Einführung in SQL Server-Big Data-Cluster
Gilt für: ![]() SQL Server 2019 (15.x)
SQL Server 2019 (15.x)
Wichtig
Das Microsoft SQL Server 2019-Big Data-Cluster-Add-On wird eingestellt. Der Support für SQL Server 2019-Big Data-Clusters endet am 28. Februar 2025. Alle vorhandenen Benutzer*innen von SQL Server 2019 mit Software Assurance werden auf der Plattform vollständig unterstützt, und die Software wird bis zu diesem Zeitpunkt weiterhin über kumulative SQL Server-Updates verwaltet. Weitere Informationen finden Sie im Ankündigungsblogbeitrag und unter Big Data-Optionen auf der Microsoft SQL Server-Plattform.
In SQL Server 2019 (15.x) können Sie SQL Server-Big Data-Cluster verwenden, um skalierbare Cluster von SQL Server-, Spark- und HDFS-Containern bereitzustellen, die auf Kubernetes ausgeführt werden. Diese Komponenten werden nebeneinander ausgeführt, sodass Sie Big Data von Transact-SQL oder Spark lesen, schreiben und verarbeiten können, während Sie Ihre wichtigen relationalen Daten mit einem hohen Big-Data-Volumen problemlos kombinieren und analysieren können.
Erste Schritte
- Weitere Informationen finden Sie zuerst unter Erste Schritte bei der Bereitstellung von SQL Server Big Data Clusters
- Neue Features des neuesten Releases finden Sie in den Versionshinweisen.
- Häufig gestellte Fragen finden Sie unter Big Data-Cluster: Häufig gestellte Fragen.
Architektur von Big-Data-Clustern
Das folgende Diagramm zeigt die Komponenten eines SQL Server-Big-Data-Clusters.

Controller
Der Controller bietet Verwaltungs-und Sicherheitsfunktionen für den Cluster. Er enthält den Verwaltungsdienst, den Konfigurationsspeicher und andere Dienste auf Clusterebene wie Kibana, Grafana und Elasticsearch.
Computepool
Der Computepool stellt Rechenressourcen für den Cluster bereit. Er enthält Knoten, auf denen Pods für SQL Server für Linux laufen. Die Pods im Computepool werden für bestimmte Verarbeitungsaufgaben in SQL-Computeinstanzen unterteilt.
Datenpool
Der Datenpool wird für Datenpersistenz verwendet. Der Datenpool besteht aus mindestens einem Pod, auf dem SQL Server für Linux ausgeführt wird. Er wird zum Erfassen von Daten aus SQL-Abfragen oder Spark-Aufträgen verwendet.
Speicherpool
Der Speicherpool besteht aus den Speicherpoolpods, bestehend aus SQL Server für Linux, Spark und HDFS. Alle Speicherknoten in einem Big-Data-Cluster für SQL Server sind Mitglieder eines HDFS-Clusters.
Tipp
Einen detaillierten Einblick in die Architektur und Installation von Big-Data-Clustern erhalten Sie unter Workshop: Microsoft SQL Server Big Data-Cluster Architektur.
App-Pool
Es handelt sich hierbei um die Bereitstellung von Anwendungen in SQL Server-Big Data-Clustern durch die Bereitstellung von Schnittstellen zum Erstellen, Verwalten und Ausführen von Anwendungen.
Szenarien und Features
Big Data-Cluster für SQL Server bieten Flexibilität bei der Interaktion mit Big Data. Sie können externe Datenquellen abfragen, Big Data in dem von SQL Server verwalteten HDFS speichern oder Daten aus mehreren externen Datenquellen über den Cluster abfragen. Die Daten können Sie dann für KI, Machine Learning und andere Analyseaufgaben verwenden.
Sie können SQL Server-Big Data-Cluster für Folgendes verwenden:
- Bereitstellen skalierbarer Cluster aus SQL Server-, Spark- und HDFS-Containern, die auf Kubernetes ausgeführt werden
- Lesen, Schreiben und Verarbeiten von Big Data von Transact-SQL oder Spark
- Einfaches Kombinieren und Analysieren hochwertiger relationaler Daten mit hohen Volumen von Big Data
- Abfragen externer Datenquellen
- Speichern von Big Data in von SQL Server verwaltetem HDFS
- Abfragen von Daten aus mehreren externen Datenquellen über den Cluster
- Verwenden der Daten für künstliche Intelligenz, maschinelles Lernen und andere Analyseaufgaben
- Bereitstellen und Ausführen von Anwendungen in Big Data-Clustern
- Virtualisieren von Daten mit PolyBase. Abfragen von Daten aus externen Datenquellen in SQL Server, Oracle, Teradata, MongoDB und generischen ODBC mit externen Tabellen.
- Bereitstellen der Hochverfügbarkeit für die SQL Server-Masterinstanz und alle Datenbanken mithilfe von Always On-Verfügbarkeitsgruppen
In den folgenden Abschnitten finden Sie weitere Informationen zu diesen Szenarios.
Datenvirtualisierung
Durch die Nutzung von PolyBase können Big Data-Cluster für SQL Server externe Datenquellen abfragen, ohne die Daten zu verschieben oder zu kopieren. SQL Server 2019 (15.x) führt neue Connectors für Datenquellen ein. Weitere Informationen finden Sie unter Neuerungen in PolyBase 2019.
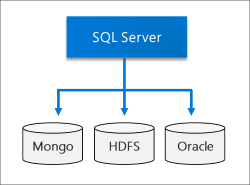
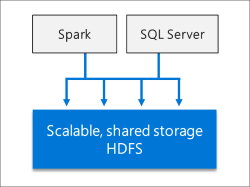
Data Lake
Ein Big-Data-Cluster für SQL Server enthält einen skalierbaren HDFS-Speicherpool. Dieser kann verwendet werden, um Big Data zu speichern, die möglicherweise aus mehreren externen Quellen erfasst wird. Sobald die Big Data im HDFS im Big-Data-Cluster gespeichert wurden, können Sie die Daten analysieren und abfragen und mit ihren relationalen Daten kombinieren.
Integrierte KI und maschinelles Lernen
Big Data-Cluster für SQL Server ermöglichen AI- und Machine Learning-Aufgaben für die Daten, die in HDFS-Speicherpools und den Datenpools gespeichert werden. Mithilfe von R, Python, Scala oder Java können Sie sowohl Spark als auch integrierte KI-Tools in SQL Server verwenden.

Verwaltung und Überwachung
Verwaltung und Überwachung werden durch eine Kombination von Befehlszeilentools, APIs, Portalen und dynamischen Verwaltungssichten bereitgestellt.
Sie können Azure Data Studio dazu verwenden, eine Vielzahl von Aufgaben im Big-Data-Cluster auszuführen:
- Integrierte Codeausschnitte für allgemeine Verwaltungsaufgaben.
- Möglichkeit zum Durchsuchen von HDFS, zum Hochladen von Dateien, zur Vorschau von Dateien und zum Erstellen von Verzeichnissen.
- Möglichkeit zum Erstellen, Öffnen und Ausführen von Jupyter-kompatiblen Notebooks.
- Datenvirtualisierungsassistent für eine vereinfachte Erstellung externer Datenquellen (aktiviert durch die Datenvirtualisierungserweiterung)
Kubernetes-Konzepte
Ein Big-Data-Cluster für SQL Server ist ein Cluster von Linux-Containern, die von Kubernetes orchestriert werden.
Kubernetes ist ein Open-Source-Containerorchestrator, mit dem Sie Containerbereitstellungen nach Bedarf skalieren können. In der folgenden Tabelle sind einige wichtige Kubernetes-Termini definiert:
| Begriff | BESCHREIBUNG |
|---|---|
| Cluster | Ein Kubernetes-Cluster ist eine Gruppe von Computern, die als Knoten bezeichnet werden. Ein Knoten steuert den Cluster und wird als Masterknoten bezeichnet. Die übrigen Knoten sind Workerknoten. Der Kubernetes-Master ist für die Verteilung der Arbeit auf die Worker und für die Überwachung der Clusterintegrität verantwortlich. |
| Node | Ein Knoten führt Containeranwendungen aus. Dabei kann es sich entweder um einen physischen oder einen virtuellen Computer handeln. Ein Kubernetes-Cluster kann eine Mischung aus Knoten von physischen und virtuellen Computern enthalten. |
| Pod | Ein Pod ist die unteilbare Bereitstellungseinheit von Kubernetes. Ein Pod ist eine logische Gruppe von einem oder mehreren Containern und zugeordneter Ressourcen, die zum Ausführen einer Anwendung erforderlich sind. Jeder Pod läuft auf einem Knoten. Ein Knoten kann einen oder mehrere Pods ausführen. Der Kubernetes-Master weist den Knoten im Cluster automatisch Pods zu. |
In SQL Server Big Data-Cluster ist Kubernetes für den Status des Clusters verantwortlich. Dabei erstellt und konfiguriert Kubernetes die Clusterknoten, weist den Knoten Pods zu und überwacht die Integrität des Clusters.
Zugehöriger Inhalt
- Erste Schritte bei der Bereitstellung von Big Data-Cluster für SQL Server
- Wiederherstellen einer Datenbank in der Masterinstanz eines Big Data-Clusters für SQL Server
- Übermitteln von Spark-Aufträgen auf Big Data-Cluster für SQL Server in Azure Data Studio
- Workshop zur Architektur von Big-Data-Clustern
- Big Data-Cluster in a Nutshell