Grundlegendes zu Delta Lake
Delta Lake ist eine Open-Source-Speicherebene, die die Spark-basierte Data Lake-Verarbeitung um die Semantik relationaler Datenbanken erweitert. Tabellen in Microsoft Fabric-Lakehouses sind Deltatabellen, die durch das dreieckige Deltasymbol (▴) auf der Lakehouse-Benutzeroberfläche gekennzeichnet werden.
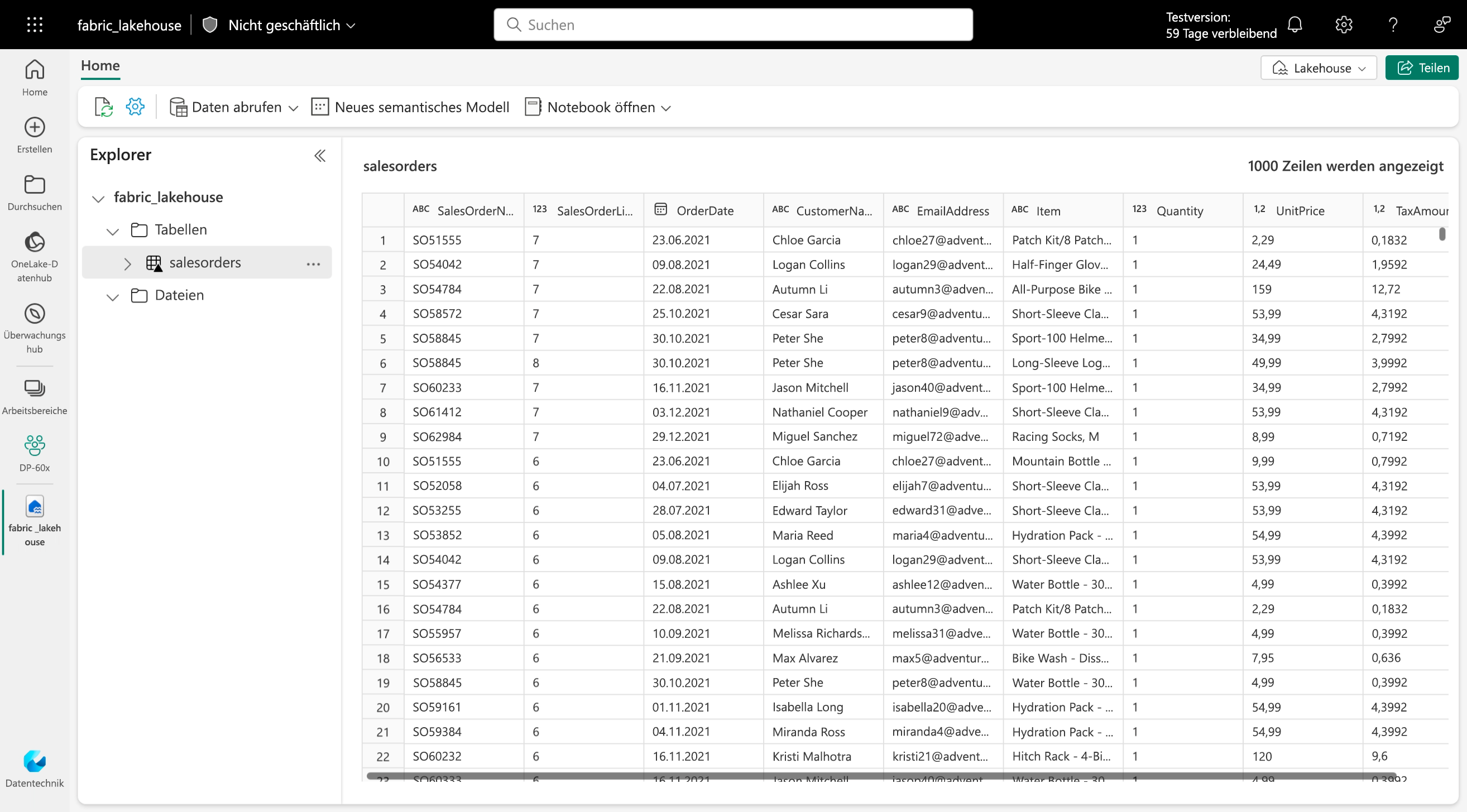
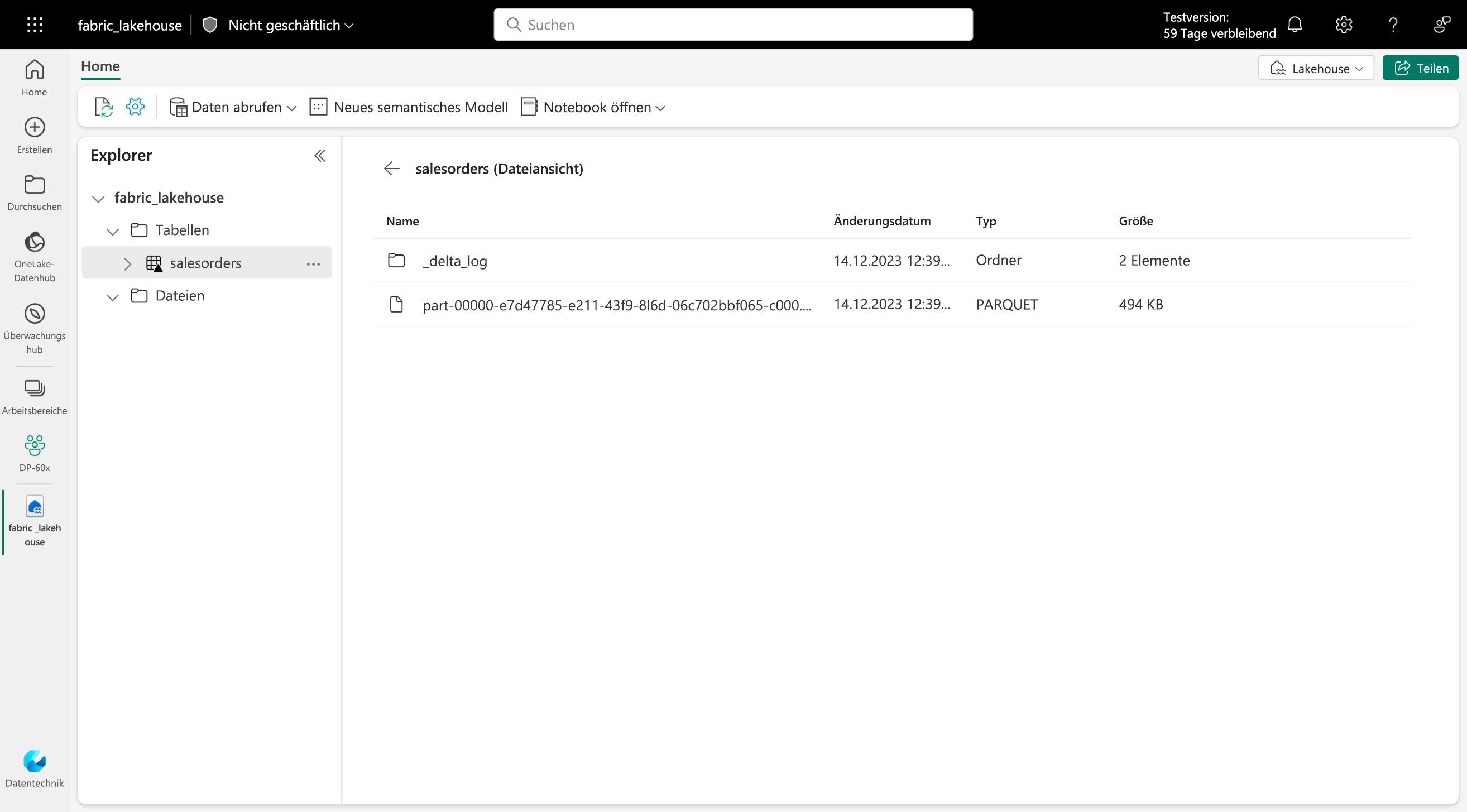
Deltatabellen sind Schemaabstraktionen für Datendateien, die im Deltaformat gespeichert sind. Für jede Tabelle legt das Lakehouse einen Ordner mit Parquet-Datendateien und einen Ordner namens _delta_Log an, in dem die Transaktionsdetails im JSON-Format protokolliert werden.
Die Verwendung von Deltatabellen hat unter anderem die folgenden Vorteile:
- Relationale Tabellen, die Abfrage- und Datenänderungen unterstützen. Mit Apache Spark können Sie Daten in Deltatabellen speichern, die CRUD-Vorgänge (Create, Read, Update, Delete; Erstellen, Lesen, Aktualisieren, Löschen) unterstützen. Mit anderen Worten: Sie können wie in einem relationalen Datenbanksystem Datenzeilen auswählen, einfügen, aktualisieren und löschen.
- Unterstützung für ACID-Transaktionen. Relationale Datenbanken sind darauf ausgelegt, Änderungen an Transaktionsdaten zu unterstützen, die Atomarität (Transaktionen werden als eine einzelne Arbeitseinheit abgeschlossen), Konsistenz (Transaktionen verlassen die Datenbank in einem konsistenten Zustand), Isolation (laufende Transaktionen können sich nicht gegenseitig beeinträchtigen) und Dauerhaftigkeit (wenn eine Transaktion abgeschlossen ist, werden die von ihr vorgenommenen Änderungen dauerhaft gespeichert) ermöglichen. Delta Lake bietet in Spark dieselbe Transaktionsunterstützung, indem ein Transaktionsprotokoll implementiert und eine serialisierbare Isolation für gleichzeitige Vorgänge erzwungen wird.
- Datenversionsverwaltung und Zeitreise. Da alle Transaktionen im Transaktionsprotokoll protokolliert werden, können Sie mehrere Versionen jeder Tabellenzeile nachverfolgen und sogar mithilfe des Features Zeitreise eine frühere Version einer Zeile in einer Abfrage abrufen.
- Unterstützung für Batch- und Streamingdaten. Während die meisten relationalen Datenbanken Tabellen mit statischen Daten enthalten, bietet Spark über die Spark Structured Streaming-API native Unterstützung für Streamingdaten. Delta Lake-Tabellen können sowohl als Senken (Ziele) als auch als Quellen für Streamingdaten dienen.
- Standardformate und Interoperabilität. Die zugrunde liegenden Daten für Deltatabellen sind im Parquet-Format gespeichert, das üblicherweise in Data Lake-Erfassungspipelines genutzt wird. Darüber hinaus können Sie den SQL-Analyseendpunkt für das Microsoft Fabric-Lakehouse verwenden, um Deltatabellen in SQL abzufragen.