ITextRange-Schnittstelle (tom.h)
Die ITextRange-Objekte sind leistungsstarke Bearbeitungs- und Datenbindungstools, mit denen ein Programm Text in einem Textabschnitt auswählen und diesen dann untersuchen oder ändern kann.
Vererbung
Die ITextRange-Schnittstelle erbt von der IDispatch-Schnittstelle . ITextRange verfügt auch über folgende Membertypen:
Methoden
Die ITextRange-Schnittstelle verfügt über diese Methoden.
|
ITextRange::CanEdit Bestimmt, ob der angegebene Bereich bearbeitet werden kann. |
|
ITextRange::CanPaste Bestimmt, ob ein Datenobjekt in einem angegebenen Format in den aktuellen Bereich eingefügt werden kann. |
|
ITextRange::ChangeCase Ändert die Groß-/Kleinschreibung von Buchstaben in diesem Bereich entsprechend dem Type-Parameter. |
|
ITextRange::Collapse Reduziert den angegebenen Textbereich in einen entarteten Punkt am Anfang oder Ende des Bereichs. |
|
ITextRange::Copy Kopiert den Text in ein Datenobjekt. |
|
ITextRange::Cut Schneidet den Nur- oder Rich-Text abhängig vom pVar-Parameter in ein Datenobjekt oder in die Zwischenablage. |
|
ITextRange::D elete Imitiert die ENTF- und RÜCKTASTEn mit und ohne gedrückte STRG-TASTE. |
|
ITextRange::EndOf Verschiebt die Enden dieses Bereichs an das Ende der letzten überlappenden Einheit im Bereich. |
|
ITextRange::Expand Erweitert diesen Bereich, sodass alle darin enthaltenen Teileinheiten vollständig enthalten sind. |
|
ITextRange::FindText Sucht bis zu Anzahl von Zeichen für den von bstr angegebenen Text. Die Startposition und Die Richtung werden ebenfalls durch Anzahl angegeben, und die Übereinstimmungskriterien werden durch Flags angegeben. |
|
ITextRange::FindTextEnd Sucht bis zu Anzahl von Zeichen für die Zeichenfolge bstr, beginnend mit end cp des Bereichs. |
|
ITextRange::FindTextStart Sucht bis zu Anzahl von Zeichen für die Zeichenfolge bstr, beginnend am Start cp (cpFirst) des Bereichs. |
|
ITextRange::GetChar Ruft das Zeichen an der Startposition des Bereichs ab. |
|
ITextRange::GetDuplicate Ruft ein Duplikat dieses Bereichsobjekts ab. |
|
ITextRange::GetEmbeddedObject Ruft einen Zeiger auf das eingebettete Objekt am Anfang des angegebenen Bereichs ab, d. h. auf cpFirst. Der Bereich muss entweder eine Einfügemarke sein oder nur das eingebettete Objekt auswählen. |
|
ITextRange::GetEnd Ruft die Endzeichenposition des Bereichs ab. |
|
ITextRange::GetFont Ruft ein ITextFont-Objekt mit den Zeichenattributen des angegebenen Bereichs ab. |
|
ITextRange::GetFormattedText Ruft ein ITextRange-Objekt mit dem formatierten Text des angegebenen Bereichs ab. |
|
ITextRange::GetIndex Ruft den Story-Index des Unit-Parameters an der angegebenen Startzeichenposition ab. |
|
ITextRange::GetPara Ruft ein ITextPara-Objekt mit den Absatzattributen des angegebenen Bereichs ab. |
|
ITextRange::GetPoint Ruft Bildschirmkoordinaten für die Position des Anfangs- oder Endzeichens im Textbereich zusammen mit der zeileninternen Position ab. |
|
ITextRange::GetStart Ruft die Anfangszeichenposition des Bereichs ab. |
|
ITextRange::GetStoryLength Ruft die Anzahl der Zeichen in der Geschichte des Bereichs ab. |
|
ITextRange::GetStoryType Rufen Sie den Typ der Geschichte des Bereichs ab. |
|
ITextRange::GetText Ruft den Nur-Text in diesem Bereich ab. Die Text-Eigenschaft ist die Standardeigenschaft der ITextRange-Schnittstelle. |
|
ITextRange::InRange Bestimmt, ob sich dieser Bereich innerhalb oder am gleichen Text wie ein angegebener Bereich befindet. |
|
ITextRange::InStory Bestimmt, ob die Story dieses Bereichs mit der Story eines angegebenen Bereichs identisch ist. |
|
ITextRange::IsEqual Bestimmt, ob dieser Bereich die gleichen Zeichenpositionen und die gleiche Geschichte wie die eines angegebenen Bereichs aufweist. |
|
ITextRange::Move Verschiebt die Einfügemarke um eine angegebene Anzahl von Einheiten vorwärts oder rückwärts. Wenn der Bereich nicht degeneriert ist, wird der Bereich je nach Anzahl auf eine Einfügemarke reduziert und dann verschoben. |
|
ITextRange::MoveEnd Verschiebt die Endposition des Bereichs. |
|
ITextRange::MoveEndUntil Verschiebt das Ende des Bereichs an die Zeichenposition des ersten gefundenen Zeichens, das sich in dem satz von Cset angegebenen Zeichen befindet, vorausgesetzt, dass das Zeichen unter Anzahl der Zeichen des Bereichsendes gefunden wird. |
|
ITextRange::MoveEndWhile Verschiebt das Ende des Bereichs entweder Count-Zeichen oder einfach über alle zusammenhängenden Zeichen, die in der durch Cset angegebenen Zeichenmenge gefunden werden, je nachdem, welcher Wert kleiner ist. |
|
ITextRange::MoveStart Verschiebt die Startposition des Bereichs um die angegebene Anzahl von Einheiten in die angegebene Richtung. |
|
ITextRange::MoveStartUntil Verschiebt die Startposition des Bereichs um die Position des ersten gefundenen Zeichens, das sich in der durch Cset angegebenen Zeichenmenge befindet, vorausgesetzt, dass das Zeichen unter Anzahl der Zeichen der Startposition gefunden wird. |
|
ITextRange::MoveStartWhile Verschiebt die Startposition des Bereichs entweder Anzahlzeichen oder einfach über alle zusammenhängenden Zeichen hinaus, die in dem durch Cset angegebenen Satz von Zeichen gefunden werden, je nachdem, welcher Wert kleiner ist. |
|
ITextRange::MoveUntil Sucht bis zu Anzahl von Zeichen für das erste Zeichen in dem von Cset angegebenen Zeichensatz. Wenn ein Zeichen gefunden wird, wird der Bereich bis zu diesem Punkt reduziert. Der Anfang der Suche und die Richtung werden ebenfalls durch Anzahl angegeben. |
|
ITextRange::MoveWhile Beginnt an einem angegebenen Ende eines Bereichs und sucht, während die Zeichen zu dem durch Cset angegebenen Satz gehören und die Anzahl der Zeichen kleiner oder gleich Anzahl ist. |
|
ITextRange::P aste Fügt Text aus einem angegebenen Datenobjekt ein. |
|
ITextRange::ScrollIntoView Scrollt den angegebenen Bereich in die Ansicht. |
|
ITextRange::Select Legt die Anfangs- und Endposition sowie die Storywerte der aktiven Auswahl auf die Werte dieses Bereichs fest. |
|
ITextRange::SetChar Legt das Zeichen an der Anfangsposition des Bereichs fest. |
|
ITextRange::SetEnd Legt die Endposition des Bereichs fest. |
|
ITextRange::SetFont Legt die Zeichenattribute dieses Bereichs auf die attribute des angegebenen ITextFont-Objekts fest. |
|
ITextRange::SetFormattedText Legt den formatierten Text dieses Bereichstexts auf den formatierten Text des angegebenen Bereichs fest. |
|
ITextRange::SetIndex Ändert diesen Bereich in die angegebene Einheit der Story. |
|
ITextRange::SetPara Legt die Absatzattribute dieses Bereichs auf die des angegebenen ITextPara-Objekts fest. |
|
ITextRange::SetPoint Ändert den Bereich basierend auf einem angegebenen Punkt um oder nach oben durch (abhängig von Extend) den Punkt (x, y), der gemäß Type ausgerichtet ist. |
|
ITextRange::SetRange Passt die Bereichsendpunkte an die angegebenen Werte an. |
|
ITextRange::SetStart Legt die Zeichenposition für den Anfang dieses Bereichs fest. |
|
ITextRange::SetText Legt den Text in diesem Bereich fest. |
|
ITextRange::StartOf Verschiebt den Bereichsende an den Anfang der ersten überlappenden Einheit im Bereich. |
Hinweise
Mehrere Textbereiche können aktiv sein und kooperativ an derselben Geschichte arbeiten und sich mit der Geschichte weiterentwickeln. Wenn beispielsweise ein Textbereich den angegebenen Text vor einem anderen Textbereich löscht, verfolgt dieser die Änderung nach. In diesem Sinne ähneln Textbereiche Microsoft Word Lesezeichen, die auch Bearbeitungsänderungen nachverfolgen. Textmarken können jedoch keinen Text bearbeiten, während Textbereiche dies können. Darüber hinaus können Sie mit Bereichen Text bearbeiten, ohne die Auswahl oder die Zwischenablage zu ändern, die beide für Endbenutzer von Nutzen sind. Die ITextSelection-Schnittstelle erbt von ITextRange und fügt einige UI-orientierte Methoden und Eigenschaften hinzu, wie im Abschnitt zu ITextSelection beschrieben.
Sie können einen Textbereich mithilfe von Methoden basierend auf Zeichenpositionen betrachten. Insbesondere zeichnet sich ein Textbereich durch Folgendes aus:
- Die erste Zeichenposition cpFirst, die auf eine Einfügemarke direkt vor dem ersten Zeichen (relativ zum Anfang der Geschichte) im Bereich zeigt.
- Die GrenzwertpositioncpLim, die auf eine Einfügemarke zeigt, die unmittelbar auf das letzte Zeichen im Bereich folgt.
In der folgenden Abbildung werden Zeichenpositionen durch die Zeilen dargestellt, die die Buchstaben trennen. Die entsprechenden Zeichenpositionswerte werden unter den Zeilen angegeben. Der Bereich, der bei cpFirst = 5 beginnt und mit cpLim = 7 endet, enthält das zweistellige Wort ist. Wenn diese Abbildung den vollständigen Text in einer Geschichte darstellt, beträgt die Länge der Geschichte 30.
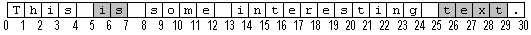 Die Länge eines Bereichs wird durch cpLim - cpFirst oder gleichwertig durch End – Start angegeben. Ein Bereich mit der Länge 0 (null) wird als degenerierter oder leerer Bereich bezeichnet und weist die gleichen cp*-Werte auf, d. h. cpFirst = cpLim. Ein Beispiel für einen degeneraten Bereich ist die aktuelle Einfügemarke. Eine Auswahl ungleich NULL ist ein Beispiel für einen nicht degeneraten Bereich.
Die Länge eines Bereichs wird durch cpLim - cpFirst oder gleichwertig durch End – Start angegeben. Ein Bereich mit der Länge 0 (null) wird als degenerierter oder leerer Bereich bezeichnet und weist die gleichen cp*-Werte auf, d. h. cpFirst = cpLim. Ein Beispiel für einen degeneraten Bereich ist die aktuelle Einfügemarke. Eine Auswahl ungleich NULL ist ein Beispiel für einen nicht degeneraten Bereich.
Angenommen, der durch schattierte Zellen in der vorherigen Abbildung angegebene Bereich von 5 bis 7 wird angewiesen, seinen Text zu löschen (siehe Löschen), wodurch er sich in eine Einfügemarke verwandelt. Der Bereich von 25 bis 29 würde automatisch seinen Inhalt nachverfolgen, nämlich das Wort text. In der folgenden Abbildung wird das Ergebnis veranschaulicht.
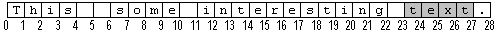 In dieser Abbildung wurde der Bereich für Text jetzt automatisch angepasst, um cpFirst = 23 und cpLim = 27 zu haben. Der Besitzer des Bereichs muss sich keine Gedanken über die Aktualisierung der Werte für die Position des Bereichszeichens im Angesicht der Bearbeitung machen.
In dieser Abbildung wurde der Bereich für Text jetzt automatisch angepasst, um cpFirst = 23 und cpLim = 27 zu haben. Der Besitzer des Bereichs muss sich keine Gedanken über die Aktualisierung der Werte für die Position des Bereichszeichens im Angesicht der Bearbeitung machen.
Die Namen der Move-Methoden geben an, welches Ende verschoben werden soll. Beachten Sie jedoch, dass beide Enden an die Zielposition verschoben werden, wenn eine Methode versucht, ein Bereichsende über das andere zu verschieben. Daher befindet sich die Einfügemarke an der Zielposition. Das Konzept ist, dass cpFirst und cpLim immer der grundlegenden Bedingung gehorchen müssen
0 <= cpFirst<= cpLim<= # characters in story
oder gleichwertig für einen Bereich r, 0 <= r. Start <= r. End <= r. StoryLength, was sie von den Namen dieser Mengen erwarten würden.
Ein weiteres wichtiges Merkmal ist, dass alle Geschichten am Ende einen nicht eleierbaren endgültigen CR-Charakter (0xD) enthalten. So hat auch eine leere Geschichte einen einzigen Charakter, nämlich den endgültigen CR. Ein Bereich kann dieses Zeichen auswählen, kann aber nicht zu einer Einfügemarke darüber hinaus werden. Um zu sehen, wie dies funktioniert, versuchen Sie, die endgültige CR in einem Word Dokument auszuwählen, und drücken Sie dann die NACH-RECHTS-TASTE, um sie zu reduzieren. Die Verzeichnisstruktur wird vor der endgültigen CR reduziert, aber die CR kann nicht gelöscht werden. Das Text Object Model (TOM) funktioniert genauso. Also, wenn r. Start <= r. Ende, dann r. End <= (r. StoryLength – 1). Eine Diskussion zum Löschen einer CR finden Sie unter Löschen.
Einige Methoden hängen von einem Unit-Argument ab, das die in der folgenden Tabelle aufgeführten vordefinierten Werte annehmen kann.
| Einheit | Wert | Bedeutung |
|---|---|---|
| tomCharacter | 1 | Zeichen |
| tomWord | 2 | Word. |
| tomSentence | 3 | Satz. |
| tomParagraph | 4 | Absatz. |
| tomLine | 5 | Zeile (angezeigt). |
| tomStory | 6 | Geschichte. |
| tomScreen | 7 | Bildschirm (wie für PAGE UP/PAGE DOWN). |
| tomSection | 8 | Abschnitt. |
| tomColumn | 9 | Tabellenspalte. |
| tomRow | 10 | Tabellenzeile. |
| tomWindow | 11 | Links oben oder rechts unten im Fenster. |
| tomCell | 12 | Tabellenzelle. |
| tomCharFormat | 13 | Ausführung konstanter Zeichenformatierung. |
| tomParaFormat | 14 | Ausführung konstanter Absatzformatierung. |
| tomTable | 15 | Tabelle. |
| tomObject | 16 | Eingebettetes Objekt. |
Die meisten Unit-Werte sind selbsterklärend. Die folgenden Beschreibungen werden jedoch zur weiteren Übersichtlichkeit bereitgestellt.
tomWord
Die TomWord-Konstante ist ein Ende des Absatzes oder eine Spanne von Alphanumerik oder Interpunktion, einschließlich der folgenden Leerzeichen. Um ein Bildschirmgefühl für tomWord zu erhalten, watch, wie sich das Caret bewegt, wenn Sie in einem Word Dokument STRG+NACH-RECHTS(—>) oder STRG+NACH-LINKS(<—) drücken.tomSentence
Die TomSentence-Konstante beschreibt eine Textzeichenfolge, die mit einem Punkt, Fragezeichen oder Ausrufezeichen endet und entweder von einem oder mehreren ASCII-Leerzeichen (9 bis 0xd und 0x20) oder dem Unicode-Absatztrennzeichen (0x2029) folgt. Der nachfolgende Leerraum ist Teil des Satzes. Der letzte Satz in einer Geschichte muss kein Punkt, Fragezeichen oder Ausrufezeichen aufweisen. Der Anfang einer Geschichte gilt als Beginn einer TomSentence, auch wenn die Zeichenfolge dort nicht grammatikalisch als Satz gilt. Andere Sätze müssen einem Satzende folgen und dürfen nicht mit einem Punkt, Fragezeichen oder Ausrufezeichen beginnen.tomParagraph
Die tomParagraph-Konstante ist eine Textzeichenfolge, die durch eine Absatzendemarke (CRLF, CR, VT (für UMSCHALT+EINGABETASTE), LF, FF oder 0x2029) beendet wird. TOM-Engines haben immer eine nicht löschbare Absatzendmarke am Ende einer Geschichte. Daher verfügen alle TOM-Geschichten automatisch über mindestens ein tomWord, eine tomSentence und einen tomParagraph.tomLine
Die tomLine-Konstante entspricht einer Textzeile auf einer Anzeige, sofern dem Bereich eine Anzeige zugeordnet ist. Wenn keine Anzeige einem Bereich zugeordnet ist, wird tomLine als tomParagraph behandelt. Eine Auswahl verfügt automatisch über eine Anzeige und einen Bereich, der ein Duplikat ist (siehe GetDuplicate). Andere Bereiche verfügen je nach TOM-Engine und Kontext möglicherweise nicht über eine Anzeige.Methoden, die ein oder beide Enden in Bezug auf Einheit verschieben, z. B . Move, MoveEnd und MoveStart, hängen vom vorzeichenden Count-Argument ab. Mit Ausnahme der geometrischen ITextSelection-Bewegungsbefehle werden die zu verschiebenden Enden nach vorne verschoben (gegen Ende der Geschichte), und wenn Count kleiner als null ist, werden die Enden nach hinten verschoben (zum Anfang). Der Standardwert von Count für diese Move-Methoden ist 1. Diese Methoden versuchen, Count Units zu verschieben, aber die Bewegung geht nie über die Enden der Geschichte hinaus.
Methoden, die ein oder beide Enden durch übereinstimmende Zeichenfolgen oder Zeichenfolgenmuster verschieben, z. B . MoveWhile, MoveEndWhile und MoveStartWhile, können bis zu einer maximalen Anzahl von Zeichen durch das argument Count mit Vorzeichen verschoben werden. Wenn Count größer als 0 ist, werden die zu verschiebenden Enden nach vorne verschoben, und wenn Count kleiner als 0 ist, werden die Enden nach hinten verschoben. Zwei spezielle Count-Werte , tomForward und tomBackward, werden definiert. Diese Werte erreichen garantiert das Ende bzw. den Anfang der Geschichte. Der Standardwert von Count ist tomForward.
In Move*-Methoden, die einen nicht entarteten Bereich in einen degenerierten Bereich umwandeln, z. B .MoveWhile und MoveUntil, wird cpFirst geändert, wenn Count negativ und cpLim geändert wird, wenn Count positiv ist. Nach dieser Bewegung wird auch das andere Ende des Bereichs an den neuen Standort verschoben. Genauere Count-Informationen finden Sie in den einzelnen Methoden. Für nicht entgenerierte Bereiche verschieben die Methoden MoveStart, MoveEnd, MoveStartWhile, MoveEndWhile, MoveStartUntil und MoveEndUntil entweder die Startposition (Start) oder die Endposition (Ende).
Verwenden Sie die MoveEnd-Methode , um eine Einheit auszuwählen, die einem zusammenhängenden Bereich entspricht, z. B. tomWord, tomSentence und tomParagraph. Um eine Einheit auszuwählen, die einem nicht zusammenhängenden Bereich entspricht, z. B. tomObject, verwenden Sie die EndOf-Methode , da das nächste Objekt ggf. nach substanziellem Zwischentext auftreten kann, wenn überhaupt. Um eine tomCell-Einheit auszuwählen, muss sich der Bereich innerhalb einer Tabelle befinden.
Es folgen Beispiele und weitere Erläuterungen der Argumente Count und Unit . Beachten Sie, dass TOM-Engines möglicherweise nicht alle Einheiten in der obigen Tabelle unterstützen. Rich-Bearbeitungssteuerelemente bieten beispielsweise nicht die Konzepte von Abschnitten, sondern geben E_NOTIMPL zurück, wenn tomSection angegeben wird. Wenn eine TOM-Engine jedoch eine Einheit unterstützt, verfügt sie über den in der Tabelle angegebenen Indexwert.
Anwendungen implementieren die ITextRange-Schnittstelle in der Regel nicht. Microsoft-Textlösungen, z. B. Rich-Edit-Steuerelemente, implementieren ITextRange als Teil ihrer TOM-Implementierung.
Anwendungen können einen ITextRange-Zeiger abrufen, indem sie die Range-Methode aufrufen.
Anforderungen
| Anforderung | Wert |
|---|---|
| Unterstützte Mindestversion (Client) | Windows Vista [nur Desktop-Apps] |
| Unterstützte Mindestversion (Server) | Windows Server 2003 [nur Desktop-Apps] |
| Zielplattform | Windows |
| Kopfzeile | tom.h |
Siehe auch
Konzept