Leitfaden zur Architektur der Abfrageverarbeitung
Gilt für:![]() SQL Server
SQL Server![]() Azure SQL-Datenbank
Azure SQL-Datenbank![]() Azure SQL Managed Instance
Azure SQL Managed Instance
Die SQL Server-Datenbank-Engine verarbeitet Abfragen für verschiedene Datenspeicherarchitekturen, z.B. lokale Tabellen, partitionierte Tabellen und über mehrere Server verteilte Tabellen. In den folgenden Themen wird erläutert, wie mit SQL Server Abfragen verarbeitet werden und die Wiederverwendung von Abfragen mithilfe des Zwischenspeicherns von Ausführungsplänen optimiert wird.
Ausführungsmodi
Die SQL Server-Datenbank-Engine kann Transact-SQL-Anweisungen mit zwei verschiedenen Verarbeitungsmodi verarbeiten:
- Zeilenmodusausführung
- Batchmodusausführung
Zeilenmodusausführung
Die Zeilenmodusausführung ist eine Methode zur Abfrageverarbeitung, die mit herkömmlichen RDMBS-Tabellen verwendet wird, in denen Daten im Zeilenformat gespeichert sind. Wenn eine Abfrage ausgeführt wird und auf Daten in Rowstore-Tabellen zugreift, lesen die Operatoren der Ausführungsstruktur und die untergeordneten Operatoren jede erforderliche Zeile in allen Spalten, die im Tabellenschema angegeben wurden. Für jede gelesene Zeile ruft SQL Server die Spalten ab, die für das Resultset erforderlich sind und auf die durch SELECT-Anweisungen, JOIN-Prädikate oder Filterprädikate verwiesen wird.
Hinweis
Die Zeilenmodusausführung ist für OLTP-Szenarios sehr effizient, kann jedoch beim Überprüfen großer Datenmengen (z.B. in einem Data Warehousing-Szenario) weniger effizient sein.
Batchmodusausführung
DieBatchmodusausführung ist eine Methode zur Abfrageverarbeitung, die zum gleichzeitigen Abfragen mehrerer Zeilen (d.h. eines Batchs) verwendet wird. Jede Spalte innerhalb eines Batchs wird als Vektor in einem separaten Bereich des Arbeitsspeichers gespeichert. Die Batchmodusverarbeitung ist also vektorbasiert. Die Batchmodusverarbeitung verwendet ebenfalls Algorithmen, die für Mehrkern-CPUs und erhöhten Arbeitsspeicherdurchsatz bei moderner Hardware optimiert sind.
Bei ihrer Einführung war die Batchmodusausführung eng mit dem Columnstore-Speicherformat integriert und für dieses optimiert. Ab SQL Server 2019 (15.x) und in Azure SQL-Datenbank erfordert die Batchmodusausführung jedoch keine Columnstore-Indizes mehr. Weitere Informationen finden Sie unter Batchmodus bei Rowstore.
Bei der Batchmodusverarbeitung kommen, sofern möglich, komprimierte Daten zum Einsatz. Zugleich werden die Austauschoperatoren beseitigt, die von der Zeilenmodusausführung verwendet werden. Das Ergebnis ist eine bessere Parallelität und Leistung.
Wenn eine Abfrage im Batchmodus ausgeführt wird und auf Daten in Columnstore-Indizes zugreift, lesen die Operatoren der Ausführungsstruktur und die untergeordneten Operatoren mehrere Zeilen gleichzeitig in Spaltensegmenten. SQL Server liest nur die Spalten, die für das Ergebnis erforderlich sind und auf die durch eine SELECT-Anweisung, ein JOIN-Prädikat oder ein Filterprädikat verwiesen wird. Weitere Informationen zu Columnstore-Indizes finden Sie unter Columnstore-Indizes: Architektur.
Hinweis
Die Batchmodusausführung ist in Data Warehousing-Szenarios, bei denen große Datenmengen gelesen und aggregiert werden, sehr effizient.
Verarbeiten von SQL-Anweisungen
Die Verarbeitung einer einzelnen Transact-SQL-Anweisung ist das grundlegendste Verfahren, mit dem Transact-SQL-Anweisungen von SQL Server ausgeführt werden. Die Schritte, die zur Verarbeitung einer einzelnen SELECT -Anweisung verwendet werden, die nur auf lokale Basistabellen verweist (keine Sichten oder Remotetabellen), sollen das zugrunde liegende Verfahren veranschaulichen.
Rangfolge logischer Operatoren
Wenn mehr als ein logischer Operator in einer Anweisung verwendet wird, wird NOT zuerst ausgewertet, dann AND und schließlich OR. Arithmetische (und bitweise) Operatoren werden vor logischen Operatoren verarbeitet. Weitere Informationen finden Sie unter Operator Precedence (Operatorrangfolge).
Im folgenden Beispiel ist die Color-Bedingung nur für ProductModel 21 anwendbar und nicht für ProductModel 20, weil AND Vorrang gegenüber OR hat.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR ProductModelID = 21
AND Color = 'Red';
GO
Sie können die Bedeutung der Abfrage ändern, indem Sie durch Hinzufügen von Klammern veranlassen, dass der Operator OR zuerst ausgewertet wird. Die folgende Abfrage findet nur Produkte unter den Modellen 20 und 21, deren Farbe „red“ (rot) ist.
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE (ProductModelID = 20 OR ProductModelID = 21)
AND Color = 'Red';
GO
Die Verwendung von Klammern kann auch dann empfehlenswert sein, wenn diese nicht unbedingt erforderlich sind, da sie die Übersichtlichkeit von Abfragen verbessern und zudem die Wahrscheinlichkeit von Flüchtigkeitsfehlern verringern, die sich aus der Rangfolge der Operatorenauswertung ergeben. Die Leistung wird durch den Einsatz von Klammern nicht wesentlich beeinträchtigt. Das folgende Beispiel ist leichter zu lesen als das ursprüngliche Beispiel, obwohl sie syntaktisch übereinstimmen:
SELECT ProductID, ProductModelID
FROM Production.Product
WHERE ProductModelID = 20 OR (ProductModelID = 21
AND Color = 'Red');
GO
Optimieren von SELECT-Anweisungen
Eine SELECT-Anweisung ist nicht prozedural; sie gibt nicht die genauen Schritte vor, die der Datenbankserver verwenden soll, um die angeforderten Daten abzurufen. Dies bedeutet, dass der Datenbankserver die Anweisung analysieren muss, um das effizienteste Verfahren zum Extrahieren der angeforderten Daten zu ermitteln. Dieser Vorgang wird als Optimieren der SELECT -Anweisung bezeichnet. Die Komponente, die ihn durchführt, wird als Abfrageoptimierer bezeichnet. Die Eingaben für den Abfrageoptimierer bestehen aus der Abfrage, dem Datenbankschema (Tabellen- und Indexdefinitionen) und den Datenbankstatistiken. Die Ausgabe des Abfrageoptimierers ist ein Abfrageausführungsplan, der manchmal auch als Abfrageplan oder Ausführungsplan bezeichnet wird. Der Inhalt eines Ausführungsplans wird ausführlicher an späterer Stelle in diesem Artikel beschrieben.
Die Ein- und Ausgaben des Abfrageoptimierers während der Optimierung einer einzelnen SELECT-Anweisung werden in folgendem Diagramm dargestellt:
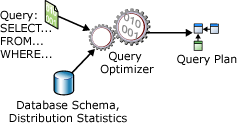
Eine SELECT -Anweisung definiert lediglich Folgendes:
- Das Format des Resultsets. Dieses wird meistens in der Auswahlliste angegeben. Das endgültige Format des Resultsets wird jedoch auch von anderen Klauseln, wie z.B.
ORDER BYundGROUP BY, beeinflusst. - Die Tabellen, die die Quelldaten enthalten. Dies wird in der
FROM-Klausel angegeben. - Die logischen Beziehungen zwischen den Tabellen, die im Rahmen der
SELECT-Anweisung relevant sind. Diese werden in den Joinspezifikationen definiert, die in derWHERE-Klausel oder in einerON-Klausel, die aufFROMfolgt, auftreten können. - Die Bedingungen, die die Zeilen in den Quelltabellen erfüllen müssen, um für die
SELECT-Anweisung qualifiziert zu sein. Diese werden in denWHERE- undHAVING-Klauseln angegeben.
In einem Abfrageausführungsplan wird Folgendes definiert:
Die Reihenfolge des Zugriffs auf die Quelltabellen.
In der Regel gibt es viele Abfolgen, in denen der Datenbankserver auf die Basistabellen zugreifen kann, um das Resultset zu erstellen. Wenn dieSELECT-Anweisung z.B. auf drei Tabellen verweist, könnte der Datenbankserver zuerst aufTableAzugreifen, dann die Daten ausTableAverwenden, um die entsprechenden Zeilen ausTableBzu extrahieren, und dann die Daten ausTableBverwenden, um Daten ausTableCzu extrahieren. Die anderen Abfolgen, in denen der Datenbankserver auf die Tabellen zugreifen kann, lauten:
TableC,TableB,TableAoder
TableB,TableA,TableCoder
TableB,TableC,TableAoder
TableC,TableATableBDie Methoden, die verwendet werden, um Daten aus den einzelnen Tabellen zu extrahieren.
Für den Zugriff auf die Daten in den einzelnen Tabellen gibt es in der Regel unterschiedliche Methoden. Wenn nur wenige Zeilen mit bestimmten Schlüsselwerten erforderlich sind, kann der Datenbankserver einen Index verwenden. Wenn alle Zeilen der Tabelle erforderlich sind, kann der Datenbankserver die Indizes übergehen und einen Tabellenscan ausführen. Wenn alle Zeilen einer Tabelle erforderlich sind, die Tabelle jedoch über einen Index verfügt, dessen Schlüsselspalten in einerORDER BY-Klausel verwendet werden, kann durch die Durchführung eines Indexscans anstelle eines Tabellenscans eine andere Sortierung des Resultsets gespeichert werden. Wenn es sich um eine sehr kleine Tabelle handelt, können Tabellenscans die effizienteste Methode für fast alle Zugriffe auf die Tabelle darstellen.Die Methoden, die für Berechnungen und zum Filtern, Aggregieren und Sortieren von Daten aus den einzelnen Tabellen verwendet werden.
Beim Zugriff auf Daten von Tabellen aus gibt es verschiedene Methoden zum Durchführen von Berechnungen für Daten – z. B. Berechnen von skalaren Werten –, zum Aggregieren und Sortieren von Daten wie im Abfragetext definiert – z. B. bei Verwendung einerGROUP BY- oderORDER BY-Klausel –, und zum Filtern von Daten – z. B. bei Verwendung einerWHERE- oderHAVING-Klausel.
Der Vorgang, in dessen Verlauf ein bestimmter Ausführungsplan aus einer Anzahl möglicher Ausführungspläne ausgewählt wird, wird Optimierung genannt. Der Abfrageoptimierer ist eine der wichtigsten Komponenten des Datenbank-Engine. Der Abfrageoptimierer erzeugt zwar den zusätzlichen Aufwand, um die Abfrage analysieren und einen Plan auswählen zu können, ein Vielfaches dieses Aufwands wird jedoch normalerweise dadurch eingespart, dass der Abfrageoptimierer einen effizienten Ausführungsplan auswählt. Nehmen Sie z. B. an, zwei Bauunternehmer erhalten dieselben Konstruktionszeichnungen für ein Haus. Wenn nun das eine Unternehmen zunächst einige Tage darauf verwendet, den Bau des Hauses detailliert zu planen, das andere Unternehmen jedoch sofort und ohne weitere Planung mit dem Bau des Hauses beginnt, ist es mehr als wahrscheinlich, dass das erste Unternehmen, das sich Zeit für die Planung des Projekts nimmt, den Bau des Hauses zuerst abschließen wird.
Der Abfrageoptimierer von SQL Server arbeitet kostenorientiert. Jeder denkbare Ausführungsplan verfügt über zugeordnete Kosten hinsichtlich des Umfangs der benötigten Verarbeitungsressourcen. Der Abfrageoptimierer muss die möglichen Pläne analysieren und den Plan auswählen, der die geringsten geschätzten Kosten verursacht. Einige komplexe SELECT -Anweisungen verfügen über mehrere Tausend mögliche Ausführungspläne. In einem solchen Fall werden nicht alle denkbaren Kombinationen vom Abfrageoptimierer analysiert. Stattdessen werden komplexe Algorithmen verwendet, um einen Ausführungsplan zu ermitteln, dessen Kosten sich in vernünftigem Rahmen an die möglichen Mindestkosten annähern.
Der Abfrageoptimierer von SQL Server wählt nicht nur den Ausführungsplan aus, der die geringsten Kosten bezüglich der benötigten Ressourcen verursacht. Stattdessen wird der Plan ausgewählt, der die Ergebnisse so schnell wie möglich an den Benutzer zurückgibt und dabei Kosten für Ressourcen in vertretbarem Maß verursacht. Für die parallele Verarbeitung einer Abfrage werden in der Regel mehr Ressourcen verwendet als für die serielle Verarbeitung, die Abfrageausführung wird jedoch schneller beendet. Der SQL Server-Abfrageoptimierer verwendet einen Plan mit paralleler Ausführung, um Ergebnisse zurückzugeben, wenn sich dies nicht negativ auf die Serverlast auswirkt.
Der SQL Server-Abfrageoptimierer stützt sich bei der Schätzung der Ressourcenkosten, die durch unterschiedliche Methoden zum Extrahieren von Informationen aus einer Tabelle oder einem Index verursacht werden, auf Verteilungsstatistiken. Die Verteilungsstatistiken werden für Spalten und Indizes gespeichert und enthalten Informationen über die Dichte1 der zugrunde liegenden Daten. Dies dient dazu, die Selektivität der Werte in einem bestimmten Index oder einer bestimmten Spalte zu kennzeichnen. In einer Tabelle für Autos stammen z. B. viele Autos von demselben Hersteller, jedes Auto verfügt jedoch über eine eindeutige Fahrzeugnummer. Ein Index für das VIN-Objekt weist eine höhere Selektivität auf als ein Index für den Hersteller, da „VIN“ eine niedrigere Dichte als „Hersteller“ aufweist. Wenn die Indexstatistik nicht auf dem aktuellen Stand ist, wählt der Abfrageoptimierer möglicherweise nicht den Plan aus, der für den aktuellen Status der Tabelle am besten geeignet ist. Weitere Informationen zu Dichten finden Sie unter Statistik.
1 Dichte definiert die Verteilung von eindeutigen Werten, die in den Daten vorhanden sind, oder die durchschnittliche Anzahl doppelter Werte für eine bestimmte Spalte. Bei einer Verringerung der Dichte erhöht sich die Selektivität eines Werts.
Der SQL Server-Abfrageoptimierer ist deshalb so wichtig, weil er es dem Datenbankserver ermöglicht, dynamische Anpassungen an geänderte Bedingungen in der Datenbank vorzunehmen, ohne dass eine Eingabe durch einen Programmierer oder Datenbankadministrator erforderlich ist. Programmierer können sich somit darauf konzentrieren, das endgültige Ergebnis der Abfrage zu beschreiben. Sie können sich darauf verlassen, dass der SQL Server-Abfrageoptimierer bei jeder Ausführung der Anweisung einen effizienten Ausführungsplan auf der Basis des aktuellen Status der Datenbank erstellt.
Hinweis
SQL Server Management Studio verfügt über drei Optionen zum Anzeigen von Ausführungsplänen:
- Der geschätzte Ausführungsplan: Dieser entspricht dem kompilierten, vom Abfrageoptimierer erzeugten Plan.
- Der tatsächliche Ausführungsplan: Dieser entspricht dem kompilierten Plan und enthält zusätzlich den zugehörigen Ausführungskontext. Dies umfasst die Laufzeitinformationen, die nach Abschluss der Ausführung verfügbar sind, z. B. Ausführungswarnungen oder, in neueren Versionen von Datenbank-Engine, die vergangene und die CPU-Zeit der Ausführung.
- Die Live-Abfragestatistik: Diese entspricht dem kompilierten Plan und enthält zusätzlich den Ausführungskontext. Dies umfasst Laufzeitinformationen während des Ausführungsfortschritts, die sekündlich aktualisiert werden. Laufzeitinformationen enthalten beispielsweise die genaue Anzahl der Zeilen, die die Operatoren durchlaufen.
Verarbeiten einer SELECT-Anweisung
SQL Server führt zur Verarbeitung einer einzelnen SELECT-Anweisung die folgenden grundlegenden Schritte aus:
- Der Parser scannt die
SELECT-Anweisung und spaltet sie in ihre logischen Einheiten auf, wie z.B. Schlüsselwörter, Ausdrücke, Operatoren und Bezeichner. - Eine Abfragestruktur, manchmal auch Sequenzstruktur genannt, wird erstellt, die die logischen Schritte beschreibt, die für die Transformation der Quelldaten in das für das Resultset benötigte Format erforderlich sind.
- Der Abfrageoptimierer analysiert verschiedene Arten des Zugriffs auf die Quelltabellen. Anschließend wählt er die Reihenfolge der Schritte aus, mit denen die Ergebnisse am schnellsten mithilfe möglichst weniger Ressourcen zurückgegeben werden. Die Abfragestruktur wird aktualisiert, um diese genaue Reihenfolge von Schritten aufzuzeichnen. Die endgültige, optimierte Version der Abfragestruktur wird als Ausführungsplan bezeichnet.
- Die relationale Engine beginnt mit der Ausführung des Ausführungsplans. Während der Verarbeitung von Schritten, für die Daten aus den Basistabellen erforderlich sind, fordert die relationale Engine an, dass die Speicher-Engine die Daten aus den Rowsets übergibt, die durch die relationale Engine angefordert wurden.
- Die relationale Engine transformiert die Daten, die von der Speicher-Engine zurückgegeben werden, in das für das Resultset definierte Format und gibt das Resultset an den Client zurück.
Reduktion konstanter Ausdrücke und Auswertung von Ausdrücken
SQL Server wertet bestimmte konstante Ausdrücke frühzeitig aus, um die Abfrageleistung zu steigern. Dies wird als Reduktion konstanter Ausdrücke bezeichnet. Eine Konstante ist ein Transact-SQL-Literal, z. B. 3, 'ABC', '2005-12-31', 1.0e3 oder 0x12345678.
Zur Kompilierzeit reduzierbare Ausdrücke
SQL Server verwendet die Reduktion konstanter Ausdrücke mit den folgenden Ausdruckstypen:
- Arithmetische Ausdrücke wie
1 + 1und5 / 3 * 2, die nur Konstanten enthalten. - Logische Ausdrücke wie
1 = 1und1 > 2 AND 3 > 4, die nur Konstanten enthalten. - Integrierte Funktionen, die von SQL Server zur Kompilierzeit reduziert werden können, einschließlich
CASTundCONVERT. Im Allgemeinen gilt eine systeminterne Funktion als zur Kompilierzeit reduzierbar, wenn sie ausschließlich aus Eingaben besteht – ohne weitere kontextbezogene Informationen wie SET-Optionen, Spracheinstellungen, Datenbankoptionen oder Verschlüsselungsschlüssel. Nicht deterministische Funktionen sind nicht zur Kompilierzeit reduzierbar. Deterministische integrierte Funktionen sind bis auf einige Ausnahmen zur Kompilierzeit reduzierbar. - Deterministische Methoden von CLR-benutzerdefinierten Typen sowie deterministische CLR-benutzerdefinierte Skalarwertfunktionen (beginnend mit SQL Server 2012 (11.x)). Weitere Informationen finden Sie unter Reduktion konstanter Ausdrücke für benutzerdefinierte CLR-Funktionen und -Methoden.
Hinweis
Eine Ausnahme sind große Objekte. Wenn der Ausgabetyp des Reduktionsprozesses ein großes Objekt (text, ntext, image, nvarchar(max), varchar(max), varbinary(max) oder XML) ist, reduziert SQL Server den Ausdruck nicht zur Kompilierzeit.
Nicht zur Kompilierzeit reduzierbare Ausdrücke
Alle anderen Ausdruckstypen können nicht zur Kompilierzeit reduziert werden. Das gilt insbesondere für folgende Arten von Ausdrücken:
- Nicht konstante Ausdrücke, wie z. B. Ausdrücke, deren Ergebnisse vom Wert einer Spalte abhängig sind.
- Ausdrücke, deren Ergebnisse von einer lokalen Variable bzw. einem lokalen Parameter abhängig sind, wie z. B. @x.
- Nicht deterministische Funktionen.
- Benutzerdefinierte Transact-SQL-Funktionen1.
- Ausdrücke, deren Ergebnisse von Spracheinstellungen abhängig sind.
- Ausdrücke, deren Ergebnisse von SET-Optionen abhängig sind.
- Ausdrücke, deren Ergebnisse von Serverkonfigurationsoptionen abhängig sind.
1 Vor SQL Server 2012 (11.x) konnten deterministische CLR-benutzerdefinierte Skalarwertfunktionen und Methoden CLR-benutzerdefinierter Typen nicht reduziert werden.
Beispiele für zur Kompilierzeit reduzierbare und nicht zur Kompilierzeit reduzierbare konstante Ausdrücke
Betrachten Sie die folgende Abfrage:
SELECT *
FROM Sales.SalesOrderHeader AS s
INNER JOIN Sales.SalesOrderDetail AS d
ON s.SalesOrderID = d.SalesOrderID
WHERE TotalDue > 117.00 + 1000.00;
Wird für diese Abfrage die PARAMETERIZATION-Datenbankoption nicht auf FORCEDfestgelegt, wird der Ausdruck 117.00 + 1000.00 ausgewertet und durch sein Ergebnis (1117.00) ersetzt, bevor die Abfrage kompiliert wird. Die Vorteile dieser Reduktion des konstanten Ausdrucks sind folgende:
- Der Ausdruck muss zur Laufzeit nicht mehrmals ausgewertet werden.
- Der durch die Auswertung des Ausdrucks erhaltene Wert wird vom Abfrageoptimierer verwendet, um die Größe des Resultsets der Teilabfrage
TotalDue > 117.00 + 1000.00zu schätzen.
Wenn dbo.f jedoch eine skalare benutzerdefinierte Funktion ist, wird der Ausdruck dbo.f(100) nicht zur Kompilierzeit reduziert, da SQL Server keine benutzerdefinierten Funktionen zur Kompilierzeit reduziert, auch wenn sie deterministisch sind. Weitere Informationen zur Parametrisierung finden Sie unter Erzwungene Parametrisierung weiter unten in diesem Artikel.
Ausdrucksauswertung
Außerdem werden bestimmte Ausdrücke, die zwar nicht zur Kompilierzeit ausgewertet werden, deren Argumente jedoch zur Kompilierzeit bekannt sind – unabhängig davon, ob es sich bei den Argumenten um Parameter oder Konstanten handelt – hinsichtlich der Größe ihrer Resultsets (Kardinalität) geschätzt. Dieser Vorgang ist ein Bestandteil des Abfrageoptimierers.
Insbesondere werden folgende integrierte Funktionen und spezielle Operatoren zur Kompilierzeit ausgewertet, wenn alle diesbezüglichen Eingaben bekannt sind: UPPER, LOWER, RTRIM, DATEPART( YY only ), GETDATE, CAST und CONVERT. Die folgenden Operatoren werden ebenfalls zur Kompilierzeit ausgewertet, wenn alle diesbezüglichen Eingaben bekannt sind:
- Arithmetische Operatoren: +, -, *, /, unäres Minus
- Logische Operatoren:
AND,ORundNOT - Vergleichsoperatoren: <, >, <=, >=, <>,
LIKE,IS NULL,IS NOT NULL
Während der Kardinalitätsschätzung wertet der Abfrageoptimierer keine anderen Funktionen oder Operatoren aus.
Beispiele für die Ausdrucksauswertung zur Kompilierzeit
Sehen Sie sich diese gespeicherte Prozedur an:
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc( @d datetime )
AS
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d+1;
Während der Optimierung der SELECT-Anweisung der Prozedur versucht der Abfrageoptimierer, die erwartete Kardinalität des Resultsets für die Bedingung OrderDate > @d+1 auszuwerten. Der Ausdruck @d+1 kann nicht zur Kompilierzeit reduziert werden, da @d ein Parameter ist. Zum Zeitpunkt der Optimierung ist der Wert dieses Parameters jedoch bekannt. Dadurch kann der Abfrageoptimierer die Größe des Resultsets genau schätzen, was zur Auswahl des optimalen Abfrageplans beiträgt.
Betrachten Sie nun ein ähnliches Beispiel, in dem jedoch @d2 durch eine lokale Variable, @d+1, ersetzt wird, und der Ausdruck statt in einer Abfrage in einer SET-Anweisung ausgewertet wird.
USE AdventureWorks2022;
GO
CREATE PROCEDURE MyProc2( @d datetime )
AS
BEGIN
DECLARE @d2 datetime
SET @d2 = @d+1
SELECT COUNT(*)
FROM Sales.SalesOrderHeader
WHERE OrderDate > @d2
END;
Wenn die SELECT-Anweisung in MyProc2 in SQL Server optimiert wird, ist der Wert von @d2 nicht bekannt. Daher verwendet der Abfrageoptimierer eine Standardschätzung für die Selektivität von OrderDate > @d2 (in diesem Fall 30 Prozent).
Verarbeiten anderer Anweisungen
Die zuvor beschriebenen grundlegenden Schritte für die Verarbeitung einer SELECT-Anweisung gelten auch für andere Transact-SQL-Anweisungen wie INSERT, UPDATE und DELETE. UPDATE - und DELETE -Anweisungen müssen sich auf die Gruppe von Zeilen beziehen, die geändert bzw. gelöscht werden soll. Der Vorgang zum Identifizieren dieser Zeilen ist der gleiche Vorgang, der zum Identifizieren der Quellzeilen verwendet wird, die einen Beitrag zum Resultset einer SELECT -Anweisung leisten. Die UPDATE- und INSERT-Anweisung können eingebettete SELECT-Anweisungen enthalten, welche die Datenwerte bereitstellen, die aktualisiert oder eingefügt werden sollen.
Sogar DDL-Anweisungen (Data Definition Language, Datendefinitionssprache), wie z.B. CREATE PROCEDURE oder ALTER TABLE, werden letztendlich in eine Folge relationaler Operationen aufgelöst, die für die Systemkatalogtabellen und manchmal (wie bei ALTER TABLE ADD COLUMN) auch für die Datentabellen ausgeführt werden.
Arbeitstabellen
Soll eine logische Operation ausgeführt werden, die in einer Transact-SQL-Anweisung angegeben wurde, muss die relationale Engine ggf. eine Arbeitstabelle erstellen. Arbeitstabellen sind interne Tabellen, die zum Speichern von Zwischenergebnissen verwendet werden. Arbeitstabellen werden für bestimmte GROUP BY-, ORDER BY- oder UNION -Abfragen generiert. Wenn beispielsweise eine ORDER BY-Klausel auf Spalten verweist, die nicht durch Indizes erfasst werden, muss die relationale Engine ggf. eine Arbeitstabelle generieren, um das Resultset in der angeforderten Reihenfolge sortieren zu können. Arbeitstabellen werden mitunter auch als Spool-Speicher verwendet, die vorübergehend das Ergebnis der Ausführung eines Teils eines Abfrageplans aufnehmen. Arbeitstabellen werden in tempdb erstellt und automatisch wieder gelöscht, sobald sie nicht mehr benötigt werden.
Sichtauflösung
Der SQL Server-Abfrageprozessor behandelt indizierte und nicht indizierte Sichten unterschiedlich:
- Die Zeilen einer indizierten Sicht werden in der Datenbank in demselben Format wie eine Tabelle gespeichert. Wenn sich der Abfrageoptimierer entscheidet, eine indizierte Sicht in einem Abfrageplan zu verwenden, wird die indizierte Sicht auf die gleiche Weise wie eine Basistabelle behandelt.
- Nur die Definition einer nicht indizierten Sicht wird gespeichert, nicht die Zeilen der Sicht. Der Abfrageoptimierer nimmt die Logik aus der Sichtdefinition in den Ausführungsplan auf, den er für die Transact-SQL-Anweisung erstellt, die auf die nicht indizierte Sicht verweist.
Die Logik, mit der der SQL Server-Abfrageoptimierer entscheidet, wann eine indizierte Sicht verwendet werden soll, ist mit der Logik vergleichbar, mit der ermittelt wird, wann ein Index für eine Tabelle verwendet wird. Wenn die Daten in der indizierten Sicht die gesamte oder einen Teil der Transact-SQL-Anweisung erfüllen und der Abfrageoptimierer ermittelt, dass ein Index für die Sicht der Zugriffspfad mit den geringsten Kosten ist, wählt der Abfrageoptimierer den Index unabhängig davon aus, ob im Namen der Abfrage auf die Sicht verwiesen wird.
Wenn eine Transact-SQL-Anweisung auf eine nicht indizierte Sicht verweist, analysieren der Parser und der Abfrageoptimierer sowohl die Quelle der Transact-SQL-Anweisung als auch die Quelle der Sicht und lösen sie dann zu einem einzelnen Ausführungsplan auf. Es gibt nicht einen Plan für die Transact-SQL-Anweisung und einen weiteren Plan für die Sicht.
Nehmen Sie z. B. an, dass die folgende Sicht verwendet wird:
USE AdventureWorks2022;
GO
CREATE VIEW EmployeeName AS
SELECT h.BusinessEntityID, p.LastName, p.FirstName
FROM HumanResources.Employee AS h
JOIN Person.Person AS p
ON h.BusinessEntityID = p.BusinessEntityID;
GO
Von dieser Sicht ausgehend führen die beiden folgenden Transact-SQL-Anweisungen die gleichen Vorgänge für die Basistabellen aus und erzeugen identische Ergebnisse:
/* SELECT referencing the EmployeeName view. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.Sales.SalesOrderHeader AS soh
JOIN AdventureWorks2022.dbo.EmployeeName AS EmpN
ON (soh.SalesPersonID = EmpN.BusinessEntityID)
WHERE OrderDate > '20020531';
/* SELECT referencing the Person and Employee tables directly. */
SELECT LastName AS EmployeeLastName, SalesOrderID, OrderDate
FROM AdventureWorks2022.HumanResources.Employee AS e
JOIN AdventureWorks2022.Sales.SalesOrderHeader AS soh
ON soh.SalesPersonID = e.BusinessEntityID
JOIN AdventureWorks2022.Person.Person AS p
ON e.BusinessEntityID =p.BusinessEntityID
WHERE OrderDate > '20020531';
Durch die SQL Server Management Studio-Showplanfunktion wird deutlich, dass die relationale Engine für beide SELECT-Anweisungen denselben Ausführungsplan erstellt.
Verwenden von Hinweisen mit Sichten
Hinweise, die für Sichten in einer Abfrage gespeichert werden, können zu Konflikten mit anderen Hinweisen führen, die beim Erweitern der Sicht für den Zugriff auf ihre Basistabellen erkannt werden. Wenn das passiert, gibt die Abfrage einen Fehler zurück. Angenommen, die folgende Sicht enthält einen Tabellenhinweis in ihrer Definition:
USE AdventureWorks2022;
GO
CREATE VIEW Person.AddrState WITH SCHEMABINDING AS
SELECT a.AddressID, a.AddressLine1,
s.StateProvinceCode, s.CountryRegionCode
FROM Person.Address a WITH (NOLOCK), Person.StateProvince s
WHERE a.StateProvinceID = s.StateProvinceID;
Nehmen Sie nun an, dass die folgende Abfrage eingegeben wird:
SELECT AddressID, AddressLine1, StateProvinceCode, CountryRegionCode
FROM Person.AddrState WITH (SERIALIZABLE)
WHERE StateProvinceCode = 'WA';
Die Abfrage erzeugt einen Fehler, weil der SERIALIZABLE -Hinweis, der für die Person.AddrState -Sicht in der Abfrage angewendet wird, an die beiden Tabellen Person.Address und Person.StateProvince in der Sicht weitergegeben wird, wenn diese erweitert wird. Das Erweitern der Sicht legt jedoch außerdem den NOLOCK -Hinweis für Person.Addressoffen. Da die SERIALIZABLE - und NOLOCK -Hinweise einen Konflikt verursachen, ist die sich ergebende Abfrage falsch.
Die PAGLOCK-, NOLOCK-, ROWLOCK-, TABLOCK- oder TABLOCKX -Tabellenhinweise verursachen Konflikte miteinander, genau wie die HOLDLOCK-, NOLOCK-, READCOMMITTED-, REPEATABLEREAD-, SERIALIZABLE -Tabellenhinweise.
Hinweise können über die Ebenen geschachtelter Sichten weitergegeben werden. Angenommen, eine Abfrage wendet den HOLDLOCK -Hinweis auf eine v1-Sicht an. Wenn v1 erweitert wird, wird erkennbar, dass die Sicht v2 Teil ihrer Definition ist. Die Definition vonv2enthält einen NOLOCK -Hinweis für eine der Basistabellen der Sicht. Diese Tabelle erbt jedoch außerdem den HOLDLOCK -Hinweis für die Sicht v1von der Abfrage. Da die NOLOCK - und HOLDLOCK -Hinweise einen Konflikt verursachen, führt die Abfrage zu einem Fehler.
Wenn der FORCE ORDER -Hinweis in einer Abfrage verwendet wird, die eine Sicht enthält, wird die Joinreihenfolge der Tabellen innerhalb der Sicht durch die Position der Sicht im sortierten Konstrukt festgelegt. Die folgende Abfrage trifft z. B. eine Auswahl aus drei Tabellen und einer Sicht:
SELECT * FROM Table1, Table2, View1, Table3
WHERE Table1.Col1 = Table2.Col1
AND Table2.Col1 = View1.Col1
AND View1.Col2 = Table3.Col2;
OPTION (FORCE ORDER);
Außerdem ist View1 wie im folgenden Beispiel gezeigt definiert:
CREATE VIEW View1 AS
SELECT Colx, Coly FROM TableA, TableB
WHERE TableA.ColZ = TableB.Colz;
Die Joinreihenfolge im Abfrageplan lautet Table1, Table2, TableA, TableB, Table3.
Auflösen von Indizes für Sichten
Wie bei jedem Index entscheidet sich SQL Server nur dann für die Verwendung einer indizierten Sicht in seinem Abfrageplan, wenn der Abfrageoptimierer feststellt, dass dies vorteilhaft ist.
Indizierte Sichten können in jeder Edition von SQL Server erstellt werden. In einigen Editionen einiger älterer Versionen von SQL Server berücksichtigt der Abfrageoptimierer die indizierte Sicht automatisch. In einigen Editionen einiger älterer Versionen von SQL Server muss der NOEXPAND -Tabellenhinweis verwendet werden, um eine indizierte Sicht zu verwenden. Die automatische Verwendung einer indizierten Ansicht durch den Abfrageoptimierer wird nur in bestimmten Editionen von SQL Server unterstützt. Azure SQL-Datenbank und Azure SQL Managed Instance unterstützen auch die automatische Verwendung indizierter Ansichten ohne Angabe des NOEXPAND-Hinweises.
Der Abfrageoptimierer von SQL Server verwendet eine indizierte Sicht, wenn die folgenden Bedingungen erfüllt sind:
- Die folgenden Sitzungsoptionen sind auf
ONfestgelegt:ANSI_NULLSANSI_PADDINGANSI_WARNINGSARITHABORTCONCAT_NULL_YIELDS_NULLQUOTED_IDENTIFIER
- Die
NUMERIC_ROUNDABORT-Sitzungsoption ist auf OFF festgelegt. - Der Abfrageoptimierer findet eine Übereinstimmung zwischen den Indexspalten der Sicht und Abfrageelementen, wie z. B.:
- Suchbedingungsprädikate in der WHERE-Klausel
- Joinvorgänge
- Aggregatfunktionen
GROUP BY-Klauseln- Tabellenverweise
- Die geschätzten Kosten für das Verwenden des Indexes sind die niedrigsten Kosten aller durch den Abfrageoptimierer berücksichtigten Zugriffsmechanismen.
- Für jede Tabelle, auf die in der Abfrage verwiesen wird (entweder direkt oder durch Erweitern einer Sicht zum Zugriff auf die zugrunde liegenden Tabellen), die einem Tabellenverweis in der indizierten Sicht entspricht, muss derselbe Satz von Hinweisen in der Abfrage angewendet werden.
Hinweis
Die READCOMMITTED - und READCOMMITTEDLOCK -Hinweise werden in diesem Kontext immer als unterschiedliche Hinweise angesehen, unabhängig von der aktuellen Transaktionsisolationsstufe.
Abweichend von den Anforderungen für die SET-Optionen und Tabellenhinweise verwendet der Abfrageoptimierer hier dieselben Regeln, mit denen er ermittelt, ob ein Tabellenindex eine Abfrage erfüllt. In der zu verwendenden Abfrage für eine indizierte Sicht muss nichts weiter angegeben werden.
Eine Abfrage muss nicht explizit in der FROM-Klausel auf eine indizierte Sicht verweisen, damit der Abfrageoptimierer die indizierte Sicht verwendet. Falls die Abfrage Verweise auf Spalten in den Basistabellen enthält, die auch in der indizierten Sicht vorhanden sind, und der Abfrageoptimierer schätzt, dass das Verwenden der indizierten Sicht den kostengünstigsten Zugriffsmechanismus darstellt, wählt der Abfrageoptimierer die indizierte Sicht aus. Die Vorgehensweise ist dabei ähnlich wie bei der Auswahl von Basistabellenindizes, wenn in einer Abfrage nicht direkt auf diese verwiesen wird. Der Abfrageoptimierer kann die Sicht auswählen, wenn sie Spalten enthält, auf die die Abfrage nicht verweist – vorausgesetzt die Sicht bietet die kostengünstigste Möglichkeit zum Abdecken mindestens einer Spalte, die in der Abfrage angegeben ist.
Der Abfrageoptimierer behandelt eine indizierte Sicht, auf die in der FROM-Klausel verwiesen wird, als Standardsicht. Der Abfrageoptimierer erweitert am Beginn des Optimierungsprozesses die Definition der Sicht in die Abfrage. Dann erfolgt der Abgleich der indizierten Sicht. Die indizierte Sicht kann im endgültigen Ausführungsplan verwendet werden, der vom Abfrageoptimierer ausgewählt wird, oder stattdessen kann der Plan die erforderlichen Daten aus der Sicht materialisieren, indem auf die Basistabellen zugegriffen wird, auf die durch die Sicht verwiesen wird. Der Abfrageoptimierer wählt die kostengünstigste Alternative aus.
Verwenden von Hinweisen mit indizierten Sichten
Sie können verhindern, dass Sichtindizes für eine Abfrage verwendet werden, indem Sie den EXPAND VIEWS -Abfragehinweis verwenden oder indem Sie mit dem NOEXPAND -Tabellenhinweis die Verwendung eines Indexes für eine indizierte Sicht erzwingen, die in der FROM -Klausel einer Abfrage angegeben ist. Sie sollten jedoch den Abfrageoptimierer für jede Abfrage dynamisch ermitteln lassen, welches die besten Zugriffsmethoden sind. Verwenden Sie EXPAND und NOEXPAND nur in bestimmten Fällen, wenn Tests gezeigt haben, dass durch sie die Leistung deutlich gesteigert wird.
Die Option
EXPAND VIEWSgibt an, dass der Abfrageoptimierer für die gesamte Abfrage keine Sichtindizes verwendet.Wenn
NOEXPANDfür eine Sicht angegeben wird, zieht der Abfrageoptimierer die Verwendung sämtlicher Indizes in Erwägung, die für die Sicht definiert sind.NOEXPANDmit der optionalenINDEX()-Klausel zwingt den Abfrageoptimierer, die angegebenen Indizes zu verwenden.NOEXPANDkann nur für eine indizierte Sicht angegeben werden, nicht für eine nicht indizierte Sicht. Die automatische Verwendung einer indizierten Ansicht durch den Abfrageoptimierer wird nur in bestimmten Editionen von SQL Server unterstützt. Azure SQL-Datenbank und Azure SQL Managed Instance unterstützen auch die automatische Verwendung indizierter Ansichten ohne Angabe desNOEXPAND-Hinweises.
Wenn weder NOEXPAND noch EXPAND VIEWS in einer Abfrage angegeben ist, die eine Sicht enthält, wird die Sicht erweitert, um auf die zugrunde liegenden Tabellen zuzugreifen. Wenn die Abfrage, die die Sicht bildet, irgendwelche Tabellenhinweise enthält, werden diese Hinweise auch an die zugrunde liegenden Tabellen weitergegeben. (Detaillierte Informationen zu diesem Vorgang finden Sie unter „Sichtauflösung“.) Solange die der Sicht zugrunde liegenden Tabellen identische Sätze von Hinweisen besitzen, kommt die Abfrage für den Abgleich mit einer indizierten Sicht infrage. Zumeist stimmen diese Hinweise miteinander überein, da sie direkt aus der Sicht vererbt werden. Wenn die Abfrage jedoch auf Tabellen und nicht auf Sichten verweist und die direkt auf diese Tabellen angewendeten Hinweise nicht identisch sind, kommt eine solche Abfrage nicht für den Abgleich mit einer indizierten Sicht infrage. Wenn die Hinweise INDEX, PAGLOCK, ROWLOCK, TABLOCKX, UPDLOCKoder XLOCK auf die Tabellen angewendet werden, auf die die Abfrage nach der Sichterweiterung verweist, kommt die Abfrage nicht für den Abgleich mit einer indizierten Sicht infrage.
Wenn ein Tabellenhinweis in Form von INDEX (index_val[ ,...n] ) auf eine Sicht in einer Abfrage verweist und Sie nicht gleichzeitig den NOEXPAND-Hinweis angeben, wird der Indexhinweis ignoriert. Zum Angeben eines bestimmten Indexes verwenden Sie NOEXPAND.
Allgemein gilt: Wenn der Abfrageoptimierer eine indizierte Sicht mit einer Abfrage abgleicht, werden alle für die Tabellen oder Sichten in der Abfrage angegebenen Hinweise direkt auf die indizierte Sicht angewendet. Wenn der Abfrageoptimierer sich entscheidet, keine indizierte Sicht zu verwenden, werden alle Hinweise direkt zu den Tabellen weitergegeben, auf die in der Sicht verwiesen wird. Weitere Informationen finden Sie unter „Sichtauflösung“. Diese Weitergabe gilt nicht für die Joinhinweise. Diese werden ausschließlich an ihrer ursprünglichen Position in der Abfrage angewendet. Joinhinweise werden vom Abfrageoptimierer beim Abgleich von Abfragen zu indizierten Sichten nicht berücksichtigt. Wenn ein Abfrageplan eine indizierte Sicht verwendet, die mit einem Teil einer Abfrage übereinstimmt, der einen Joinhinweis enthält, wird der Joinhinweis im Plan nicht verwendet.
In den Definitionen indizierter Sichten sind Hinweise nicht zulässig. In den Kompatibilitätsmodi 80 und höher ignoriert SQL Server die in den Definitionen indizierter Sichten enthaltenen Hinweise, wenn diese verwaltet werden oder wenn Abfragen ausgeführt werden, in denen indizierte Sichten verwendet werden. Obwohl die Verwendung von Hinweisen in den Definitionen indizierter Sichten im Kompatibilitätsmodus 80 nicht zu einem Syntaxfehler führt, werden sie ignoriert.
Weitere Informationen finden Sie unter Tabellenhinweise (Transact-SQL).
Auflösen verteilter partitionierter Sichten
Der SQL Server-Abfrageprozessor optimiert die Leistung von verteilten partitionierten Sichten. Der wichtigste Aspekt bei der Leistung von verteilten partitionierten Sichten ist das Minimieren der Datenmenge, die zwischen den Mitgliedsservern übertragen wird.
SQL Server erstellt intelligente, dynamische Pläne, in denen verteilte Abfragen effizient für den Zugriff auf Daten in Remotemitgliedstabellen verwendet werden:
- Zunächst verwendet der Abfrageprozessor OLE DB, um die Definitionen der CHECK-Einschränkungen aus jeder Mitgliedstabelle abzurufen. Dadurch kann der Abfrageprozessor die Verteilung der Schlüsselwerte auf die Mitgliedstabellen zuordnen.
- Der Abfrageprozessor vergleicht die Schlüsselbereiche, die in der
WHERE-Klausel einer Transact-SQL-Anweisung angegeben sind, mit der Zuordnung, die die Verteilung der Zeilen in den Mitgliedstabellen anzeigt. Anschließend erstellt der Abfrageprozessor einen Abfrageausführungsplan, der mithilfe von verteilten Abfragen nur die Remotezeilen abruft, die zum Ausführen der Transact-SQL-Anweisung erforderlich sind. Darüber hinaus wird der Ausführungsplan so erstellt, dass alle Zugriffe auf Remotemitgliedstabellen, entweder für Daten oder Metadaten, so lange verzögert werden, bis die Informationen benötigt werden.
Stellen Sie sich z. B. ein System vor, in dem eine Customers-Tabelle über Server1 (CustomerID von 1 bis 3299999), Server2 (CustomerID von 3300000 bis 6599999) und Server3 (CustomerID von 6600000 bis 9999999) partitioniert ist.
Stellen Sie sich den Ausführungsplan vor, der für diese auf Server1 ausgeführte Abfrage erstellt wird:
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID BETWEEN 3200000 AND 3400000;
Der Ausführungsplan für diese Abfrage extrahiert die Zeilen mit CustomerID -Schlüsselwerten von 3200000 bis 3299999 aus der lokalen Mitgliedstabelle und gibt eine verteilte Abfrage aus, um die Zeilen mit Schlüsselwerten von 3300000 bis 3400000 von Server2 abzurufen.
Der Abfrageprozessor von SQL Server kann zudem eine dynamische Logik in die Abfrageausführungspläne für Transact-SQL-Anweisungen integrieren, bei denen die Schlüsselwerte nicht bekannt sind, wenn der Plan erstellt werden muss. Sehen Sie sich z.B. diese gespeicherte Prozedur an:
CREATE PROCEDURE GetCustomer @CustomerIDParameter INT
AS
SELECT *
FROM CompanyData.dbo.Customers
WHERE CustomerID = @CustomerIDParameter;
SQL Server kann nicht vorhersagen, welcher Schlüsselwert jeweils bei der Ausführung der Prozedur durch den @CustomerIDParameter-Parameter zurückgegeben wird. Da der Schlüsselwert nicht vorhergesagt werden kann, kann der Abfrageprozessor auch nicht vorhersagen, auf welche Mitgliedstabelle zugegriffen werden muss. Wegen dieses Aspekts erstellt SQL Server einen Ausführungsplan mit Bedingungslogik (sogenannte dynamische Filter), um zu steuern, auf welche Mitgliedstabelle basierend auf den Eingabeparameterwerten zugegriffen wird. Angenommen die gespeicherte Prozedur GetCustomer wurde für Server1 ausgeführt, dann kann die Logik des Ausführungsplans wie folgt dargestellt werden:
IF @CustomerIDParameter BETWEEN 1 and 3299999
Retrieve row from local table CustomerData.dbo.Customer_33
ELSE IF @CustomerIDParameter BETWEEN 3300000 and 6599999
Retrieve row from linked table Server2.CustomerData.dbo.Customer_66
ELSE IF @CustomerIDParameter BETWEEN 6600000 and 9999999
Retrieve row from linked table Server3.CustomerData.dbo.Customer_99
SQL Server erstellt diese dynamischen Ausführungspläne manchmal sogar für nicht parametrisierte Abfragen. Der Abfrageoptimierer kann eine Abfrage parametrisieren, sodass der Ausführungsplan wieder verwendet werden kann. Falls der Abfrageoptimierer eine Abfrage parametrisiert, die auf eine partitionierte Sicht verweist, kann der Abfrageoptimierer nicht mehr davon ausgehen, dass die erforderlichen Zeilen aus einer bestimmten Basistabelle stammen. In diesem Fall muss der Optimierer dynamische Filter im Ausführungsplan verwenden.
Ausführung von gespeicherten Prozeduren und Triggern
SQL Server speichert nur die Quelle für gespeicherte Prozeduren und Trigger. Wenn eine gespeicherte Prozedur oder ein Trigger das erste Mal ausgeführt wird, wird die Quelle zu einem Ausführungsplan kompiliert. Wenn die gespeicherte Prozedur oder der Trigger erneut ausgeführt wird, bevor der Ausführungsplan aus dem Arbeitsspeicher entfernt wurde, erkennt die relationale Engine den vorhandenen Plan und verwendet ihn erneut. Wenn der Plan aus dem Arbeitsspeicher entfernt wurde, wird ein neuer Plan erstellt. Dieser Vorgang ist mit dem Verfahren vergleichbar, das SQL Server für alle Transact-SQL-Anweisungen anwendet. Der wesentliche Leistungsvorteil, den gespeicherte Prozeduren und Trigger in SQL Server im Vergleich zu Batches dynamischer Transact-SQL besitzen, besteht darin, dass ihre Transact-SQL-Anweisungen immer identisch sind. Aus diesem Grund können sie durch die relationale Engine auf einfache Weise vorhandenen Ausführungsplänen zugeordnet werden. Pläne für gespeicherte Prozeduren und Trigger können einfach erneut verwendet werden.
Der Ausführungsplan für gespeicherte Prozeduren und Trigger wird getrennt von dem Ausführungsplan für den Batch ausgeführt, der die gespeicherte Prozedur aufruft oder den Trigger auslöst. Dadurch können die Ausführungspläne für gespeicherte Prozeduren und Trigger mehrmals erneut verwendet werden.
Zwischenspeichern und Wiederverwenden von Ausführungsplänen
SQL Server verfügt über einen Arbeitsspeicherpool, der zum Speichern von Ausführungsplänen und von Datenpuffern verwendet wird. Der Prozentsatz des Pools, der entweder für Ausführungspläne oder für Datenpuffer zugeordnet wird, verändert sich dynamisch in Abhängigkeit vom Status des Systems. Der Teil des Arbeitsspeicherpools, der zum Speichern von Ausführungsplänen verwendet wird, wird Plancache genannt.
Der Plancache enthält zwei Speicher für alle kompilierten Pläne:
- Der Cache für Objektpläne (OBJCP) wird für Pläne verwendet, die sich auf persistente Objekte beziehen (gespeicherte Prozeduren, Funktionen und Auslöser).
- Der Cache für SQL-Pläne (SQLCP) wird für Pläne verwendet, die sich auf automatisch parametrisierte, dynamische oder vorbereitete Abfragen beziehen.
Die folgende Abfrage stellt Informationen zur Arbeitsspeicherauslastung für diese zwei Caches bereit:
SELECT * FROM sys.dm_os_memory_clerks
WHERE name LIKE '%plans%';
Hinweis
Der Plancache verfügt über zwei zusätzliche Speicher, die nicht zum Speichern von Plänen verwendet werden:
- Der Cache für Bound Trees (PHDR) wird für Datenstrukturen während der Plankompilierung für Ansichten, Einschränkungen und Standardwerte verwendet. Diese Strukturen werden „Bound Trees“ (Gebundene Strukturen) oder „Algebrizer Trees“ (Algebrizerstrukturen) genannt.
- Der Cache für erweiterte gespeicherte Prozedur (XPROC) wird für vordefinierte Systemprozeduren wie
sp_executeSqloderxp_cmdshellverwendet, die mithilfe einer DLL-Datei und nicht mit Transact-SQL-Anweisungen definiert werden. Die zwischengespeicherte Struktur enthält nur den Funktionsnamen und den Namen der DLL-Datei, in der die Prozedur implementiert wird.
SQL Server-Ausführungspläne weisen die folgenden Hauptkomponenten auf:
Kompilierter Plan (oder Abfrageplan)
Der vom Kompilierungsprozess erstellte Abfrageplan ist größtenteils eine wiedereintrittsfähige, schreibgeschützte Datenstruktur, die von einer beliebigen Anzahl an Benutzern verwendet werden kann. Diese speichert Informationen über:Physische Operatoren implementieren den durch logische Operatoren beschriebenen Vorgang.
Die Reihenfolge dieser Operatoren, die bestimmt, in welcher Reihenfolge auf Daten zugegriffen, gefiltert und aggregiert werden.
Die Anzahl der geschätzten Zeilen, die die Operatoren durchlaufen.
Hinweis
In neueren Versionen von Datenbank-Engine werden auch Informationen über die Statistikobjekte gespeichert, die für die Kardinalitätsschätzung verwendet wurden.
Welche Unterstützungsobjekte erstellt werden müssen, z. B. Arbeitstabellen oder Arbeitsdateien in
tempdb. Im Abfrageplan werden keine Informationen über den Benutzerkontext oder die Laufzeit gespeichert. Im Arbeitsspeicher befinden sich immer nur eine oder zwei Kopien des Abfrageplans: eine Kopie für alle seriellen Ausführungen und eine weitere für alle parallelen Ausführungen. Die parallele Kopie deckt alle parallelen Ausführungen ab, und zwar unabhängig von ihrem Grad an Parallelität.
Ausführungskontext
Jeder Benutzer, der die Abfrage zurzeit ausführt, verfügt über eine Datenstruktur mit den Daten, die für diese Ausführung spezifisch sind, z. B. Parameterwerte. Diese Datenstruktur wird als Ausführungskontext bezeichnet. Die Datenstrukturen des Ausführungskontexts werden wiederverwendet, aber nicht ihr Inhalt. Wenn ein anderer Benutzer dieselbe Abfrage ausführt, werden die Datenstrukturen mit dem Kontext für den neuen Benutzer nochmal initialisiert.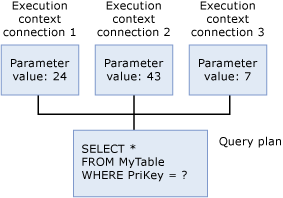
Wenn eine Transact-SQL-Anweisung in SQL Server ausgeführt wird, durchsucht die Datenbank-Engine zunächst den Plancache, um zu überprüfen, ob ein vorhandener Ausführungsplan für die gleiche Transact-SQL-Anweisung vorhanden ist. Die Transact-SQL-Anweisung wird als vorhanden qualifiziert, wenn sie exakt einer zuvor ausgeführten Transact-SQL-Anweisung mit einem zwischengespeicherten Plan entspricht. SQL Server verwendet sämtliche vorhandenen Pläne wieder, die hierbei gefunden werden, und spart somit den Aufwand für das erneute Kompilieren der Transact-SQL-Anweisung. Wenn kein Ausführungsplan vorhanden ist, generiert SQL Server einen neuen Ausführungsplan für die Abfrage.
Hinweis
Die Ausführungspläne für einige Transact-SQL-Anweisungen werden nicht im Plancache beibehalten. Das gilt beispielsweise für Anweisungen für Massenvorgänge, die in Rowstore ausgeführt werden, oder für Anweisungen mit Zeichenfolgenliteralen mit einer Größe von mehr als 8 KB. Diese Pläne sind nur vorhanden, während die Abfrage ausgeführt wird.
SQL Server verwendet einen effizienten Algorithmus, um vorhandene Ausführungspläne für bestimmte Transact-SQL-Anweisungen zu suchen. In den meisten Systemen können durch die Wiederverwendung vorhandener Pläne anstelle des erneuten Kompilierens jeder Transact-SQL-Anweisung mehr Ressourcen eingespart werden als für den Scan nach vorhandenen Plänen erforderlich sind.
Die Algorithmen, die Transact-SQL-Anweisungen mit vorhandenen, nicht verwendeten Ausführungsplänen im Plancache vergleichen, erfordern, dass alle Objektverweise vollqualifiziert sind. Angenommen, Person ist das Standardschema für den Benutzer, der die unten angegebenen SELECT-Anweisungen ausführt. Da es in diesem Beispiel nicht erforderlich ist, dass die Tabelle Person zum Ausführen vollqualifiziert ist, bedeutet dies, dass die zweite Anweisung nicht mit einem vorhandenen Plan verglichen wird, aber die dritte Anweisung:
USE AdventureWorks2022;
GO
SELECT * FROM Person;
GO
SELECT * FROM Person.Person;
GO
SELECT * FROM Person.Person;
GO
Wenn eine der folgenden SET-Optionen für eine jeweilige Ausführung geändert wird, wirkt sich das auf die Wiederverwendungsfähigkeit der Pläne aus, da Datenbank-Engine konstantes Folding durchführt und diese Optionen sich auf die Ergebnisse solcher Ausdrücke auswirken:
ANSI_NULL_DFLT_OFF
FORCEPLAN
ARITHABORT
DATEFIRST
ANSI_PADDING
NUMERIC_ROUNDABORT
ANSI_NULL_DFLT_ON
SPRACHE
CONCAT_NULL_YIELDS_NULL
DATEFORMAT
ANSI_WARNINGS
QUOTED_IDENTIFIER
ANSI_NULLS
NO_BROWSETABLE
ANSI_DEFAULTS
Zwischenspeichern mehrerer Pläne für dieselbe Abfrage
Abfragen und Ausführungspläne sind in Datenbank-Engine eindeutig identifizierbar, ähnlich wie bei einem Fingerabdruck:
- Der Abfrageplanhash ist ein binärer Hashwert, der im Ausführungsplan für eine jeweilige Abfrage berechnet und dann zur eindeutigen Identifizierung ähnlicher Ausführungspläne verwendet wird.
- Der Abfragehash ist ein binärer Hashwert, der für den Transact-SQL-Text einer Abfrage berechnet und zur eindeutigen Identifizierung von Abfragen verwendet wird.
Ein kompilierter Plan kann mithilfe eines Planhandles aus dem Plancache abgerufen werden. Dies ist ein vorübergehender Bezeichner, der nur konstant bleibt, während der Plan sich im Cache befindet. Der Planhandle ist ein Hashwert, der vom kompilierten Plan des gesamten Batches abgeleitet wurde. Der Planhandle für einen kompilierten Plan bleibt gleich, auch wenn mindestens eine Anweisung im Batch neu kompiliert wird.
Hinweis
Wenn ein Plan für mehrere Anweisungen kompiliert wurde, können Sie den Plan für einzelne Anweisungen im Batch mithilfe des Planhandles und der Anweisungsoffsets abrufen.
Die dynamische Verwaltungssicht sys.dm_exec_requests enthält die Spalten statement_start_offset und statement_end_offset für alle Datensätze, die auf die aktuell ausgeführte Anweisung eines Batches oder persistenten Objekts verweisen, das derzeit ausgeführt wird. Weitere Informationen finden Sie unter sys.dm_exec_requests (Transact-SQL).
Die dynamische Verwaltungssicht sys.dm_exec_query_stats enthält diese Spalten für alle Datensätze, die auf die Position einer Anweisung im Batch oder persistenten Objekt verweisen. Weitere Informationen finden Sie unter sys.dm_exec_query_stats (Transact-SQL).
Der tatsächliche Transact-SQL-Text eines Batchs wird in einem vom Plancache getrennten Speicherbereich gespeichert, der als SQL Manager-Cache (SQLMGR) bezeichnet wird. Der Transact-SQL-Text für einen kompilierten Plan kann mithilfe eines SQL-Handles aus dem SQL Manager-Cache abgerufen werden. Dieses Handle ist ein vorübergehender Bezeichner, der nur konstant bleibt, solange sich mindestens ein Plan im Plancache befindet, der auf ihn verweist. Der SQL-Handle ist ein Hashwert, der vom gesamten Batchtext abgeleitet wird und ist für alle Batches immer eindeutig.
Hinweis
Wie bei einem kompilierten Plan wird der Transact-SQL-Text pro Batch mitsamt den Kommentaren gespeichert. Der SQL-Handle enthält den MD5-Hash des gesamten Batchtexts und ist für alle Batches immer eindeutig.
Die folgende Abfrage bietet Informationen über die Arbeitsspeicherauslastung für den SQL Manager-Cache:
SELECT * FROM sys.dm_os_memory_objects
WHERE type = 'MEMOBJ_SQLMGR';
Zwischen einem SQL-Handle und Planhandles besteht eine 1:n-Beziehung. Eine solche Bedingung liegt vor, wenn sich der Cacheschlüssel für die kompilierten Pläne unterscheidet. Dies kann aufgrund einer Änderung an den SET-Optionen zwischen zwei Ausführungen desselben Batches auftreten.
Sehen Sie sich die folgende gespeicherte Prozedur an:
USE WideWorldImporters;
GO
CREATE PROCEDURE usp_SalesByCustomer @CID int
AS
SELECT * FROM Sales.Customers
WHERE CustomerID = @CID
GO
SET ANSI_DEFAULTS ON
GO
EXEC usp_SalesByCustomer 10
GO
Überprüfen Sie, was Sie mithilfe der folgenden Abfrage im Plancache ermitteln können:
SELECT cp.memory_object_address, cp.objtype, refcounts, usecounts,
qs.query_plan_hash, qs.query_hash,
qs.plan_handle, qs.sql_handle
FROM sys.dm_exec_cached_plans AS cp
CROSS APPLY sys.dm_exec_sql_text (cp.plan_handle)
CROSS APPLY sys.dm_exec_query_plan (cp.plan_handle)
INNER JOIN sys.dm_exec_query_stats AS qs ON qs.plan_handle = cp.plan_handle
WHERE text LIKE '%usp_SalesByCustomer%'
GO
Hier sehen Sie das Ergebnis.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Führen Sie jetzt die gespeicherte Prozedur mit einem anderen Parameter aus, aber nehmen Sie keine anderen Änderungen am Ausführungskontext vor:
EXEC usp_SalesByCustomer 8
GO
Überprüfen Sie nochmal, was Sie im Plancache ermitteln können. Hier sehen Sie das Ergebnis.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Beachten Sie, dass der Wert von usecounts auf 2 erhöht wurde. Das bedeutet, dass der selbe zwischengespeicherte Plan ohne Änderungen wiederverwendet wurde, da die Datenstrukturen des Ausführungskontexts nochmal verwendet wurden. Ändern Sie nun die SET ANSI_DEFAULTS-Option, und führen Sie die gespeicherte Prozedur mit dem gleichen Parameter aus.
SET ANSI_DEFAULTS OFF
GO
EXEC usp_SalesByCustomer 8
GO
Überprüfen Sie nochmal, was Sie im Plancache ermitteln können. Hier sehen Sie das Ergebnis.
memory_object_address objtype refcounts usecounts query_plan_hash query_hash
--------------------- ------- --------- --------- ------------------ ------------------
0x000001CD01DEC060 Proc 2 1 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
0x000001CC6C534060 Proc 2 2 0x3B4303441A1D7E6D 0xA05D5197DA1EAC2D
plan_handle
------------------------------------------------------------------------------------------
0x0500130095555D02B031F111CD01000001000000000000000000000000000000000000000000000000000000
0x0500130095555D02D022F111CD01000001000000000000000000000000000000000000000000000000000000
sql_handle
------------------------------------------------------------------------------------------
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
0x0300130095555D02C864C10061AB000001000000000000000000000000000000000000000000000000000000
Beachten Sie, dass nun zwei Einträge in der dynamische Verwaltungssicht von sys.dm_exec_cached_plans enthalten sind:
- Die
usecounts-Spalte zeigt den Wert1im ersten Datensatz, d. h. der Plan wurde einmal mitSET ANSI_DEFAULTS OFFausgeführt. - Die
usecounts-Spalte zeigt den Wert2im zweiten Datensatz, d. h. der Plan wurde mitSET ANSI_DEFAULTS ONausgeführt, weil er zweimal ausgeführt wurde. - Die unterschiedlichen
memory_object_address-Werte beziehen sich auf verschiedene Ausführungsplaneinträge im Plancache. Dersql_handle-Wert gilt jedoch für beide Einträge, weil sie sich auf denselben Batch beziehen.- Die Ausführung, bei der OFF für
ANSI_DEFAULTSfestgelegt ist, verfügt über einen neuenplan_handleund kann in Aufrufen wiederverwendet werden, die über die gleichen SET-Optionen verfügen. Der neue Planhandle ist erforderlich, weil der Ausführungskontext aufgrund geänderter SET-Optionen neu initialisiert wurde. Dadurch wird jedoch keine Neukompilierung ausgelöst: beide Einträge beziehen sich auf denselben Plan und dieselbe Abfrage, was durch die identischenquery_plan_hash- undquery_hash-Werte bestätigt wird.
- Die Ausführung, bei der OFF für
Das bedeutet schließlich, das zwei Planeinträge für denselben Batch im Cache enthalten sind. Dies unterstreicht die Wichtigkeit davon, dass sichergestellt werden muss, dass die SET-Optionen identisch sind, die sich auf den Plancache auswirken, wenn die gleichen Abfragen wiederholt ausgeführt werden, um die Wiederverwendung des Plans zu optimieren und die Größe des Plancaches auf das erforderliche Mindestmaß zu beschränken.
Tipp
Ein häufig auftretendes Problem besteht darin, dass verschiedene Clients möglicherweise unterschiedliche Standardwerte für die SET-Optionen aufweisen. Bei der Herstellung einer Verbindung über SQL Server Management Studio wird QUOTED_IDENTIFIER beispielsweise auf ON festgelegt, während SQLCMD QUOTED_IDENTIFIER auf OFF festgelegt. Wenn die gleichen Abfragen auf diesen zwei Clients ausgeführt werden, führt dies wie im Beispiel oben zu mehreren Plänen.
Entfernen von Ausführungsplänen aus dem Plancache
Ausführungspläne verbleiben im Plancache, solange ausreichend Speicherplatz für deren Speicherung zur Verfügung steht. Wenn nicht ausreichend Speicherplatz zur Verfügung steht, ermittelt die SQL Server Datenbank-Engine kostenbasiert, welche Ausführungspläne aus dem Plancache entfernt werden. Für die kostenbasierte Entscheidung erhöht und senkt die SQL Server Datenbank-Engine die aktuelle Kostenvariable für sämtliche Ausführungspläne anhand der im Folgenden aufgeführten Faktoren.
Wenn ein Benutzerprozess einen Ausführungsplan in den Cache einfügt, werden die aktuellen Kosten auf die Kosten der ursprünglichen Abfragekompilierung festgelegt. Für Ad-hoc-Ausführungspläne legt der Benutzerprozess die aktuellen Kosten auf 0 (null) fest. Jedes Mal, wenn danach ein Benutzerprozess auf einen Ausführungsplan verweist, werden die aktuellen Kosten auf die ursprünglich kompilierten Kosten zurückgesetzt. Für Ad-hoc-Ausführungspläne erhöht der Benutzerprozess die aktuellen Kosten. Für alle Pläne entspricht der maximale Wert für die aktuellen Kosten den Kosten der ursprünglichen Kompilierung.
Wenn nicht ausreichend Speicherplatz zur Verfügung steht, werden von der SQL Server Datenbank-Engine Ausführungspläne aus dem Plancache gelöscht. Um zu ermitteln, welche Pläne entfernt werden sollen, überprüft die SQL Server Datenbank-Engine wiederholt den Status sämtlicher Ausführungspläne. Die Pläne, deren aktuelle Kosten 0 (null) betragen, werden entfernt. Ein Ausführungsplan, dessen aktuelle Kosten 0 (null) betragen, wird bei unzureichendem Speicher nicht automatisch entfernt. Der Ausführungsplan wird nur bei einer Überprüfung durch die SQL Server Datenbank-Engine entfernt, wenn die aktuellen Kosten 0 (null) betragen. Wird ein Ausführungsplan derzeit nicht von einer Abfrage verwendet, werden bei der Überprüfung des Plans die aktuellen Kosten von der SQL Server Datenbank-Engine durch Reduzieren dieser Kosten gegen 0 (null) gesenkt.
Die SQL Server Datenbank-Engine überprüft die Ausführungspläne wiederholt, bis genügend Ausführungspläne entfernt wurden, um die Speicheranforderungen zu erfüllen. Wenn nicht ausreichend Speicher zur Verfügung steht, können die Kosten eines Ausführungsplans mehrmals erhöht und gesenkt werden. Sobald wieder ausreichend Speicher zur Verfügung steht, werden die aktuellen Kosten nicht verwendeter Ausführungspläne von SQL Server Datenbank-Engine nicht mehr gesenkt. Alle Ausführungspläne verbleiben im Plancache, auch wenn die Kosten 0 (null) betragen.
Wenn nicht ausreichend Speicher zur Verfügung steht, verwendet SQL Server Datenbank-Engine den Ressourcenmonitor und Benutzerarbeitsthreads, um Speicherplatz im Prozedurcache freizugeben. Vom Ressourcenmonitor und von den Benutzerarbeitsthreads können gleichzeitig ausgeführte Pläne überprüft werden, um die Kosten für die nicht verwendeten Ausführungspläne zu senken. Wenn nicht ausreichend globaler Speicher zur Verfügung steht, werden durch den Ressourcenmonitor Ausführungspläne aus dem Plancache gelöscht. Dadurch wird die Einhaltung von Richtlinien für den Systemspeicher, Prozessspeicher, Ressourcenpoolspeicher und die maximale Größe aller Caches erzwungen.
Die maximale Größe für alle Caches ist eine Funktion der Pufferpoolgröße und kann den maximalen Serverarbeitsspeicher nicht überschreiten. Weitere Informationen zum Konfigurieren des maximalen Serverarbeitsspeichers finden Sie in den Details zur Einstellung max server memory von sp_configure.
Wenn nicht ausreichend Einzelcachespeicher zur Verfügung steht, werden durch die Benutzerarbeitsthreads Ausführungspläne aus dem Plancache gelöscht. Dadurch wird die Einhaltung der Richtlinien für die maximale Einzelcachegröße und die maximale Anzahl von Einzelcacheeinträgen erzwungen.
In den folgenden Beispielen wird erläutert, welche Ausführungspläne aus dem Plancache entfernt werden:
- Auf einen Ausführungsplan wird regelmäßig verwiesen, sodass seine Kosten nie den Wert 0 (null) erreichen. Der Plan verbleibt im Plancache und wird nur dann entfernt, wenn nicht genügend Arbeitsspeicher vorhanden ist und die aktuellen Kosten 0 (null) sind.
- Ein Ad-hoc-Ausführungsplan wird eingefügt. Auf diesen wird erst wieder verwiesen, wenn nicht ausreichend Speicherplatz zur Verfügung steht. Ad-hoc-Pläne werden mit einem Wert für die aktuellen Kosten von 0 (null) initialisiert. Daher wird der Plan aus dem Plancache entfernt, wenn der Ausführungsplan vom SQL Server Datenbank-Engine überprüft wird und die aktuellen Kosten 0 (null) betragen. Der Ad-hoc-Ausführungsplan verbleibt im Plancache mit aktuellen Kosten vom Wert 0 (null), wenn genügend Arbeitsspeicher vorhanden ist.
Um einen einzelnen Plan oder alle Pläne manuell aus dem Cache zu entfernen, verwenden Sie DBCC FREEPROCCACHE. DBCC FREESYSTEMCACHE kann auch verwendet werden, um jeden Cache, einschließlich des Plancaches, zu leeren. Ab SQL Server 2016 (13.x) ist ALTER DATABASE SCOPED CONFIGURATION CLEAR PROCEDURE_CACHE verfügbar, um den Prozedur-/Plancache für die Datenbank im Bereich zu löschen.
Eine Änderung in einigen Konfigurationseinstellungen über sp_configure und reconfigure führt ebenfalls dazu, dass Pläne aus dem Plancache entfernt werden. Die Liste dieser Konfigurationseinstellungen finden Sie im Abschnitt „Hinweise“ des DBCC FREEPROCCACHE-Artikels. Durch eine Konfigurationsänderung wie diese wird die folgende Infomeldung in das Fehlerprotokoll aufgenommen:
SQL Server has encountered %d occurrence(s) of cachestore flush for the '%s' cachestore (part of plan cache) due to some database maintenance or reconfigure operations.
Erneutes Kompilieren von Ausführungsplänen
Bestimmte Änderungen in einer Datenbank können dazu führen, dass ein Ausführungsplan basierend auf dem neuen Status der Datenbank ineffizient oder ungültig ist. SQL Server erkennt die Änderungen, die einen Ausführungsplan ungültig machen, und kennzeichnet den Plan als ungültig. Für die nächste Verbindung, die die Abfrage ausführt, muss dann ein neuer Plan kompiliert werden. Folgende Bedingungen können dazu führen, dass ein Plan ungültig wird:
- Änderungen, die an einer Tabelle oder einer Sicht vorgenommen werden, auf die in der Abfrage verwiesen wird (
ALTER TABLEundALTER VIEW). - Änderungen, die an einer einzigen Prozedur vorgenommen werden, durch die alle Pläne für die Prozedur aus dem Cache gelöscht werden (
ALTER PROCEDURE). - Änderungen an Indizes, die vom Ausführungsplan verwendet werden.
- Updates der vom Ausführungsplan verwendeten Statistiken, die entweder explizit durch eine Anweisung, wie beispielsweise
UPDATE STATISTICS, oder automatisch generiert werden. - Löschen eines Indexes, der von dem Ausführungsplan verwendet wird.
- Ein expliziter Aufruf von
sp_recompile. - Eine große Anzahl von Änderungen an Schlüsseln (generiert durch
INSERT- oderDELETE-Anweisungen von anderen Benutzern, die eine Tabelle ändern, auf die in der Abfrage verwiesen wird). - Bei Tabellen mit Triggern eine deutliche Erhöhung der Zeilenanzahl in der eingefügten oder gelöschten Tabelle.
- Ausführen einer gespeicherten Prozedur mithilfe der Option
WITH RECOMPILE.
Die meisten Neukompilierungen sind erforderlich, um die Richtigkeit der Anweisungen sicherzustellen oder um möglicherweise schnellere Abfrageausführungspläne zu erhalten.
Jedes Mal, wenn in früheren SQL Server-Versionen als 2005 eine in einem Batch vorhandene Anweisung eine Neukompilierung ausgelöst hat, wurde der gesamte durch eine gespeicherte Prozedur, einen Trigger, einen Ad-hoc-Batch oder eine vorbereitete Anweisung übermittelte Batch noch mal kompiliert. Ab SQL Server 2005 (9.x) wird nur die Anweisung innerhalb des Batches, der die Neukompilierung auslöst, noch mal kompiliert. Zudem gibt es in SQL Server 2005 (9.x) und höheren Versionen aufgrund der erweiterten Features zusätzliche Neukompilierungstypen.
Die Neukompilierung auf Anweisungsebene wirkt sich positiv auf die Leistung aus, da in den meisten Fällen wenige Anweisungen Neukompilierungen und die damit verbundenen Sanktionen in Bezug auf die CPU-Zeit und die Sperren verursachen. Diese Sanktionen werden daher für die anderen Anweisungen innerhalb des Batchs vermieden, für die keine Neukompilierung erforderlich ist.
Das sql_statement_recompile erweiterte Ereignis (XEvent) meldet Neukompilierungen auf Anweisungsebene. Dieses XEvent tritt auf, wenn eine Neukompilierung auf Anweisungsebene für jede Art von Batch erforderlich ist. Dazu gehören gespeicherte Prozeduren, Trigger, Ad-hoc-Batches und Abfragen. Batches können möglicherweise über mehrere Schnittstellen, einschließlich sp_executesql, dynamische SQL-Anweisungen, Prepare-Methoden oder Execute-Methoden gesendet werden.
Die recompile_cause Spalte von sql_statement_recompile XEvent enthält einen ganzzahligen Code, der den Grund für die Neukompilierung angibt. Die folgende Tabelle enthält die möglichen Gründe:
Schema geändert
Statistiken geändert
Verzögerte Kompilierung
SET-Option geändert
Temporäre Tabelle geändert
Remote-Rowset geändert
FOR BROWSE-Berechtigung geändert
Abfragebenachrichtigungsumgebung geändert
Partitionierte Sicht geändert
Cursoroptionen geändert
OPTION (RECOMPILE) angefordert.
Parametrisierter Plan geleert
Plan geändert, der die Datenbankversion betrifft
Erzwingende Richtlinie des Abfragespeicherplans geändert
Erzwingende Richtlinie des Abfragespeicherplans fehlgeschlagen
Plan des Abfragespeichers fehlt
Hinweis
In SQL Server-Versionen, in denen XEvents nicht verfügbar sind, kann das SQL Server Profiler SP:Recompile-Ablaufverfolgungsereignis für den gleichen Zweck von Neukompilierungen auf Anweisungsebene verwendet werden.
Das Ablaufverfolgungsereignis SQL:StmtRecompile meldet ebenfalls Neukompilierungen, und es kann auch zum Nachverfolgen und Debuggen von Neukompilierungen verwendet werden.
Während SP:Recompile nur für gespeicherte Prozeduren und Trigger generiert wird, wird SQL:StmtRecompile für gespeicherte Prozeduren, Trigger, Ad-hoc-Batches, Batches, die mithilfe von sp_executesqlausgeführt werden, vorbereitete Abfragen sowie für dynamisches SQL generiert.
Die EventSubClass-Spalte von SP:Recompile und SQL:StmtRecompile enthält einen ganzzahligen Code, der den Grund für die Neukompilierung angibt. Die Codes sind hier beschrieben.
Hinweis
Wenn die Datenbankoption AUTO_UPDATE_STATISTICS auf ON festgelegt wird, werden Abfragen neu kompiliert, wenn sie Tabellen oder indizierte Sichten betreffen, deren Statistiken aktualisiert wurden oder deren Kardinalitäten sich seit der letzten Ausführung signifikant geändert haben.
Dieses Verhalten gilt für standardmäßige benutzerdefinierte Tabellen, temporäre Tabellen und die durch DML-Trigger erstellten eingefügten und gelöschten Tabellen. Wenn sich sehr viele Neukompilierungen auf die Abfrageleistung auswirken, können Sie diese Einstellung in OFFändern. Wenn die AUTO_UPDATE_STATISTICS-Datenbankoption auf OFF festgelegt wird, werden auf der Grundlage von Statistiken oder wegen Änderungen der Kardinalität keine Neukompilierungen durchgeführt, mit Ausnahme der durch DML INSTEAD OF-Trigger erstellten eingefügten und gelöschten Tabellen. Da diese Tabellen in tempdb erstellt wurden, hängt die Neukompilierung von Abfragen, die auf diese Tabellen zugreifen, von der AUTO_UPDATE_STATISTICS-Einstellung in tempdb ab.
Beachten Sie, dass, auch wenn diese Einstellung auf OFF festgelegt ist, Abfragen in früheren SQL Server-Versionen als 2005 weiterhin auf der Grundlage der Kardinalitätsänderungen in den durch DML-Trigger eingefügten und gelöschten Tabellen noch mal kompiliert werden.
Parameter und Wiederverwendung von Ausführungsplänen
Durch die Verwendung von Parametern, einschließlich der Parametermarkierungen in ADO-, OLE DB- und ODBC-Anwendungen, kann die Wiederverwendbarkeit von Ausführungsplänen erhöht werden.
Warnung
Es ist sicherer, Parameter oder Parametermarkierungen zu verwenden, die vom Endbenutzer eingegebene Werte enthalten, als die Werte in einer Zeichenfolge zu verketten, die dann mithilfe einer API-Datenzugriffsmethode, einer EXECUTE -Anweisung oder einer gespeicherten sp_executesql -Prozedur ausgeführt werden.
Die zwei folgenden SELECT -Anweisungen unterscheiden sich lediglich im Hinblick auf die Werte, die in der WHERE -Klausel verglichen werden:
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT *
FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Die Ausführungspläne für diese Abfragen unterscheiden sich lediglich hinsichtlich des Werts, der für den Vergleich mit der ProductSubcategoryID -Spalte gespeichert wird. Das Ziel von SQL Server besteht zwar darin, stets zu erkennen, ob Anweisungen im Prinzip den gleichen Plan generieren, und diesen Plan dann wiederzuverwenden, in komplexen Transact-SQL-Anweisungen ist das jedoch nicht immer möglich.
Wenn Sie Konstanten mithilfe von Parametern von den Transact-SQL-Anweisungen trennen, unterstützen Sie die relationale Engine dabei, doppelte Pläne zu erkennen. Es gibt folgende Möglichkeiten, um Parameter zu verwenden:
Verwenden Sie in Transact-SQL
sp_executesql:DECLARE @MyIntParm INT SET @MyIntParm = 1 EXEC sp_executesql N'SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = @Parm', N'@Parm INT', @MyIntParmDiese Methode wird für Transact-SQL-Skripts, gespeicherte Prozeduren oder Trigger empfohlen, die SQL-Anweisungen dynamisch generieren.
ADO, OLE DB und ODBC verwenden Parametermarkierungen. Parametermarkierungen sind Fragezeichen (?), die eine Konstante in einer SQL-Anweisung ersetzen und an eine Programmvariable gebunden sind. Beispielsweise können Sie in einer ODBC-Anwendung folgende Aktionen ausführen:
Dient
SQLBindParameterzum Binden einer ganzzahligen Variablen an die erste Parametermarkierung in einer SQL-Anweisung.Speichern Sie den ganzzahligen Wert in der Variablen.
Führen Sie die Anweisung aus, und geben Sie dabei die Parametermarkierung (?) an:
SQLExecDirect(hstmt, "SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductSubcategoryID = ?", SQL_NTS);
Der SQL Server Native Client-OLE DB-Anbieter und der SQL Server Native Client-ODBC-Treiber, die beide mit SQL Server zur Verfügung gestellt werden, verwenden
sp_executesql, um Anweisungen an SQL Server zu senden, wenn Parametermarkierungen in Anwendungen verwendet werden.Zum Entwerfen von gespeicherten Prozeduren mit vorprogrammierter Parameterverwendung
Wenn Sie beim Entwerfen ihrer Anwendungen nicht explizit Parameter in diese einbauen, können Sie auch den SQL Server-Abfrageoptimierer heranziehen, um bestimmte Abfragen mithilfe des Standardverhaltens der einfachen Parametrisierung automatisch zu parametrisieren. Alternativ können Sie erzwingen, dass der Abfrageoptimierer die Parametrisierung aller Abfragen in der Datenbank in Betracht zieht, indem Sie die PARAMETERIZATION-Option der ALTER DATABASE-Anweisung auf FORCED festlegen.
Auch wenn die erzwungene Parametrisierung aktiviert ist, kann die einfache Parametrisierung erfolgen. Die folgende Abfrage kann beispielsweise gemäß den Regeln der erzwungenen Parametrisierung nicht parametrisiert werden:
SELECT * FROM Person.Address
WHERE AddressID = 1 + 2;
Sie kann jedoch nach den Regeln der einfachen Parametrisierung parametrisiert werden. Wenn die erzwungene Parametrisierung einen Fehler erzeugt, wird anschließend die einfache Parametrisierung versucht.
Einfache Parametrisierung
In SQL Server wird durch die Verwendung von Parametern oder Parametermarkierungen in Transact-SQL-Anweisungen die Fähigkeit der relationalen Engine verbessert, neue Transact-SQL-Anweisungen vorhandenen, zuvor kompilierten Ausführungsplänen zuzuordnen.
Warnung
Es ist sicherer, Parameter oder Parametermarkierungen zu verwenden, die vom Endbenutzer eingegebene Werte enthalten, als die Werte in einer Zeichenfolge zu verketten, die dann mithilfe einer API-Datenzugriffsmethode, einer EXECUTE -Anweisung oder einer gespeicherten sp_executesql -Prozedur ausgeführt werden.
Wenn eine Transact-SQL-Anweisung ohne Parameter ausgeführt wird, parametrisiert SQL Server die Anweisung intern, um die Wahrscheinlichkeit zu erhöhen, dass ein übereinstimmender Ausführungsplan gefunden wird. Dieser Prozess wird als einfache Parametrisierung bezeichnet. In SQL Server-Versionen vor 2005 wurde dieser Prozess als automatische Parametrisierung bezeichnet.
Angenommen, die folgende Anweisung wird ausgeführt:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
Der Wert 1 am Ende der Anweisung kann als Parameter angegeben werden. Die relationale Engine erstellt den Ausführungsplan für diesen Batch so, als ob anstelle des Werts 1 ein Parameter angegeben worden wäre. Aufgrund dieser einfachen Parametrisierung erkennt SQL Server, dass die folgenden beiden Anweisungen im Prinzip den gleichen Ausführungsplan generieren, und verwendet den ersten Plan auch für die zweite Anweisung:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 1;
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductSubcategoryID = 4;
Bei der Verarbeitung komplexer Transact-SQL-Anweisungen ist es für die relationale Engine ggf. schwer, parametrisierbare Ausdrücke zu bestimmen. Um die Wahrscheinlichkeit zu erhöhen, dass die relationale Engine Übereinstimmungen zwischen komplexen Transact-SQL-Anweisungen und vorhandenen, nicht verwendeten Ausführungsplänen erkennt, können Sie die Parameter explizit mithilfe von sp_executesql oder mithilfe von Parametermarkierungen angeben.
Hinweis
Wenn die arithmetischen Operatoren +, -, *, /, oder % zur impliziten oder expliziten Konvertierung von Konstantenwerten der Datentypen „int“, „smallint“, „tinyint“ oder „bigint“ in die Datentypen „float“, „real“, „decimal“ oder „numeric“ verwendet werden, wendet SQL Server spezielle Regeln an, um den Typ und die Genauigkeit der Ausdrucksergebnisse zu berechnen. Allerdings unterscheiden sich diese Regeln in Abhängigkeit davon, ob die Abfrage parametrisiert ist oder nicht. Daher können gleiche Ausdrücke in Abfragen in einigen Fällen zu unterschiedlichen Ergebnissen führen.
Beim Standardverhalten der einfachen Parametrisierung parametrisiert SQL Server eine relativ kleine Klasse von Abfragen. Allerdings können Sie angeben, dass mit bestimmten Einschränkungen alle Abfragen in einer Datenbank parametrisiert werden, indem Sie die PARAMETERIZATION -Option des Befehls ALTER DATABASE auf FORCEDfestlegen. Damit kann die Leistung von Datenbanken verbessert werden, bei denen sehr viele gleichzeitige Abfragen auftreten, indem die Häufigkeit der Abfragekompilierungen verringert wird.
Alternativ können Sie angeben, dass eine einzelne Abfrage und alle anderen Abfragen, die in ihrer Syntax gleichwertig sind, und lediglich in ihren Parameterwerten abweichen, parametrisiert werden.
Tipp
Wenn Sie eine ORM-Lösung (Object-Relational Mapping, objektrelationale Zuordnung) wie Entity Framework (EF) verwenden, werden Anwendungsabfragen wie manuelle LINQ-Abfragestrukturen oder bestimmte unformatierte SQL-Abfragen unter Umständen nicht parametrisiert. Dies wirkt sich auf die Wiederverwendung von Plänen und die Möglichkeit zum Nachverfolgen von Abfragen im Abfragespeicher aus. Weitere Informationen finden Sie unter Zwischenspeichern und Parametrisieren von Abfragen und Unformatierte SQL-Abfragen.
Erzwungene Parametrisierung
Sie können das standardmäßige Parametrisierungsverhalten von SQL Server, die einfache Parametrisierung, überschreiben, indem Sie angeben, dass alle SELECT-, INSERT-, UPDATE- und DELETE -Anweisungen in einer Datenbank mit bestimmten Einschränkungen parametrisiert werden sollen. Die erzwungene Parametrisierung wird aktiviert, indem die PARAMETERIZATION -Option in der FORCED -Anweisung auf ALTER DATABASE festgelegt wird. Die erzwungene Parametrisierung kann die Leistungsfähigkeit bestimmter Datenbanken erhöhen, indem die Frequenz der Kompilierungen und Neukompilierungen von Anweisungen verringert wird. Dabei handelt es sich im Allgemeinen um Datenbanken, die einer großen Anzahl gleichzeitiger Abfragen ausgesetzt sind, wie z. B. Point-of-Sale-Anwendungen.
Wenn die PARAMETERIZATION -Option auf FORCEDfestgelegt ist, werden während der Kompilierung der Abfrage alle Literalwerte in SELECT-, INSERT-, UPDATE- oder DELETE -Anweisungen, ungeachtet der Form, in der sie übergeben wurden, in Parameter konvertiert. Ausnahmen bilden Literalwerte in folgenden Abfragekonstruktionen:
INSERT...EXECUTE-Anweisungen.- Anweisungen innerhalb des Hauptteils von gespeicherten Prozeduren, Triggern oder benutzerdefinierten Funktionen. In SQL Server werden bereits Abfragepläne für diese Routinen wiederverwendet.
- Vorbereitete Anweisungen, die bereits in der clientbasierten Anwendung parametrisiert wurden.
- Anweisungen, die XQuery-Methodenaufrufe enthalten, wo die Methode in einem Kontext angezeigt wird, in dem ihre Argumente normalerweise parametrisiert werden, wie beispielsweise die
WHERE-Klausel. Wenn die Methode in einem Kontext angezeigt wird, in dem ihre Argumente normalerweise nicht parametrisiert werden, wird der Rest der Anweisung parametrisiert. - Anweisungen in einem Transact-SQL-Cursor. (
SELECT-Anweisungen innerhalb von API-Cursorn werden parametrisiert.) - Als veraltet markierte Abfragekonstrukte.
- Eine Anweisung, die im Kontext von
ANSI_PADDINGoderANSI_NULLSmit der EinstellungOFFausgeführt wird. - Anweisungen mit mehr als 2.097 parametrisierbaren Literalwerten.
- Anweisungen, die auf Variablen verweisen, wie beispielsweise
WHERE T.col2 >= @bb. - Anweisungen mit
RECOMPILE-Abfragehinweis. - Anweisungen mit
COMPUTE-Klauseln. - Anweisungen mit
WHERE CURRENT OF-Klauseln.
Außerdem werden die folgenden Abfrageklauseln nicht parametrisiert. In diesen Fällen sind nur die Klauseln nicht parametrisiert. Andere Klauseln in derselben Abfrage können für eine erzwungene Parametrisierung in Frage kommen.
- <select_list> einer beliebigen
SELECT-Anweisung. Dies trifft ebenfalls aufSELECT-Listen von Unterabfragen sowieSELECT-Listen innerhalb vonINSERT-Anweisungen zu. - Unterabfragen mit
SELECT-Anweisungen innerhalb vonIF-Anweisungen. - Die Abfrageklauseln
TOP,TABLESAMPLE,HAVING,GROUP BY,ORDER BY,OUTPUT...INTOundFOR XML. - Direkte oder als Teilausdrücke formulierte Argumente der Operatoren
OPENROWSET,OPENQUERY,OPENDATASOURCE,OPENXMLsowie allerFULLTEXT-Operatoren. - Das pattern-Argument und das escape_character-Argument einer
LIKE-Klausel. - Das style-Argument einer
CONVERT-Klausel. - Integer-Konstanten innerhalb einer
IDENTITY-Klausel. - Über die ODBC-Erweiterungssyntax angegebene Konstanten.
- Zum Kompilierungszeitpunkt auf eine Konstante reduzierbare Ausdrücke, die Argumente der Operatoren
+,-,*,/und%sind. Um zu ermitteln, ob die erzwungene Parametrisierung in Frage kommt, betrachtet SQL Server einen Ausdruck als vor der Kompilierzeit auf eine Konstante reduzierbar, wenn die beiden folgenden Bedingungen erfüllt sind:- Der Ausdruck enthält keine Spalten, Variablen oder Unterabfragen.
- Der Ausdruck enthält eine
CASE-Klausel.
- Argumente von Abfragehinweisklauseln. Zu diesen Argumenten gehören das Argument number_of_rows des Abfragehinweises
FAST, das Argument number_of_processors des AbfragehinweisesMAXDOPsowie das Argument number des AbfragehinweisesMAXRECURSION.
Die Parametrisierung wird auf der Ebene der einzelnen Transact-SQL-Anweisungen ausgeführt, d. h. die Anweisungen werden nacheinander batchweise parametrisiert. Nach dem Kompilieren wird eine parametrisierte Abfrage ausgeführt – in dem Kontext des Batches, in dem die Abfrage ursprünglich übermittelt wurde. Wenn ein Ausführungsplan für eine Abfrage zwischengespeichert wird, können Sie anhand der sql-Spalte der dynamischen Verwaltungssicht sys.syscacheobjects ermitteln, ob die Abfrage parametrisiert wurde. Wenn eine Abfrage parametrisiert wird, stehen die Namen und Datentypen der Parameter vor dem Text des übergebenen Batches in dieser Spalte, wie beispielsweise (@1 tinyint).
Hinweis
Parameternamen sind willkürlich. Benutzer bzw. Anwendungen sollten sich nicht auf eine bestimmte Namensreihenfolge verlassen. Darüber hinaus kann sich zwischen verschiedenen Versionen von SQL Server und Service Pack-Upgrades Folgendes ändern: Parameternamen, die Auswahl der parametrisierten Literale und der Abstand im parametrisierten Text.
Parameterdatentypen
Beim Parametrisieren von Literalwerten konvertiert SQL Server die Parameter in folgende Datentypen:
- Integer-Literale, die von der Größe her in den int-Datentyp passen, werden beim Parametrisieren in int-Werte konvertiert. Größere Integer-Literale, die Teil von Prädikaten mit Vergleichsoperatoren (
<,<=,=,!=,>,>=,!<,!>,<>,ALL,ANY,SOME,BETWEENundIN) sind, werden beim Parametrisieren in numeric(38,0)-Werte konvertiert. Größere Literale, die nicht Teil von Prädikaten mit Vergleichsoperatoren sind, werden bei der Parametrisierung in numerische Werte mit ausreichenden Ziffern (precision) für ihre Größe und einem Dezimalstellenwert (scale) von 0 konvertiert. - Numerische Festkommaliterale, die Teil von Prädikaten mit Vergleichsoperatoren sind, werden bei der Parametrisierung in numerische Werte mit 38 Ziffern (precision) und einem für ihre Größe ausreichenden Dezimalstellenwert (scale) konvertiert. Numerische Festkommaliterale, die nicht Teil von Prädikaten mit Vergleichsoperatoren sind, werden bei der Parametrisierung in numerische Werte mit ausreichenden Ziffern (precision) und einem ausreichenden Dezimalstellenwert (scale) für ihre Größe konvertiert.
- Numerische Fließkommaliterale werden bei der Parametrisierung in float(53)-Werte konvertiert.
- Nicht-Unicode-Zeichenfolgenliterale werden bei der Parametrisierung in varchar(8000)-Werte konvertiert, wenn das Literal 8.000 Zeichen nicht überschreitet, und in varchar(max)-Werte, wenn es 8.000 Zeichen überschreitet.
- Unicode-Zeichenfolgenliterale werden bei der Parametrisierung in nvarchar(4000)-Werte konvertiert, wenn das Literal 4.000 Zeichen nicht überschreitet, und in nvarchar(max)-Werte, wenn es 4.000 Zeichen überschreitet.
- Binäre Literale werden bei der Parametrisierung in varbinary(8000)-Werte konvertiert, wenn das Literal 8.000 Bytes nicht überschreitet. Wenn es 8.000 Bytes überschreitet, wird es in einen varbinary(max)-Wert konvertiert.
- Literale vom Typ „money“ werden bei der Parametrisierung in money-Werte konvertiert.
Richtlinien für die Verwendung der erzwungenen Parametrisierung
Berücksichtigen Sie Folgendes, wenn Sie die PARAMETERIZATION -Option auf FORCED festlegen:
- Die erzwungene Parametrisierung konvertiert die literalen Konstanten einer Abfrage, sobald diese kompiliert wird, tatsächlich in Parameter. Daher ist es möglich, dass der Abfrageoptimierer nicht die optimalen Abfragepläne auswählt. Insbesondere verringert sich die Wahrscheinlichkeit, dass der Abfrageoptimierer eine Übereinstimmung zwischen der Abfrage und der richtigen indizierten Sicht oder dem Index für eine berechnete Spalte findet. Außerdem wählt der Abfrageoptimierer möglicherweise auch für Abfragen für partitionierte Tabellen und verteilte partitionierte Sichten nicht optimale Abfragepläne aus. Die erzwungene Parametrisierung sollte deshalb nicht in Umgebungen verwendet werden, die sich stark auf indexierte Sichten oder Indizes für berechnete Spalten stützen. Im Allgemeinen sollte die
PARAMETERIZATION FORCED-Option nur von erfahrenen Datenbankadministratoren verwendet werden, und auch dann nur, wenn diese sichergestellt haben, dass die erzwungene Parametrisierung die Leistung der Datenbank nicht beeinträchtigt. - Verteilte Abfragen, die auf mehrere Datenbanken verweisen, sind für die erzwungene Parametrisierung geeignet, solange die
PARAMETERIZATION-Option in der Datenbank aufFORCEDfestgelegt wird, in deren Kontext die Abfrage ausgeführt wird. - Wenn die
PARAMETERIZATION-Option aufFORCEDfestgelegt wird, werden alle Abfragepläne aus dem Plancache der Datenbank geleert, mit Ausnahme derer, die gerade kompiliert, erneut kompiliert oder ausgeführt werden. Die Pläne der Abfragen, die während der Einstellungsänderung kompiliert, erneut kompiliert oder ausgeführt werden, werden beim nächsten Ausführen der Abfrage parametrisiert. - Das Festlegen der
PARAMETERIZATION-Option ist ein Onlinevorgang, d.h., es sind keine exklusiven Sperren auf Datenbankebene erforderlich. - Die aktuelle Einstellung der
PARAMETERIZATION-Option wird beim erneuten Anfügen oder Wiederherstellen einer Datenbank beibehalten.
Sie können das Verhalten der erzwungenen Parametrisierung überschreiben, indem Sie angeben, dass für eine einzelne Abfrage und für alle anderen Abfragen, die syntaktisch äquivalent sind und sich nur in ihren Parameterwerten unterscheiden, die einfache Parametrisierung versucht werden soll. Im Gegensatz dazu können Sie angeben, dass die erzwungene Parametrisierung nur für einen Satz von syntaktisch äquivalenten Abfragen versucht werden soll, selbst wenn die erzwungene Parametrisierung in der Datenbank deaktiviert ist. Zu diesem Zweck werdenPlanhinweislisten verwendet.
Hinweis
Wird die PARAMETERIZATION-Option auf FORCED festgelegt, unterscheiden sich Fehlermeldungen möglicherweise, wenn die Option PARAMETERIZATION auf SIMPLE festgelegt ist: Eventuell werden mehr Fehlermeldungen unter erzwungener Parametrisierung ausgegeben, und die Zeilennummern, in denen die Fehler aufgetreten sind, werden möglicherweise falsch gemeldet.
Vorbereiten von SQL-Anweisungen
Die relationale Engine von SQL Server bietet vollständige Unterstützung für die Vorbereitung von Transact-SQL-Anweisungen vor ihrer Ausführung. Wenn eine Anwendung eine Transact-SQL-Anweisung mehrfach ausführen muss, kann mithilfe der Datenbank-API Folgendes erreicht werden:
- Einmaliges Vorbereiten der Anweisung. Mit diesem Schritt wird die Transact-SQL-Anweisung zu einem Ausführungsplan kompiliert.
- Ausführen des vorkompilierten Ausführungsplans immer dann, wenn die Anweisung ausgeführt werden muss. Dadurch muss die Transact-SQL-Anweisung nach der ersten Ausführung nicht jedes Mal erneut kompiliert werden. Das Vorbereiten und Ausführen von Anweisungen wird durch API-Funktionen und -Methoden gesteuert. Es ist nicht Teil der Transact-SQL-Sprache. Das Vorbereiten/Ausführen-Modell für die Ausführung von Transact-SQL-Anweisungen wird vom SQL Server Native Client-OLE DB-Anbieter und vom SQL Server Native Client-ODBC-Treiber unterstützt. Bei einer Vorbereitungsanforderung sendet der Anbieter oder der Treiber die Anweisung zusammen mit der Anforderung zur Vorbereitung der Anweisung an SQL Server. Von SQL Server wird ein Ausführungsplan kompiliert und ein Handle für diesen Plan an den Anbieter oder Treiber zurückgegeben. Bei einer Ausführungsanforderung sendet der Anbieter bzw. Treiber eine Anforderung an den Server, den dem Handle zugeordneten Plan auszuführen.
Vorbereitete Anweisungen können nicht zum Erstellen von temporären Objekten in SQL Server verwendet werden. Vorbereitete Anweisungen können nicht auf gespeicherte Systemprozeduren verweisen, die temporäre Objekte, wie z. B. temporäre Tabellen, erstellen. Diese Prozeduren müssen direkt ausgeführt werden.
Durch übermäßige Verwendung des Vorbereiten/Ausführen-Modells kann die Leistung beeinträchtigt werden. Wenn eine Anweisung nur ein Mal ausgeführt wird, wird durch eine direkte Ausführung nur ein Netzwerkroundtrip zum Server benötigt. Das Vorbereiten und Ausführen einer Transact-SQL-Anweisung, die nur einmal ausgeführt wird, erfordert einen zusätzlichen Netzwerkroundtrip: einen Trip zur Vorbereitung und einen Trip zur Ausführung der Anweisung.
Das Vorbereiten einer Anweisung ist effizienter, wenn Parametermarkierungen verwendet werden. Nehmen Sie z.B. an, eine Anwendung soll gelegentlich Produktinformationen aus der AdventureWorks -Beispieldatenbank abrufen. Es gibt zwei Möglichkeiten, wie die Anwendung diese Aufgabe ausführen kann.
Die erste Möglichkeit besteht darin, dass die Anwendung für jedes angeforderte Produkt eine eigene Abfrage ausführt:
SELECT * FROM AdventureWorks2022.Production.Product
WHERE ProductID = 63;
Die zweite Möglichkeit umfasst folgende Schritte:
Die Anwendung bereitet eine Anweisung vor, die die Parametermarkierung (?) enthält:
SELECT * FROM AdventureWorks2022.Production.Product WHERE ProductID = ?;Die Anwendung bindet eine Programmvariable an die Parametermarkierung.
Die Anwendung füllt die gebundene Variable mit dem Schlüsselwert und führt die Anweisung aus, sobald die Produktinformationen benötigt werden.
Die zweite Methode ist effizienter, sobald die Anweisung mehr als drei Mal ausgeführt wird.
In SQL Server bietet das Vorbereiten/Ausführen-Modell aufgrund der Art und Weise, wie Ausführungspläne wiederverwendet, keine erheblichen Leistungsvorteile gegenüber der direkten Ausführung. SQL Server besitzt effiziente Algorithmen zur Ermittlung von Übereinstimmungen zwischen aktuellen Transact-SQL-Anweisungen und Ausführungsplänen, die für vorhergehende Ausführungen der gleichen Transact-SQL-Anweisung generiert wurden. Wenn eine Anwendung eine SQL Server-Anweisung mit Parametermarkierungen mehrfach ausführt, verwendet Transact-SQL den Ausführungsplan der ersten Ausführung für die zweite und alle folgenden Ausführungen wieder (es sei denn, der Plan wird aus dem Plancache entfernt). Das Vorbereiten/Ausführen-Modell bietet jedoch weiterhin die folgenden Vorteile:
- Das Suchen eines Ausführungsplans anhand eines identifizierenden Handles ist effizienter als die Algorithmen, die für das Ermitteln einer übereinstimmenden Transact-SQL-Anweisung mit vorhandenen Ausführungsplänen verwendet werden.
- Die Anwendung kann steuern, wann der Ausführungsplan erstellt, und wann er wiederverwendet werden soll.
- Das Vorbereiten/Ausführen-Modell kann auf andere Datenbanken portiert werden, einschließlich früherer Versionen von SQL Server.
Parameterempfindlichkeit
Die Parameterempfindlichkeit, auch als „Parameterermittlung“ bezeichnet, bezieht sich auf einen Prozess, wobei SQL Server die aktuellen Parameter während der Kompilierung oder Neukompilierung ermittelt und diese an den Abfrageoptimierer übermittelt, sodass sie zum Generieren potenziell effizienter Abfrageausführungspläne verwendet werden können.
Parameterwerte werden während der Kompilierung oder Neukompilierung für die folgenden Batchtypen ermittelt:
- Gespeicherten Prozeduren
- Abfragen, die über
sp_executesqlübermittelt werden - Vorbereitete Abfragen
Weitere Informationen zur Problembehandlung bei fehlerhaften Problemen beim Erkennen von Parametern finden Sie unter:
- Untersuchen und beheben Sie parametersensitive Probleme
- Parameter und Wiederverwendung von Ausführungsplänen
- Optimierung parametersensitiver Pläne
- Behandeln von Problemen bei Abfragen mit parameterempfindlichem Ausführungsplan in Azure SQL-Datenbank
- Behandeln von Problemen bei Abfragen mit parameterempfindlichem Ausführungsplan in Azure SQL Managed Instance
Hinweis
Für Abfragen, die den RECOMPILE-Hinweis verwenden, werden jeweils die Parameterwerte und aktuellen Werte der lokalen Variablen ermittelt. Die ermittelten Werte (der Parameter und lokalen Variablen) sind die, die an dem Ort direkt vor der Anweisung mit dem RECOMPILE-Hinweis vorhanden sind. Im Gegensatz dazu werden bei Parametern die Werte, die innerhalb des Batchaufrufs übermittelt werden, nicht geprüft.
Parallele Abfrageverarbeitung
SQL Server ermöglicht parallele Abfragen, um die Abfrageausführung und Indexvorgänge für Computer zu optimieren, die über mehrere Mikroprozessoren (CPUs) verfügen. Da SQL Server mehrere Betriebssystem-Arbeitsthreads verwenden kann, um eine Abfrage oder einen Indexvorgang parallel auszuführen, kann der betreffende Vorgang schnell und effizient ausgeführt werden.
Während der Abfrageoptimierung sucht SQL Server nach Abfragen oder Indexvorgängen, für die eine parallele Ausführung vorteilhaft ist. Für diese Abfragen fügt SQL Server Verteilungsoperatoren in den Abfrageausführungsplan ein, um die Abfrage für die parallele Ausführung vorzubereiten. Ein Verteilungsoperator ist ein Operator in einem Plan für die Abfrageausführung, der die Prozessverwaltung, die Neuverteilung der Daten und die Ablaufsteuerung ermöglicht. Der Verteilungsoperator schließt die logischen Operatoren Distribute Streams, Repartition Streamsund Gather Streams als Untertypen ein. Einer oder mehrere dieser Operatoren können in der Showplanausgabe eines Abfrageplans für eine parallele Abfrage enthalten sein.
Wichtig
Bestimmte Konstrukte verhindern, dass SQL Servers Parallelität für den gesamten Ausführungsplan oder Teile davon nutzen kann.
Zu den Konstrukten, die Parallelität verhindern, gehören:
Benutzerdefinierte Skalarfunktionen
Weitere Informationen zu benutzerdefinierten Skalarfunktionen finden Sie unter Erstellen benutzerdefinierter Funktionen. Ab SQL Server 2019 (15.x) bietet die SQL Server Datenbank-Engine die Möglichkeit, ein Inlining dieser Funktionen vorzunehmen und die Verwendung von Parallelität während der Abfrageverarbeitung zu entsperren. Weitere Informationen zum Inlining benutzerdefinierter Skalarfunktionen finden Sie unter Intelligente Abfrageverarbeitung in SQL-Datenbanken.Remote Query
Weitere Informationen zu Remote Query finden Sie unter Referenz zu logischen und physischen Showplanoperatoren.Dynamische Cursor
Weitere Informationen zu Cursorn finden Sie unter DECLARE CURSOR.Rekursive Abfragen
Weitere Informationen zur Rekursion finden Sie unter Richtlinien zum Definieren und Verwenden rekursiver allgemeiner Tabellenausdrücke und Rekursion in T-SQL.Tabellenwertfunktionen mit mehreren Anweisungen (Multi-statement table-valued functions, MSTVFs)
Weitere Informationen zu MSTVFs finden Sie unter Erstellen benutzerdefinierter Funktionen (Datenbank-Engine).TOP-Schlüsselwort
Weitere Informationen finden Sie unter TOP (Transact-SQL).
Ein Abfrageausführungsplan enthält möglicherweise das NonParallelPlanReason-Attribut im QueryPlan-Element, das beschreibt, warum keine Parallelverarbeitung verwendet wurde. Zu den Werten für dieses Attribut gehören:
| NonParallelPlanReason Value | Beschreibung |
|---|---|
| MaxDOPSetToOne | Der maximale Grad an Parallelität ist auf 1 festgelegt. |
| EstimatedDOPIsOne | Der geschätzte Grad der Parallelität ist 1. |
| NoParallelWithRemoteQuery | Parallelität wird für Remoteabfragen nicht unterstützt. |
| NoParallelDynamicCursor | Parallele Pläne werden für dynamische Cursor nicht unterstützt. |
| NoParallelFastForwardCursor | Parallele Pläne werden für schnelle Vorwärtscursor nicht unterstützt. |
| NoParallelCursorFetchByBookmark | Parallele Pläne werden nicht für Cursor unterstützt, die anhand von Lesezeichen abrufen. |
| NoParallelCreateIndexInNonEnterpriseEdition | Die parallele Indexerstellung wird für andere Editionen als Enterprise nicht unterstützt. |
| NoParallelPlansInDesktopOrExpressEdition | Parallele Pläne werden für die Desktop- und Express-Edition nicht unterstützt. |
| NonParallelizableIntrinsicFunction | Die Abfrage verweist auf eine nicht parallelisierbare intrinsische Funktion. |
| CLRUserDefinedFunctionRequiresDataAccess | Parallelität wird für eine benutzerdefinierte CLR-Funktion, die Datenzugriff erfordert, nicht unterstützt. |
| TSQLUserDefinedFunctionsNotParallelizable | Die Abfrage verweist auf eine benutzerdefinierte T-SQL-Funktion, die nicht parallelisierbar war. |
| TableVariableTransactionsDoNotSupportParallelNestedTransaction | Tabellenvariablentransaktionen unterstützen keine parallelen verschachtelten Transaktionen. |
| DMLQueryReturnsOutputToClient | Die DML-Abfrage gibt die Ausgabe an den Client zurück und ist nicht parallelisierbar. |
| MixedSerialAndParallelOnlineIndexBuildNotSupported | Nicht unterstützte Mischung aus seriellen und parallelen Plänen für eine einzelne Onlineindexerstellung. |
| CouldNotGenerateValidParallelPlan | Fehler bei der Überprüfung des parallelen Plans, Rückgriff auf seriell. |
| NoParallelForMemoryOptimizedTables | Parallelität wird für referenzierte In-Memory-OLTP-Tabellen nicht unterstützt. |
| NoParallelForDmlOnMemoryOptimizedTable | Parallelität wird für DML in einer In-Memory-OLTP-Tabelle nicht unterstützt. |
| NoParallelForNativelyCompiledModule | Parallelität wird für referenzierte nativ compilierte Module nicht unterstützt. |
| NoRangesResumableCreate | Fehler bei der Bereichsgenerierung für einen fortsetzbaren Erstellungsvorgang. |
Nach dem Einfügen eines Verteilungsoperators ist das Ergebnis ein Plan für eine parallele Abfrageausführung. Ein Plan für die parallele Abfrageausführung kann mehrere Arbeitsthreads verwenden. Ein serieller Ausführungsplan, der von einer nicht parallelen (seriellen) Abfrage verwendet wird, verwendet nur einen Arbeitsthread bei seiner Ausführung. Die tatsächliche Anzahl der Arbeitsthreads, die von einer parallelen Abfrage verwendet werden, wird während der Initialisierung der Abfrageplanausführung bestimmt und durch die Komplexität des Plans und den Grad der Parallelität bestimmt.
Der Grad der Parallelität bestimmt die maximal verwendete Anzahl von CPUs; er bezieht sich nicht auf die Anzahl der verwendeten Arbeitsthreads. Der Grad der Parallelität wird taskbezogen festgelegt. Dieser Grenzwert gilt nicht pro Anforderung oder pro Abfrage. Das bedeutet, dass während einer parallelen Abfrageausführung eine einzelne Anforderung mehrere Tasks erzeugen kann, die einem Scheduler zugeordnet sind. Mehr als die von MAXDOP angegebenen Prozessoren können möglicherweise gleichzeitig zu jedem Punkt der Abfrageausführung verwendet werden, wenn unterschiedliche Aufgaben gleichzeitig ausgeführt werden. Weitere Informationen finden Sie im Handbuch zur Thread- und Taskarchitektur.
Der SQL Server-Abfrageoptimierer verwendet keinen parallelen Ausführungsplan für eine Abfrage, wenn eine der folgenden Bedingungen zutrifft:
- Der serielle Ausführungsplan ist trivial oder überschreitet den Kostenschwellenwert für die Parallelitätseinstellung nicht.
- Der serielle Ausführungsplan hat eine niedrigere geschätzte Unterstrukturkosten als alle parallelen Ausführungsplan, die vom Optimierer untersucht werden.
- Die Abfrage enthält skalare oder relationale Operatoren, die nicht parallel ausgeführt werden können. Bestimmte Operatoren können verursachen, dass ein Abschnitt des Ausführungsplans oder der gesamte Plan im seriellen Modus ausgeführt wird.
Hinweis
Die geschätzten Unterstrukturkosten eines parallelen Plans können unter dem Kostenschwellenwert für die Parallelitätseinstellung liegen. Dies gibt an, dass die geschätzten Unterstrukturkosten des seriellen Plans sie überschritten haben, und der Abfrageplan mit den niedrigeren geschätzten Teilstrukturkosten wurde ausgewählt.
Parallelitätsgrad (DOP)
SQL Server erkennt automatisch den am besten geeigneten Grad an Parallelität für jede Instanz einer parallelen Abfrageausführung oder eines DDL-Indizierungsvorgangs (Data Definition Language). Dazu werden die folgenden Kriterien untersucht:
Wird SQL Server auf einem Computer mit mehreren Mikroprozessoren (oder CPUs) ausgeführt wie z. B. auf einem symmetrischen Multiprozessorcomputer (Symmetric Multiprocessing, SMP)? Nur Computer mit mehreren CPUs können parallele Abfragen verwenden.
Sind ausreichend Arbeitsthreads verfügbar? Jeder Abfrage- oder Indexvorgang setzt zu seiner Ausführung eine bestimmte Anzahl von Arbeitsthreads voraus. Das Ausführen eines parallelen Plans erfordert mehr Arbeitsthreads als ein serieller Plan, und die Anzahl der erforderlichen Arbeitsthreads steigt mit dem Grad der Parallelität. Wenn die Arbeitsthreadanforderung des parallelen Plans für einen bestimmten Grad der Parallelität nicht erfüllt werden kann, reduziert SQL Server Datenbank-Engine den Grad an Parallelität automatisch oder verwirft den parallelen Plan in dem angegebenen Arbeitsauslastungskontext. Stattdessen wird der serielle Plan (ein Arbeitsthread) ausgeführt.
Welcher Abfragetyp oder Indexvorgangstyp soll ausgeführt werden? Indexvorgänge, die einen Index erstellen oder neu erstellen oder einen gruppierten Index löschen, sowie Abfragen, die sehr viele CPU-Zyklen beanspruchen, eignen sich am besten für einen parallelen Plan. So sind z. B. Joins großer Tabellen, umfassende Aggregationen und Sortierungen großer Resultsets gut geeignet. Für einfache Abfragen, die häufig in transaktionsverarbeitenden Anwendungen eingesetzt werden, wird der zusätzliche Aufwand, der für die Koordinierung einer parallelen Abfrageausführung erforderlich ist, durch die erwartete Leistungssteigerung in der Regel nicht gerechtfertigt. Um zu ermitteln, für welche Abfragen die parallele Ausführung sinnvoll ist und für welche dies nicht gilt, vergleicht die SQL Server Datenbank-Engine die geschätzten Kosten für die Ausführung der Abfrage oder des Indexvorgangs mithilfe des Werts für den Kostenschwellenwert für Parallelität. Benutzer können den Standardwert 5 mithilfe von sp_configure ändern, wenn durch einen richtigen Test ermittelt wurde, dass ein anderer Wert besser für die ausgeführte Workload geeignet ist.
Gibt es eine ausreichende Anzahl von zu verarbeitenden Zeilen? Wenn der Abfrageoptimierer ermittelt, dass die Anzahl der Zeilen zu niedrig ist, werden keine Verteilungsoperatoren eingesetzt, um die Zeilen zu verteilen. Demzufolge werden die Operatoren seriell ausgeführt. Durch das Ausführen der Operatoren in einem seriellen Plan werden Situationen vermieden, in denen die Kosten für Start, Verteilung und Koordinierung den Nutzen übersteigen, der durch die parallele Ausführung der Operatoren erzielt würde.
Sind aktuelle Verteilungsstatistiken verfügbar? Wenn der höchste Grad der Parallelität nicht möglich ist, werden zunächst niedrigere Grade in Betracht gezogen, bevor der parallele Plan verworfen wird. Wenn Sie z. B. einen gruppierten Index für eine Sicht erstellen, können die Statistiken nicht ausgewertet werden, weil der gruppierte Index noch nicht vorhanden ist. In diesem Fall kann die SQL Server Datenbank-Engine nicht den höchsten Grad an Parallelität für den Indexvorgang bereitstellen. Allerdings können einige Vorgänge, wie z. B. das Sortieren und Scannen, von der parallelen Ausführung profitieren.
Hinweis
Parallele Indexvorgänge sind nur in den Editionen SQL Server Enterprise, Developer und Evaluation verfügbar.
Zur Ausführungszeit ermittelt die SQL Server Datenbank-Engine, ob die aktuelle Systemlast und die oben beschriebenen Konfigurationsinformationen die parallele Ausführung zulassen. Wenn die parallele Ausführung gerechtfertigt ist, ermittelt die SQL Server Datenbank-Engine die optimale Anzahl von Arbeitsthreads und verteilt dann die Ausführung des parallelen Plans auf diese Arbeitsthreads. Wenn die parallele Ausführung eines Abfrage- oder Indexvorgangs mit mehreren Arbeitsthreads gestartet wird, wird dieselbe Anzahl an Arbeitsthreads bis zur Beendigung des Vorgangs verwendet. SQL Server Datenbank-Engine bestimmt die optimale Anzahl von Arbeitsthreads jedes Mal neu, wenn ein Ausführungsplan aus dem Plancache abgerufen wird. Bei einer Ausführung einer Abfrage könnte z. B. ein serieller Plan verwendet werden, bei einer späteren Ausführung derselben Abfrage ein paralleler Plan, der drei Arbeitsthreads verwendet, und bei der dritten Ausführung dieser Abfrage ein paralleler Plan, der vier Arbeitsthreads verwendet.
Die Aktualisierungs- und Löschoperatoren in einem parallelen Abfrageausführungsplan werden seriell ausgeführt, aber die WHERE-Klausel einer UPDATE- oder DELETE-Anweisung wird möglicherweise parallel ausgeführt. Die eigentlichen Datenänderungen werden anschließend seriell auf die Datenbank angewendet.
Bis zu SQL Server 2012 (11.x) wird der Einfügeoperator ebenfalls seriell ausgeführt. Der SELECT-Teil einer INSERT-Anweisung kann jedoch parallel ausgeführt werden. Die eigentlichen Datenänderungen werden anschließend seriell auf die Datenbank angewendet.
Ab SQL Server 2014 (12.x) und dem Datenbank-Kompatibilitäts Grad 110 kann die SELECT ... INTO-Anweisung parallel ausgeführt werden. Andere Formen von Einfügeoperatoren funktionieren genau so, wie es für SQL Server 2012 (11.x) beschrieben ist.
Ab SQL Server 2016 (13.x) und dem Datenbank-Kompatibilitätsgrad 130 kann die INSERT ... SELECT-Anweisung parallel ausgeführt werden, wenn in Heaps oder gruppierte Columnstore-Indizes (CCI) eingefügt und der TABLOCK-Hinweis verwendet wird. Einfügevorgänge in lokale temporäre Tabellen (durch das #-Präfix gekennzeichnet) und in globale temporäre Tabellen (durch das ##-Präfix gekennzeichnet) sind ebenfalls für Parallelität geeignet, wenn der TABLOCK-Hinweis verwendet wird. Weitere Informationen finden Sie unter INSERT (Transact-SQL).
Statische Cursor und keysetgesteuerte Cursor können durch parallele Ausführungspläne aufgefüllt werden. Das spezifische Verhalten dynamischer Cursor kann jedoch nur durch die serielle Ausführung gewährleistet werden. Für eine Abfrage, die Teil eines dynamischen Cursors ist, generiert der Abfrageoptimierer immer einen seriellen Ausführungsplan.
Überschreiben der Grade der Parallelität
Der Grad an Parallelität legt die Anzahl der bei der Ausführung paralleler Pläne einzusetzenden Prozessoren fest. Diese Konfiguration kann auf verschiedenen Ebenen festgelegt werden:
Auf Serverebene mithilfe der Serverkonfigurationsoption für den maximalen Grad an Parallelität (MAXDOP).
Gilt für: SQL ServerHinweis
Mit SQL Server 2019 (15.x) wurden automatische Empfehlungen zum Festlegen der MAXDOP-Serverkonfigurationsoption während des Installationsvorgangs eingeführt. Auf der Setupbenutzeroberfläche können Sie entweder die empfohlenen Einstellungen übernehmen oder Ihren eigenen Wert eingeben. Weitere Informationen finden Sie unter Konfiguration der Datenbank-Engine – Seite „MaxDOP“.
Auf Arbeitsauslastungsebene mithilfe der Konfigurationsoption für die Resource Governor-Arbeitsauslastungsgruppe MAX_DOP.
Gilt für: SQL ServerAuf Datenbankebene mithilfe der datenbankweit gültigen KonfigurationMAXDOP.
Gilt für: SQL Server und Azure SQL-DatenbankAuf Abfrage- oder INDEX-Anweisungsebene mithilfe des MAXDOP-Abfragehinweises oder der MAXDOP-Indexoption. Sie können z.B. die MAXDOP-Option verwenden, um durch Erhöhen oder Reduzieren eine Steuerung der Anzahl der einem Onlineindexvorgang zugewiesenen Prozessoren zu bewirken. Auf diese Weise können Sie die Ressourcen, die von dem Indexvorgang verwendet werden, mit den Ressourcen gleichzeitiger Benutzer ausgleichen.
Gilt für: SQL Server und Azure SQL-Datenbank
Wenn die Option „Max. Grad an Parallelität“ auf 0 (Standard) festgelegt wurde, kann SQL Server alle verfügbaren Prozessoren (maximal 64) zur Ausführung paralleler Pläne verwenden. Obwohl SQL Server ein Laufzeitziel von 64 logischen Prozessoren festlegt, wenn MAXDOP auf 0 festgelegt ist, kann falls nötig ein anderer Wert manuell festgelegt werden. Wenn MAXDOP für Abfragen und Indizes auf 0 (null) festgelegt wurde, kann SQL Server alle verfügbaren Prozessoren (maximal 64) zur Ausführung paralleler Pläne für die jeweiligen Abfragen oder Indizes verwenden. MAXDOP ist kein erzwungener Wert für alle parallelen Abfragen, sondern eher ein Ziel mit Vorbehalt für alle Abfragen, die für die Parallelität qualifiziert sind. Das bedeutet, dass wenn nicht genügend Arbeitsthreads zur Laufzeit vorhanden sind, eine Abfrage möglicherweise mit einem niedrigeren Grad der Parallelität als die MAXDOP-Serverkonfigurationsoption ausgeführt wird.
Tipp
Weitere Informationen finden Sie in den MAXDOP-Empfehlungen für Richtlinien zum Konfigurieren von MAXDOP auf Server-, Datenbank-, Abfrage- oder Hinweisebene.
Beispiel für eine parallele Abfrage
In der folgenden Abfrage wird die Anzahl der Bestellungen gezählt, die in einem bestimmten Quartal, beginnend mit dem 1. April 2000, aufgegeben wurden und in denen mindestens ein Artikel der Bestellung vom Kunden erst nach dem angekündigten Datum empfangen wurde. Die Abfrage listet die Anzahl dieser Bestellungen gruppiert nach Priorität der Bestellung und in aufsteigender Reihenfolge der Priorität auf.
In diesem Beispiel werden erfundene Tabellen- und Spaltennamen verwendet.
SELECT o_orderpriority, COUNT(*) AS Order_Count
FROM orders
WHERE o_orderdate >= '2000/04/01'
AND o_orderdate < DATEADD (mm, 3, '2000/04/01')
AND EXISTS
(
SELECT *
FROM lineitem
WHERE l_orderkey = o_orderkey
AND l_commitdate < l_receiptdate
)
GROUP BY o_orderpriority
ORDER BY o_orderpriority
Nehmen Sie an, dass die folgenden Indizes für die lineitem- und die orders-Tabelle definiert werden:
CREATE INDEX l_order_dates_idx
ON lineitem
(l_orderkey, l_receiptdate, l_commitdate, l_shipdate)
CREATE UNIQUE INDEX o_datkeyopr_idx
ON ORDERS
(o_orderdate, o_orderkey, o_custkey, o_orderpriority)
Im Folgenden sehen Sie einen möglichen parallelen Plan, der für die zuvor beschriebene Abfrage generiert wurde:
|--Stream Aggregate(GROUP BY:([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=COUNT(*)))
|--Parallelism(Gather Streams, ORDER BY:
([ORDERS].[o_orderpriority] ASC))
|--Stream Aggregate(GROUP BY:
([ORDERS].[o_orderpriority])
DEFINE:([Expr1005]=Count(*)))
|--Sort(ORDER BY:([ORDERS].[o_orderpriority] ASC))
|--Merge Join(Left Semi Join, MERGE:
([ORDERS].[o_orderkey])=
([LINEITEM].[l_orderkey]),
RESIDUAL:([ORDERS].[o_orderkey]=
[LINEITEM].[l_orderkey]))
|--Sort(ORDER BY:([ORDERS].[o_orderkey] ASC))
| |--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([ORDERS].[o_orderkey]))
| |--Index Seek(OBJECT:
([tpcd1G].[dbo].[ORDERS].[O_DATKEYOPR_IDX]),
SEEK:([ORDERS].[o_orderdate] >=
Apr 1 2000 12:00AM AND
[ORDERS].[o_orderdate] <
Jul 1 2000 12:00AM) ORDERED)
|--Parallelism(Repartition Streams,
PARTITION COLUMNS:
([LINEITEM].[l_orderkey]),
ORDER BY:([LINEITEM].[l_orderkey] ASC))
|--Filter(WHERE:
([LINEITEM].[l_commitdate]<
[LINEITEM].[l_receiptdate]))
|--Index Scan(OBJECT:
([tpcd1G].[dbo].[LINEITEM].[L_ORDER_DATES_IDX]), ORDERED)
Die folgende Abbildung zeigt einen Abfrageplan, der mit einem Parallelitätsgrad von 4 ausgeführt wird und ein Join von zwei Tabellen einschließt.

Der parallele Plan enthält drei Parallelism-Operatoren. Sowohl der „Index Seek“-Operator des o_datkey_ptr-Indexes als auch der „Index Scan“-Operator des l_order_dates_idx-Indexes werden parallel ausgeführt. Dadurch werden mehrere exklusive Datenströme erzeugt. Dies kann mithilfe der nächsten Parallelism-Operatoren oberhalb der Operatoren „Index Scan“ und „Index Seek“ bestimmt werden. Beide Operatoren nehmen einfach eine Umverteilung der Daten auf die Datenströme vor, sodass dieselbe Anzahl von Datenströmen als Ausgabe erzeugt wird, wie als Eingabe vorlag. Diese Anzahl der Datenströme entspricht dem Grad an Parallelität.
Der „Parallelism“-Operator oberhalb des l_order_dates_idx Index Scan-Operators nimmt mithilfe des Werts für L_ORDERKEY als Schlüssel eine Neueinteilung der Eingabedatenströme vor. Auf diese Weise gelangen identische Werte für L_ORDERKEY in dieselben Ausgabedatenströme. Gleichzeitig behalten die Ausgabedatenströme die Reihenfolge für die L_ORDERKEY-Spalte bei, sodass die Eingabeanforderungen des „Merge Join“-Operators erfüllt sind.
Der „Parallelism“-Operator oberhalb des „Index Seek“-Operators nimmt mithilfe des Werts für O_ORDERKEY eine Neueinteilung der Eingabedatenströme vor. Da die Eingabe nicht anhand der Werte der O_ORDERKEY-Spalte sortiert wird, es sich hierbei aber um die Joinspalte des Merge Join-Operators handelt, stellt der „Sort“-Operator zwischen dem „Parallelism“- und dem „Merge Join“-Operator sicher, dass die Eingabe für den Merge Join-Operator auf der Basis der Joinspalten sortiert wird. Der Sort-Operator wird wie der „Merge Join“-Operator parallel ausgeführt.
Der oberste „Parallelism“-Operator fasst die Ergebnisse von mehreren Datenströmen in einem einzigen Datenstrom zusammen. Teilaggregationen, die vom „Stream Aggregate“-Operator unterhalb des „Parallelism“-Operators vorgenommen werden, werden dann in dem „Stream Aggregate“-Operator oberhalb des „Parallelism“-Operators zu einem einzigen SUM-Wert für jeden Wert von O_ORDERPRIORITY aufsummiert. Dieser Plan verwendet acht Arbeisthreads, da er zwei Austauschsegmente mit einem Parallelitätsgrad von 4 besitzt.
Weitere Informationen zu den in diesem Beispiel verwendeten Operatoren finden Sie unter Showplan Logical and Physical Operators Reference (Referenz zu logischen und physischen Showplanoperatoren).
Parallele Indexvorgänge
Die für das Erstellen oder Neuerstellen eines Indexes bzw. für das Löschen eines gruppierten Indexes erstellten Abfragepläne ermöglichen parallele Threadvorgänge mit mehreren Workern auf Computern, die über mehrere Mikroprozessoren verfügen.
Hinweis
Parallele Indexvorgänge sind nur in Enterprise Edition ab SQL Server 2008 (10.0.x) verfügbar.
SQL Server verwendet die gleichen Algorithmen wie bei anderen Abfragen, um den Grad an Parallelität (die Gesamtzahl der separaten Arbeitsthreads, die ausgeführt werden sollen) für Indexvorgänge zu ermitteln. Der maximale Grad an Parallelität für einen Indexvorgang hängt von der Serverkonfigurationsoption Max. Grad an Parallelität ab. Der Wert „Max. Grad an Parallelität“ kann für einzelne Indexvorgänge überschrieben werden; legen Sie hierzu die MAXDOP-Indexoption in den Anweisungen CREATE INDEX, ALTER INDEX, DROP INDEX und ALTER TABLE fest.
Wenn die SQL Server Datenbank-Engine einen Indexausführungsplan erstellt, wird die Anzahl der parallelen Vorgänge auf den niedrigsten der folgenden Werte festgelegt:
- Die Anzahl der Mikroprozessoren (oder CPUs) des Computers.
- Die in der Serverkonfigurationsoption „Max. Grad an Parallelität“ angegebene Anzahl.
- Die Anzahl der CPUs, die nicht bereits einen Schwellenwert an Arbeit überschritten haben, die für SQL Server-Arbeitsthreads durchgeführt wird.
Auf einem Computer mit acht CPUs und einem Wert für „Max. Grad an Parallelität“ in Höhe von 6 werden z.B. maximal sechs parallele Arbeitsthreads für einen Indexvorgang generiert. Falls fünf der CPUs in dem Computer bereits den Schwellenwert von SQL Server-Arbeit überschritten haben, wenn ein Indexausführungsplan erstellt wird, legt der Ausführungsplan nur drei parallele Arbeitsthreads fest.
Die Hauptphasen eines parallelen Indexvorgangs umfassen Folgendes:
- Ein koordinierender Arbeitsthread scannt die Tabelle schnell und nach dem Zufallsprinzip, um die Verteilung der Indexschlüssel einzuschätzen. Der koordinierende Arbeitsthread legt die Schlüsselgrenzen fest, die eine Reihe von Schlüsselbereichen erstellen, die dem Grad an parallelen Vorgängen entsprechen, wobei jeder Schlüsselbereich so geschätzt wird, dass eine ähnlich große Anzahl von Zeilen abgedeckt ist. Wenn z.B. vier Millionen Zeilen in einer Tabelle vorhanden sind und der Grad an Parallelität 4 beträgt, bestimmt der koordinierende Arbeitsthread die Schlüsselwerte, die vier Zeilengruppen mit je einer Million Zeilen in jeder Gruppe trennen. Wenn nicht genügend Schlüsselbereiche für die Verwendung aller CPUs eingerichtet werden können, wird der Grad an Parallelität entsprechend verringert.
- Der koordinierende Arbeitsthread verteilt eine Reihe von Arbeitsthreads, die dem Grad an parallelen Vorgängen entsprechen, und wartet, dass diese Arbeitsthreads ihre Arbeit beenden. Jeder Arbeitsthread scannt die Basistabelle mithilfe eines Filters, der nur Zeilen mit Schlüsselwerten in dem Bereich abruft, der dem Arbeitsthread zugewiesen ist. Jeder Arbeitsthread erstellt eine Indexstruktur für die Zeilen in seinem Schlüsselbereich. Bei einem partitionierten Index erstellt jeder Arbeitsthread eine angegebene Anzahl an Partitionen. Partitionen werden von Arbeitsthreads nicht gemeinsam genutzt.
- Nachdem alle parallelen Arbeitsthreads abgeschlossen sind, verbindet der koordinierende Arbeitsthread die Untereinheiten des Indexes zu einem einzelnen Index. Diese Phase gilt nur für Offline-Indexvorgänge.
Einzelne CREATE TABLE - oder ALTER TABLE -Anweisungen können über mehrere Einschränkungen verfügen, die die Erstellung eines Indexes erforderlich machen. Diese mehrfachen Indexerstellungsvorgänge werden seriell durchgeführt, obwohl jeder einzelne Indexerstellungsvorgang auf einem Computer mit mehreren CPUs als paralleler Vorgang ausgeführt werden kann.
Architektur verteilter Abfragen
Microsoft SQL Server unterstützt zwei Methoden, um auf heterogene OLE DB-Datenquellen in Transact-SQL-Anweisungen zu verweisen:
Verbindungsservernamen
Mithilfe der gespeicherten Systemprozedurensp_addlinkedserverundsp_addlinkedsrvloginkann einer OLE DB-Datenquelle ein Servername zugewiesen werden. Auf Objekte in diesen Verbindungsservern kann in Transact-SQL-Anweisungen mithilfe von aus vier Teilen bestehenden Namen verwiesen werden. Wenn z.B. der VerbindungsservernameDeptSQLSrvrfür eine andere Instanz von SQL Server definiert wird, verweist die folgende Anweisung auf eine Tabelle auf diesem Server:SELECT JobTitle, HireDate FROM DeptSQLSrvr.AdventureWorks2022.HumanResources.Employee;Der Verbindungsservername kann auch in einer
OPENQUERY-Anweisung angegeben werden, um ein Rowset aus einer OLE DB-Datenquelle zu öffnen. In Transact-SQL-Anweisungen kann dann auf dieses Rowset wie auf eine Tabelle verwiesen werden.Ad-hoc-Konnektornamen
Für seltene Verweise auf eine Datenquelle wird dieOPENROWSET- oderOPENDATASOURCE-Funktion zusammen mit den Informationen angegeben, die zum Herstellen einer Verbindung mit dem Verbindungsserver erforderlich sind. Auf das Rowset kann dann auf die gleiche Weise verwiesen werden, wie auf eine Tabelle in Transact-SQL-Anweisungen verwiesen wird:SELECT * FROM OPENROWSET('Microsoft.Jet.OLEDB.4.0', 'c:\MSOffice\Access\Samples\Northwind.mdb';'Admin';''; Employees);
SQL Server verwendet OLE DB für die Kommunikation zwischen der relationalen Engine und der Speicher-Engine. Die relationale Engine zerlegt jede Transact-SQL-Anweisung in eine Reihe von Vorgängen für einfache OLE DB-Rowsets, die durch die Speicher-Engine aus den Basistabellen geöffnet werden. Dies bedeutet, dass die relationale Engine einfache OLE DB-Rowsets auch für jede OLE DB-Datenquelle öffnen kann.
Die relationale Engine verwendet die OLE DB-API (Application Programming Interface), um die Rowsets auf Verbindungsservern zu öffnen, die Zeilen abzurufen und Transaktionen zu verwalten.
Auf dem Server, auf dem SQL Server ausgeführt wird, muss für jede OLE DB-Datenquelle, auf die als Verbindungsserver zugegriffen wird, ein OLE DB-Anbieter vorhanden sein. Die Reihe von Transact-SQL-Vorgängen, die für eine bestimmte OLE DB-Datenquelle angewendet werden können, wird durch die Funktionalität des OLE DB-Anbieters bestimmt.
Mitglieder der festen Serverrolle sysadmin können mithilfe der DisallowAdhocAccess -Eigenschaft in SQL Server die Ad-hoc-Konnektornamen für einen OLE DB-Anbieter in jeder Instanz von SQL Server aktivieren oder deaktivieren. Bei aktiviertem Ad-hoc-Zugriff kann ein beliebiger Benutzer, der bei der Instanz angemeldet ist, Transact-SQL-Anweisungen mit Ad-hoc-Connectornamen ausführen, die auf eine beliebige Datenquelle im Netzwerk verweisen, und mithilfe dieses OLE DB-Anbieters auf diese Datenquellen zugreifen. Mitglieder der sysadmin-Rolle können zum Steuern des Zugriffs auf Datenquellen den Ad-hoc-Zugriff auf diesen OLE DB-Anbieter deaktivieren. Auf diese Weise können Benutzer lediglich auf diejenigen Datenquellen zugreifen, auf die mit den von den Administratoren definierten Verbindungsservernamen verwiesen wird. Standardmäßig ist der Ad-hoc-Zugriff für SQL Server-OLE DB-Anbieter aktiviert und für alle anderen OLE DB-Anbieter deaktiviert.
Mithilfe von verteilten Abfragen kann Benutzern der Zugriff auf andere Datenquellen gewährt werden (z.B. auf Dateien, nicht relationale Datenquellen wie Active Directory usw.). Dies geschieht innerhalb des Sicherheitskontexts des Microsoft Windows-Kontos, mit dem der SQL Server-Dienst ausgeführt wird. Bei Windows-Anmeldungen nimmt SQL Server die Identität der Anmeldung ordnungsgemäß an; dies ist jedoch bei SQL Server-Anmeldungen nicht möglich. Auf diese Weise ist es einem Benutzer, der verteilte Abfragen ausführt, potenziell möglich, auf eine andere Datenquelle zuzugreifen, für die er selbst keine Berechtigungen hat, wohl aber das Konto, mit dem der SQL Server-Dienst ausgeführt wird. Verwenden Sie sp_addlinkedsrvlogin , um spezifische Anmeldungen mit Zugriffsrechten für die entsprechenden Verbindungsserver zu definieren. Diese Steuerung ist nicht für Ad-hoc-Namen verfügbar. Sie sollten daher sehr sorgfältig beim Aktivieren eines OLE DB-Anbieters für den Ad-hoc-Zugriff sein.
Wenn möglich, verlagert SQL Server relationale Vorgänge wie Joins, Einschränkungen, Projektionen, Sortierungen und Gruppierungen auf die OLE DB-Datenquelle. SQL Server liest die Basistabellen nicht standardmäßig in SQL Server ein, um die relationalen Vorgänge selbst durchzuführen. SQL Server fragt den OLE DB-Anbieter ab, um zu ermitteln, welche Ebene der SQL-Grammatik er unterstützt, und sendet auf der Grundlage dieser Informationen so viele relationale Vorgänge wie möglich an den Anbieter.
SQL Server gibt einen Mechanismus an, mit dem ein OLE DB-Anbieter Statistiken zur Verteilung von Schlüsselwerten innerhalb der OLE DB-Datenquelle zurückgibt. So kann der SQL Server-Abfrageoptimierer das Datenmuster in der Datenquelle im Hinblick auf die Anforderungen jeder Transact-SQL-Anweisung besser analysieren, wodurch der Abfrageoptimierer besser in der Lage ist, optimale Ausführungspläne zu generieren.
Verbesserte Abfrageverarbeitung bei partitionierten Tabellen und Indizes
SQL Server 2008 (10.0.x) hat für viele parallele Pläne eine bessere Leistung bei der Verarbeitung von Abfragen in partitionierten Tabellen, eine geänderte Art der Darstellung paralleler und serieller Pläne und bessere Partitionierungsinformationen in Kompilierzeit- und Laufzeitausführungsplänen ermöglicht. In diesem Thema werden diese Verbesserungen vorgestellt. Außerdem erhalten Sie Hinweise zur Interpretation der Abfrageausführungspläne für partitionierte Tabellen und Indizes sowie zu bewährten Methoden zur Verbesserung der Abfrageleistung bei partitionierten Objekten.
Hinweis
Partitionierte Tabellen und Indizes werden bis SQL Server 2014 (12.x) nur in der Enterprise-, Developer- und Evaluation-Version von SQL Server unterstützt. Ab SQL Server 2016 (13.x) SP1 werden partitionierte Tabellen und Indizes auch in SQL Server Standard Edition unterstützt.
Neuer partitionsgerichteter Suchvorgang (SEEK)
In SQL Server wird die interne Darstellung einer partitionierten Tabelle so geändert, dass der Abfrageprozessor die Tabelle für einen mehrspaltigen Index mit PartitionID als führender Spalte hält. PartitionID ist eine verborgene berechnete Spalte, die intern die ID der Partition, die eine bestimmte Zeile enthält, repräsentiert. Beispiel: Die Tabelle T, die als T(a, b, c)definiert ist, wird in Spalte a partitioniert und enthält in Spalte b einen gruppierten Index. In SQL Server wird diese partitionierte Tabelle intern als nicht partitionierte Tabelle mit dem Schema T(PartitionID, a, b, c) und einem gruppierten Index im zusammengesetzten Schlüssel (PartitionID, b)behandelt. Auf diese Weise kann der Abfrageoptimierer Suchvorgänge basierend auf PartitionID in allen partitionierten Tabellen und Indizes durchführen.
Die Partitionsentfernung wird jetzt im Suchvorgang vorgenommen.
Außerdem wurde der Abfrageoptimierer so erweitert, dass jetzt zunächst ein Such- oder Scanvorgang mit einer Bedingung für PartitionID (als logischer führender Spalte) und ggf. für weitere Indexschlüsselspalten durchgeführt werden kann. Anschließend wird dann für jeden eindeutigen Wert, der die Kriterien des Suchvorgangs der ersten Ebene erfüllt hat, ein Suchvorgang der zweiten Ebene mit einer anderen Bedingung in einer oder mehreren zusätzlichen Spalten durchgeführt. Dies bedeutet, dass mit diesem Vorgang, der Skip-Scan genannt wird, der Abfrageoptimierer basierend auf einer Bedingung zunächst einen Such- bzw. Scanvorgang durchführen kann, mit dem die Partitionen ermittelt werden, auf die zugegriffen werden muss, und dann innerhalb dieses Operators einen Indexsuchvorgang der zweiten Ebene, durch den Zeilen in diesen Partitionen zurückgegeben werden, die eine andere Bedingung erfüllen. Sehen Sie sich zum Beispiel die folgende Abfrage an:
SELECT * FROM T WHERE a < 10 and b = 2;
Gehen Sie nun davon aus, dass die Tabelle T, die als T(a, b, c)definiert ist, in Spalte a partitioniert wird und in Spalte b einen gruppierten Index enthält. Die Partitionsgrenzen für Tabelle T werden mit der folgenden Partitionsfunktion definiert:
CREATE PARTITION FUNCTION myRangePF1 (int) AS RANGE LEFT FOR VALUES (3, 7, 10);
Zur Auflösung der Abfrage führt der Abfrageprozessor zunächst einen Suchvorgang der ersten Ebene durch, in dem alle Partitionen mit Zeilen, die die Bedingung T.a < 10erfüllen, gesucht werden. Hierdurch werden die Partitionen identifiziert, auf die zugegriffen werden muss. In diesen identifizierten Partitionen führt der Prozessor dann einen Suchvorgang der zweiten Ebene im gruppierten Index der Spalte b durch, um die Zeilen zu suchen, die die Bedingung T.b = 2 und T.a < 10erfüllen.
Die folgende Abbildung ist eine logische Darstellung des Skip-Scan-Vorgangs. Sie zeigt die Tabelle T mit Daten in den Spalten a und b. Die Partitionen sind mit 1 bis 4 nummeriert, wobei die Partitionsgrenzen durch gestrichelte vertikale Linien angezeigt werden. Durch einen Suchvorgang der ersten Ebene in den Partitionen (nicht abgebildet) wurde ermittelt, dass die Partitionen 1, 2 und 3 die Suchbedingung, die durch die für die Tabelle definierte Partitionierung und das Prädikat für Spalte a vorgegeben wurde, erfüllen. Das heißt, sie erfüllen die Bedingung T.a < 10. Der vom Suchvorgang der zweiten Ebene innerhalb des Skip-Scan-Vorgangs durchlaufene Pfad ist anhand der Kurve zu erkennen. Im Wesentlichen wird beim Skip-Scan-Vorgang in diesen Partitionen nach Zeilen gesucht, die die Bedingung b = 2erfüllen. Die Gesamtkosten für den Skip-Scan-Vorgang entsprechen den Kosten, die durch drei separate Indexsuchvorgänge entstehen würden.

Anzeigen von Partitionierungsinformationen in Abfrageausführungsplänen
Sie können die Ausführungspläne für Abfragen in partitionierten Tabellen und Indizes überprüfen, indem Sie die Transact-SQL SET -Anweisung SET SHOWPLAN_XML bzw. SET STATISTICS XMLausführen oder den in SQL Server Management Studio ausgegebenen grafischen Ausführungsplan verwenden. So können Sie zum Beispiel den Ausführungsplan für die Kompilierzeit anzeigen, indem Sie auf der Symbolleiste für den Abfrage-Editor die Option Geschätzten Ausführungsplan anzeigen auswählen. Der Laufzeitplan kann durch Auswählen von Tatsächlichen Ausführungsplan einschließen angezeigt werden.
Mit diesen Tools können Sie die folgenden Informationen abrufen:
- Die Vorgänge, wie z.B.
scans,seeks,inserts,updates,mergesunddeletes, bei denen auf partitionierte Tabellen oder Indizes zugegriffen wird. - Die Partitionen, auf die durch die Abfrage zugegriffen wird. So finden sich zum Beispiel in Ausführungsplänen für die Laufzeit Informationen zur Gesamtanzahl der Partitionen sowie zu den Bereichen angrenzender Partitionen, auf die zugegriffen wird.
- Wann Skip-Scan in einem Such- bzw. Scanvorgang verwendet wird, um Daten aus einer oder mehreren Partitionen abzurufen.
Bessere Partitionierungsinformationen
SQL Server stellt verbesserte Partitionierungsinformationen sowohl für Kompilierzeit- als auch für Laufzeitausführungspläne bereit. Die Ausführungspläne enthalten jetzt die folgenden Informationen:
- Ein optionales
Partitioned-Attribut, das anzeigt, dass für eine partitionierte Tabelle ein Operator wieseek,scan,insert,update,mergeoderdeleteausgeführt wird. - Ein neues
SeekPredicateNew-Element mit einemSeekKeys-Unterelement, dasPartitionIDals führende Indexschlüsselspalte sowie Filterbedingungen enthält, mit denen Bereichssuchen fürPartitionIDfestgelegt werden. Das Vorhandensein von zweiSeekKeys-Unterelementen zeigt an, dass fürPartitionIDein Skip-Scan-Vorgang verwendet wird. - Zusammenfassende Informationen mit der Gesamtanzahl der Partitionen, auf die zugegriffen wird. Diese Informationen sind nur in Laufzeitplänen verfügbar.
Nehmen Sie die folgende Abfrage für die partitionierte Tabelle fact_salesals Beispiel zur Veranschaulichung, wie diese Informationen im grafischen Ausführungsplan und in der XML-Showplanausgabe angezeigt werden. Durch diese Abfrage werden Daten in zwei Partitionen aktualisiert.
UPDATE fact_sales
SET quantity = quantity - 2
WHERE date_id BETWEEN 20080802 AND 20080902;
Die folgende Abbildung zeigt die Eigenschaften des Clustered Index Seek-Operators im Laufzeitausführungsplan für diese Abfrage. Die Definition der Tabelle fact_sales und die Partitionsdefinition finden Sie in diesem Thema im Abschnitt „Beispiel“.

Das Partitioned-Attribut
Wenn ein Operator wie „Index Seek“ für eine partitionierte Tabelle oder einen partitionierten Index ausgeführt wird, enthalten der Kompilierzeit- und Laufzeitplan das Attribut Partitioned, das auf True (1) festgelegt wird. Das Attribut wird nicht angezeigt, wenn es auf False (0) gesetzt ist.
Das Partitioned -Attribut kann in den folgenden physischen und logischen Operatoren erscheinen:
- Table Scan
- Index Scan
- Index Seek
- Einfügen
- Update
- Löschen
- Merge
Wie in der obigen Abbildung zu sehen, wird das Attribut in den Eigenschaften des Operators, in dem es definiert ist, angezeigt. In der XML-Showplanausgabe erscheint das Attribut als Partitioned="1" im RelOp -Knoten des Operators, in dem es definiert ist.
Neues Suchprädikat (SEEK-Prädikat)
In der XML-Showplanausgabe wird das SeekPredicateNew -Element in dem Operator angezeigt, in dem es definiert ist. Das Element kann maximal zwei Instanzen des SeekKeys -Unterelements enthalten. Durch das erste SeekKeys -Element wird der Suchvorgang (SEEK) auf erster Ebene für die Partitions-ID des logischen Index angegeben. In diesem Suchvorgang werden die Partitionen ermittelt, auf die zugegriffen werden muss, damit die Bedingungen der Abfrage erfüllt werden können. Durch das zweite SeekKeys -Element wird der Suchvorgang auf zweiter Ebene innerhalb des Skip-Scan-Vorgangs festgelegt, der in allen Partitionen durchgeführt wird, die im ersten Suchvorgang identifiziert wurden.
Zusammenfassende Partitionsinformationen
In Laufzeitausführungsplänen geben die zusammenfassenden Partitionsinformationen Auskunft darüber, auf wie viele und auf welche Partitionen zugegriffen wird. Anhand dieser Informationen können Sie überprüfen, ob in der Abfrage auf die richtigen Partitionen zugegriffen wird und ob alle anderen Partitionen vom Zugriff ausgenommen werden.
Die folgenden Informationen werden bereitgestellt: Actual Partition Countund Partitions Accessed.
Actual Partition Count ist die Gesamtzahl der Partitionen, auf die durch die Abfrage zugegriffen wird.
Partitions Accessedist in der XML-Showplanausgabe die Übersichtsinformation zur Partition, die im neuen RuntimePartitionSummary -Element im RelOp -Knoten des Operators, in dem sie definiert ist, erscheint. Das folgende Beispiel zeigt den Inhalt des RuntimePartitionSummary -Elements, durch den angegeben wird, dass auf insgesamt zwei Partitionen (Partition 2 und 3) zugegriffen wird.
<RunTimePartitionSummary>
<PartitionsAccessed PartitionCount="2" >
<PartitionRange Start="2" End="3" />
</PartitionsAccessed>
</RunTimePartitionSummary>
Anzeigen von Partitionsinformationen mittels anderer Showplan-Methoden
Die Showplanmethoden SHOWPLAN_ALL, SHOWPLAN_TEXTund STATISTICS PROFILE stellen keine der in diesem Thema beschriebenen Partitionsinformationen bereit, mit der folgenden Ausnahme. Als Teil des SEEK -Prädikats werden die Partitionen, auf die zugegriffen werden muss, durch ein Bereichsprädikat für die berechnete Spalte, die die Partitions-ID repräsentiert, identifiziert. Das folgende Beispiel zeigt das SEEK -Prädikat für einen Clustered Index Seek -Operator. Es wird auf die Partitionen 2 und 3 zugegriffen, und der SEEK-Operator filtert die Zeilen heraus, die die Bedingung date_id BETWEEN 20080802 AND 20080902erfüllen.
|--Clustered Index Seek(OBJECT:([db_sales_test].[dbo].[fact_sales].[ci]),
SEEK:([PtnId1000] >= (2) AND [PtnId1000] \<= (3)
AND [db_sales_test].[dbo].[fact_sales].[date_id] >= (20080802)
AND [db_sales_test].[dbo].[fact_sales].[date_id] <= (20080902))
ORDERED FORWARD)
Interpretieren von Ausführungsplänen für partitionierte Heaps
Ein partitionierter Heap wird als logischer Index für die Partitions-ID behandelt. Die Partitionsentfernung für einen partitionierten Heap wird in einem Ausführungsplan als Table Scan -Operator mit einem SEEK -Prädikat für die Partitions-ID dargestellt. Das folgende Beispiel zeigt die bereitgestellten Showplan-Informationen:
|-- Table Scan (OBJECT: ([db].[dbo].[T]), SEEK: ([PtnId1001]=[Expr1011]) ORDERED FORWARD)
Interpretieren von Ausführungsplänen für angeordnete Joins
Eine Anordnung von Joins kann eintreten, wenn zwei Tabellen mit derselben oder einer ähnlichen Partitionsfunktion partitioniert und die Partitionierungsspalten auf beiden Seiten des Joins in der Join-Bedingung der Abfrage angegeben werden. Der Abfrageoptimierer kann einen Plan erzeugen, in dem die Partitionen aller Tabellen mit identischer Partitions-ID separat verknüpft werden. Angeordnete Joins sind jedoch möglicherweise schneller als nicht angeordnete, da sie ggf. weniger Arbeitsspeicher und weniger Verarbeitungszeit benötigen. Die Entscheidung, ob ein Plan für nicht angeordnete oder angeordnete Joins erzeugt wird, fällt auf Grundlage der geschätzten Kosten.
Bei einem Plan für angeordnete Joins liest der Nested Loops -Join eine oder mehrere zusammengefasste Tabellen- oder Indexpartitionen auf der Innenseite. Die Zahlen in den Constant Scan -Operatoren repräsentieren die Partitionsnummern.
Wenn parallele Pläne für angeordnete Joins für partitionierte Tabellen oder Indizes erzeugt werden, wird ein Parallelism-Operator zwischen dem Constant Scan -Joinoperator und dem Nested Loops -Joinoperator eingefügt. In diesem Fall lesen und bearbeiten mehrere Arbeitsthreads auf der Außenseite des Joins jeweils eine andere Partition.
Die folgende Abbildung zeigt einen parallelen Abfrageplan für einen angeordneten Join.
Parallele Ausführungsstrategie für Abfragen bei partitionierten Objekten
Der Abfrageprozessor verwendet eine parallele Ausführungsstrategie für Abfragen bei partitionierten Objekten. Im Rahmen dieser Ausführungsstrategie ermittelt der Abfrageprozessor die für die Abfrage erforderlichen Tabellenpartitionen und die den einzelnen Partitionen zugewiesenen Arbeitsthreadanteile. In den meisten Fällen ordnet der Abfrageprozessor den einzelnen Partitionen eine etwa gleich große Anzahl an Arbeitsthreads zu und führt anschließend die Abfrage partitionsübergreifend parallel aus. In den folgenden Absätzen wird die Arbeitsthreadzuordnung näher erläutert.
Wenn die Arbeitsthreadanzahl kleiner ist als die Partitionsanzahl, ordnet der Abfrageprozessor jeden Arbeitsthread einer anderen Partition zu, und zunächst verbleiben eine oder mehrere Partitionen ohne Arbeitsthreadzuordnung. Wenn die Ausführung eines Arbeitsthreads für eine Partition abgeschlossen ist, weist der Abfrageprozessor diesen der nächsten Partition zu, bis jeder Partition ein Arbeitsthread zugewiesen wurde. Dies ist der einzige Fall, in dem der Abfrageprozessor Arbeitsthreads anderen Partitionen neu zuordnet.
Zeigt einen Arbeitsthread, der nach seinem Abschluss erneut zugeordnet wurde Wenn die Anzahl an Arbeitsthreads und an Partitionen gleich ist, wird jeder Partition ein Arbeitsthread zugewiesen. Abgeschlossene Arbeitsthreads werden nicht erneut zugeordnet.

Wenn die Arbeitsthreadanzahl größer ist als die Partitionsanzahl, wird jeder Partition dieselbe Anzahl an Arbeitsthreads zugewiesen. Falls es sich bei der Anzahl an Arbeitsthreads nicht um ein Vielfaches der Anzahl an Partitionen handelt, weist der Abfrageprozessor einigen Partitionen einen weiteren Arbeitsthread zu, sodass alle verfügbaren Arbeitsthreads verwendet werden. Wenn nur eine Partition vorhanden ist, werden alle Arbeitsthreads dieser Partition zugewiesen. In der Abbildung unten sind vier Partitionen und 14 Arbeitsthreads verfügbar. Jeder Partition werden drei Arbeitsthreads zugewiesen, und zwei Partitionen wird jeweils ein zusätzlicher Arbeitsthread zugewiesen, sodass alle 14 Arbeitsthreads zugewiesen sind. Abgeschlossene Arbeitsthreads werden nicht erneut zugeordnet.

Die oben aufgeführten Beispiele sind einfache Beschreibungen der Arbeitsthreadzuordnung. Die tatsächliche Strategie ist komplexer und umfasst weitere Variablen, die sich während der Abfrageausführung ergeben. Beispiel: Wenn die Tabelle partitioniert ist, in Spalte A einen gruppierten Index aufweist und eine Abfrage mit der Prädikatklausel WHERE A IN (13, 17, 25)verwendet wird, weist der Abfrageprozessor jedem dieser drei Suchwerte (A=13, A=17 und A=25) statt jeder Tabellenpartition einen oder mehrere Arbeitsthreads zu. Die Abfrage muss nur für die Partitionen ausgeführt werden, die diese Werte enthalten. Wenn sich alle Suchwerte in derselben Partition befinden, werden alle Arbeitsthreads dieser Partition zugewiesen.
Ein weiteres Beispiel: Die Tabelle weist vier Partitionen in Spalte A mit Grenzpunkten (10, 20, 30) sowie einen Index in Spalte B auf, und für die Abfrage wird folgende Prädikatklausel verwendet: WHERE B IN (50, 100, 150). Da die Tabellenpartitionen auf den A-Werten basieren, können die B-Werte in allen Tabellenpartitionen enthalten sein. Somit sucht der Abfrageprozessor in jeder der vier Tabellenpartitionen nach jedem der drei B-Werte (50, 100, 150). Der Abfrageprozessor weist Arbeitsthreads proportional zu, sodass alle zwölf Abfragesuchläufe parallel ausgeführt werden können.
| Tabellenpartitionen auf Grundlage der Spalte A | Suche in allen Tabellenpartitionen nach B-Spaltenwerten |
|---|---|
| Tabellenpartition 1: A < 10 | B=50, B=100, B=150 |
| Tabellenpartition 2: A >= 10 AND A < 20 | B=50, B=100, B=150 |
| Tabellenpartition 3: A >= 20 AND A < 30 | B=50, B=100, B=150 |
| Tabellenpartition 4: A > 30 | B=50, B=100, B=150 |
Bewährte Methoden
Wir empfehlen die folgenden bewährten Vorgehensweisen, um die Leistung von Abfragen zu verbessern, bei denen in großen partitionierten Tabellen und Indizes auf eine große Menge von Daten zugegriffen wird:
- Verteilen Sie alle Partitionen über viele Datenträger (Datenträgerstriping). Dies ist besonders bei Verwendung von Festplatten relevant.
- Verwenden Sie möglichst einen Server mit einem Hauptspeicher, der groß genug ist für Partitionen, auf die häufig zugegriffen wird, bzw. für alle Partitionen, um die E/A-Kosten zu senken.
- Falls die abgefragten Daten nicht in den Arbeitsspeicher passen, komprimieren Sie die Tabellen und Indizes. Dies reduziert die E/A-Kosten.
- Verwenden Sie einen Server mit schnellen und möglichst vielen Prozessoren, um sich die Vorteile der parallelen Abfrageverarbeitung zu Nutze zu machen.
- Stellen Sie sicher, dass der Server über eine ausreichend große E/A-Controllerbandbreite verfügt.
- Erstellen Sie für jede große partitionierte Tabelle einen gruppierten Index, um den optimierten B-Strukturscan voll nutzen zu können.
- Beachten Sie die Empfehlungen für bewährte Vorgehensweisen im Whitepaper The Data Loading Performance Guide (Leistungsleitfaden für das Laden von Daten), wenn Sie mittels Massenladen Daten in partitionierte Tabellen laden.
Beispiel
Im folgenden Beispiel wird eine Testdatenbank mit einer Tabelle, die sieben Partitionen aufweist, erstellt. Verwenden Sie die zuvor in diesem Thema vorgestellten Tools, wenn Sie die Abfragen in diesem Beispiel durchführen, um Partitionierungsinformationen für den Kompilierungszeitplan und den Laufzeitplan anzuzeigen.
Hinweis
In diesem Beispiel werden über eine Millionen Zeilen in die Tabelle eingefügt. Je nach Hardware kann die Ausführung dieses Beispiels einige Minuten dauern. Stellen Sie vor dem Ausführen dieses Beispiels sicher, dass mehr als 1,5 GB Speicherplatz zur Verfügung stehen.
USE master;
GO
IF DB_ID (N'db_sales_test') IS NOT NULL
DROP DATABASE db_sales_test;
GO
CREATE DATABASE db_sales_test;
GO
USE db_sales_test;
GO
CREATE PARTITION FUNCTION [pf_range_fact](int) AS RANGE RIGHT FOR VALUES
(20080801, 20080901, 20081001, 20081101, 20081201, 20090101);
GO
CREATE PARTITION SCHEME [ps_fact_sales] AS PARTITION [pf_range_fact]
ALL TO ([PRIMARY]);
GO
CREATE TABLE fact_sales(date_id int, product_id int, store_id int,
quantity int, unit_price numeric(7,2), other_data char(1000))
ON ps_fact_sales(date_id);
GO
CREATE CLUSTERED INDEX ci ON fact_sales(date_id);
GO
PRINT 'Loading...';
SET NOCOUNT ON;
DECLARE @i int;
SET @i = 1;
WHILE (@i<1000000)
BEGIN
INSERT INTO fact_sales VALUES(20080800 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
GO
DECLARE @i int;
SET @i = 1;
WHILE (@i<10000)
BEGIN
INSERT INTO fact_sales VALUES(20080900 + (@i%30) + 1, @i%10000, @i%200, RAND() - 25, (@i%3) + 1, '');
SET @i += 1;
END;
PRINT 'Done.';
GO
-- Two-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080802 AND 20080902
GROUP BY date_id ;
GO
SET STATISTICS XML OFF;
GO
-- Single-partition query.
SET STATISTICS XML ON;
GO
SELECT date_id, SUM(quantity*unit_price) AS total_price
FROM fact_sales
WHERE date_id BETWEEN 20080801 AND 20080831
GROUP BY date_id;
GO
SET STATISTICS XML OFF;
GO
Zugehöriger Inhalt
- Referenz zu logischen und physischen Showplanoperatoren
- Erweiterte Ereignisübersicht
- Bewährte Methoden für die Überwachung von Workloads mit Abfragespeicher
- Kardinalitätsschätzung (SQL Server)
- Intelligente Abfrageverarbeitung in SQL-Datenbanken
- Operatorrangfolge (Transact-SQL)
- Übersicht über den Ausführungsplan
- Leistungscenter für SQL Server-Datenbank-Engine und Azure SQL-Datenbank