und werden weiterhin aktualisiert. Da das Training jedoch deaktiviert ist, werden keine neuen Aggregationen hinzugefügt. Power BI nutzt weiterhin die vorhandenen Tabellen, um nach Möglichkeit aggregierte Abfrageergebnisse zu erhalten.
Wenn Sie die Tabellen löschen, wird das Modell in seinen ursprünglichen Zustand ohne automatische Aggregationen zurückversetzt.
Wählen Sie Übernehmen.