Block-Clone-Vorgänge auf ReFS
Block-Clone-Vorgänge weisen das Dateisystem an, den Bytewert von Dateien im Namen einer Anwendung zu kopieren, bei der die Zieldatei entweder der Ausgangsdatei gleicht oder nicht. Herkömmliche Kopiervorgänge sind leider kostspielig, da sie in den zugrunde liegenden physischen Daten teure Lese- und Schreibvorgänge auslösen.
Block-Clone-Vorgänge auf ReFS führen jedoch Kopien als kostengünstige Metadatenvorgänge aus, anstatt Lese- und Schreibvorgänge auf Dateidaten durchzuführen. ReFS ermöglicht mehreren Dateien, die gleichen logischen Cluster (physische Speicherorte auf einem Datenträger) zu teilen, wodurch Kopiervorgänge nur einer Region der Datei auf einem separaten physischen Speicherort zugeordnet werden müssen und der teure, physische Vorgang zu einem schnellen logischen Vorgang konvertiert wird. Dadurch werden Kopien schneller erstellt und es wird weniger E/A im zugrunde liegenden Speicher generiert. Von dieser Verbesserung profitieren auch Virtualisierungs-Workloads, da die Zusammenführungsvorgänge für Prüfpunkte .vhdx bei der Verwendung von Block-Clone-Vorgängen erheblich beschleunigt werden. Da mehrere Dateien die gleichen logischen Cluster teilen können, werden identische Daten physisch nicht mehrmals gespeichert, was die Speicherkapazität verbessert.
Funktionsweise
Block-Clone-Vorgänge auf ReFS konvertieren eine Dateidatenoperation in einen Metadatenvorgang. Um diese Optimierung vorzunehmen, führt ReFS Referenzzähler in die Metadaten für die kopierten Regionen ein. Diese Referenzzähler zeichnen die Anzahl der eindeutigen Dateiregionen auf, die die gleichen physischen Regionen aufweisen. Dadurch können mehrere Dateien die gleichen physischen Daten gemeinsam nutzen:

Durch das Beibehalten der Referenzzähler für jeden logischen Cluster behält ReFS die Isolation zwischen Dateien bei: Schreibvorgänge auf freigegebene Regionen lösen einen Zuordnungsmechanismus der Schreibvorgänge aus, wobei ReFS dem eingehenden Schreibvorgang eine neue Region zuordnet. Dieser Mechanismus bewahrt die Integrität der freigegebenen logischen Cluster.
Beispiel
Angenommen, es gibt zwei Dateien: X und Y, wobei jede Datei aus drei Bereichen besteht und jede Region auf getrennte logische Cluster verweist.
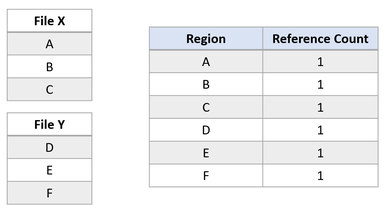
Angenommen eine Anwendung erteilt einen Block-Clone-Vorgang von Datei X für Datei Y, bei dem die Regionen A und B auf den Versatz von Bereich E kopiert werden. Dies würde folgenden Dateisystemstatus ergeben:
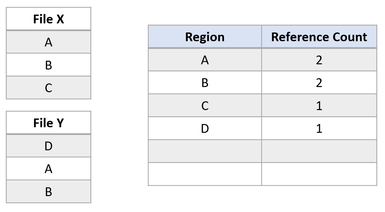
Dieser Dateisystemstatus zeigt eine erfolgreiche Duplizierung der Block-Clone-Region an. Da ReFS diesen Kopiervorgang nur beim Update von VCN- auf LCN-Zuordnungen durchführt, werden keine physischen Daten gelesen und die physischen Daten in der Datei Y werden nicht überschrieben. Datei X und Datei Y teilen jetzt logische Cluster, was durch die Referenzzähler in der Tabelle dargestellt wird. Da keine Daten physisch kopiert wurde, reduziert ReFS den Kapazitätsverbrauch auf dem Volume.
Nehmen wir nun an, die Anwendung versucht, Region A in Datei X zu überschreiben. ReFS dupliziert den freigegebenen Bereich, aktualisiert die Verweiszähler entsprechend und führt den eingehenden Schreibvorgang im neu duplizierten Bereich aus. Dadurch wird sichergestellt, dass die Isolation zwischen den Dateien beibehalten wird.
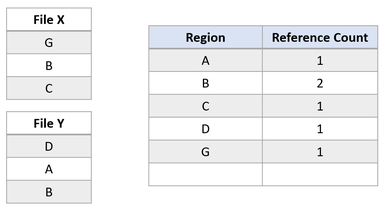
Nach dem Ändern des Schreibvorgangs wird Region B weiterhin von beide Dateien verwendet. Wäre Region A größer als ein Cluster, würde nur der geänderte Cluster dupliziert und der verbleibende Teil würde freigegeben.
Einschränkungen der Funktion und Hinweise
- Die Quell- und Zielregion muss an einer Cluster-Begrenzung beginnen und enden.
- Die geklonte Region muss kleiner sein als 4 GB.
- Die maximale Anzahl von Dateiregionen, die derselben physischen Region zugeordnet werden können, lautet 8175.
- Die Zielregion darf nicht über das Ende der Datei erweitert werden. Falls die Anwendung das Ziel mit geklonten Daten erweitern möchte, müssen sie zuerst SetEndOfFile aufrufen.
- Wenn sich die Quell- und Zielregionen in derselben Datei befinden, dürfen diese nicht überlappen. (Die Anwendung kann möglicherweise durch Aufteilen des Block-Clone-Vorgangs in mehrere Block-Clone-Vorgänge ausgeführt werden, wenn diese nicht überlappen).
- Die Quell- und Zieldateien müssen sich auf demselben Volume ReFS befinden.
- Die Quell- und Zieldateien müssen die gleichen Integrity Streams-Einstellungen aufweisen.
- Hat die Quelldatei eine geringe Datendichte, muss die Zieldatei ebenfalls eine geringe Datendichte aufweisen.
- Der Block-Clone-Vorgang durchbricht gemeinsam genutzte opportunistische Sperren (auch Opportunistische Sperren der Stufe 2 genannt).
- Das ReFS-Volume muss mit Windows Server 2016 formatiert worden sein, und wenn das Failoverclustering verwendet wird, muss die Clustering-Funktionsebene zum Zeitpunkt der Formatierung Windows Server 2016 oder höher sein.
- Ab Windows 11 24H2- und Windows Server 2025-Builds erfolgt das Klonen von Blöcken systemintern in unterstützten Windows-Kopiervorgängen.