CREATE TABLE AS SELECT
Gilt für: ![]() Azure Synapse Analytics Analytics
Azure Synapse Analytics Analytics ![]() Platform System (PDW)
Platform System (PDW)
CREATE TABLE AS SELECT (CTAS) ist eins der wichtigsten verfügbaren T-SQL-Features. Es handelt sich dabei um einen vollständig parallelisierten Vorgang, bei dem eine neue Tabelle anhand der Ausgabe einer SELECT-Anweisung erstellt wird. CTAS ist die schnellste und einfachste Möglichkeit, eine Kopie einer Tabelle zu erstellen.
Verwenden Sie CTAS z.B., um:
- eine Tabelle mit einer anderen Hashverteilungsspalte neu zu erstellen.
- eine Tabelle als Replikat neu zu erstellen.
- einen Columnstore-Index für ausgewählte Spalten in der Tabelle zu erstellen.
- externe Daten abzufragen oder zu importieren.
Hinweis
Da CTAS auf den Funktionen zum Erstellen einer Tabelle aufbaut, wird in diesem Artikel nicht der Artikel CREATE TABLE wiederholt. Stattdessen werden die Unterschiede zwischen den Anweisungen CTAS und CREATE TABLE beschrieben. Weitere Informationen zu CREATE TABLE finden Sie im Artikel zur Anweisung CREATE TABLE (Azure Synapse Analytics).
- Diese Syntax wird vom serverlosen SQL-Pool in Azure Synapse Analytics nicht unterstützt.
- CTAS wird im Warehouse in Microsoft Fabric unterstützt.
![]() Transact-SQL-Syntaxkonventionen
Transact-SQL-Syntaxkonventionen
Syntax
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
[ ( column_name [ ,...n ] ) ]
WITH (
<distribution_option> -- required
[ , <table_option> [ ,...n ] ]
)
AS <select_statement>
OPTION <query_hint>
[;]
<distribution_option> ::=
{
DISTRIBUTION = HASH ( distribution_column_name )
| DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] )
| DISTRIBUTION = ROUND_ROBIN
| DISTRIBUTION = REPLICATE
}
<table_option> ::=
{
CLUSTERED COLUMNSTORE INDEX --default for Synapse Analytics
| CLUSTERED COLUMNSTORE INDEX ORDER (column[,...n])
| HEAP --default for Parallel Data Warehouse
| CLUSTERED INDEX ( { index_column_name [ ASC | DESC ] } [ ,...n ] ) --default is ASC
}
| PARTITION ( partition_column_name RANGE [ LEFT | RIGHT ] --default is LEFT
FOR VALUES ( [ boundary_value [,...n] ] ) )
<select_statement> ::=
[ WITH <common_table_expression> [ ,...n ] ]
SELECT select_criteria
<query_hint> ::=
{
MAXDOP
}
Argumente
Einzelheiten finden Sie im Abschnitt Arguments (Argumente) im Artikel CREATE TABLE.
Spaltenoptionen
column_name [ ,...n ]
Spaltennamen lassen die in CREATE TABLE erwähnten Spaltenoptionen nicht zu. Sie können stattdessen eine optionale Liste mit mindestens einem Spaltennamen für die neue Tabelle bereitstellen. Die Spalten in der neuen Tabelle haben die von Ihnen angegebenen Namen. Wenn Sie Spaltennamen angeben, muss die Anzahl der Spalten in der Spaltenliste mit der Anzahl der Spalten in den SELECT-Ergebnissen übereinstimmen. Wenn Sie keine Spaltennamen angeben, übernimmt die neue Zieltabelle die Spaltennamen aus den Ergebnissen der SELECT-Anweisung.
Sie können keine anderen Spaltenoptionen wie z. B. Datentypen, Sortierung oder NULL-Zulässigkeit angeben. Jedes dieser Attribute wird aus den Ergebnissen der SELECT-Anweisung abgeleitet. Sie können die SELECT-Anwendung allerdings zum Ändern der Attribute verwenden. Ein Beispiel finden Sie unter Verwenden von CTAS zum Ändern von Spaltenattributen.
Tabellenverteilungsoptionen
Weitere Informationen und Hilfe bei der Auswahl der besten Verteilungsspalte finden Sie im Abschnitt Table distribution options (Tabellenverteilungsoptionen) im Artikel CREATE TABLE. Empfehlungen zur Auswahl der Verteilung für eine Tabelle auf Basis der tatsächlichen Verwendungs- oder Beispielabfragen finden Sie unter Verteilungsratgeber in Azure Synapse SQL.
DISTRIBUTION = HASH (distribution_column_name) | ROUND_ROBIN | REPLICATE Die CTAS-Anweisung erfordert eine Verteilungsoption und verfügt nicht über Standardwerte. Hierin unterscheidet sie sich von CREATE TABLE, da letztere Standardwerte aufweist.
DISTRIBUTION = HASH ( [distribution_column_name [, ...n]] ) verteilt die Zeilen basierend auf den Hashwerten von bis zu acht Spalten, sodass die Basistabellendaten noch gleichmäßiger verteilt werden, die Datenschiefe im Laufe der Zeit verringert wird und die Abfrageleistung verbessert wird.
Hinweis
- Wenn Sie das Feature aktivieren möchten, ändern Sie mit diesem Befehl den Kompatibilitätsgrad der Datenbank in 50. Weitere Informationen zum Festlegen des Datenbank-Kompatibilitätsgrads finden Sie unter ALTER DATABSE SCOPED CONFIGURATION. Beispiel:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = 50; - Wenn Sie das Feature für die mehrspaltige Verteilung (Multi-Column Distribution, MCD) deaktivieren möchten, führen Sie diesen Befehl aus, um den Kompatibilitätsgrad der Datenbank in AUTO zu ändern. Beispiel:
ALTER DATABASE SCOPED CONFIGURATION SET DW_COMPATIBILITY_LEVEL = AUTO;vorhandene MCD-Tabellen bleiben erhalten, werden aber unlesbar. Bei Abfragen mit MCD-Tabellen wird dieser Fehler zurückgegeben:Related table/view is not readable because it distributes data on multiple columns and multi-column distribution is not supported by this product version or this feature is disabled.- Aktivieren Sie das Feature erneut, um wieder auf MCD-Tabellen zugreifen zu können.
- Um Daten in eine MCD-Tabelle zu laden, verwenden Sie CTAS-Anweisungen. Bei der Datenquelle muss es sich um Synapse SQL-Tabellen handeln.
- CTAS in MCD HEAP-Zieltabellen wird nicht unterstützt. Verwenden Sie stattdessen INSERT SELECT als Problemumgehung, um Daten in MCD-HEAP-Tabellen zu laden.
- Die Verwendung von SSMS zum Generieren eines Skripts zum Erstellen von MCD-Tabellen wird derzeit ab SSMS-Version 19 unterstützt.
Weitere Informationen und Hilfe bei der Auswahl der besten Verteilungsspalte finden Sie im Abschnitt Table distribution options (Tabellenverteilungsoptionen) im Artikel CREATE TABLE.
Empfehlungen für die beste Verteilung, die basierend auf Ihren Workloads, finden Sie unter Verteilungsratgeber (Distribution Advisor) in Azure Synapse SQL.
Tabellenpartitionsoptionen
Standardmäßig erstellt die CTAS-Anweisung eine nicht partitionierte Tabelle, selbst wenn die Quelltabelle partitioniert ist. Sie müssen die Partitionsoptionen angeben, um mit der CTAS-Anweisung eine partitionierte Tabelle zu erstellen.
Einzelheiten finden Sie im Abschnitt Table partition options (Tabellenpartitionsoptionen) im Artikel CREATE TABLE.
SELECT-Anweisung
Die SELECT-Anweisung ist der wesentliche Unterschied zwischen CTAS und CREATE TABLE.
WITH common_table_expression
Gibt ein temporäres benanntes Resultset an, das als allgemeiner Tabellenausdruck (CTE, Common Table Expression) bezeichnet wird. Weitere Informationen finden Sie unter WITH common_table_expression (Transact-SQL).
SELECT select_criteria
Füllt die neue Tabelle mit den Ergebnissen einer SELECT-Anweisung auf. Select_criteria ist der Hauptteil der SELECT-Anweisung, der bestimmt, welche Daten in die neue Tabelle kopiert werden sollen. Informationen zu SELECT-Anweisungen finden Sie unter SELECT (Transact-SQL).
Abfragetipp
Benutzer können MAXDOP auf eine ganze Zahl festlegen, um den maximalen Grad an Parallelität zu steuern. Wenn MAXDOP auf 1 festgelegt ist, wird die Abfrage von einem einzelnen Thread ausgeführt.
Berechtigungen
CTAS erfordert eine SELECT-Berechtigung für alle Objekte, auf die in select_criteria verwiesen wird.
Berechtigungen zum Erstellen einer Tabelle finden Sie unter Permissions (Berechtigungen) im Artikel CREATE TABLE.
Bemerkungen
Weitere Informationen finden Sie unter Allgemeine Hinweise im Artikel CREATE TABLE.
Einschränkungen
Weitere Informationen zu Einschränkungen und Einschränkungen finden Sie unter "Einschränkungen und Einschränkungen " in CREATE TABLE.
Ein sortierter, gruppierter Columnstore-Index kann für Spalten beliebiger in Azure Synapse Analytics unterstützter Datentypen erstellt werden, mit Ausnahme von Zeichenfolgenspalten.
SET ROWCOUNT (Transact-SQL) hat keine Auswirkung auf CTAS. Verwenden Sie TOP (Transact-SQL), um ein ähnliches Verhalten zu erzielen.
CTAS unterstützt die
OPENJSONFunktion nicht als Teil derSELECTAnweisung. Als Alternative verwenden SieINSERT INTO ... SELECT. Zum Beispiel:DECLARE @json NVARCHAR(MAX) = N' [ { "id": 1, "name": "Alice", "age": 30, "address": { "street": "123 Main St", "city": "Wonderland" } }, { "id": 2, "name": "Bob", "age": 25, "address": { "street": "456 Elm St", "city": "Gotham" } } ]'; INSERT INTO Users (id, name, age, street, city) SELECT id, name, age, JSON_VALUE(address, '$.street') AS street, JSON_VALUE(address, '$.city') AS city FROM OPENJSON(@json) WITH ( id INT, name NVARCHAR(50), age INT, address NVARCHAR(MAX) AS JSON );
Sperrverhalten
Weitere Informationen finden Sie unter Locking Behavior (Sperrverhalten) im Artikel CREATE TABLE.
Leistung
Bei einer Tabelle mit Hashverteilung können Sie CTAS verwenden, um eine andere Verteilungsspalte auszuwählen. Hierdurch kann die Leistung für Joins und Aggregationen verbessert werden. Wenn Sie keine andere Verteilungsspalte auswählen möchten, erreichen Sie die beste CTAS-Leistung, wenn Sie dieselbe Verteilungsspalte auswählen. Hierdurch wird die Neuverteilung von Zeilen vermieden.
Wenn Sie CTAS zum Erstellen einer Tabelle verwenden und die Leistung unwichtig ist, können Sie ROUND_ROBIN angeben, damit Sie sich nicht für eine Verteilungsspalte entscheiden müssen.
Um die Datenverschiebung in nachfolgenden Abfragen zu vermeiden, können Sie REPLICATE angeben. Dies erfolgt auf Kosten der höheren Speicherkapazität für das Laden einer vollständigen Kopie der Tabelle auf jedem Computeknoten.
Beispiele für das Kopieren einer Tabelle
A. Kopieren einer Tabelle mithilfe von CTAS
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Eine der häufigsten Anwendungen von CTAS ist wahrscheinlich das Erstellen einer Kopie einer Tabelle, damit Sie die DLL verändern können. Wenn Sie Ihre Tabelle z. B. ursprünglich als ROUND_ROBIN erstellt haben und sie jetzt in eine Tabelle ändern möchten, die auf eine Spalte verteilt wird, können Sie mit CTAS die Verteilungsspalte ändern. CTAS kann auch zur Änderung der Partitionierung, des Index oder der Spaltentypen verwendet werden.
Nehmen wir an, dass Sie diese Tabelle durch Festlegen von HEAP und mit dem Standardverteilungstyp von ROUND_ROBIN erstellt haben.
CREATE TABLE FactInternetSales
(
ProductKey INT NOT NULL,
OrderDateKey INT NOT NULL,
DueDateKey INT NOT NULL,
ShipDateKey INT NOT NULL,
CustomerKey INT NOT NULL,
PromotionKey INT NOT NULL,
CurrencyKey INT NOT NULL,
SalesTerritoryKey INT NOT NULL,
SalesOrderNumber NVARCHAR(20) NOT NULL,
SalesOrderLineNumber TINYINT NOT NULL,
RevisionNumber TINYINT NOT NULL,
OrderQuantity SMALLINT NOT NULL,
UnitPrice MONEY NOT NULL,
ExtendedAmount MONEY NOT NULL,
UnitPriceDiscountPct FLOAT NOT NULL,
DiscountAmount FLOAT NOT NULL,
ProductStandardCost MONEY NOT NULL,
TotalProductCost MONEY NOT NULL,
SalesAmount MONEY NOT NULL,
TaxAmt MONEY NOT NULL,
Freight MONEY NOT NULL,
CarrierTrackingNumber NVARCHAR(25),
CustomerPONumber NVARCHAR(25)
)
WITH(
HEAP,
DISTRIBUTION = ROUND_ROBIN
);
Jetzt möchten Sie eine neue Kopie dieser Tabelle mit einem gruppierten Columnstore-Index erstellen, damit Sie die Leistungsvorteile von gruppierten Columnstore-Tabellen nutzen können. Außerdem soll diese Tabelle nach ProductKey verteilt werden, da Sie Joins für diese Spalte erwarten und Datenverschiebungen während Joinvorgängen nach ProductKey vermeiden möchten. Schließlich möchten Sie auch eine Partitionierung für OrderDateKey hinzufügen, sodass Sie schnell alte Daten löschen können, indem Sie alte Partitionen verwerfen. Im Folgenden finden Sie die CTAS-Anweisung, mit der sie die alte Tabelle in eine neue Tabelle kopieren:
CREATE TABLE FactInternetSales_new
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(ProductKey),
PARTITION
(
OrderDateKey RANGE RIGHT FOR VALUES
(
20000101,20010101,20020101,20030101,20040101,20050101,20060101,20070101,20080101,20090101,
20100101,20110101,20120101,20130101,20140101,20150101,20160101,20170101,20180101,20190101,
20200101,20210101,20220101,20230101,20240101,20250101,20260101,20270101,20280101,20290101
)
)
)
AS SELECT * FROM FactInternetSales;
Schließlich können Sie Ihre Tabellen umbenennen, um die Namen mit Ihrer neuen Tabelle zu tauschen. Anschließend können Sie die alte Tabelle ablegen.
RENAME OBJECT FactInternetSales TO FactInternetSales_old;
RENAME OBJECT FactInternetSales_new TO FactInternetSales;
DROP TABLE FactInternetSales_old;
Beispiele für Spaltenoptionen
B. Verwenden von CTAS zum Ändern von Spaltenattributen
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Dieses Beispiel verwendet CTAS, um die Datentypen, NULL-Zulässigkeit und Sortierung für mehrere Spalten in der Tabelle DimCustomer2 zu ändern.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] nvarchar(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL
)
WITH (CLUSTERED COLUMNSTORE INDEX, DISTRIBUTION = HASH([CustomerKey]));
-- CTAS example to change data types, nullability, and column collations
CREATE TABLE test
WITH (HEAP, DISTRIBUTION = ROUND_ROBIN)
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
CustomerAlternateKey COLLATE Latin1_General_CS_AS_KS_WS AS CustomerAlternateKeyChangeCollation
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NOT NULL,
[CustomerAlternateKeyNullable] NVARCHAR(15) COLLATE SQL_Latin1_General_CP1_CI_AS NULL,
[CustomerAlternateKeyChangeCollation] NVARCHAR(15) COLLATE Latin1_General_CS_AS_KS_WS NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN);
Als letzten Schritt können Sie RENAME (Transact-SQL) verwenden, um die Tabellennamen zu tauschen. Dadurch wird DimCustomer2 zur neuen Tabelle.
RENAME OBJECT DimCustomer2 TO DimCustomer2_old;
RENAME OBJECT test TO DimCustomer2;
DROP TABLE DimCustomer2_old;
Beispiele für die Tabellenverteilung
C. Verwenden von CTAS zum Ändern der Verteilungsmethode für eine Tabelle
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Dieses einfache Beispiel zeigt, wie die Verteilungsmethode für eine Tabelle geändert wird. Um die Funktionsweise hinter diesem Vorgang zu zeigen, wird eine Tabelle mit Hashverteilung in RoundRobin geändert. Anschließend wird die RoundRobin-Tabelle wieder in eine Tabelle mit Hashverteilung geändert. Die finale Tabelle entspricht der ursprünglichen Tabelle.
In den meisten Fällen müssen Sie eine Tabelle mit Hashverteilung nicht in eine Roundrobin-Tabelle ändern. Es kommt häufiger vor, dass Sie eine RoundRobin-Tabelle in eine Tabelle mit Hashverteilung ändern müssen. Dies ist z.B. der Fall, wenn Sie eine neue Tabelle ursprünglich als RoundRobin laden und sie später in eine Tabelle mit Hashverteilung ändern möchten, um eine Leistungssteigerung bei Joins zu erzielen.
In diesem Beispiel wird die AdventureWorksDW-Beispieldatenbank verwendet. Um die Azure Synapse Analytics-Version zu laden, siehe Schnellstart: Erstellen und Abfragen eines dedizierten SQL-Pools (früher SQL DW) in Azure Synapse Analytics über das Azure-Portal.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a round-robin table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
Ändern Sie sie nun wieder zurück in eine Tabelle mit Hashverteilung.
-- You just made DimSalesTerritory a round-robin table.
-- Change it back to the original hash-distributed table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH(SalesTerritoryKey)
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
D: Verwenden von CTAS zur Konvertierung in eine replizierte Tabelle
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Dieses Beispiel gilt für die Konvertierung von RoundRobin-Tabellen oder Tabellen mit Hashverteilung in eine replizierte Tabelle. In diesem Beispiel geht die vorherige Methode zum Ändern des Verteilungstyps noch einen Schritt weiter. Da es sich bei DimSalesTerritory um eine Dimension und vermutlich um eine kleinere Tabelle handelt, können Sie die Tabelle als repliziert neu erstellen, um Datenverschiebungen bei der Verknüpfung zu anderen Tabellen zu vermeiden.
-- DimSalesTerritory is hash-distributed.
-- Copy it to a replicated table.
CREATE TABLE [dbo].[myTable]
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = REPLICATE
)
AS SELECT * FROM [dbo].[DimSalesTerritory];
-- Switch table names
RENAME OBJECT [dbo].[DimSalesTerritory] to [DimSalesTerritory_old];
RENAME OBJECT [dbo].[myTable] TO [DimSalesTerritory];
DROP TABLE [dbo].[DimSalesTerritory_old];
E. Verwenden von CTAS zum Erstellen einer Tabelle mit weniger Spalten
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Das folgende Beispiel erstellt eine verteilte RoundRobin-Tabelle mit dem Namen myTable (c, ln). Die neue Tabelle hat nur zwei Spalten. Sie verwendet die Spaltenaliase in der SELECT-Anweisung für die Spaltennamen.
CREATE TABLE myTable
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
Beispiele für Abfragehinweise
F. Verwenden eines Abfragehinweises mit CREATE TABLE AS SELECT (CTAS)
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Diese Abfrage zeigt die grundlegende Syntax für die Verwendung eines Join-Abfragehinweis mit der CTAS-Anweisung. Nach dem Senden der Abfrage verwendet Azure Synapse Analytics die Hashjoinstrategie beim Generieren des Abfrageplans für jede einzelne Verteilung. Weitere Informationen zum Hashjoin-Abfragehinweis finden Sie unter OPTION-Klausel (Transact-SQL).
CREATE TABLE dbo.FactInternetSalesNew
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = ROUND_ROBIN
)
AS SELECT T1.* FROM dbo.FactInternetSales T1 JOIN dbo.DimCustomer T2
ON ( T1.CustomerKey = T2.CustomerKey )
OPTION ( HASH JOIN );
Beispiele für externe Tabellen
G. Verwenden von CTAS zum Importieren von Daten aus Azure Blob Storage
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Verwenden Sie zum Importieren von Daten aus einer externen Tabelle CREATE TABLE AS SELECT, um die Daten aus der externen Tabelle auszuwählen. Die Syntax zum Auswählen von Daten aus einer externen Tabelle in Azure Synapse Analytics entspricht der Syntax zum Auswählen von Daten aus einer regulären Tabelle.
Das folgende Beispiel definiert eine externe Tabelle basierend auf Daten in einem Azure Blob Storage-Konto. Anschließend wird CREATE TABLE AS SELECT verwendet, um Daten aus der externen Tabelle auszuwählen. Dadurch werden die Daten aus Dateien mit Texttrennzeichen aus Azure Blob Storage importiert und in einer neuen Azure Synapse Analytics-Tabelle gespeichert.
--Use your own processes to create the text-delimited files on Azure Blob Storage.
--Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION='/logs/clickstream/2015/',
DATA_SOURCE = MyAzureStorage,
FILE_FORMAT = TextFileFormat)
;
--Use CREATE TABLE AS SELECT to import the Azure Blob Storage data into a new
--Synapse Analytics table called ClickStreamData
CREATE TABLE ClickStreamData
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
H. Verwenden von CTAS zum Importieren von Hadoop-Daten aus einer externen Tabelle
Gilt für: Analytics-Plattformsystem (PDW)
Verwenden Sie zum Importieren von Daten aus einer externen Tabelle einfach CREATE TABLE AS SELECT, um die Daten aus der externen Tabelle auszuwählen. Die Syntax zum Auswählen von Daten aus einer externen Tabelle in Analytics-Plattformsystem (PDW) entspricht der Syntax zum Auswählen von Daten aus einer regulären Tabelle.
Das folgende Beispiel definiert eine externe Tabelle auf einem Hadoop-Cluster. Anschließend wird CREATE TABLE AS SELECT verwendet, um Daten aus der externen Tabelle auszuwählen. Dadurch werden die Daten aus Dateien mit Texttrennzeichen aus Hadoop importiert und in einer neuen Analytics-Plattformsystem (PDW)-Tabelle gespeichert.
-- Create the external table called ClickStream.
CREATE EXTERNAL TABLE ClickStreamExt (
url VARCHAR(50),
event_date DATE,
user_IP VARCHAR(50)
)
WITH (
LOCATION = 'hdfs://MyHadoop:5000/tpch1GB/employee.tbl',
FORMAT_OPTIONS ( FIELD_TERMINATOR = '|')
)
;
-- Use your own processes to create the Hadoop text-delimited files
-- on the Hadoop Cluster.
-- Use CREATE TABLE AS SELECT to import the Hadoop data into a new
-- table called ClickStreamPDW
CREATE TABLE ClickStreamPDW
WITH
(
CLUSTERED COLUMNSTORE INDEX,
DISTRIBUTION = HASH (user_IP)
)
AS SELECT * FROM ClickStreamExt
;
Beispiele für die Verwendung von CTAS zum Ersetzen von SQL Server-Code
Verwenden Sie CTAS, um einige nicht unterstützte Features zu umgehen. Sie können nicht nur Code für das Data Warehouse ausführen – das Umschreiben von vorhandenem Code für die Verwendung von CTAS verbessert normalerweise auch die Leistung. Das liegt am vollständig parallelisierten Design dieser Anweisung.
Hinweis
Versuchen Sie, die Denkweise „CTAS zuerst“ zu verinnerlichen. Wenn Sie denken, dass Sie ein Problem mithilfe von CTAS lösen können, ist es in der Regel der beste Weg, das Problem anzugehen, selbst wenn Sie dann möglicherweise mehr Daten schreiben müssen.
I. Verwenden von CTAS anstelle von SELECT..INTO
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
SQL Server-Code verwendet in der Regel SELECT..INTO, um eine Tabelle mit den Ergebnissen einer SELECT-Anweisung aufzufüllen. Dies ist ein Beispiel für eine SELECT..INTO-Anweisung von SQL Server.
SELECT *
INTO #tmp_fct
FROM [dbo].[FactInternetSales]
Diese Syntax wird in Azure Synapse Analytics und Parallel Data Warehouse nicht unterstützt. Dieses Beispiel stellt das erneute Generieren der vorherigen SELECT..INTO-Anweisung als CTAS-Anweisung dar. Sie können eine der DISTRIBUTION-Optionen verwenden, die in der CTAS-Syntax beschrieben werden. Dieses Beispiel verwendet die Verteilungsmethode ROUND_ROBIN.
CREATE TABLE #tmp_fct
WITH
(
DISTRIBUTION = ROUND_ROBIN
)
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
J. Verwenden von CTAS zur Vereinfachung von MERGE-Anweisungen
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
MERGE-Anweisungen können zumindest teilweise durch CTAS ersetzt werden. Sie können INSERT und UPDATE in eine einzige Anweisung konsolidieren. Alle gelöschten Datensätze müssten in einer zweiten Anweisung geschlossen werden.
Im Anschluss sehen Sie ein Beispiel für UPSERT:
CREATE TABLE dbo.[DimProduct_upsert]
WITH
( DISTRIBUTION = HASH([ProductKey])
, CLUSTERED INDEX ([ProductKey])
)
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;
RENAME OBJECT dbo.[DimProduct] TO [DimProduct_old];
RENAME OBJECT dbo.[DimProduct_upsert] TO [DimProduct];
K. Explizites Angeben des Datentyps und der NULL-Zulässigkeit der Ausgabe
Gilt für: Azure Synapse Analytics und Analytics-Plattformsystem (PDW)
Beim Migrieren von SQL Server-Code zu Azure Synapse Analytics stoßen Sie möglicherweise auf das folgende Programmierungsmuster:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE result
(result DECIMAL(7,2) NOT NULL
)
WITH (DISTRIBUTION = ROUND_ROBIN)
INSERT INTO result
SELECT @d*@f
;
Sie denken vermutlich instinktiv, dass Sie diesen Code zu einer CTAS-Anweisung migrieren sollten und damit richtig liegen. Hierbei liegt jedoch ein verstecktes Problem vor.
Der folgende Code erzielt NICHT das gleiche Ergebnis:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
;
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT @d*@f as result
;
Beachten Sie, dass die Spalte „result“ (Ergebnis) die Werte des Datentyps und der NULL-Zulässigkeit des Ausdrucks übernimmt. Dies kann zu geringfügigen Abweichungen bei Werten führen, wenn Sie nicht vorsichtig sind.
Versuchen Sie als Beispiel einmal Folgendes:
SELECT result,result*@d
from result
;
SELECT result,result*@d
from ctas_r
;
Der für „result“ gespeicherte Wert unterscheidet sich. Da der gespeicherte Wert in der Spalte „result“ auch in anderen Ausdrücken verwendet wird, hat dieser Fehler eine noch größere Bedeutung.
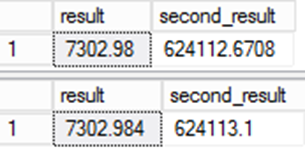
Dies ist für Datenmigrationen wichtig. Auch wenn die zweite Abfrage natürlich genauer ist, liegt ein Problem vor. Die Daten würden sich zum Quellsystem unterscheiden, was Fragen zur Integrität in der Migration aufwirft. Dies ist einer der seltenen Fällen, in denen die „falsche“ Antwort tatsächlich die richtige ist!
Der Grund für die Abweichung zwischen beiden Ergebnissen ist die implizite Typumwandlung. Im ersten Beispiel definiert die Tabelle die Spaltendefinition. Wenn die Zeile eingefügt wird, tritt eine implizite Typkonvertierung ein. Im zweiten Beispiel gibt es keine implizite Typumwandlung, da der Ausdruck den Datentyp der Spalte definiert. Beachten Sie auch, dass die Spalte im zweiten Beispiel so konfiguriert wurde, dass NULL-Werte zulässig sind. Im ersten Beispiel ist dies nicht der Fall. Bei der Erstellung der Tabelle im ersten Beispiel wurde die NULL-Zulässigkeit der Spalte explizit definiert. Im zweiten Beispiel wurde es dem Ausdruck überlassen, was standardmäßig zur Definition von NULL führt.
Zum Beheben dieser Probleme müssen Sie die Typkonvertierung und NULL-Zulässigkeit im Teil SELECT der CTAS-Anweisung explizit festlegen. Sie können diese Eigenschaften nicht im Create Table-Teil festlegen.
Das Korrigieren des Codes wird im folgenden Beispiel veranschaulicht:
DECLARE @d DECIMAL(7,2) = 85.455
, @f FLOAT(24) = 85.455
CREATE TABLE ctas_r
WITH (DISTRIBUTION = ROUND_ROBIN)
AS
SELECT ISNULL(CAST(@d*@f AS DECIMAL(7,2)),0) as result
Beachten Sie Folgendes im Beispiel:
- CAST oder CONVERT hätten verwendet werden können.
- ISNULL wird anstelle von COALESCE verwendet, um die NULL-Zulässigkeit zu erzwingen.
- ISNULL ist die äußerste Funktion.
- Der zweite Teil von ISNULL ist die Konstante
0.
Hinweis
Damit die NULL-Zulässigkeit korrekt festgelegt wird, ist es wichtig, ISNULL und nicht COALESCE zu verwenden. COALESCE ist keine deterministische Funktion. Daher lässt das Ergebnis des Ausdrucks immer NULL-Werte zu. ISNULL ist anders. ISNULL ist deterministisch. Wenn der zweite Teil der ISNULL-Funktion eine Konstante oder ein Literal ist, ergibt sich daraus der Wert NOT NULL.
Dieser Tipp eignet sich nicht nur zum Sicherstellen der Integrität von Berechnungen. Er ist auch wichtig für den Partitionswechsel von Tabellen. Angenommen, Sie haben diese Tabelle als Fakt definiert:
CREATE TABLE [dbo].[Sales]
(
[date] INT NOT NULL
, [product] INT NOT NULL
, [store] INT NOT NULL
, [quantity] INT NOT NULL
, [price] MONEY NOT NULL
, [amount] MONEY NOT NULL
)
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101,20020101
,20030101,20040101,20050101
)
)
)
;
Allerdings ist das Wertfeld ein berechneter Ausdruck und kein Teil der Quelldaten.
Um Ihr partitioniertes Dataset zu erstellen, sollten Sie das folgende Beispiel berücksichtigen:
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, [quantity]*[price] AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create')
;
Die Abfrage sollte ganz normal ausgeführt werden. Das Problem tritt auf, wenn Sie versuchen, den Partitionswechsel durchzuführen. Die Tabellendefinitionen stimmen nicht überein. Damit die Tabellendefinitionen übereinstimmen, muss die CTAS-Anweisung geändert werden.
CREATE TABLE [dbo].[Sales_in]
WITH
( DISTRIBUTION = HASH([product])
, PARTITION ( [date] RANGE RIGHT FOR VALUES
(20000101,20010101
)
)
)
AS
SELECT
[date]
, [product]
, [store]
, [quantity]
, [price]
, ISNULL(CAST([quantity]*[price] AS MONEY),0) AS [amount]
FROM [stg].[source]
OPTION (LABEL = 'CTAS : Partition IN table : Create');
Sie sehen, dass die Typkonsistenz und das Aufrechterhalten von NULL-Zulässigkeitseigenschaften für CTAS bewährte Methoden für gute Softwareentwicklung sind. Sie können somit die Integrität in Ihren Berechnungen aufrecht erhalten und gleichzeitig sicherstellen, dass Partitionswechsel möglich sind.
L. Erstellen eines sortierten gruppierten Columnstore-Index mit MAXDOP 1
CREATE TABLE Table1 WITH (DISTRIBUTION = HASH(c1), CLUSTERED COLUMNSTORE INDEX ORDER(c1) )
AS SELECT * FROM ExampleTable
OPTION (MAXDOP 1);
Nächste Schritte
- CREATE EXTERNAL DATA SOURCE (Transact-SQL)
- CREATE EXTERNAL FILE FORMAT (Transact-SQL)
- CREATE EXTERNAL TABLE (Transact-SQL)
- CREATE EXTERNAL TABLE AS SELECT (Transact-SQL)
- CREATE TABLE (Azure Synapse Analytics)
- DROP TABLE (Transact-SQL)
- DROP EXTERNAL TABLE (Transact-SQL)
- ALTER TABLE (Transact-SQL)
- ALTER EXTERNAL TABLE (Transact-SQL)
Gilt für: ![]() Warehouse in Microsoft Fabric
Warehouse in Microsoft Fabric
CREATE TABLE AS SELECT (CTAS) ist eins der wichtigsten verfügbaren T-SQL-Features. Es handelt sich dabei um einen vollständig parallelisierten Vorgang, bei dem eine neue Tabelle anhand der Ausgabe einer SELECT-Anweisung erstellt wird. CTAS ist die schnellste und einfachste Möglichkeit, eine Kopie einer Tabelle zu erstellen.
Verwenden Sie beispielsweise CTAS in Warehouse in Microsoft Fabric für Folgendes:
- Erstellen einer Kopie einer Tabelle mit einigen Spalten der Quelltabelle.
- Erstellen einer Tabelle, die das Ergebnis einer Abfrage ist, durch die andere Tabellen verknüpft werden.
Weitere Informationen zur Verwendung von CTAS in Ihrem Warehouse in Microsoft Fabric finden Sie unter Erfassen von Daten in Ihrem Warehouse mithilfe von Transact-SQL.
Hinweis
Da CTAS auf den Funktionen zum Erstellen einer Tabelle aufbaut, wird in diesem Artikel nicht der Artikel CREATE TABLE wiederholt. Stattdessen werden die Unterschiede zwischen den Anweisungen CTAS und CREATE TABLE beschrieben. Weitere Informationen zu CREATE TABLE finden Sie unter der CREATE TABLE-Anweisung.
![]() Transact-SQL-Syntaxkonventionen
Transact-SQL-Syntaxkonventionen
Syntax
CREATE TABLE { database_name.schema_name.table_name | schema_name.table_name | table_name }
AS <select_statement>
[;]
<select_statement> ::=
SELECT select_criteria
Argumente
Ausführliche Informationen finden Sie unter Argumente in CREATE TABLE für Microsoft Fabric.
Spaltenoptionen
column_name [ ,...n ]
Spaltennamen lassen die in CREATE TABLE erwähnten Spaltenoptionen nicht zu. Sie können stattdessen eine optionale Liste mit mindestens einem Spaltennamen für die neue Tabelle bereitstellen. Die Spalten in der neuen Tabelle haben die von Ihnen angegebenen Namen. Wenn Sie Spaltennamen angeben, muss die Anzahl der Spalten in der Spaltenliste mit der Anzahl der Spalten in den SELECT-Ergebnissen übereinstimmen. Wenn Sie keine Spaltennamen angeben, übernimmt die neue Zieltabelle die Spaltennamen aus den Ergebnissen der SELECT-Anweisung.
Sie können keine anderen Spaltenoptionen wie z. B. Datentypen, Sortierung oder NULL-Zulässigkeit angeben. Jedes dieser Attribute wird aus den Ergebnissen der SELECT-Anweisung abgeleitet. Sie können die SELECT-Anwendung allerdings zum Ändern der Attribute verwenden.
SELECT-Anweisung
Die SELECT-Anweisung ist der wesentliche Unterschied zwischen CTAS und CREATE TABLE.
SELECT select_criteria
Füllt die neue Tabelle mit den Ergebnissen einer SELECT-Anweisung auf. Select_criteria ist der Hauptteil der SELECT-Anweisung, der bestimmt, welche Daten in die neue Tabelle kopiert werden sollen. Informationen zu SELECT-Anweisungen finden Sie unter SELECT (Transact-SQL).
Hinweis
In Microsoft Fabric ist die Verwendung von Variablen in CTAS nicht zulässig.
Berechtigungen
CTAS erfordert eine SELECT-Berechtigung für alle Objekte, auf die in select_criteria verwiesen wird.
Berechtigungen zum Erstellen einer Tabelle finden Sie unter Permissions (Berechtigungen) im Artikel CREATE TABLE.
Bemerkungen
Weitere Informationen finden Sie unter Allgemeine Hinweise im Artikel CREATE TABLE.
Einschränkungen
SET ROWCOUNT (Transact-SQL) hat keine Auswirkung auf CTAS. Verwenden Sie TOP (Transact-SQL), um ein ähnliches Verhalten zu erzielen.
Weitere Informationen finden Sie unter Limitations and Restrictions (Einschränkungen) im Artikel CREATE TABLE.
Sperrverhalten
Weitere Informationen finden Sie unter Locking Behavior (Sperrverhalten) im Artikel CREATE TABLE.
Beispiele für das Kopieren einer Tabelle
Weitere Informationen zur Verwendung von CTAS in Ihrem Warehouse in Microsoft Fabric finden Sie unter Erfassen von Daten in Ihrem Warehouse mithilfe von Transact-SQL.
A. Verwenden von CTAS zum Ändern von Spaltenattributen
Dieses Beispiel verwendet CTAS, um Datentypen und NULL-Zulässigkeit für mehrere Spalten in der Tabelle DimCustomer2 zu ändern.
-- Original table
CREATE TABLE [dbo].[DimCustomer2] (
[CustomerKey] INT NOT NULL,
[GeographyKey] INT NULL,
[CustomerAlternateKey] VARCHAR(15)NOT NULL
)
-- CTAS example to change data types and nullability of columns
CREATE TABLE test
AS
SELECT
CustomerKey AS CustomerKeyNoChange,
CustomerKey*1 AS CustomerKeyChangeNullable,
CAST(CustomerKey AS DECIMAL(10,2)) AS CustomerKeyChangeDataTypeNullable,
ISNULL(CAST(CustomerKey AS DECIMAL(10,2)),0) AS CustomerKeyChangeDataTypeNotNullable,
GeographyKey AS GeographyKeyNoChange,
ISNULL(GeographyKey,0) AS GeographyKeyChangeNotNullable,
CustomerAlternateKey AS CustomerAlternateKeyNoChange,
CASE WHEN CustomerAlternateKey = CustomerAlternateKey
THEN CustomerAlternateKey END AS CustomerAlternateKeyNullable,
FROM [dbo].[DimCustomer2]
-- Resulting table
CREATE TABLE [dbo].[test] (
[CustomerKeyNoChange] INT NOT NULL,
[CustomerKeyChangeNullable] INT NULL,
[CustomerKeyChangeDataTypeNullable] DECIMAL(10, 2) NULL,
[CustomerKeyChangeDataTypeNotNullable] DECIMAL(10, 2) NOT NULL,
[GeographyKeyNoChange] INT NULL,
[GeographyKeyChangeNotNullable] INT NOT NULL,
[CustomerAlternateKeyNoChange] VARCHAR(15) NOT NULL,
[CustomerAlternateKeyNullable] VARCHAR(15) NULL,
NOT NULL
)
B. Verwenden von CTAS zum Erstellen einer Tabelle mit weniger Spalten
Im folgenden Beispiel wird eine Tabelle mit dem Namen myTable (c, ln) erstellt. Die neue Tabelle hat nur zwei Spalten. Sie verwendet die Spaltenaliase in der SELECT-Anweisung für die Spaltennamen.
CREATE TABLE myTable
AS SELECT CustomerKey AS c, LastName AS ln
FROM dimCustomer;
C. Verwenden von CTAS anstelle von SELECT..INTO
SQL Server-Code verwendet in der Regel SELECT..INTO, um eine Tabelle mit den Ergebnissen einer SELECT-Anweisung aufzufüllen. Dies ist ein Beispiel für eine SELECT..INTO-Anweisung von SQL Server.
SELECT *
INTO NewFactTable
FROM [dbo].[FactInternetSales]
Dieses Beispiel stellt das erneute Generieren der vorherigen SELECT..INTO-Anweisung als CTAS-Anweisung dar.
CREATE TABLE NewFactTable
AS
SELECT *
FROM [dbo].[FactInternetSales]
;
D: Verwenden von CTAS zur Vereinfachung von MERGE-Anweisungen
MERGE-Anweisungen können zumindest teilweise durch CTAS ersetzt werden. Sie können INSERT und UPDATE in eine einzige Anweisung konsolidieren. Alle gelöschten Datensätze müssten in einer zweiten Anweisung geschlossen werden.
Im Anschluss sehen Sie ein Beispiel für UPSERT:
CREATE TABLE dbo.[DimProduct_upsert]
AS
-- New rows and new versions of rows
SELECT s.[ProductKey]
, s.[EnglishProductName]
, s.[Color]
FROM dbo.[stg_DimProduct] AS s
UNION ALL
-- Keep rows that are not being touched
SELECT p.[ProductKey]
, p.[EnglishProductName]
, p.[Color]
FROM dbo.[DimProduct] AS p
WHERE NOT EXISTS
( SELECT *
FROM [dbo].[stg_DimProduct] s
WHERE s.[ProductKey] = p.[ProductKey]
)
;