Konfigurieren von PolyBase für den Zugriff auf externe Daten in Hadoop
Gilt für: ![]() SQL Server – nur Windows
SQL Server – nur Windows ![]() Azure SQL Managed Instance
Azure SQL Managed Instance
In diesem Artikel wird erläutert, wie Sie PolyBase in einer SQL Server-Instanz verwenden, um externe Daten in Hadoop abzufragen.
Hinweis
Ab SQL Server 2022 (16.x) wird Hadoop in PolyBase nicht mehr unterstützt.
Voraussetzungen
- Wenn Sie PolyBase nicht installiert haben, finden Sie weitere Informationen unter PolyBase installation (Installieren von PolyBase). Die Voraussetzungen für die Installation werden im entsprechenden Artikel erläutert.
- Ab SQL Server 2019 (15.x) müssen Sie auch das PolyBase-Feature aktivieren.
- PolyBase unterstützt zwei Hadoop-Anbieter: Hortonworks Data Platform (HDP) und Cloudera Distributed Hadoop (CDH). Hadoop folgt dem Muster „Hauptversion.Nebenversion“ für neue Releases, und alle Versionen, die zu einer unterstützten Haupt- und Nebenversion gehören, werden unterstützt. Informationen zu den unterstützten Versionen von HDP (Hortonworks Data Platform) und CDH (Cloudera Distributed Hadoop) finden Sie unter Konfiguration der PolyBase-Konnektivität.
Hinweis
PolyBase unterstützt Hadoop-Verschlüsselungszonen ab SQL Server 2016 SP1 CU7 und SQL Server 2017 CU3. Wenn Sie PolyBase-Erweiterungsgruppen verwenden, müssen alle Computeknoten auch einen Build aufweisen, der Unterstützung für Hadoop-Verschlüsselungszonen enthält.
Konfigurieren der Hadoop-Konnektivität
Zunächst konfigurieren Sie SQL Server PolyBase für die Verwendung Ihres Hadoop-Anbieters.
Führen Sie sp_configure mit „hadoop connectivity“ aus, und legen Sie einen geeigneten Wert für Ihren Anbieter fest. Informationen zum Ermitteln des Werts für Ihren Anbieter finden Sie unter Konfiguration der PolyBase-Konnektivität.
-- Values map to various external data sources. -- Example: value 7 stands for Hortonworks HDP 2.1 to 2.6 on Linux, -- 2.1 to 2.3 on Windows Server, and Azure Blob Storage sp_configure @configname = 'hadoop connectivity', @configvalue = 7; GO RECONFIGURE GOSie müssen SQL Server mithilfe von services.msc neu starten. Durch den Neustart von SQL Server werden folgende Dienste neu gestartet:
- SQL Server PolyBase-Datenverschiebungsdienst
- SQL Server PolyBase-Engine

Aktivieren der PushDown-Berechnung
Um die Abfrageleistung zu verbessern, aktivieren Sie die Weitergabeberechnung für Ihren Hadoop-Cluster:
Suchen Sie die Datei yarn-site.xml im Installationspfad von SQL Server. In der Regel lautet der Pfad:
C:\Program Files\Microsoft SQL Server\MSSQL13.MSSQLSERVER\MSSQL\Binn\PolyBase\Hadoop\conf\Suchen Sie auf dem Hadoop-Computer die analoge Datei im Hadoop-Konfigurationsverzeichnis. Suchen Sie in der Datei den Wert des Konfigurationsschlüssels „yarn.application.classpath.“, und kopieren Sie diesen.
Suchen Sie auf dem SQL Server-Computer in der Datei yarn-site.xml die Eigenschaft yarn.application.classpath. Fügen Sie den Wert vom Hadoop-Computer in das Element „Value“ ein.
Für alle CDH 5.X-Versionen müssen Sie die Konfigurationsparameter „mapreduce.application.classpath“ entweder ans Ende der Datei „yarn-site.xml“ oder in die Datei „mapred-site.xml“ einfügen. HortonWorks enthält diese Konfigurationen in den yarn.application.classpath-Konfigurationen. Weitere Beispiele finden Sie unter PolyBase-Konfiguration.
Wichtig
Wenn Sie die Pushdownberechnungsfunktion für Hadoop verwenden möchten, muss der Hadoop-Zielcluster über die Kernkomponenten von HDFS (Hadoop Distributed File System), YARN und MapReduce verfügen. Dabei muss der Auftragsverlaufserver aktiviert sein. PolyBase übermittelt die Weitergabeabfrage über MapReduc und ruft den Status über den Auftragsverlaufserver ab. Wenn keine dieser Komponenten vorhanden ist, tritt bei der Abfrage ein Fehler auf.
Konfigurieren einer externen Tabelle
Um die Daten in Ihrer Hadoop-Datenquelle abzufragen, müssen Sie eine externe Tabelle definieren, die in Transact-SQL-Abfragen verwendet werden soll. Die folgenden Schritte beschreiben, wie Sie die externe Tabelle konfigurieren.
Erstellen Sie einen Hauptschlüssel für die Datenbank, falls noch keiner vorhanden ist. Dies ist erforderlich, um das Geheimnis für die Anmeldeinformationen zu verschlüsseln.
CREATE MASTER KEY ENCRYPTION BY PASSWORD = 'password';Argumente
PASSWORD ='password'
Das zum Verschlüsseln des Datenbank-Hauptschlüssels verwendete Kennwort. „password“ (Kennwort) muss den Anforderungen der Windows-Kennwortrichtlinien des Computers entsprechen, auf dem die Instanz von SQL Server ausgeführt wird.
Erstellen Sie datenbankweite Anmeldeinformationen für Hadoop-Cluster, die mit Kerberos gesichert sind.
-- IDENTITY: the Kerberos user name. -- SECRET: the Kerberos password CREATE DATABASE SCOPED CREDENTIAL HadoopUser1 WITH IDENTITY = '<hadoop_user_name>', Secret = '<hadoop_password>';Erstellen Sie mit CREATE EXTERNAL DATA SOURCE eine externe Datenquelle.
-- LOCATION (Required) : Hadoop Name Node IP address and port. -- RESOURCE MANAGER LOCATION (Optional): Hadoop Resource Manager location to enable pushdown computation. -- CREDENTIAL (Optional): the database scoped credential, created above. CREATE EXTERNAL DATA SOURCE MyHadoopCluster WITH ( TYPE = HADOOP, LOCATION ='hdfs://10.xxx.xx.xxx:xxxx', RESOURCE_MANAGER_LOCATION = '10.xxx.xx.xxx:xxxx', CREDENTIAL = HadoopUser1 );Erstellen Sie mit CREATE EXTERNAL FILE FORMAT ein externes Dateiformat.
-- FORMAT TYPE: Type of format in Hadoop (DELIMITEDTEXT, RCFILE, ORC, PARQUET). CREATE EXTERNAL FILE FORMAT TextFileFormat WITH ( FORMAT_TYPE = DELIMITEDTEXT, FORMAT_OPTIONS (FIELD_TERMINATOR ='|', USE_TYPE_DEFAULT = TRUE))Erstellen Sie mit CREATE EXTERNAL TABLE eine externe Tabelle, die auf in Hadoop gespeicherte Daten verweist. In diesem Beispiel handelt es sich bei den externen Daten um Kfz-Sensordaten.
-- LOCATION: path to file or directory that contains the data (relative to HDFS root). CREATE EXTERNAL TABLE [dbo].[CarSensor_Data] ( [SensorKey] int NOT NULL, [CustomerKey] int NOT NULL, [GeographyKey] int NULL, [Speed] float NOT NULL, [YearMeasured] int NOT NULL ) WITH (LOCATION='/Demo/', DATA_SOURCE = MyHadoopCluster, FILE_FORMAT = TextFileFormat );Erstellen Sie Statistiken für eine externe Tabelle.
CREATE STATISTICS StatsForSensors on CarSensor_Data(CustomerKey, Speed)
PolyBase-Abfragen
Es gibt drei Funktionen, für die PolyBase geeignet ist:
- Ad-hoc-Abfragen von externen Tabellen
- Importieren von Daten
- Exportieren von Daten
Die folgenden Abfragen stellen fiktive Kfz-Sensordaten für das Beispiel bereit.
Ad-hoc-Abfragen
Die folgende Ad-hoc-Abfrage verknüpft relationale Daten mit Hadoop-Daten. Sie wählt Kunden aus, die schneller als 35 Meilen pro Stunde fahren, und verknüpft in SQL Server gespeicherte strukturierte Daten mit in Hadoop gespeicherten Daten aus KFZ-Sensoren.
SELECT DISTINCT Insured_Customers.FirstName,Insured_Customers.LastName,
Insured_Customers. YearlyIncome, CarSensor_Data.Speed
FROM Insured_Customers, CarSensor_Data
WHERE Insured_Customers.CustomerKey = CarSensor_Data.CustomerKey and CarSensor_Data.Speed > 35
ORDER BY CarSensor_Data.Speed DESC
OPTION (FORCE EXTERNALPUSHDOWN); -- or OPTION (DISABLE EXTERNALPUSHDOWN)
Daten importieren
Die folgende Abfrage importiert externe Daten in SQL Server. Dieses Beispiel importiert Daten zu schnellen Fahrern in SQL Server zur genaueren Analyse. Zu Verbesserung der Leistung wird in diesem Beispiel ein Columnstore-Index verwendet.
SELECT DISTINCT
Insured_Customers.FirstName, Insured_Customers.LastName,
Insured_Customers.YearlyIncome, Insured_Customers.MaritalStatus
INTO Fast_Customers from Insured_Customers INNER JOIN
(
SELECT * FROM CarSensor_Data where Speed > 35
) AS SensorD
ON Insured_Customers.CustomerKey = SensorD.CustomerKey
ORDER BY YearlyIncome
CREATE CLUSTERED COLUMNSTORE INDEX CCI_FastCustomers ON Fast_Customers;
Exportieren von Daten
Die folgende Abfrage exportiert Daten aus SQL Server nach Hadoop. Zu diesem Zweck müssen Sie zuerst den PolyBase-Export aktivieren. Erstellen Sie dann eine externe Tabelle für das Ziel, bevor Sie mit dem Datenexport beginnen.
-- Enable INSERT into external table
sp_configure 'allow polybase export', 1;
reconfigure
-- Create an external table.
CREATE EXTERNAL TABLE [dbo].[FastCustomers2009] (
[FirstName] char(25) NOT NULL,
[LastName] char(25) NOT NULL,
[YearlyIncome] float NULL,
[MaritalStatus] char(1) NOT NULL
)
WITH (
LOCATION='/old_data/2009/customerdata',
DATA_SOURCE = HadoopHDP2,
FILE_FORMAT = TextFileFormat,
REJECT_TYPE = VALUE,
REJECT_VALUE = 0
);
-- Export data: Move old data to Hadoop while keeping it query-able via an external table.
INSERT INTO dbo.FastCustomer2009
SELECT T.* FROM Insured_Customers T1 JOIN CarSensor_Data T2
ON (T1.CustomerKey = T2.CustomerKey)
WHERE T2.YearMeasured = 2009 and T2.Speed > 40;
Anzeigen von PolyBase-Objekten in SSMS
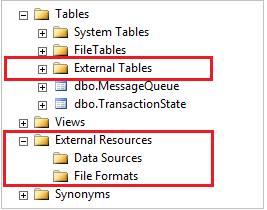
In SSMS werden externe Tabellen in einem separaten Ordner Externe Tabellenangezeigt. Externe Datenquellen und externe Dateiformate befinden sich in Unterordnern unter Externe Ressourcen.
Nächste Schritte
Weitere Lernprogramme zum Erstellen externer Datenquellen und externer Tabellen für eine Vielzahl von Datenquellen finden Sie unter PolyBase Transact-SQL-Referenz.
In den folgenden Artikeln finden Sie weitere Möglichkeiten zur Verwendung und Überwachung von PolyBase: