Worum handelt es sich bei Azure HDInsight?
Sehen wir uns die Funktionen und Verwendungsmöglichkeiten von HDInsight an. Anhand dieser Übersicht können Sie feststellen, ob HDInsight die Anforderungen Ihrer Organisation erfüllt.
Was versteht man unter "Big Data"?
Der Begriff Big Data beschreibt die extrem umfangreichen strukturierten und unstrukturierten Daten, die Organisationen sammeln. Diese Daten können für Organisationen äußerst nützlich sein. Dies ist insbesondere der Fall, wenn eine Organisation durch Analyse der Daten Erkenntnisse gewinnen kann, die eine fundiertere Entscheidungsfindung ermöglichen. Diese Entscheidungen können letztlich dazu beitragen, dass eine Organisation erfolgreicher wird. Durch eine Big Data-Analyse kann eine kommerzielle Organisation beispielsweise Kundengepflogenheiten erkennen, um den Umsatz zu steigern.
Azure HDInsight-Definition
Azure HDInsight ist ein vollständig verwalteter, cloudbasierter Open-Source-Analysedienst für Unternehmen. Mit HDInsight können Sie Ihre Big Data-Daten steuern und verwalten. HDInsight:
Ist eine Cloudverteilung von Hadoop-Komponenten.
Ermöglicht eine einfachere, schnellere und kostengünstigere Verarbeitung großer Datenmengen.
Unterstützt die Verwendung von Open-Source-Frameworks, wie z. B.:
- Hadoop
- Apache Spark
- Apache Hive
- Apache Kafka
Hinweis
Mit diesen Frameworks können Sie einen weiten Bereich von Szenarien ermöglichen, z.B. Extrahieren, Transformieren und Laden (ETL), Data Warehousing, Machine Learning und IoT.
HDInsight bietet mehrere Vorteile für Organisationen, die Big Data verarbeiten, und weist folgende Eigenschaften auf:
Open Source: Ermöglicht das Erstellen optimierter Cluster für verschiedene Open-Source-Frameworks.
Zuverlässig: Bietet eine End-to-End-SLA für alle Produktionsworkloads.
Skalierbar: Ermöglicht das Skalieren von Workloads abhängig vom jeweiligen Bedarf.
Tipp
Durch die bedarfsabhängige Erstellung von Clustern können Sie Ihre Kosten senken. Sie zahlen nur für das, was Sie wirklich nutzen.
Sicher: Ermöglicht den Schutz Ihrer Unternehmensdatenressourcen durch Integration mit:
- Virtuelles Azure-Netzwerk
- Azure-Verschlüsselungstechniken
- Microsoft Entra ID
Konform: Erfüllt die gängigsten branchen- und behördenspezifischen Compliancestandards.
Überwacht: Stellt durch Integration in Azure Monitor eine einzelne Schnittstelle bereit. über die alle Cluster überwacht werden können.
Mögliche Unterstützt durch HDInsight bei der Big Data-Verarbeitung
Sie können HDInsight für viele Szenarien mit Big Data-Verarbeitung verwenden. Mögliche Daten sind:
- Historische Daten:Diese Daten wurden bereits gesammelt und gespeichert.
- Echtzeitdaten: Diese Daten werden direkt aus der Quelle gestreamt.
Die Verarbeitungsszenarien für diese Daten lassen sich in folgenden Kategorien zusammenfassen:
- Batchverarbeitung
- Data Warehousing
- IoT
- Data Science
- Hybrid
Sehen wir uns diese Kategorien genauer an.
Batchverarbeitung
Organisationen verwenden Batchverarbeitungsaufträge, um Big Data für die weitere Analyse aufzubereiten. Dieser Prozess umfasst in der Regel drei Phasen:
- Lesen der Quelldatendateien aus heterogenen Datenquellen.
- Verarbeiten der Daten.
- Schreiben der Daten in einen skalierbaren Speicher.
Hinweis
Dieser Prozess wird oftmals als ETL (Extrahieren, Transformieren und Laden) bezeichnet.
Sie können die transformierten Daten für Data Warehousing- oder Data Science-Zwecke verwenden.
Tipp
Eine wichtige Anforderung für ETL ist die horizontale Skalierung von Computeressourcen, um die Verarbeitung großer Datenmengen zu ermöglichen.
Data Warehousing
Ein Data Warehouse stellt einer Organisation einen Speicherort zur Verfügung, in dem Big Data gespeichert werden können, die analysiert werden sollen. Data Warehousing bietet folgende Möglichkeiten:
- Speichern der Daten.
- Aufbereiten der Daten für die Analyse.
- Bereitstellen der aufbereiteten Daten in einem strukturierten Format, sodass die Daten anschließend von Analysetools abgefragt werden können.
Das folgende Diagramm zeigt, wie Apache Hadoop in HDInsight Daten aus mehreren Quellen sammelt und speichert. Apache Spark und Apache Hive bereiten die Daten auf und analysieren die Daten. Schließlich werden die Daten für die Verwendung mit Business Intelligence-Tools modelliert. Für die Visualisierung der Ergebnisse wird Power BI verwendet.
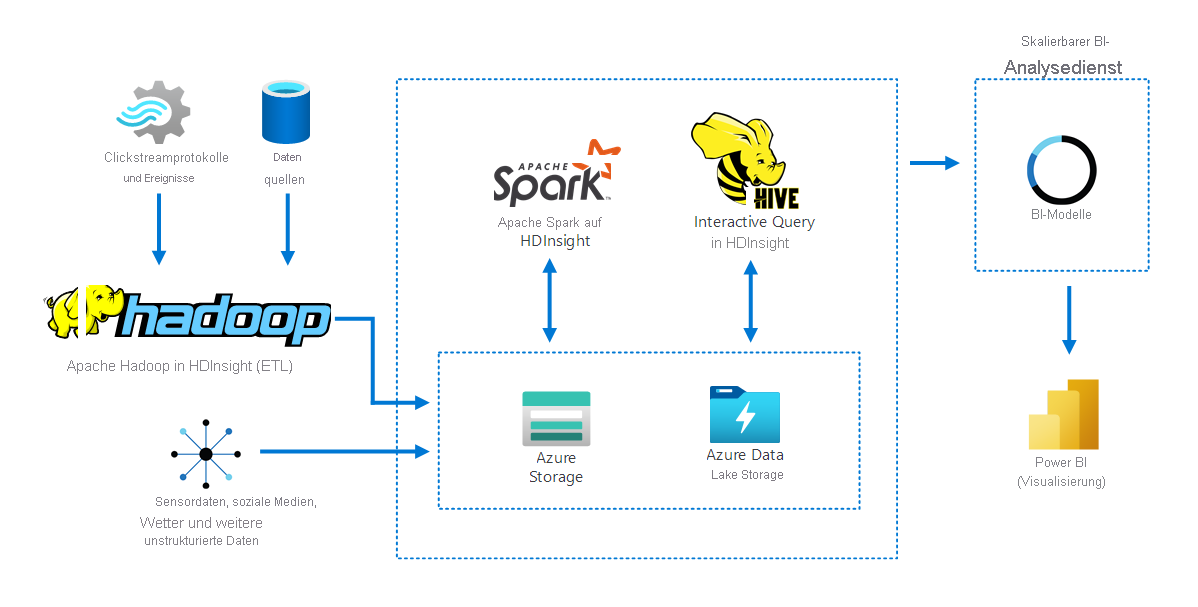
Komponenten dieses Szenarios:
- Apache Spark ist ein Framework für die Parallelverarbeitung und unterstützt In-Memory-Verarbeitung, um die Leistung von Anwendungen für die Big Data-Analyse zu steigern.
- Apache Hive in Azure HDInsight ist ein Data Warehouse-System für Apache Hadoop. Hive ermöglicht die Zusammenfassung, Abfrage und Analyse von Daten. Mit diesen Komponenten können Sie interaktive Abfragen für Petabytes von strukturierten oder unstrukturierten Daten in einem beliebigen Format durchführen.
Tipp
Hive-Abfragen werden in HiveQL geschrieben (eine SQL-ähnliche Abfragesprache).
Internet der Dinge (IoT)
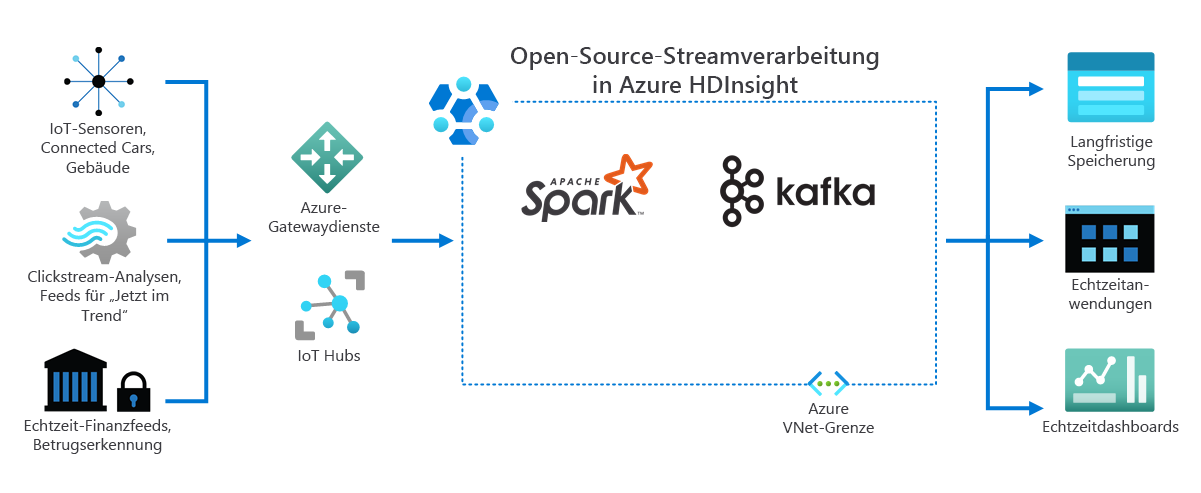
Wie das folgende Diagramm zeigt, verarbeitet HDInsight Streamingdaten, die in Echtzeit von verschiedenen Geräten und Sensoren empfangen werden. In diesem Beispiel stellen mehrere Open-Source-Frameworks eine Streamverarbeitung bereit, darunter Apache Spark und Apache Kafka.
Azure-Gatewaydienste und IoT-Hubs leiten die Daten aus verschiedenen Quellen an diese Frameworks weiter. Die Frameworks verarbeiten die Daten anschließend und übergeben sie an:
- Langfristige Speicherung
- Echtzeit-Apps
- Echtzeitdashboards
Data Science
Mithilfe von HDInsight können Sie gängige Data Science-Aufgaben durchführen, z. B.:
- Datenerfassung.
- Featureentwicklung
- Modellierung
- Modellauswertung
Das folgende Diagramm veranschaulicht ein Data Science-Szenario, in dem folgende Aufgaben erledigt werden:
- Die Daten werden mithilfe von Azure Data Factory aus einer lokalen Datenquelle erfasst.
- Die erfassten Daten werden dann im Azure-Speicher gespeichert (entweder Azure Blob Storage oder in einem Data Lake Store).
- Azure Spark in HDInsight verarbeitet die Daten und bereitet diese für Azure Machine Learning auf. Die Daten werden darüber hinaus mit Power BI visualisiert.

Hybrid
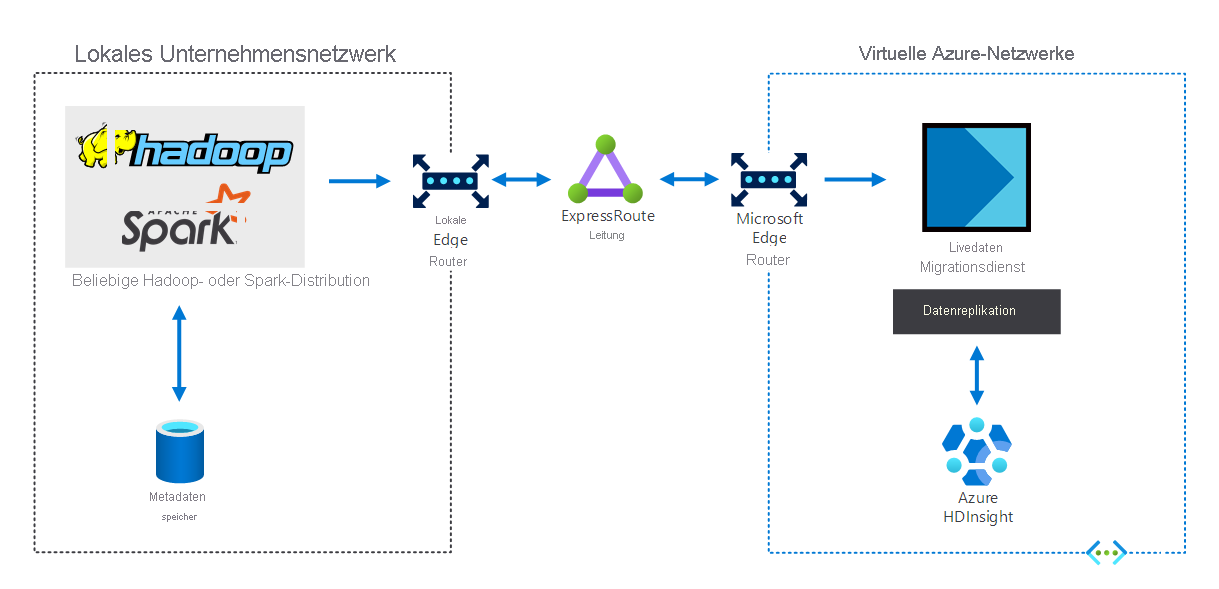
Organisationen, die über eine lokale Big Data-Infrastruktur verfügen, können HDInsight verwenden, um diese Infrastruktur auf Azure zu erweitern. So können die Vorteile der erweiterten Analysefunktionen der Azure-Cloud genutzt werden. Das folgende Diagramm zeigt das hybride Szenario, das folgende Eigenschaften aufweist:
- Die lokale Big Data-Infrastruktur besteht aus Metadatenspeichern und einer Hadoop- oder Spark-Verteilung auf lokalen VMs.
- Eine Azure ExpressRoute-Verbindung verbindet die lokale Unternehmensnetzwerkumgebung mit virtuellen Azure-Netzwerken.
- Ein Livedatenmigrator für Azure repliziert die von der lokalen Umgebung empfangenen Daten nach HDInsight.