Azure Data Lake Storage und Azure Blob Storage im Vergleich
In Azure Blob Storage können große Mengen unstrukturierter Daten (Objektdaten) in einem flachen Namespace in einem Blobcontainer gespeichert werden. Blobnamen können „/“-Zeichen enthalten, um Blobs in virtuellen „Ordnern“ zu organisieren, aber im Hinblick auf die Blobverwaltbarkeit werden die Blobs als Hierarchie in einer Ebene in einem flachen Namespace gespeichert.
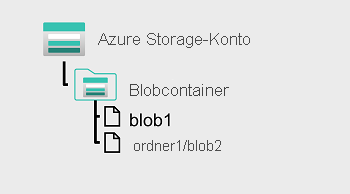
Der Zugriff auf diese Daten erfolgt mit HTTP oder HTTPS.
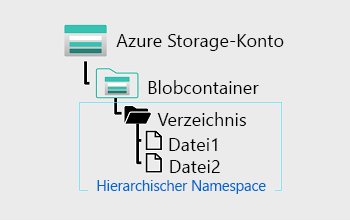
Azure Data Lake Storage Gen2 basiert auf Blobspeicher und optimiert die E/A von großen Datenmengen mithilfe eines hierarchischen Namespaces, der Blobdaten in Verzeichnissen organisiert und Metadaten zu jedem Verzeichnis und den darin enthaltenen Dateien speichert. Durch diese Struktur kann z.B. das Umbenennen oder Löschen von Verzeichnissen in einem einzigen Vorgang durchgeführt werden. Für flache Namespaces sind hingegen mehrere Vorgänge erforderlich, deren Anzahl von der Anzahl der Objekte in der Struktur abhängt. Da hierarchische Namespaces die Daten organisieren, bieten sie eine bessere Leistung beim Speichern und Abrufen der Daten für Analysen. Dadurch werden auch die Kosten verringert.
Tipp
Wenn Sie Daten speichern möchten, ohne diese zu analysieren, sollten Sie das Speicherkonto als Azure Blob Storage-Konto einrichten, indem Sie die Option Hierarchischer Namespace auf Deaktiviert festlegen. Sie können Blob Storage auch dazu verwenden, um selten verwendete Daten zu archivieren oder Website-Objekte wie Bilder und Medien zu speichern.
Wenn Sie die Daten analysieren, sollten Sie Azure Data Lake Storage Gen2 als Speicher verwenden, indem Sie Hierarchischer Namespace auf Aktiviert festlegen. Da Azure Data Lake Storage Gen2 in Azure Storage integriert ist, können Anwendungen entweder APIs von Blobs oder des Azure Data Lake Storage Gen2-Dateisystems für den Zugriff auf Daten verwenden.