Erkunden, Lernen, Erstellen und Verwenden von Data Quality-Regeln
Datenqualität ist die Messung der Integrität von Daten in einem organization und wird mithilfe von Datenqualitätsbewertungen bewertet. Basierend auf der Bewertung der Daten anhand von Regeln, die im Microsoft Purview Data Catalog definiert sind, generierte Bewertungen.
Datenqualitätsregeln sind wichtige Richtlinien, die Organisationen festlegen, um die Genauigkeit, Konsistenz und Vollständigkeit ihrer Daten sicherzustellen. Diese Regeln tragen zur Aufrechterhaltung der Datenintegrität und -zuverlässigkeit bei.
Im Folgenden finden Sie einige wichtige Aspekte von Data Quality-Regeln:
Genauigkeit : Daten sollten reale Entitäten genau darstellen. Kontext ist wichtig! Wenn Sie beispielsweise Kundenadressen speichern, stellen Sie sicher, dass diese mit den tatsächlichen Standorten übereinstimmen.
Vollständigkeit : Das Ziel dieser Regel besteht darin, die leeren, NULL- oder fehlenden Daten zu identifizieren. Diese Regel überprüft, ob alle Werte vorhanden sind (wenn auch nicht notwendigerweise richtig).
Konformität : Diese Regel stellt sicher, dass die Daten Datenformatierungsstandards wie die Darstellung von Datumsangaben, Adressen und zulässigen Werten einhalten.
Konsistenz : Diese Regel überprüft, ob unterschiedliche Werte desselben Datensatzes mit einer bestimmten Regel übereinstimmen und keine Widersprüche vorliegen. Die Datenkonsistenz stellt sicher, dass die gleichen Informationen in verschiedenen Datensätzen einheitlich dargestellt werden. Wenn Sie über einen Produktkatalog verfügen, sind für instance konsistente Produktnamen und -beschreibungen von entscheidender Bedeutung.
Zeitachse: Mit dieser Regel soll sichergestellt werden, dass auf die Daten in so kurzer Zeit wie möglich zugegriffen werden kann. Dadurch wird sichergestellt, dass die Daten auf dem neuesten Stand sind.
Eindeutigkeit : Mit dieser Regel wird überprüft, ob Werte nicht dupliziert werden. Wenn beispielsweise nur ein Datensatz pro Kunde vorhanden sein soll, gibt es nicht mehrere Datensätze für denselben Kunden. Jeder Kunde, jedes Produkt oder jede Transaktion sollte über einen eindeutigen Bezeichner verfügen.
Lebenszyklus der Datenqualität
Das Erstellen von Data Quality-Regeln ist der sechste Schritt im Data Quality-Lebenszyklus. Die vorherigen Schritte sind:
- Weisen Sie Benutzern Data Quality Steward-Berechtigungen in Ihrem Datenkatalog zu, um alle Data Quality-Features zu verwenden.
- Registrieren und überprüfen Sie eine Datenquelle in Ihrem Microsoft Purview Data Map.
- Hinzufügen Ihrer Datenressource zu einem Datenprodukt
- Richten Sie eine Datenquellenverbindung ein, um Ihre Quelle für die Bewertung der Datenqualität vorzubereiten.
- Konfigurieren und Ausführen der Datenprofilerstellung für ein Medienobjekt in Ihrer Datenquelle.
Erforderliche Rollen
- Zum Erstellen und Verwalten von Data Quality-Regeln müssen Ihre Benutzer in der Rolle Data Quality Steward sein.
- Um vorhandene Qualitätsregeln anzuzeigen, müssen Ihre Benutzer in der Rolle "Data Quality-Leser" sein.
Anzeigen vorhandener Datenqualitätsregeln
Wählen Sie in Microsoft Purview Data Catalog das Menü Integritätsverwaltung und das Untermenü Datenqualität aus.
Wählen Sie im Untermenü Data Quality eine Governancedomäne aus.
Wählen Sie ein Datenprodukt aus.
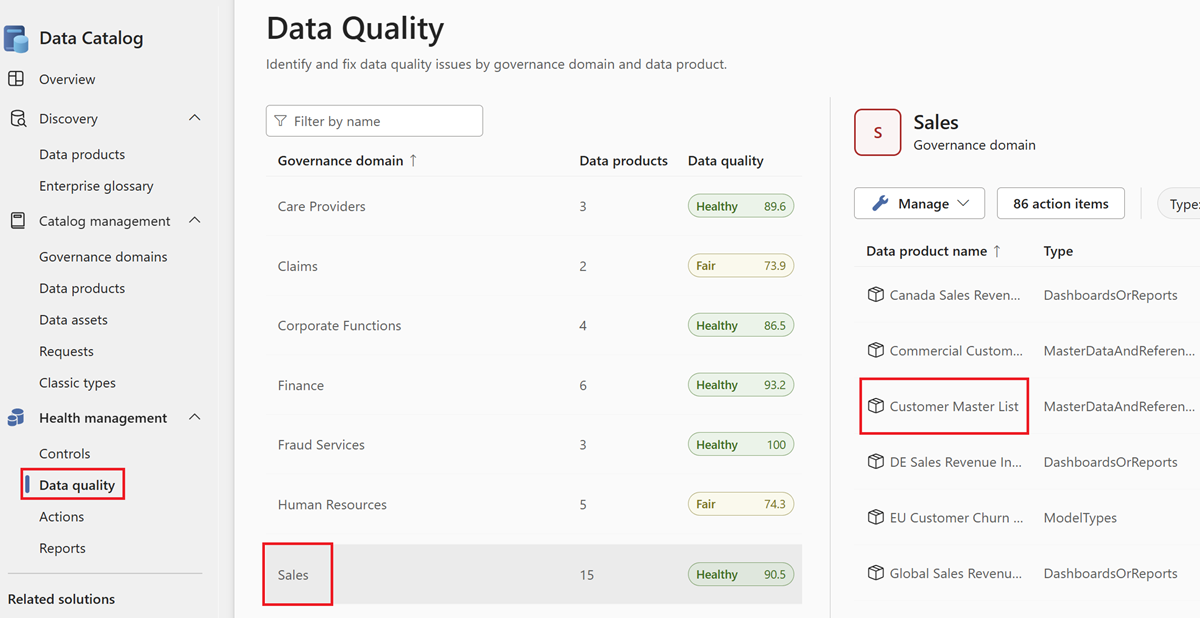
Wählen Sie eine Datenressource aus der Ressourcenliste des ausgewählten Datenprodukts aus.
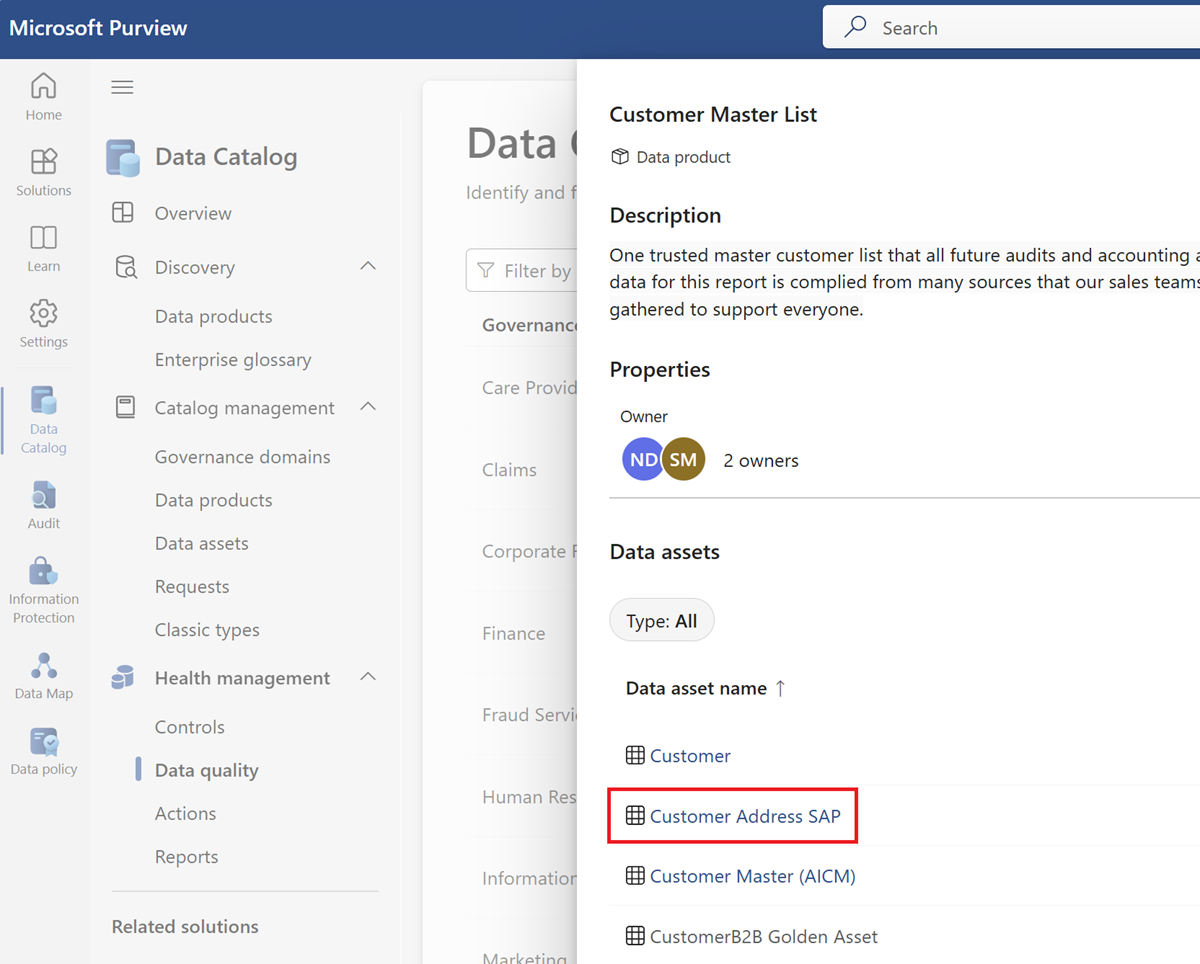
Wählen Sie die Menüregisterkarte Regeln aus, um die vorhandenen Regeln anzuzeigen, die auf das Medienobjekt angewendet werden.

Wählen Sie eine Regel aus, um den Leistungsverlauf der angewendeten Regel auf die ausgewählte Datenressource zu durchsuchen.
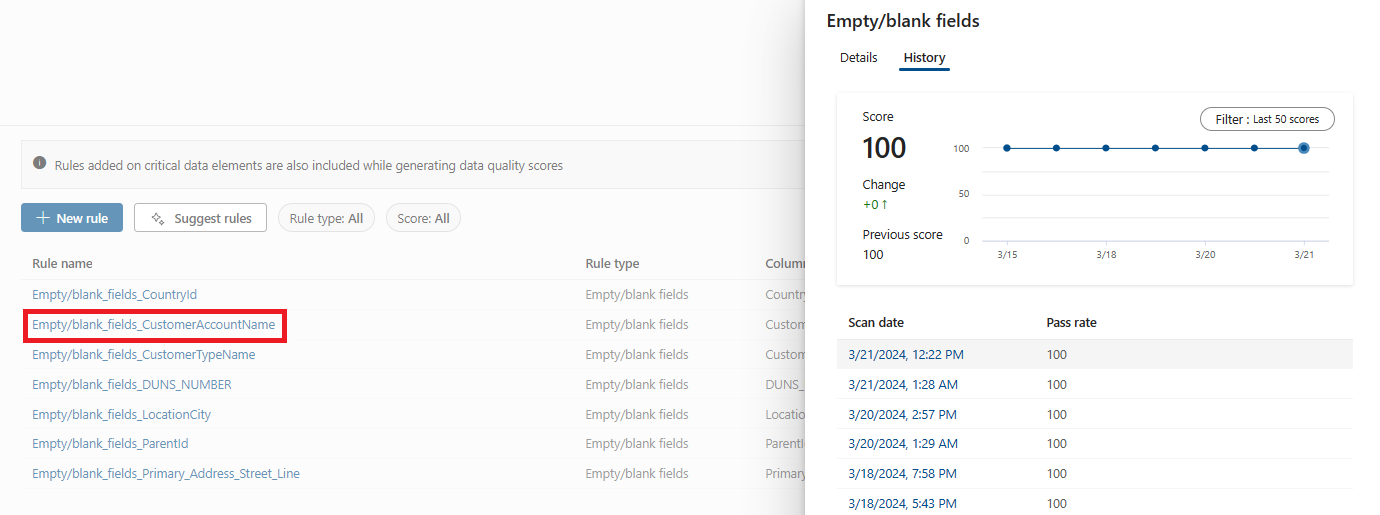




Verfügbare Data Quality-Regeln
Microsoft Purview Data Quality die Konfiguration der folgenden Regeln ermöglicht, sind dies sofort einsatzbereite Regeln, die low-code to no-code-Möglichkeit bieten, die Qualität Ihrer Daten zu messen.
| Regel | Definition |
|---|---|
| Aktualität | Bestätigt, dass alle Werte auf dem neuesten Stand sind. |
| Eindeutige Werte | Bestätigt, dass die Werte in einer Spalte eindeutig sind. |
| Übereinstimmung des Zeichenfolgenformats | Bestätigt, dass die Werte in einer Spalte einem bestimmten Format oder anderen Kriterien entsprechen. |
| Übereinstimmung des Datentyps | Bestätigt, dass die Werte in einer Spalte ihren Datentypanforderungen entsprechen. |
| Doppelte Zeilen | Sucht nach doppelten Zeilen mit den gleichen Werten in zwei oder mehr Spalten. |
| Leere/leere Felder | Sucht nach leeren und leeren Feldern in einer Spalte, in der Werte vorhanden sein sollen. |
| Tabellensuche | Bestätigt, dass ein Wert in einer Tabelle in der spezifischen Spalte einer anderen Tabelle gefunden werden kann. |
| Custom | Erstellen Sie eine benutzerdefinierte Regel mit dem Visuellen Ausdrucks-Generator. |
Aktualität
Der Zweck der Aktualitätsregel besteht darin, zu bestimmen, ob die Ressource innerhalb der erwarteten Zeit aktualisiert wurde. Microsoft Purview unterstützt derzeit die Überprüfung der Aktualität anhand der Datumsangaben der letzten Änderung.
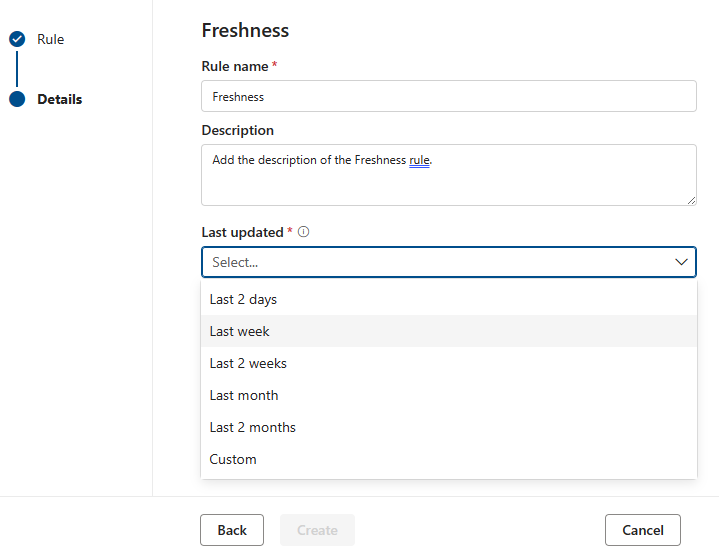
Hinweis
Die Bewertung für die Aktualitätsregel ist entweder 100 (bestanden) oder 0 (Fehler).
Eindeutige Werte
Die Regel Eindeutige Werte gibt an, dass alle Werte in der angegebenen Spalte eindeutig sein müssen. Alle Werte, die eindeutig "pass" sind, und solche, die nicht als fehlerhaft behandelt werden. Wenn die Regel Leere/leere Felder nicht für die Spalte definiert ist, werden NULL/leere Werte für die Zwecke dieser Regel ignoriert.

Übereinstimmung des Zeichenfolgenformats
Die Übereinstimmungsregel Format überprüft, ob alle Werte in der Spalte gültig sind. Wenn die Regel Leere/leere Felder nicht für eine Spalte definiert ist, werden NULL/leere Werte für die Zwecke dieser Regel ignoriert.
Diese Regel kann jeden Wert in der Spalte mit drei verschiedenen Ansätzen überprüfen:
Enumeration : Dies ist eine durch Trennzeichen getrennte Liste von Werten. Wenn der ausgewertete Wert nicht mit einem der aufgeführten Werte verglichen werden kann, schlägt die Überprüfung fehl. Kommas und umgekehrte Schrägstriche können mithilfe eines umgekehrten Schrägstrichs mit Escapezeichen versehen werden:
\. Enthält alsoa \, b, czwei Werte, der erste ista , bund der zweite istc.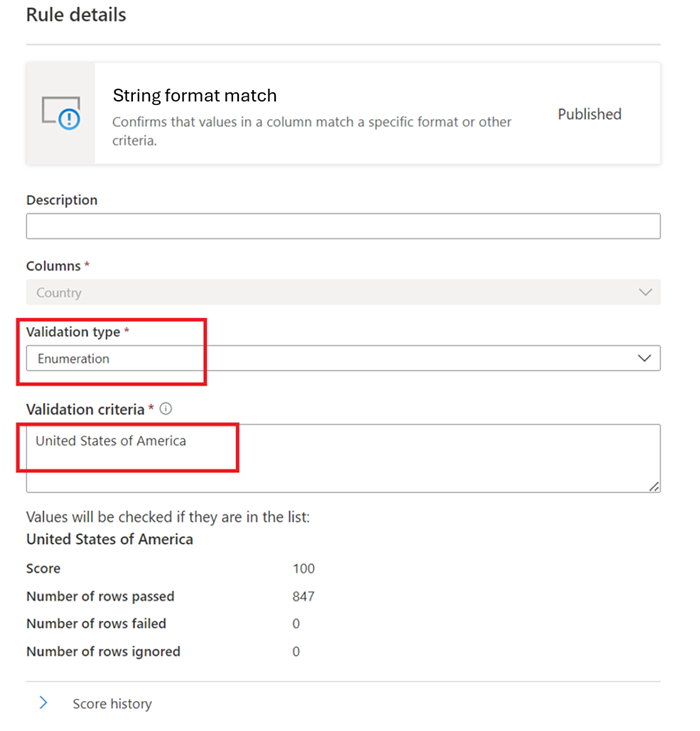
Like-Muster -
like(<string> : string, <pattern match> : string) => boolean
Das Muster ist eine Zeichenfolge, die wörtlich abgeglichen wird. Ausnahmen sind die folgenden Sondersymbole: _ entspricht einem beliebigen Zeichen in der Eingabe (ähnlich wie . inposixregulären Ausdrücken) % entspricht null oder mehr Zeichen in der Eingabe (ähnlich wie .* inposixregulären Ausdrücken). Das Escapezeichen ist "". Wenn ein Escapezeichen vor einem Sondersymbol oder einem anderen Escapezeichen steht, wird das folgende Zeichen wörtlich abgeglichen. Es ist ungültig, ein anderes Zeichen mit Escapezeichen zu versehen.like('icecream', 'ice%') -> true

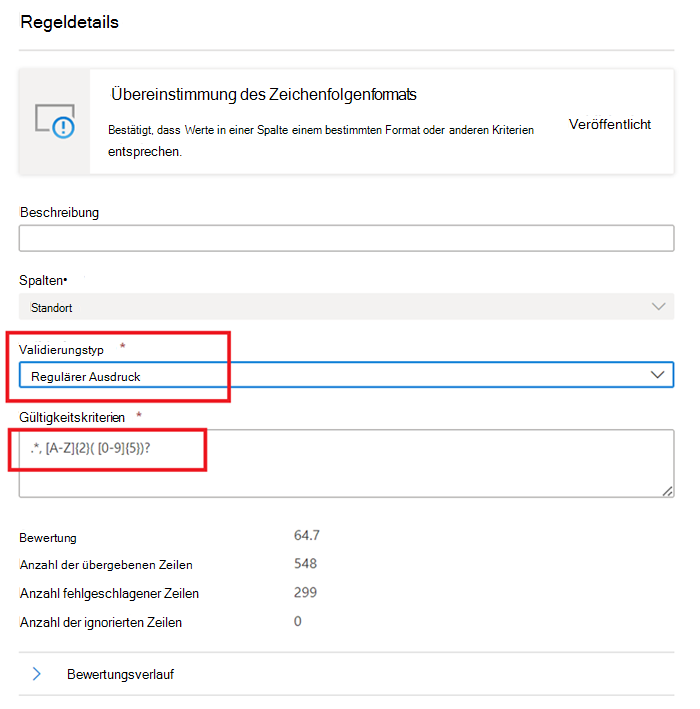
Regulärer Ausdruck –
regexMatch(<string> : string, <regex to match> : string) => boolean
Überprüft, ob die Zeichenfolge mit dem angegebenen RegEx-Muster übereinstimmt. Verwenden Sie<regex>(Zurück-Anführungszeichen), um eine Zeichenfolge ohne Escapezeichen abzugleichen.regexMatch('200.50', '(\\d+).(\\d+)') -> trueregexMatch('200.50', `(\d+).(\d+)`) -> true
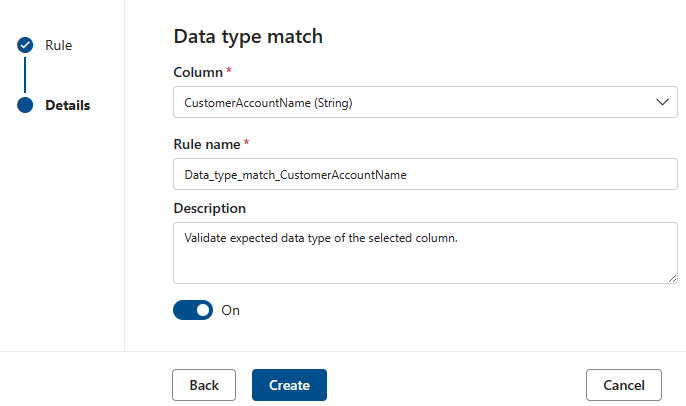
Übereinstimmung des Datentyps
Die Datentypüberstimmungsregel gibt an, welchen Datentyp die zugeordnete Spalte enthalten soll. Da die Regel-Engine in vielen verschiedenen Datenquellen ausgeführt werden muss, kann sie keine nativen Typen wie BIGINT oder VARCHAR verwenden. Stattdessen verfügt es über ein eigenes Typsystem, in das die nativen Typen übersetzt werden. Diese Regel teilt der Qualitätsscan-Engine mit, in welche der integrierten Typen der native Typ übersetzt werden soll. Das Datentypsystem stammt aus dem Azure Datenfluss-Typsystem, das in Azure Data Factory verwendet wird.
Während einer Qualitätsüberprüfung werden alle nativen Typen anhand des Datentypübereinstimmungstyps getestet, und wenn es nicht möglich ist, den nativen Typ in den Datentypübereinstimmungstyp zu übersetzen, wird diese Zeile als fehlerhaft behandelt.
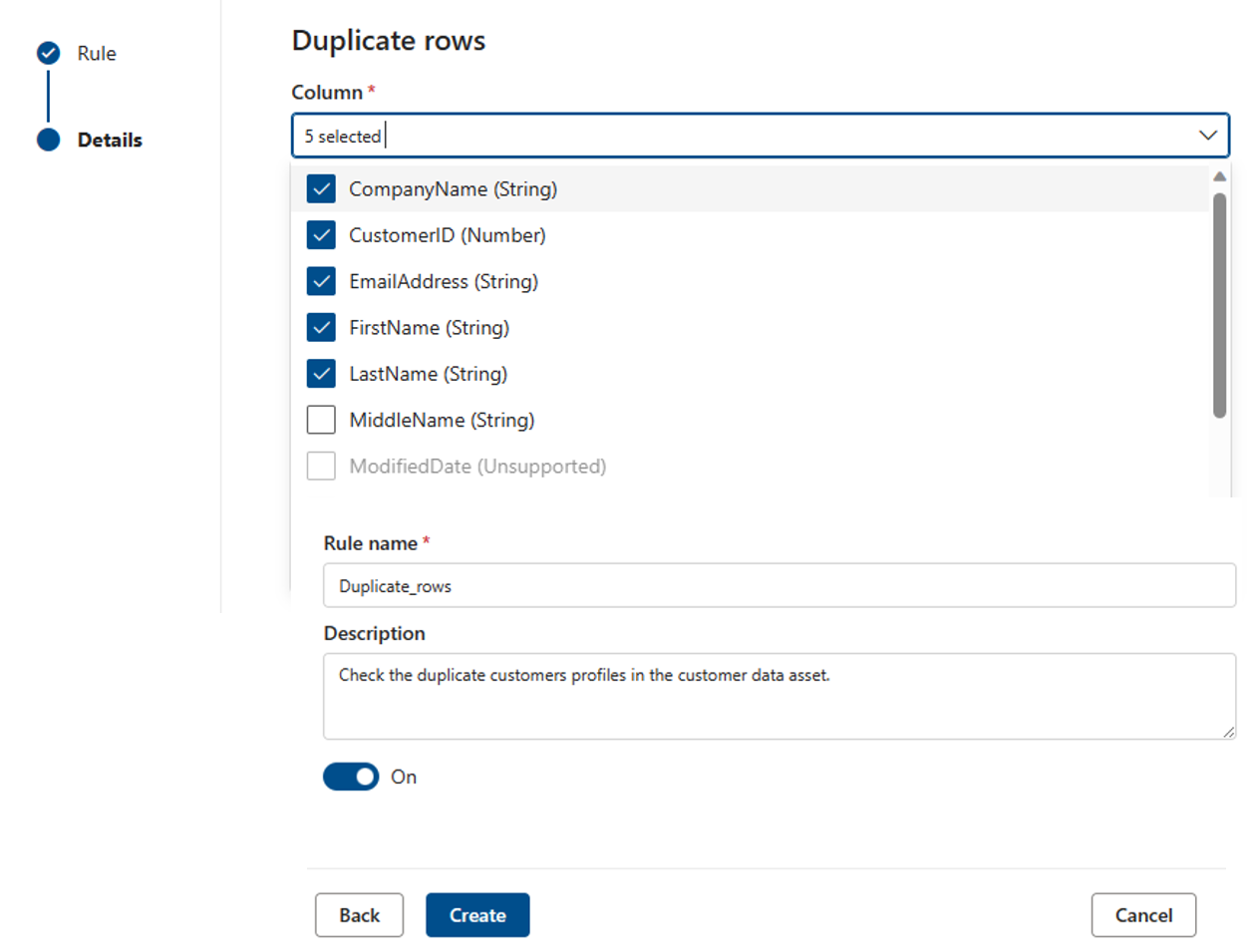
Doppelte Zeilen
Die Regel Doppelte Zeilen überprüft, ob die Kombination der Werte in der Spalte für jede Zeile in der Tabelle eindeutig ist.
Im folgenden Beispiel wird erwartet, dass die Verkettung von _CompanyName, CustomerID, EmailAddress, FirstName und LastName einen Wert erzeugt, der für alle Zeilen in der Tabelle eindeutig ist.
Jede Ressource kann null oder eine instance dieser Regel aufweisen.
Leere/leere Felder
Die Regel Leere/leere Felder bestätigt, dass die identifizierten Spalten keine NULL-Werte enthalten dürfen, und im speziellen Fall von Zeichenfolgen auch keine leeren Werte oder nur Leerzeichenwerte. Während einer Qualitätsüberprüfung wird jeder Wert in dieser Spalte, der nicht NULL ist, als richtig behandelt. Diese Regel wirkt sich auf andere Regeln aus, z. B . eindeutige Werte oder Format-Übereinstimmungsregeln . Wenn diese Regel nicht für eine Spalte definiert ist, ignorieren diese Regeln bei der Ausführung für diese Spalte automatisch alle NULL-Werte. Wenn diese Regel für eine Spalte definiert ist, untersuchen diese Regeln NULL-/leere Werte für diese Spalte und berücksichtigen sie zu Bewertungszwecken.

Tabellensuche
Die Tabellensuche-Regel untersucht jeden Wert in der Spalte, für die die Regel definiert ist, und vergleicht ihn mit einer Verweistabelle. Beispielsweise verfügt die primäre Tabelle über eine Spalte namens "location", die Städte, Bundesstaaten und Postleitzahlen im Format "City, State ZIP" enthält. Es gibt eine Referenztabelle namens citystate, die alle rechtlichen Kombinationen von Städten, Bundesstaaten und Postleitzahlen enthält, die im USA unterstützt werden. Das Ziel besteht darin, alle Speicherorte in der aktuellen Spalte mit dieser Verweisliste zu vergleichen, um sicherzustellen, dass nur rechtliche Kombinationen verwendet werden.
Dazu geben wir zuerst den Namen von "citystatezip" in das Dialogfeld "Objekte suchen" ein. Anschließend wählen wir das gewünschte Medienobjekt und dann die Spalte aus, mit der wir vergleichen möchten.
Benutzerdefinierte Regeln
Die benutzerdefinierte Regel ermöglicht das Angeben von Regeln, die versuchen, Zeilen basierend auf einem oder mehreren Werten in dieser Zeile zu überprüfen. Die benutzerdefinierte Regel umfasst zwei Teile:
- Der erste Teil ist der Filterausdruck , der optional ist und durch Aktivieren des Kontrollkästchens von "Filterausdruck verwenden" aktiviert wird. Dies ist ein Ausdruck, der einen booleschen Wert zurückgibt. Der Filterausdruck wird auf eine Zeile angewendet, und wenn er true zurückgibt, wird diese Zeile für die Regel berücksichtigt. Wenn der Filterausdruck false für diese Zeile zurückgibt, bedeutet dies, dass zeile für die Zwecke dieser Regel ignoriert wird. Das Standardverhalten des Filterausdrucks besteht darin, alle Zeilen zu übergeben. Wenn also kein Filterausdruck angegeben und keiner benötigt wird, werden alle Zeilen berücksichtigt.
- Der zweite Teil ist der Zeilenausdruck. Dies ist ein boolescher Ausdruck, der auf jede Zeile angewendet wird, die vom Filterausdruck genehmigt wird. Wenn dieser Ausdruck true zurückgibt, wird die Zeile übergeben. Wenn false, wird sie als fehler markiert.

Beispiele für benutzerdefinierte Regeln
| Szenario | Zeilenausdruck |
|---|---|
| Überprüfen Sie, ob state_id gleich Kalifornien ist und aba_Routing_Number einem bestimmten RegEx-Muster entspricht und das Geburtsdatum in einen bestimmten Bereich fällt. | state_id=='California' && regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Überprüfen, ob VendorID gleich 124 ist | {VendorID}=='124' |
| Überprüfen Sie , ob fare_amount gleich oder größer als 100 ist. | {fare_amount} >= "100" |
| Überprüfen, ob fare_amount größer als 100 und tolls_amount ungleich 100 ist | {fare_amount} >= "100" || {tolls_amount} != "400" |
| Überprüfen Sie, ob die Bewertung kleiner als 5 ist. | Rating < 5 |
| Überprüfen, ob die Anzahl der Ziffern im Jahr 4 ist | length(toString(year)) == 4 |
| Vergleichen Sie die beiden Spalten bbToLoanRatio und bankBalance , um zu überprüfen, ob ihre Werte gleich sind. | compare(variance(toLong(bbToLoanRatio)),variance(toLong(bankBalance)))<0 |
| Überprüfen Sie, ob die gekürzte und verkettete Anzahl von Zeichen in firstName, lastName, LoanID, uuid größer als 20 ist. | length(trim(concat(firstName,lastName,LoanID,uuid())))>20 |
| Überprüfen Sie, ob aba_Routing_Number mit einem bestimmten RegEx-Muster übereinstimmt und das Datum der ersten Transaktion größer als 2022-11-12 und Disallow-Listed false ist und der durchschnittliche bankBalance-Wert größer als 50000 ist und state_id gleich "Massachuse", "Tennessee", "North Dakota" oder "Albama" ist. | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && toDate(addDays(toTimestamp(initialTransaction, 'yyyy-MM-dd\'T\'HH:mm:ss'),15))>toDate('2022-11-12') && ({Disallow-Listed}=='false') && avg(toLong(bankBalance))>50000 && (state_id=='Massachuse' || state_id=='Tennessee ' || state_id=='North Dakota' || state_id=='Albama') |
| Überprüfen Sie, ob aba_Routing_Number einem bestimmten RegEx-Muster entspricht und dateOfBirth zwischen 13.12.12.1968 und 2020-12-13 liegt. | regexMatch(toString(aba_Routing_Number), '^((0[0-9])|(1[0-2])|(2[1-9])|(3[0-2])|(6[1-9])|(7[0-2])|80)([0-9]{7})$') && between(dateOfBirth,toDate('1968-12-13'),toDate('2020-12-13'))==true() |
| Überprüfen Sie, ob die Anzahl eindeutiger Werte in aba_Routing_Number gleich 1.000.000 und die Anzahl eindeutiger Werte in EMAIL_ADDR gleich 1.000.000 ist. | approxDistinctCount({aba_Routing_Number})==1000000 && approxDistinctCount({EMAIL_ADDR})==1000000 |
Sowohl der Filterausdruck als auch der Zeilenausdruck werden mithilfe der Azure Data Factory Ausdruckssprache definiert, die hier mit der hier definierten Sprache eingeführt wurde. Beachten Sie jedoch, dass nicht alle Für die generische ADF-Ausdruckssprache definierten Funktionen verfügbar sind. Die vollständige Liste der verfügbaren Funktionen finden Sie in der Funktionsliste, die im Dialogfeld "Ausdruck" verfügbar ist. Die folgenden hier definierten Funktionen werden nicht unterstützt: isDelete, isError, isIgnore, isInsert, isMatch, isUpdate, isUpsert, partitionId, cached lookup und Window.
Hinweis
<regex> (Backquote) kann in regulären Ausdrücken verwendet werden, die in benutzerdefinierten Regeln enthalten sind, um eine Zeichenfolge ohne Escapezeichen für Sonderzeichen abzugleichen. Die Sprache für reguläre Ausdrücke basiert auf Java und funktioniert wie hier angegeben.
Auf dieser Seite werden die Zeichen identifiziert, die mit Escapezeichen versehen werden müssen.
KI-gestützte automatisch generierte Regeln
Ki-gestützte automatisierte Regelgenerierung für die Messung der Datenqualität umfasst den Einsatz von Ki-Techniken (Künstliche Intelligenz), um automatisch Regeln für die Bewertung und Verbesserung der Datenqualität zu erstellen. Automatisch generierte Regeln sind inhaltsspezifisch. Die meisten allgemeinen Regeln werden automatisch generiert, sodass Benutzer sich nicht so viel Mühe geben müssen, benutzerdefinierte Regeln zu erstellen.
So durchsuchen Sie automatisch generierte Regeln und wenden sie an:
- Wählen Sie auf der Regelseite Regeln vorschlagen aus.
- Durchsuchen Sie die vorgeschlagenen Regeln in der Liste.

- Wählen Sie regeln aus der Liste der vorgeschlagenen Regeln aus, die auf die Datenressource angewendet werden sollen.

Nächste Schritte
- Konfigurieren und Ausführen einer Datenqualitätsüberprüfung für ein Datenprodukt, um die Qualität aller unterstützten Ressourcen im Datenprodukt zu bewerten.
- Überprüfen Sie Ihre Scanergebnisse , um die aktuelle Datenqualität Ihres Datenprodukts zu bewerten.