Funktionsweise von Azure HDInsight
Hier erfahren Sie, wie Azure HDInsight funktioniert. Sie erfahren mehr über die folgenden Komponenten und wie diese zusammen eine Steuerung und Verwaltung der Daten ermöglichen:
- Apache Hadoop
- HDInsight-Speicher
- HDInsight-Verarbeitung
Was ist Apache Hadoop?
Apache Hadoop ist ein cloudverteiltes Datenverarbeitungssystem, das den Kern von HDInsight bildet. Es umfasst drei Komponenten, die in der folgenden Tabelle beschrieben werden:
| Apache Hadoop-Komponente | Beschreibung |
|---|---|
| HDFS | Apache Hadoop Distributed File System (HDFS) stellt den Speicher für das Hadoop-System zur Verfügung. |
| YARN | Die YARN-Komponente (Yet Another Resource Negotiator) von Apache Hadoop stellt die Verarbeitungsfunktionalität des Systems zur Verfügung. |
| MapReduce | MapReduce ist ein Programmiermodell, mit dem Sie Daten verarbeiten und analysieren können. |
Zusammenwirken der Komponenten
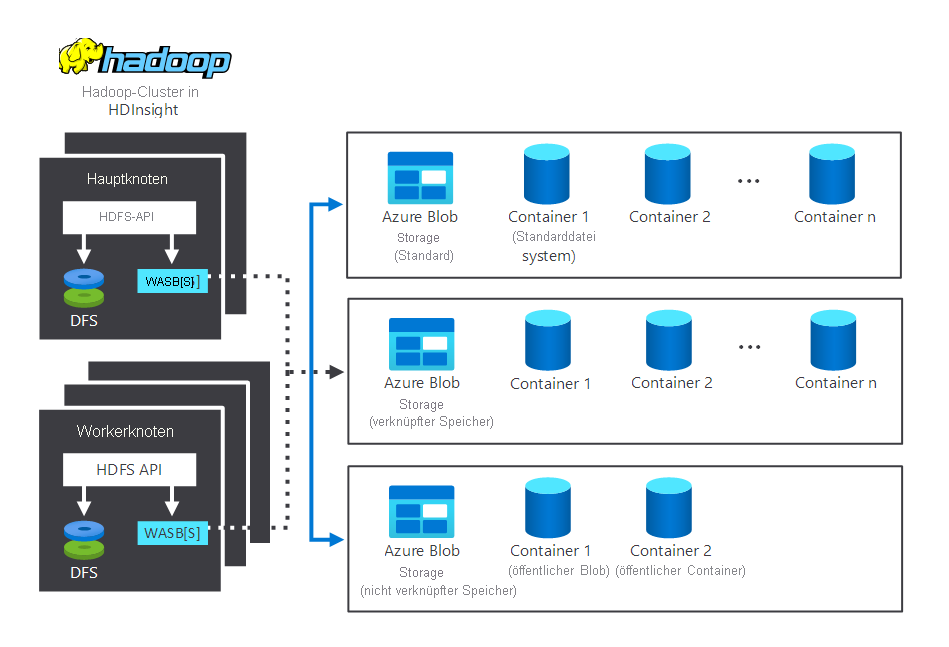
Das folgende Diagramm zeigt die Speicher- und Verarbeitungskomponenten, die in einem typischen HDInsight Hadoop-Cluster zusammenwirken. Es veranschaulicht die folgenden Komponenten:
- Hauptknoten und die Workerknoten, die die Verarbeitung durchführen.
- Mehrere WASB-Speichercenter (Windows Azure Storage Blob) in den Knoten. HDFS interagiert mit diesen Containern.
- Mehrere standardmäßige, verknüpfte und nicht verknüpfte Speichercontainer. Diese stehen beiden Knoten zur Verfügung.
Sehen wir uns nun an, wie Speicherung und Verarbeitung funktionieren.
Funktionsweise der Speicherung
Die Speicherkomponente eines Clusters wird nicht automatisch erstellt, wenn Sie einen HDInsight-Cluster bereitstellen. Stattdessen erfolgt die Bereitstellung über ein HDFS-kompatibles System wie Azure Storage oder Azure Data Lake.
Die Trennung der Speicherkomponente eines Clusters von der Verarbeitungskomponente bietet einige Vorteile. Sie können beispielsweise alle HDInsight-Cluster, die nur für Berechnungen verwendet werden, problemlos entfernen, ohne den Verlust von Daten befürchten zu müssen. Wenn Sie einen HDInsight-Cluster hinzufügen, müssen Sie ein Standarddateisystem definieren.
Wichtig
Für Azure Storage müssen Sie einen Blobcontainer als Standarddateisystem angeben.
Durch die Bereitstellung eines Standarddateisystems wird sichergestellt, dass HDInsight bei der Suche nach Dateien relative Dateiverweise auflösen kann.
Tipp
Wenn Sie den verfügbaren Speicher vergrößern möchten, können Sie je nach Bedarf weitere Dateisysteme verknüpfen. Sie können Verknüpfungen auch wieder rückgängig machen.

Funktionsweise der Verarbeitung
Bei der Verarbeitung von Daten wird die Computekomponente eines Hadoop-Clusters in HDInsight in zwei logische Bereiche unterteilt. Diese zwei Bereiche werden in der folgenden Tabelle beschrieben:
| Komponente | BESCHREIBUNG |
|---|---|
| Hauptknoten | Der Hauptknoten übernimmt und verwaltet Clientanforderungen und übergibt die Anforderungen an die Workerknoten. |
| Workerknoten | Die Workerknoten verarbeiten die Daten. |
Hinweis
Der Hauptknoten wird bisweilen als Masterknoten bezeichnet.
Die meisten Cluster enthalten zwei Hauptknoten:
- Ein aktiver Hauptknoten, der Clientverbindungen verwaltet.
- Ein passiver Hauptknoten, der Ausfallsicherheit bietet, falls der aktive Knoten offline geht.
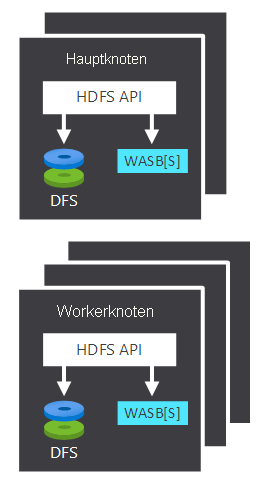
Sowohl Haupt- als auch Workerknoten können direkt mit einem lokal bereitgestellten HDFS verbunden sein oder auf Daten zugreifen, die in Azure Blob Storage oder-Azure Data Lake gespeichert sind. Welche Daten verwaltet werden, hängt von zwei Faktoren ab:
- Definition der Datenverarbeitung durch das MapReduce-Programmiermodell
- Arbeitszuteilung durch den Hauptknoten
Aufgabe von YARN
YARN erledigt die Ressourcenverwaltung in einem HDInsight-Cluster. Wenn Sie Daten verarbeiten, sorgt dieser Dienst für die Ressourcen- und Auftragsplanung.
YARN befindet sich zwischen dem HDFS und dem Berechnungssystem des HDInsight-Clusters, und arbeitet mit dem Hauptknoten zusammen, um einen Auftrag auf die Workerknoten des Clusters zu verteilen. Dadurch kann sichergestellt werden, dass die Datenverarbeitungsaufträge parallel ausgeführt werden.