Verwenden von Azure Data Lake Storage Gen2 in Datenanalyseworkloads
Azure Data Lake Store Gen2 ist eine Technologie, die mehrere Anwendungsfälle für die Datenanalyse ermöglicht. Wir betrachten nun einige gängige Arten von analytischen Workloads und ermitteln, wie Azure Data Lake Storage Gen2 mit anderen Azure-Diensten zusammenarbeitet, um sie zu unterstützen.
Verarbeitung und Analyse von Big Data
Big Data-Szenarien beziehen sich in der Regel auf analytische Workloads, die riesige Datenmengen in einer Vielzahl von Formaten umfassen, die mit hoher Geschwindigkeit verarbeitet werden müssen – die sogenannten „drei V“ (Volume (Datenmenge), Variety (Vielzahl), Velocity (Geschwindigkeit)). Azure Data Lake Storage Gen 2 bietet einen skalierbaren und sicheren verteilten Datenspeicher, in dem Big Data-Dienste wie Azure Synapse Analytics, Azure Databricks und Azure HDInsight Datenverarbeitungsframeworks wie Apache Spark, Hive und Hadoop anwenden können. Die Verteilung des Speichers und das Verarbeitungscompute ermöglichen die parallele Ausführung von Aufgaben, was auch bei der Verarbeitung großer Datenmengen hohe Leistung und Skalierbarkeit garantiert.
Data Warehousing
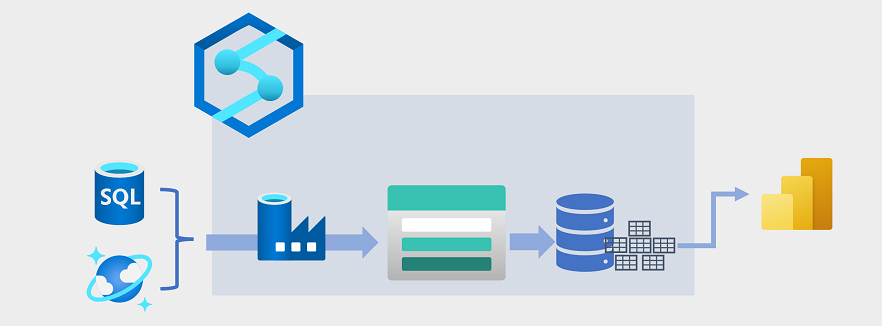
Data Warehousing hat sich in den letzten Jahren weiterentwickelt, um große Datenmengen, die als Dateien in einem Data Lake gespeichert sind, mit relationalen Tabellen in ein Data Warehouse zu integrieren. In einem typischen Beispiel für eine Data Warehousing-Lösung werden Daten aus operativen Datenspeichern wie Azure SQL-Datenbank oder Azure Cosmos DB extrahiert und in Strukturen transformiert, die für analytische Workloads besser geeignet sind. Häufig werden die Daten in einem Data Lake bereitgestellt, um die verteilte Verarbeitung zu erleichtern, bevor sie in ein relationales Data Warehouse geladen werden. In einigen Fällen verwendet das Data Warehouse externe Tabellen, um eine relationale Metadatenebene für Dateien im Data Lake zu definieren und eine Hybridarchitektur für „Data Lakehouse“ oder „Lake Database“ zu erstellen. Das Data Warehouse kann dann analytische Abfragen für Berichterstellung und Visualisierung unterstützen.
Es gibt mehrere Möglichkeiten, diese Art von Data Warehousing-Architektur zu implementieren. Das Diagramm zeigt eine Lösung, in der Azure Synapse Analytics Pipelines hostet, um ETL-Prozesse (Extrahieren, Transformieren und Laden) mit Azure Data Factory-Technologie auszuführen. Diese Prozesse extrahieren Daten aus operativen Datenquellen und laden sie in einen Data Lake, der in einem Azure Data Lake Storage Gen2-Container gehostet wird. Die Daten werden dann verarbeitet und in ein relationales Data Warehouse in einem dedizierten SQL-Pool von Azure Synapse Analytics geladen, um Datenvisualisierung und Berichterstellung mithilfe von Microsoft Power BI zu unterstützen.
Datenanalysen in Echtzeit
Unternehmen und andere Organisationen müssen permanente Datenströme erfassen und analysieren. Die Analyse muss in Echtzeit (oder so echtzeitnah wie möglich) erfolgen. Diese Datenströme können von verbundenen Geräten (häufig als Internet der Dinge- oder IoT-Geräte bezeichnet) oder aus Daten generiert werden, die von Benutzern in Social Media-Plattformen oder anderen Anwendungen generiert werden. Im Gegensatz zu herkömmlichen Batchverarbeitungsworkloads erfordert das Streaming von Daten eine Lösung, die einen grenzenlosen Strom von Datenereignissen erfassen und verarbeiten kann, während sie auftreten.
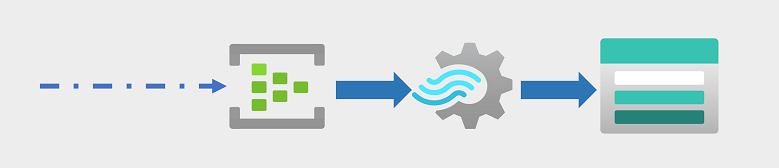
Streamingereignisse werden häufig zur Verarbeitung in einer Warteschlange erfasst. Es gibt mehrere Technologien, die Sie verwenden können, um diese Aufgabe auszuführen, einschließlich Azure Event Hubs, wie in der Abbildung dargestellt. Von hier aus werden die Daten verarbeitet, oft, um Daten über Zeitfenster zu aggregieren (z. B. um die Anzahl der Social Media-Nachrichten mit einem bestimmten Kennzeichen alle fünf Minuten zu zählen, oder um die durchschnittliche Messung eines mit dem Internet verbundenen Sensors pro Minute zu berechnen). Mit Azure Stream Analytics können Sie Aufträge erstellen, die Ereignisdaten beim Eingang abfragen und aggregieren und die Ergebnisse in eine Ausgabesenke schreiben. Eine solche Senke ist Azure Data Lake Storage Gen2, von wo aus die erfassten Echtzeitdaten analysiert und visualisiert werden können.
Data Science und maschinelles Lernen

Data Science umfasst die statistische Analyse großer Datenmengen, häufig mit Tools wie Apache Spark und Skriptsprachen wie Python. Azure Data Lake Storage Gen 2 bietet einen hochgradig skalierbaren cloudbasierten Datenspeicher für die für Data Science-Workloads erforderlichen Datenmengen.
Maschinelles Lernen ist ein Teilbereich von Data Science, in dem es um das Training von Vorhersagemodellen geht. Modelltraining erfordert große Datenmengen und die Fähigkeit, diese Daten effizient zu verarbeiten. Azure Machine Learning ist ein Clouddienst, in dem wissenschaftliche Fachkräfte für Daten Python-Code in Notebooks mithilfe dynamisch zugeordneter verteilter Computeressourcen ausführen können. Das Compute verarbeitet Daten in Azure Data Lake Storage Gen2-Containern, um Modelle zu trainieren, die dann als Produktionswebdienste bereitgestellt werden können, um Vorhersageanalyseworkloads zu unterstützen.