Übung: Skalieren der Leistung Ihrer Arbeitsauslastung
In dieser Übung greifen Sie die Thematik aus der ersten Übung wieder auf und verbessern die Leistung, indem Sie weitere CPUs für Azure SQL-Datenbank skalieren. Sie verwenden die Datenbank, die Sie in der vorherigen Übung bereitgestellt haben.
Sie finden alle Skripts für diese Übung im Ordner 04-Performance\monitor_and_scale im GitHub-Repository, das Sie geklont haben, oder in der heruntergeladenen ZIP-Datei.
Hochskalieren der Leistung von Azure SQL
Wenn ein Problem mit der CPU-Kapazität vorliegt und Sie die Leistung skalieren möchten, müssen Sie die verfügbaren Optionen ermitteln und die CPUs dann mit den entsprechenden Azure SQL-Schnittstellen skalieren.
Entscheiden Sie, wie Sie die Leistung skalieren möchten. Weil die Arbeitsauslastung CPU-gebunden ist, können Sie beispielsweise die CPU-Kapazität oder -Geschwindigkeit erhöhen. Ein SQL Server-Benutzer muss zu einem anderen Computer wechseln oder einen virtuellen Computer neu konfigurieren, um die CPU-Kapazität zu steigern. In einigen Fällen verfügt möglicherweise selbst ein SQL Server-Administrator nicht über die Berechtigung, diese Skalierungsänderungen vorzunehmen. Dieser Prozess kann einige Zeit dauern und erfordert unter Umständen sogar eine Datenbankmigration.
In Azure können Sie die CPU-Kapazität mithilfe von
ALTER DATABASE, der Azure CLI oder dem Azure-Portal ohne benutzerseitige Datenbankmigration erhöhen.Im Azure-Portal werden Optionen für die Skalierung angezeigt, um weitere CPU-Ressourcen zu erhalten. Auf dem Blatt Überblick Ihrer Datenbank können Sie die Tarifstufe für die aktuelle Bereitstellung auswählen. Mit der Tarifstufe können Sie die Dienstebene und die Anzahl der virtuellen Kerne ändern.
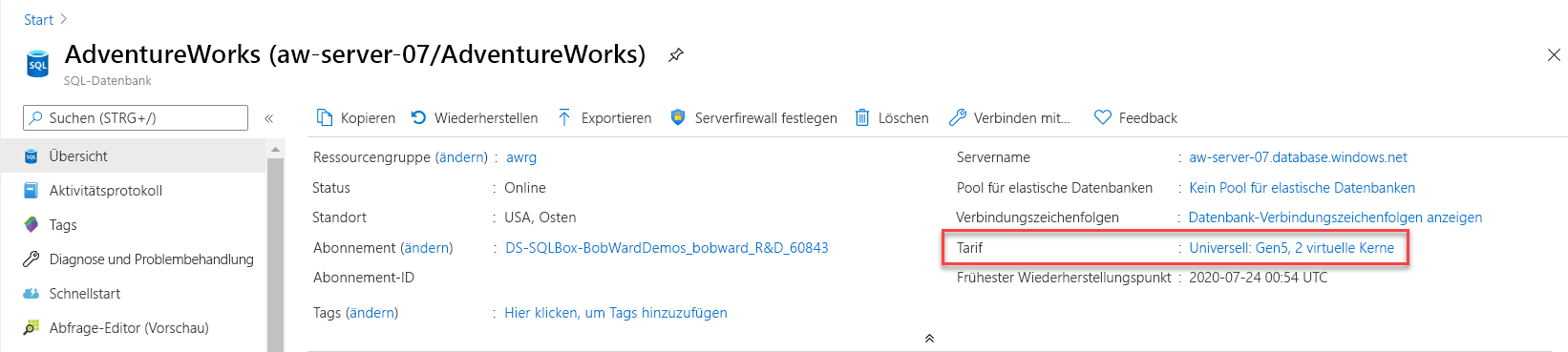
Hier finden Sie Optionen zum Ändern oder Skalieren von Computeressourcen. In der Dienstebene Universell können Sie auf bis zu acht virtuelle Kerne hochskalieren.
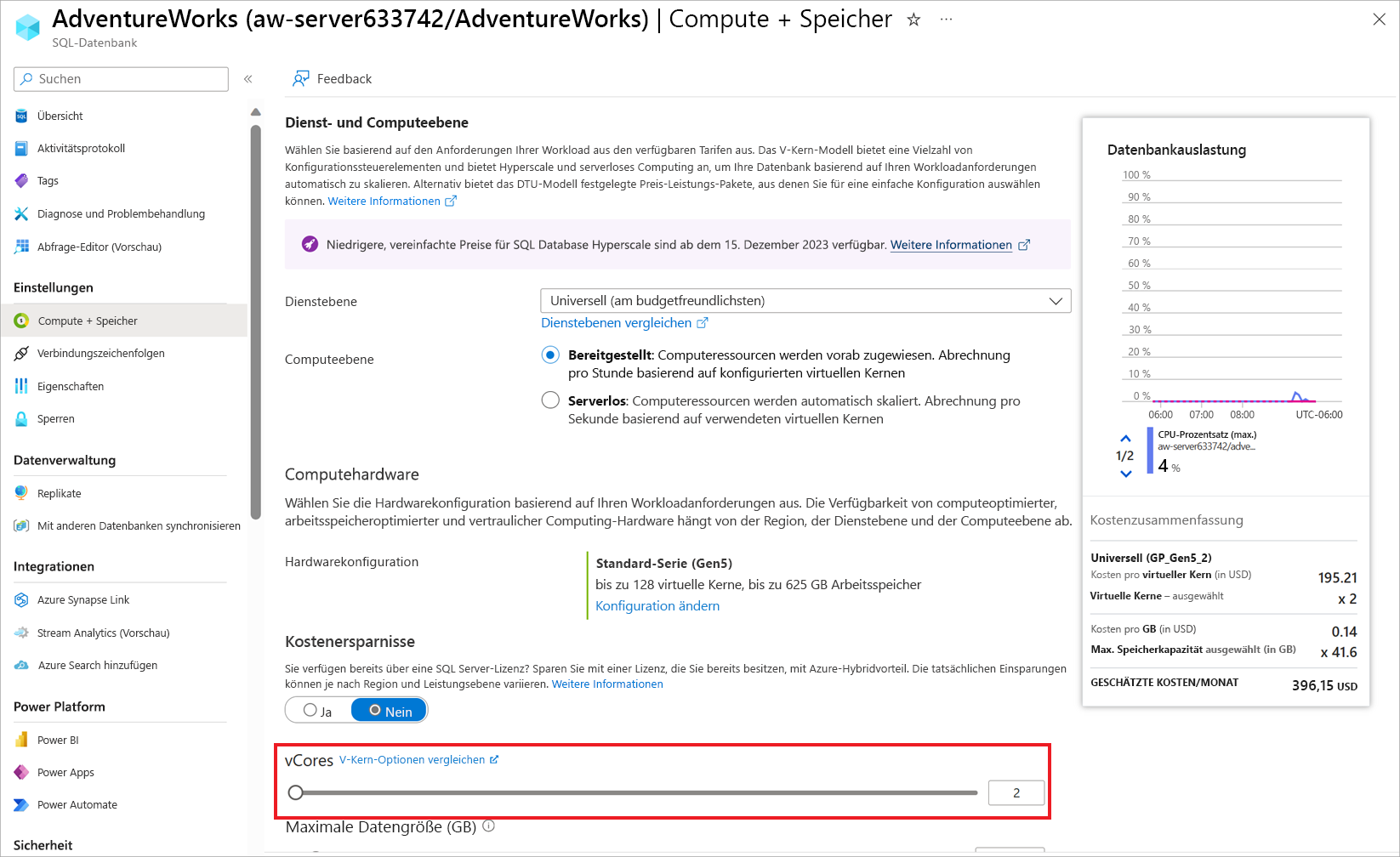
Sie können Ihre Arbeitsauslastung aber auch auf andere Weise skalieren.
Damit die Unterschiede zwischen den Berichten klar erkennbar sind, müssen Sie in dieser Übung zunächst den Abfragespeicher leeren. Wählen Sie in SQL Server Management Studio (SSMS) die Datenbank AdventureWorks aus, und klicken Sie auf das Menü Datei>Öffnen>Datei. Öffnen Sie das Skript flushhquerystore.sql in SSMS im Kontext der Datenbank AdventureWorks. Das Fenster des Abfrage-Editors sollte in etwa den folgenden Text beinhalten:
EXEC sp_query_store_flush_db;Klicken Sie auf Ausführen, um diesen T-SQL-Batch auszuführen.
Hinweis
Durch Ausführen der vorangehenden Abfrage wird der speicherinterne Teil der Abfragespeicherdaten auf die Festplatte geschrieben.
Öffnen Sie das Skript get_service_objective.sql in SSMS. Das Fenster des Abfrage-Editors sollte in etwa den folgenden Text beinhalten:
SELECT database_name,slo_name,cpu_limit,max_db_memory, max_db_max_size_in_mb, primary_max_log_rate,primary_group_max_io, volume_local_iops,volume_pfs_iops FROM sys.dm_user_db_resource_governance; GO SELECT DATABASEPROPERTYEX('AdventureWorks', 'ServiceObjective'); GOSo können Sie Ihre Dienstebene mithilfe von T-SQL herausfinden. Der Tarif bzw. die Dienstebene wird auch als Dienstziel bezeichnet. Klicken Sie auf Ausführen, um die T-SQL-Batches auszuführen.
Für die aktuelle Azure SQL-Datenbank-Bereitstellung sollten die Ergebnisse wie auf der folgenden Abbildung aussehen:
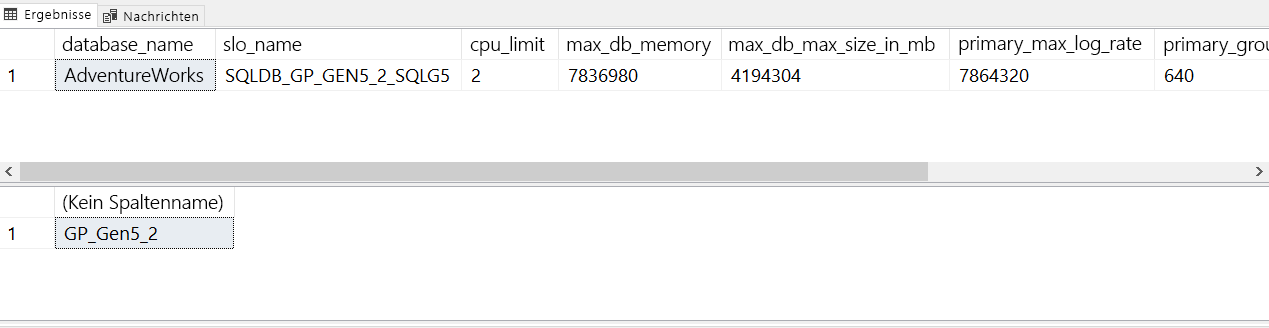
Der Begriff slo_name wird auch für das Serviceziel verwendet, SLO steht für Service Level Objective. Hierbei handelt es sich um die in einer Vereinbarung zum Service Level definierten technischen Parameter.
Die verschiedenen Werte für
slo_namesind nicht dokumentiert. Sie können jedoch am Zeichenfolgenwert erkennen, dass diese Datenbank die Dienstebene „Universell“ mit zwei virtuellen Kernen verwendet:Hinweis
SQLDB_OP_...ist die Zeichenfolge, die für die Dienstebene „Unternehmenskritisch“ verwendet wird.In der Dokumentation zu ALTER DATABASE können Sie auf Ihre SQL Server-Zielbereitstellung klicken, damit die richtigen Syntaxoptionen angezeigt werden. Klicken Sie auf das Singleton oder den Pool für elastische Datenbanken für SQL-Datenbank, um die Optionen für Azure SQL-Datenbank anzuzeigen. Das Serviceziel
'GP_Gen5_8'entspricht dem Computeumfang, den Sie im Portal ermittelt haben.Ändern Sie das Serviceziel für die Datenbank, um mehr CPUs zu skalieren. Öffnen Sie das Skript modify_service_objective.sql in SSMS, und führen Sie den T-SQL-Batch aus. Das Fenster des Abfrage-Editors sollte in etwa den folgenden Text beinhalten:
ALTER DATABASE AdventureWorks MODIFY (SERVICE_OBJECTIVE = 'GP_Gen5_8');Diese Anweisung gibt sofort ein Ergebnis zurück, die Skalierung der Computeressourcen erfolgt jedoch im Hintergrund. Bei einem so geringen Umfang sollte der Vorgang weniger als eine Minute dauern. Die Datenbank wird zudem kurz offline geschaltet, um die Änderung umzusetzen. Sie können den Fortschritt der Skalierung über das Azure-Portal verfolgen.

Klicken Sie im Objekt-Explorer im Ordner Systemdatenbanken mit der rechten Maustaste auf die Masterdatenbank, und klicken Sie auf Neue Abfrage. Führen Sie diese Abfrage im Abfrage-Editor von SSMS aus:
SELECT * FROM sys.dm_operation_status;Das ist eine weitere Möglichkeit, den Fortschritt einer Änderung des Serviceziels für Azure SQL-Datenbank zu verfolgen. Diese dynamische Verwaltungssicht macht den Änderungsverlauf des Dienstziels der Datenbank durch ALTER DATABASE verfügbar. Darin wird der aktive Fortschritt der Änderung angezeigt.
Nachstehend finden Sie eine Beispielausgabe dieser dynamischen Verwaltungssicht im Tabellenformat, nachdem die vorherige ALTER DATABASE-Anweisung ausgeführt wurde:
Element Wert session_activity_id 97F9474C-0334-4FC5-BFD5-337CDD1F9A21 resource_type 0 resource_type_desc Datenbank major_resource_id AdventureWorks minor_resource_id operation ALTER DATABASE state 1 state_desc IN_PROGRESS percent_complete 0 error_code 0 error_desc error_severity 0 error_state 0 start_time [Datum Uhrzeit] last_modify_time [Datum Uhrzeit] Während einer Änderung des Dienstziels sind Abfragen der Datenbank so lange zulässig, bis die letzte Änderung implementiert wurde. Anwendungen können dann für einen sehr kurzen Zeitraum keine Verbindung herstellen. In Azure SQL Managed Instance sind Abfragen und Verbindungen während einer Änderung der Dienstebene weiterhin zulässig, es werden jedoch alle Datenbankvorgänge wie die Erstellung neuer Datenbanken verhindert. In diesen Fällen wird die folgende Fehlermeldung angezeigt: „Der Vorgang konnte nicht abgeschlossen werden, weil für die verwaltete Instanz '[Server]' eine Änderung des Diensttarifs durchgeführt wird. Warten Sie, bis der Vorgang abgeschlossen ist, und versuchen Sie es noch mal.“
Führen Sie anschließend die zuvor aufgeführten Abfragen aus get_service_objective.sql in SSMS aus, um zu überprüfen, ob das neue Dienstziel oder die neue Dienstebene mit acht virtuellen Kernen bereits wirksam ist.
Ausführen der Arbeitsauslastung nach dem Hochskalieren
Da die Datenbank nun über eine höhere CPU-Kapazität verfügt, können Sie die Arbeitsauslastung der vorherigen Übung ausführen, um zu beobachten, ob sich die Leistung verbessert hat.
Nach Abschluss der Skalierung müssen Sie überprüfen, ob die Arbeitsauslastung schneller ausgeführt wird und ob Wartevorgänge für die CPU kürzer sind. Führen Sie die Arbeitsauslastung noch einmal mithilfe des Befehls sqlworkload.cmd aus, den Sie auch bereits in der vorherigen Übung verwendet haben.
Führen Sie mithilfe von SSMS die Abfrage aus der ersten Übung dieses Moduls noch einmal aus, um die Ergebnisse des Skripts dmdbresourcestats.sql anzuzeigen:
SELECT * FROM sys.dm_db_resource_stats;Sie sollten sehen können, dass der durchschnittliche CPU-Ressourcenverbrauch im Vergleich zu der fast 100%igen Nutzung in der vorherigen Übung nun gesunken ist.
sys.dm_db_resource_statsZeigt normalerweise eine Stunde Aktivität an. Das Ändern der Größe der Datenbank bewirkt, dasssys.dm_db_resource_statszurückgesetzt wird.Führen Sie mithilfe von SSMS die Abfrage aus der ersten Übung dieses Moduls noch einmal aus, um die Ergebnisse des Skripts dmexecrequests.sql anzuzeigen.
SELECT er.session_id, er.status, er.command, er.wait_type, er.last_wait_type, er.wait_resource, er.wait_time FROM sys.dm_exec_requests er INNER JOIN sys.dm_exec_sessions es ON er.session_id = es.session_id AND es.is_user_process = 1;Sie werden feststellen, dass es mehr Abfragen mit dem Status RUNNING (WIRD AUSGEFÜHRT) gibt. Dies bedeutet, die Worker verfügen über eine höhere CPU-Kapazität für die Ausführung.
Beobachten Sie die neue Dauer der Arbeitsauslastung. Die Arbeitsauslastungsdauer von sqlworkload.cmd sollte nun deutlich niedriger sein und etwa 25–30 Sekunden betragen.
Beobachten der Abfragespeicherberichte
Sehen Sie sich dieselben Abfragespeicherberichte an, die Sie sich auch in der vorherigen Übung angesehen haben.
Sehen Sie sich mithilfe derselben Methoden aus der ersten Übung dieses Moduls den Bericht Abfragen mit dem höchsten Ressourcenverbrauch in SSMS an:
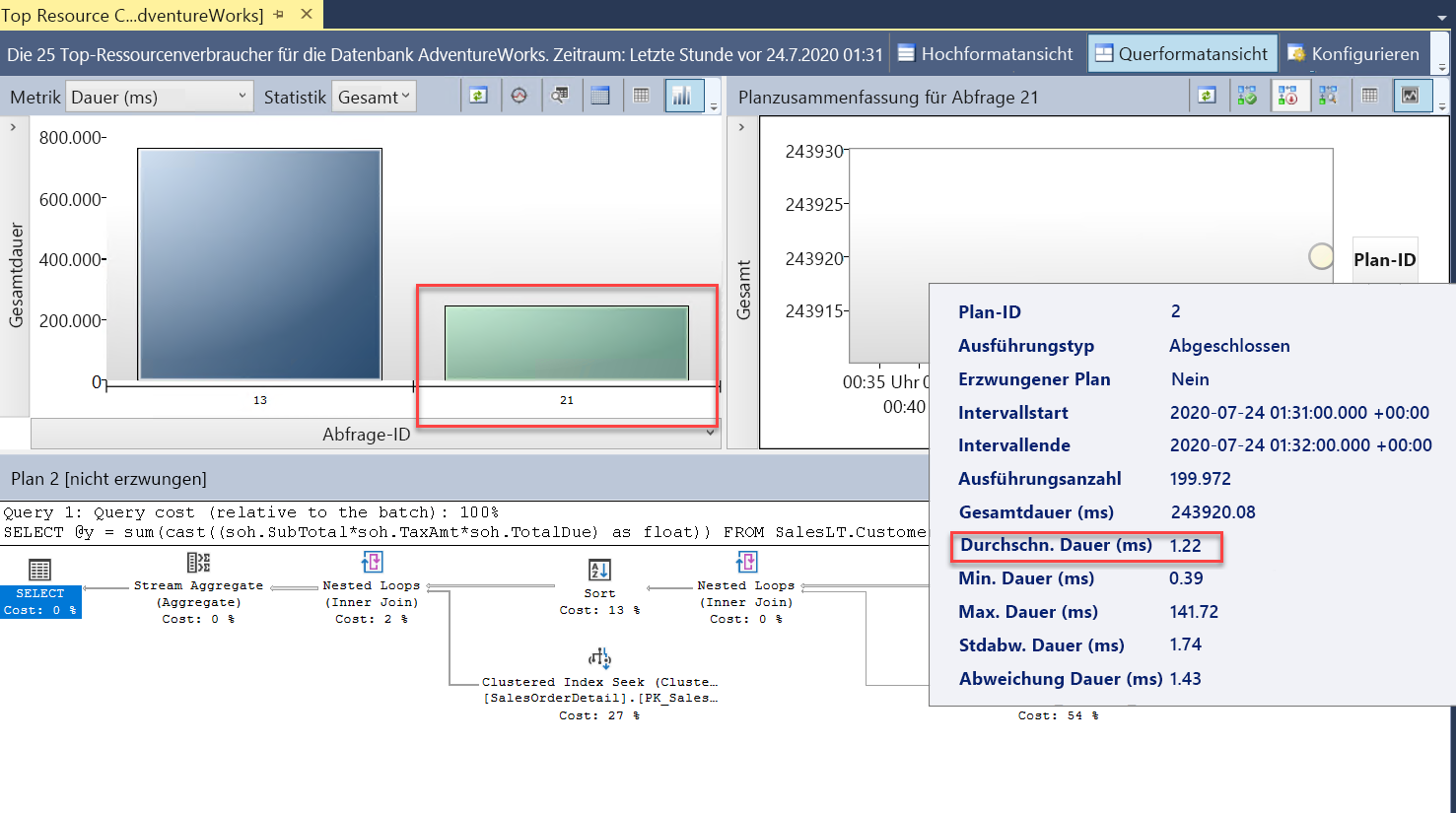
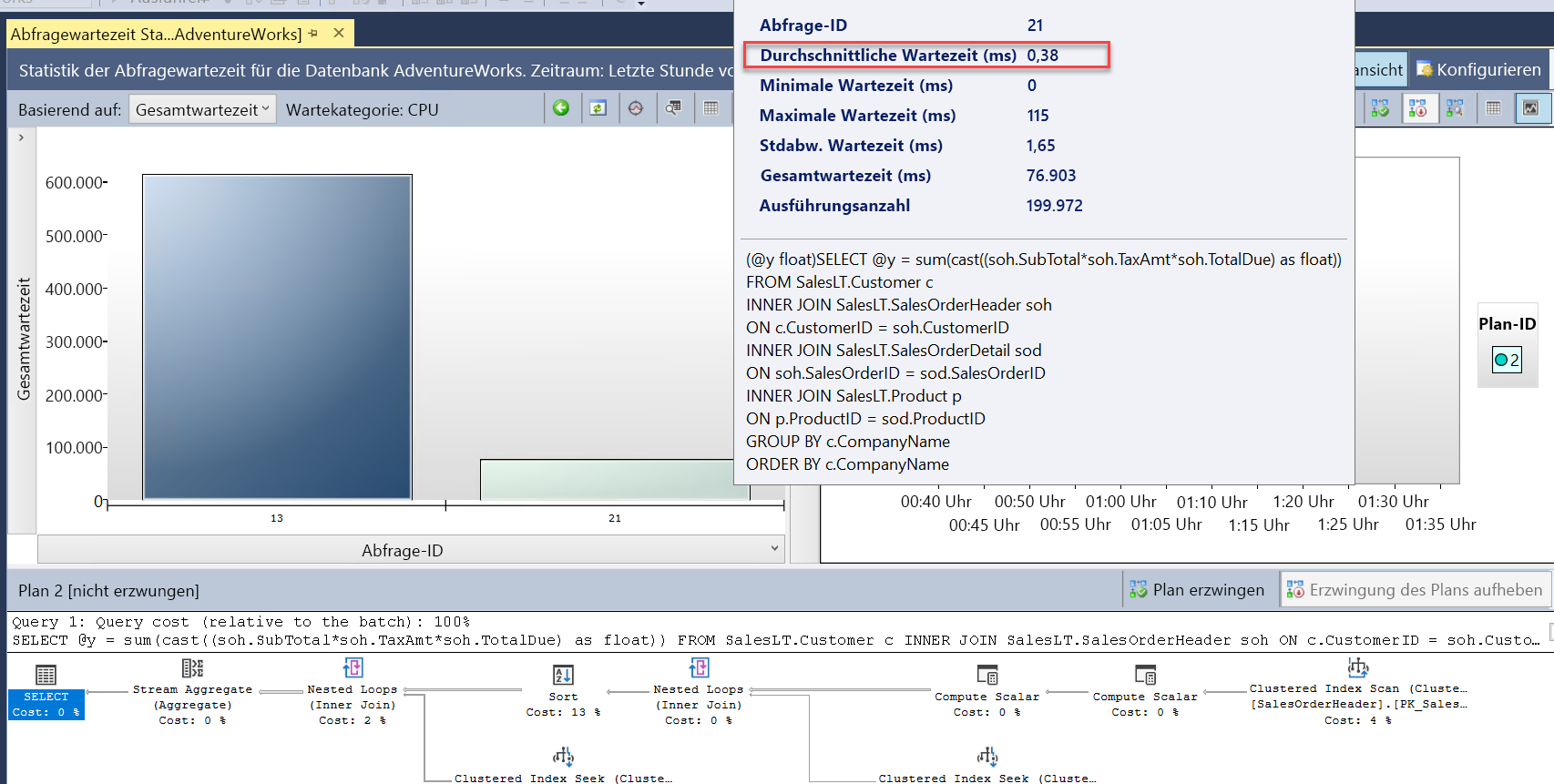
Nun werden zwei Abfragen angezeigt (
query_id). Es handelt sich bei beiden um dieselbe Abfrage. Im Abfragespeicher weisen sie jedoch unterschiedlichequery_id-Werte auf, da für den Skalierungsvorgang ein Neustart erforderlich war und die Abfrage erneut kompiliert werden musste. Im Bericht können Sie feststellen, dass die gesamte und die durchschnittliche Dauer erheblich niedriger waren.Sehen Sie sich auch den Bericht Abfragewartestatistik an, und wählen Sie die CPU-Warteleiste aus. Dort können Sie sehen, dass die durchschnittliche Wartezeit für die Abfrage insgesamt geringer ist und einen niedrigeren Prozentsatz der Gesamtdauer ausmacht. Dies ist ein guter Hinweis darauf, dass die CPU einen geringeren Ressourcenengpass darstellt, wenn die Datenbank eine geringere Anzahl an virtuellen Kernen aufweist:
Sie können nun alle Berichte sowie alle Fenster im Abfrage-Editor schließen. Trennen Sie nicht die Verbindung von SSMS, denn Sie werden das Programm in der nächsten Übung wieder benötigen.
Beobachten von Änderungen in Azure-Metriken
Navigieren Sie im Azure-Portal zur Datenbank AdventureWorks, und sehen Sie sich die Registerkarte Überwachung im Bereich Überblick noch einmal die Computenutzung an:

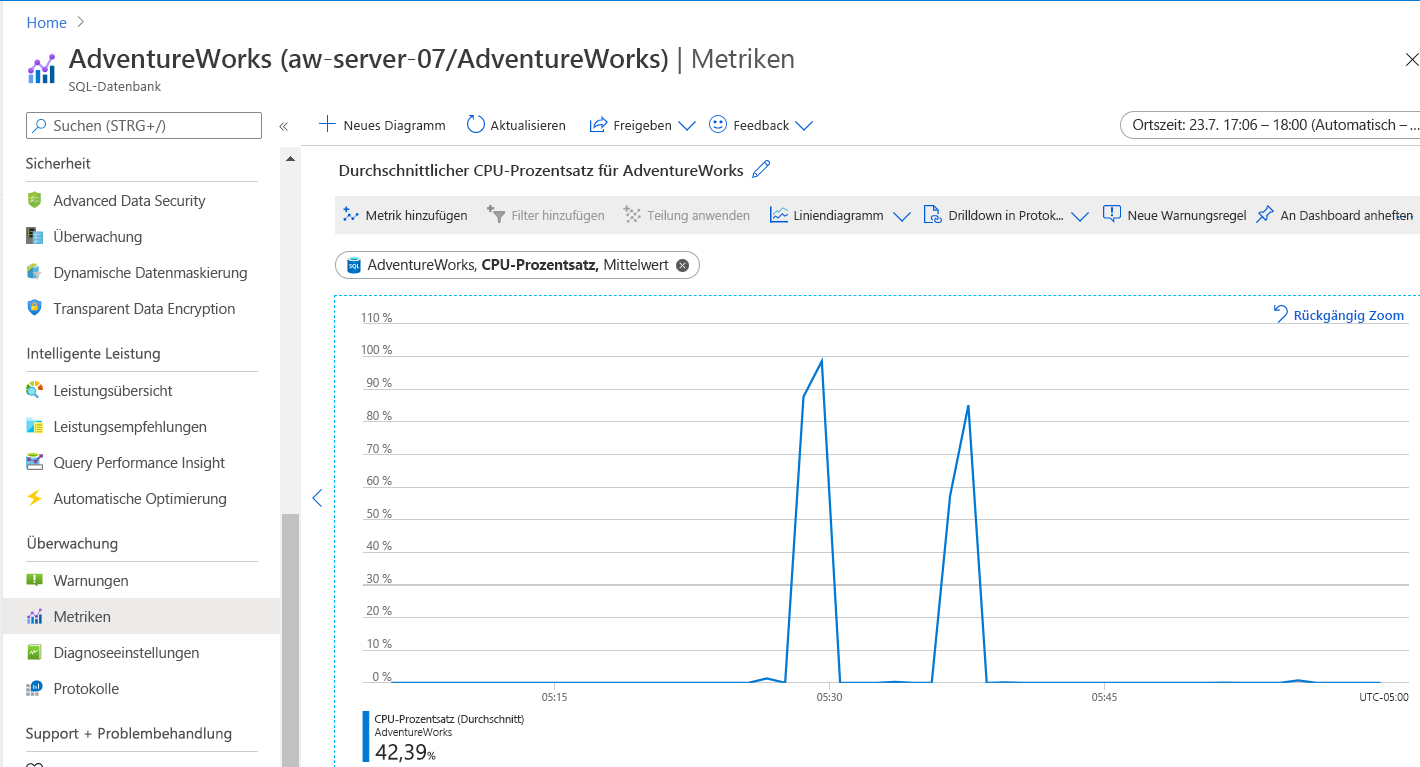
Beachten Sie, dass die Dauer bei hoher CPU-Auslastung kürzer ist. Das bedeutet, dass insgesamt weniger CPU-Ressourcen erforderlich sind, um die Arbeitsauslastung auszuführen.
Dieses Diagramm kann etwas irreführend sein. Verwenden Sie im Menü Überwachung Metriken, und legen Sie dann die Metrik auf den CPU-Grenzwert fest. Das CPU-Vergleichsdiagramm sieht in etwa wie folgt aus:
Tipp
Wenn Sie die Anzahl virtueller Kerne für diese Datenbank weiter erhöhen, können Sie die Leistung bis zu einem Schwellenwert erhöhen, bei dem alle Abfragen über ausreichend CPU-Ressourcen verfügen. Dies bedeutet nicht, dass die Anzahl virtueller Kerne der Anzahl paralleler Benutzer der Arbeitsauslastung entsprechen muss. Außerdem können Sie den Tarif so ändern, dass anstelle von Bereitgestellt Serverlos als Computetarif genutzt wird. Dadurch erzielen Sie einen besseren automatisch skalierten Ansatz für eine Arbeitsauslastung. Wenn Sie für diese Arbeitsauslastung beispielsweise einen Mindestwert von zwei und einen Höchstwert von acht virtuellen Kernen auswählen würden, würde diese Arbeitsauslastung sofort auf acht virtuelle Kerne skaliert werden.
In der nächsten Übung beobachten Sie ein Leistungsproblem und lösen dieses mithilfe von bewährten Methoden für die Anwendungsleistung.