Überlappende Schattenkarten
Kaskadierte Schattenkarten (Cascaded Shadow Maps, CSMs) sind die beste Methode, um einen der häufigsten Fehler mit Schatten zu bekämpfen: Perspektivaliasing. In diesem technischen Artikel, der davon ausgeht, dass der Leser mit der Schattenzuordnung vertraut ist, wird das Thema CSMs behandelt. Diese Parameter:
- erläutert die Komplexität von CSMs;
- gibt Details zu möglichen Varianten der CSM-Algorithmen;
- beschreibt die beiden am häufigsten verwendeten Filtertechniken: Prozentvernäherfilterung (Percentage Closer Filtering, PCF) und Filtern mit Varianzschattenkarten (VSMs);
- identifiziert und behebt einige der häufigen Fallstricke, die mit dem Hinzufügen von Filterung zu CSMs verbunden sind; Und
- zeigt, wie Sie CSMs direct3D 10 über Direct3D 11-Hardware zuordnen.
Der in diesem Artikel verwendete Code befindet sich im DirectX Software Development Kit (SDK) in den Beispielen CascadedShadowMaps11 und VarianceShadows11. Dieser Artikel erweist sich als äußerst nützlich, nachdem die im technischen Artikel Common Techniques to Improve Shadow Depth Maps (Common Techniques to Improve Shadow Depth Maps) beschriebenen Techniken implementiert wurden.
Kaskadierte Schattenkarten und Perspektivaliasing
Das Perspektivaliasing in einer Schattenkarte ist eines der am schwierigsten zu bewältigenden Probleme. Im technischen Artikel Common Techniques to Improve Shadow Depth Maps (Allgemeine Techniken zur Verbesserung von Schattentiefenkarten) werden Perspektivenaliasing beschrieben, und es werden einige Ansätze zum Beheben des Problems identifiziert. In der Praxis sind CSMs in der Regel die beste Lösung und werden häufig in modernen Spielen verwendet.
Das grundlegende Konzept von CSMs ist leicht zu verstehen. Verschiedene Bereiche des Kamera frustum erfordern Schattenkarten mit unterschiedlichen Auflösungen. Objekte, die dem Auge am nächsten liegen, erfordern eine höhere Auflösung als entfernte Objekte. Wenn sich das Auge sehr nahe an der Geometrie bewegt, können die Pixel, die dem Auge am nächsten sind, so viel Auflösung erfordern, dass selbst eine 4096 × 4096 Schattenkarte nicht ausreicht.
Die Grundidee von CSMs besteht darin, das Frustum in mehrere Frusta zu partitionieren. Für jedes Subfrustum wird eine Schattenkarte gerendert. der Pixelshader dann Stichproben aus der Karte, die der erforderlichen Auflösung am ehesten entsprechen (Abbildung 2).
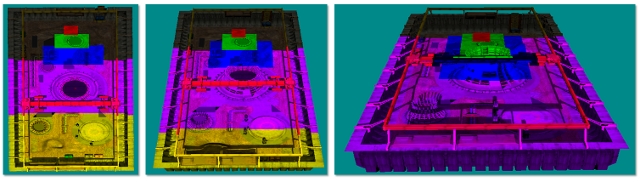
Abbildung 1. Abdeckung der Schattenkarte
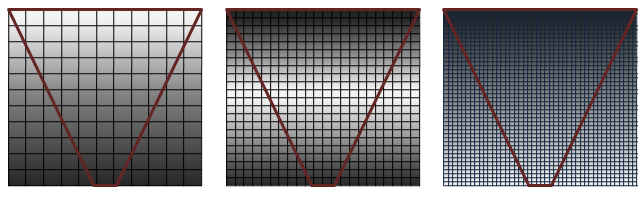
In Abbildung 1 wird die Qualität (von links nach rechts) vom höchsten zum niedrigsten angezeigt. Die Reihe von Rastern, die Schattenkarten mit einem Ansichts frustum (invertierter Kegel in Rot) darstellen, zeigt, wie die Pixelabdeckung mit verschiedenen Auflösungsschattenkarten beeinflusst wird. Schatten sind von höchster Qualität (weiße Pixel), wenn es ein 1:1-Verhältnis gibt, das Pixel im hellen Raum zu Texeln in der Schattenkarte zuordnen. Das Perspektivaliasing erfolgt in Form von großen blockigen Texturzuordnungen (linkes Bild), wenn zu viele Pixel demselben Schatten texel zugeordnet werden. Wenn die Schattenkarte zu groß ist, wird sie unter stichprobeniert. In diesem Fall werden Texel übersprungen, schimmernde Artefakte eingeführt, und die Leistung wird beeinträchtigt.
Abbildung 2. CSM-Schattenqualität
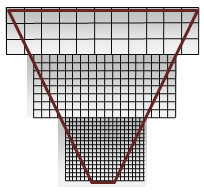
Abbildung 2 zeigt Ausschnitte aus dem Abschnitt mit der höchsten Qualität in jeder Schattenkarte in Abbildung 1. Die Schattenkarte mit den am engsten platzierten Pixeln (am Scheitelpunkt) ist dem Auge am nächsten. Technisch gesehen handelt es sich dabei um Karten der gleichen Größe, wobei Weiß und Grau verwendet werden, um den Erfolg der kaskadierten Schattenkarte zu verdeutlichen. Weiß ist ideal, da es eine gute Abdeckung zeigt – ein Verhältnis von 1:1 für Augenraumpixel und Schattenkarten-Texel.
CSMs erfordern die folgenden Schritte pro Frame.
Partitionieren Sie das Frustum in subfrusta.
Berechnen Sie eine orthografische Projektion für jedes Subfrustum.
Rendern sie eine Schattenzuordnung für jedes Subfrustum.
Rendern Sie die Szene.
Binden Sie die Schattenzuordnungen, und rendern Sie sie.
Der Vertex-Shader führt folgendes aus:
- Berechnet Texturkoordinaten für jedes Light-Subfrustum (es sei denn, die erforderliche Texturkoordinate wird im Pixelshader berechnet).
- Transformiert und beleuchtet den Scheitelpunkt usw.
Der Pixelshader führt folgendes aus:
- Bestimmt die richtige Schattenzuordnung.
- Transformiert die Texturkoordinaten bei Bedarf.
- Beispiele für die Kaskade.
- Leuchtet das Pixel.
Partitionieren von Frustum
Die Partitionierung des Frustums ist der Akt der Erstellung von Subfrusta. Eine Technik zum Teilen des Frustums besteht darin, Intervalle von null Prozent bis 10 Prozent in Z-Richtung zu berechnen. Jedes Intervall stellt dann eine nahe Ebene und eine weit entfernte Ebene als Prozentsatz der Z-Achse dar.
Abbildung 3. Anzeigen einer willkürlichen Partitionierung von Frustums
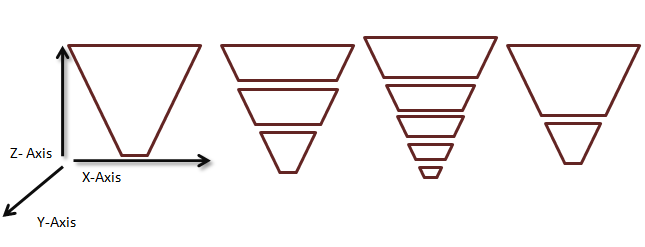
In der Praxis führt die Neuberechnung der Frustumteilungen pro Frame dazu, dass Schattenränder schimmern. Die allgemein akzeptierte Praxis besteht darin, einen statischen Satz von kaskadierenden Intervallen pro Szenario zu verwenden. In diesem Szenario wird das Intervall entlang der Z-Achse verwendet, um ein Subfrustum zu beschreiben, das beim Partitionieren des Frustums auftritt. Die Bestimmung der richtigen Größenintervalle für eine bestimmte Szene hängt von mehreren Faktoren ab.
Ausrichtung der Szenengeometrie
In Bezug auf die Szenengeometrie wirkt sich die Kameraausrichtung auf die Auswahl des kaskadierten Intervalls aus. Beispielsweise verfügt eine Kamera sehr nahe am Boden, z. B. eine Bodenkamera in einem Fußballspiel, über einen anderen statischen Satz von Kaskadenintervallen als eine Kamera am Himmel.
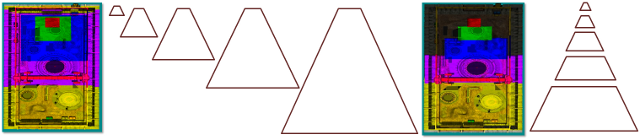
Abbildung 4 zeigt einige verschiedene Kameras und deren jeweilige Trennwände. Wenn der Z-Bereich der Szene sehr groß ist, sind mehr geteilte Ebenen erforderlich. Wenn sich das Auge beispielsweise sehr nahe der Bodenebene befindet, entfernte Objekte jedoch noch sichtbar sind, können mehrere Kaskaden erforderlich sein. Das Teilen des Frustums, sodass sich mehr Splits in der Nähe des Auges befinden (wo sich das Perspektivaliasing am schnellsten ändert), ist ebenfalls wertvoll. Wenn der größte Teil der Geometrie in einen kleinen Abschnitt (z. B. eine Overheadansicht oder einen Flugsimulator) des Ansichts frustums eingeklumpt ist, sind weniger Kaskaden erforderlich.
Abbildung 4. Unterschiedliche Konfigurationen erfordern unterschiedliche Frustumteilungen
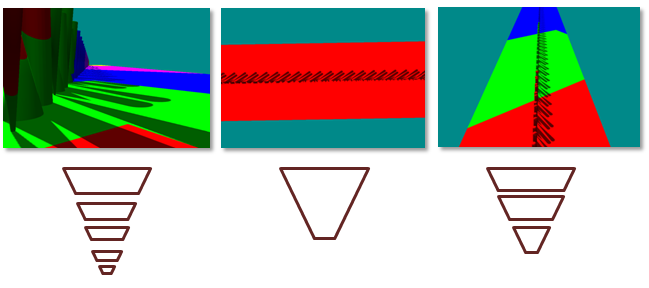
(Links) Wenn geometry einen hohen dynamischen Bereich in Z aufweist, sind viele Kaskaden erforderlich. (Mitte) Wenn die Geometrie in Z einen geringen dynamischen Bereich aufweist, ist der Vorteil mehrerer Frustums gering. (Rechts) Wenn der dynamische Bereich mittel ist, werden nur drei Partitionen benötigt.
Ausrichtung des Lichts und der Kamera
Die Projektionsmatrix jeder Kaskade ist eng um das entsprechende Subfrustum angepasst. In Konfigurationen, bei denen die Ansichtskamera und die Lichtrichtungen orthogonal sind, können die Kaskaden eng mit wenig Überlappung angepasst werden. Die Überlappung wird größer, wenn das Licht und die Ansichtskamera parallel ausgerichtet werden (Abbildung 5). Wenn das Licht und die Anzeigekamera nahezu parallel sind, wird es als "Duett frusta" bezeichnet und ist ein sehr schwieriges Szenario für die meisten Schattenalgorithmen. Es ist nicht ungewöhnlich, das Licht und die Kamera so einzuschränken, dass dieses Szenario nicht auftritt. CSMs funktionieren in diesem Szenario jedoch viel besser als viele andere Algorithmen.
Abbildung 5. Kaskadierende Überlappung nimmt zu, wenn die Lichtrichtung parallel zur Kamerarichtung wird
Viele CSM-Implementierungen verwenden frusta mit fester Größe. Der Pixelshader kann die Z-Tiefe verwenden, um in das Array von Kaskaden zu indizieren, wenn das Frustum in Intervallen mit fester Größe aufgeteilt wird.
Berechnen einer View-Frustum gebundenen
Nachdem die Frustum-Intervalle ausgewählt wurden, werden die Unterfrusta mit einer von zwei erstellt: An Szene anpassen und an Kaskadierung anpassen.
An Szene anpassen
Alle Frusta-Elemente können mit der gleichen Naheebene erstellt werden. Dies erzwingt, dass sich die Kaskaden überlappen. Im CascadedShadowMaps11-Beispiel wird diese Technik als "szenentauglich" bezeichnet.
An Cascade anpassen
Alternativ kann Frusta mit dem tatsächlichen Partitionsintervall erstellt werden, das als Nah- und Fernebene verwendet wird. Dies führt zu einer engeren Passform, verkommt aber im Falle von Frusta-Duellen zu einer Szene. In den CascadedShadowMaps11-Beispielen wird dieses Verfahren für kaskadierende Verfahren aufgerufen.
Diese beiden Methoden sind in Abbildung 6 dargestellt. Anpassung an kaskadierende Abfälle weniger Auflösung. Das Problem bei der Kaskadenpassung besteht darin, dass die orthographische Projektion basierend auf der Ausrichtung des Ansichts frustums wächst und verkleinert wird. Die Anpassung an die Szenentechnik polstert die orthografische Projektion durch die maximale Größe des Ansichts frustums, wodurch die Artefakte entfernt werden, die angezeigt werden, wenn sich die Ansichtskamera bewegt. Commons Techniques to Improve Shadow Depth Maps befasst sich mit den Artefakten, die angezeigt werden, wenn sich das Licht im Abschnitt "Bewegen des Lichts in texelgroßen Schritten" befindet.
Abbildung 6. An Szene anpassen im Vergleich zum Anpassen an Kaskade
Rendern der Schattenkarte
Das CascadedShadowMaps11-Beispiel rendert die Schattenkarten in einem großen Puffer. Dies liegt daran, dass PCF in Texturarrays ein Direct3D 10.1-Feature ist. Für jede Kaskade wird ein Viewport erstellt, der den Abschnitt des Tiefenpuffers abdeckt, der dieser Kaskade entspricht. Ein NULL-Pixel-Shader ist gebunden, da nur die Tiefe benötigt wird. Schließlich werden der richtige Viewport und die Schattenmatrix für jede Kaskade festgelegt, da die Tiefenzuordnungen einzeln in den Standard Schattenpuffer gerendert werden.
Rendern der Szene
Der Puffer, der die Schatten enthält, ist jetzt an den Pixelshader gebunden. Es gibt zwei Methoden zum Auswählen der im CascadedShadowMaps11-Beispiel implementierten Kaskade. Diese beiden Methoden werden mit Shadercode erläutert.
Interval-Based Kaskadierende Auswahl
Abbildung 7. Intervallbasierte Kaskadenauswahl

Bei der intervallbasierten Auswahl (Abbildung 7) berechnet der Vertex-Shader die Position im Weltraum des Scheitelpunkts.
Output.vDepth = mul( Input.vPosition, m_mWorldView ).z;
Der Pixelshader empfängt die interpolierte Tiefe.
fCurrentPixelDepth = Input.vDepth;
Bei der intervallbasierten Kaskadenauswahl werden ein Vektorvergleich und ein Punktprodukt verwendet, um die richtige Kakade zu bestimmen. Die CASCADE_COUNT_FLAG gibt die Anzahl der Kaskaden an. Die m_fCascadeFrustumsEyeSpaceDepths_data schränkt die Frustumpartitionen der Ansicht ein. Nach dem Vergleich enthält der fComparison den Wert 1, wobei das aktuelle Pixel größer als die Barriere ist, und den Wert 0, wenn die aktuelle Kaskade kleiner ist. Ein Punktprodukt summiert diese Werte in einen Arrayindex.
float4 vCurrentPixelDepth = Input.vDepth;
float4 fComparison = ( vCurrentPixelDepth > m_fCascadeFrustumsEyeSpaceDepths_data[0]);
float fIndex = dot(
float4( CASCADE_COUNT_FLAG > 0,
CASCADE_COUNT_FLAG > 1,
CASCADE_COUNT_FLAG > 2,
CASCADE_COUNT_FLAG > 3)
, fComparison );
fIndex = min( fIndex, CASCADE_COUNT_FLAG );
iCurrentCascadeIndex = (int)fIndex;
Nachdem die Kaskade ausgewählt wurde, muss die Texturkoordinate in die richtige Kaskade transformiert werden.
vShadowTexCoord = mul( InterpolatedPosition, m_mShadow[iCascadeIndex] );
Diese Texturkoordinate wird dann verwendet, um die Textur mit der X-Koordinate und der Y-Koordinate zu testen. Die Z-Koordinate wird verwendet, um den endgültigen Tiefenvergleich durchzuführen.
Map-Based Kaskadierende Auswahl
Die kartenbasierte Auswahl (Abbildung 8) testet die vier Seiten der Kaskaden, um die engste Karte zu finden, die das jeweilige Pixel abdeckt. Anstatt die Position im Weltraum zu berechnen, berechnet der Vertex-Shader die Position des Ansichtsraums für jede Kaskade. Der Pixelshader durchläuft die Kaskaden, um die Texturkoordinaten zu skalieren und zu verschieben, sodass sie die aktuelle Kaskade indizieren. Die Texturkoordinate wird dann anhand der Texturgrenzen getestet. Wenn die X- und Y-Werte der Texturkoordinate in eine Kaskade fallen, werden sie verwendet, um die Textur zu probieren. Die Z-Koordinate wird verwendet, um den endgültigen Tiefenvergleich durchzuführen.
Abbildung 8. Kartenbasierte Kaskadenauswahl

Interval-Based-Auswahl im Vergleich zur Map-Based-Auswahl
Die intervallbasierte Auswahl ist etwas schneller als die kartenbasierte Auswahl, da die kaskadierende Auswahl direkt erfolgen kann. Die kartenbasierte Auswahl muss die Texturkoordinate mit den Kaskadengrenzen überschneiden.
Bei der kartenbasierten Auswahl wird die Kaskade effizienter verwendet, wenn Schattenkarten nicht perfekt ausgerichtet sind (siehe Abbildung 8).
Vermischung zwischen Kaskaden
VSMs (weiter unten in diesem Artikel erläutert) und Filtertechniken wie PCF können mit CSMs mit niedriger Auflösung verwendet werden, um weiche Schatten zu erzeugen. Leider führt dies zu einer sichtbaren Naht (Abbildung 9) zwischen kaskadierten Ebenen, da die Auflösung nicht übereinstimmt. Die Lösung besteht darin, ein Band zwischen Schattenkarten zu erstellen, in dem der Schattentest für beide Kaskaden durchgeführt wird. Der Shader interpoliert dann linear zwischen den beiden Werten basierend auf der Position des Pixels im Blendband. Die Beispiele CascadedShadowMaps11 und VarianceShadows11 stellen einen GUI-Schieberegler bereit, der zum Vergrößern und Verringern dieses Weichzeichnerbands verwendet werden kann. Der Shader führt einen dynamischen Branch aus, sodass die überwiegende Mehrheit der Pixel nur aus der aktuellen Kaskade liest.
Abbildung 9. Kaskadierende Nähte

(Links) Eine sichtbare Naht ist zu sehen, wo sich Kaskaden überlappen. (Rechts) Wenn die Kaskaden gemischt werden, tritt keine Naht auf.
Filtern von Schattenzuordnungen
PCF
Das Filtern gewöhnlicher Schattenkarten erzeugt keine weichen, verschwommenen Schatten. Die Filterhardware weicht die Tiefenwerte und vergleicht diese verschwommenen Werte dann mit dem Lichtraum texel. Die harte Kante, die sich aus dem Pass/Fail-Test ergibt, ist weiterhin vorhanden. Verschwommene Schattenkarten dienen nur dazu, die harte Kante fälschlicherweise zu verschieben. PCF ermöglicht das Filtern nach Schattenkarten. Die allgemeine Idee von PCF besteht darin, einen Prozentsatz des Pixels im Schatten basierend auf der Anzahl der Teilsamples zu berechnen, die den Tiefentest über die Gesamtzahl der Teilsamples bestehen.
Direct3D 10- und Direct3D 11-Hardware kann PCF ausführen. Die Eingabe für einen PCF-Sampler besteht aus der Texturkoordinate und einem Vergleichstiefewert. Der Einfachheit halber wird PCF mit einem Vier-Tippen-Filter erklärt. Der Textursampleser liest die Textur viermal, ähnlich wie bei einem Standardfilter. Das zurückgegebene Ergebnis ist jedoch ein Prozentsatz der Pixel, die den Tiefentest bestanden haben. Abbildung 10 zeigt, wie ein Pixel, das einen der vier Tiefentests besteht, 25 Prozent im Schatten hat. Der tatsächliche Wert, der zurückgegeben wird, ist eine lineare Interpolation, die auf den Subtexelkoordinaten der gelesenen Textur basiert, um einen glatten Farbverlauf zu erzeugen. Ohne diese lineare Interpolation könnte die PCF mit vier Taps nur fünf Werte zurückgeben: { 0.0, 0.25, 0.5, 0.75, 1.0 }.
Abbildung 10. PCF-gefiltertes Bild, wobei 25 Prozent des ausgewählten Pixels abgedeckt sind
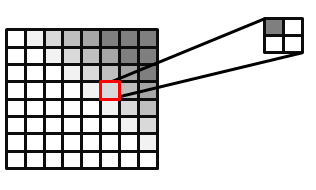
Es ist auch möglich, PCF ohne Hardwareunterstützung zu tun oder PCF auf größere Kernels zu erweitern. Einige Techniken verwenden sogar Stichproben mit einem gewichteten Kernel. Erstellen Sie hierzu einen Kernel (z. B. einen Gaußschen) für ein N × N-Raster. Die Gewichtungen müssen bis zu 1 addiert werden. Die Textur wird dann N2-mal abgetastet. Jedes Beispiel wird durch die entsprechenden Gewichtungen im Kernel skaliert. Im CascadedShadowMaps11-Beispiel wird dieser Ansatz verwendet.
Tiefenausrichtung
Tiefenverzerrung wird noch wichtiger, wenn große PCF-Kernel verwendet werden. Es ist nur gültig, die Lichtraumtiefe eines Pixels mit dem Pixel zu vergleichen, dem es in der Tiefenkarte zugeordnet ist. Die Nachbarn der Tiefenkarte texels verweisen auf eine andere Position. Diese Tiefe ist wahrscheinlich ähnlich, kann aber je nach Szene sehr unterschiedlich sein. Abbildung 11 zeigt die auftretenden Artefakte. Eine einzelne Tiefe wird mit drei benachbarten Texeln in der Schattenkarte verglichen. Einer der Tiefentests schlägt fälschlicherweise fehl, da seine Tiefe nicht mit der berechneten Lichtraumtiefe der aktuellen Geometrie korreliert. Die empfohlene Lösung für dieses Problem ist die Verwendung eines größeren Offsets. Ein zu großer Offset kann jedoch zu Peter Panning führen. Das Berechnen einer engen Nah- und Fernebene trägt dazu bei, die Auswirkungen der Verwendung eines Offsets zu reduzieren.
Abbildung 11. Fehlerhafte Selbstschattierung
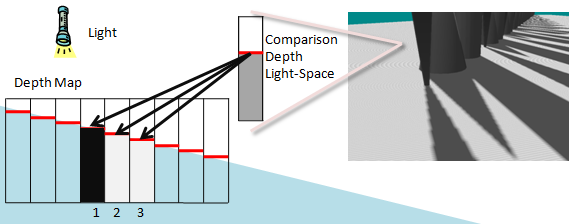
Die fehlerhafte Selbstschattierung ergibt sich aus dem Vergleich von Pixeln in der Lichtraumtiefe mit den Texeln in der Schattenkarte, die nicht korrelieren. Die Tiefe im Lichtraum korreliert mit Schatten texel 2 in der Tiefenkarte. Texel 1 ist größer als die Lichtraumtiefe, während 2 gleich und 3 kleiner ist. Texels 2 und 3 bestehen den Tiefentest, während Texel 1 fehlschlägt.
Berechnen einer Per-Texel Tiefenverzerrung mit DDX und DDY für große PCFs
Das Berechnen einer Tiefenverzerrung pro Texel mit ddx und ddy für große PCFs ist eine Technik, die die richtige Tiefenabweichung berechnet – vorausgesetzt, die Oberfläche ist planar – für das angrenzende Schattenkarten-Texel.
Diese Technik passt die Vergleichstiefe unter Verwendung der abgeleiteten Informationen auf eine Ebene an. Da diese Technik rechenintensiv ist, sollte sie nur verwendet werden, wenn eine GPU über Computezyklen verfügt. Wenn sehr große Kernels verwendet werden, ist dies möglicherweise die einzige Technik, die funktioniert, um Artefakte mit selbstschattendem Schatten zu entfernen, ohne Peter Panning zu verursachen.
Abbildung 12 zeigt das Problem. Die Tiefe im Lichtraum ist bekannt für den texel, der verglichen wird. Die Lichtraumtiefen, die den benachbarten Texeln in der Tiefenkarte entsprechen, sind unbekannt.
Abbildung 12: Szenen- und Tiefenkarte

Die gerenderte Szene wird links angezeigt, und die Tiefenkarte mit einem Beispiel-Texelblock wird rechts angezeigt. Der Blickraum texel wird dem Pixel mit der Bezeichnung D in der Mitte des Blocks zugeordnet. Dieser Vergleich ist genau. Die richtige Tiefe im Augenbereich, die mit den Pixeln korreliert, deren Nachbar D unbekannt ist. Das Zuordnen der benachbarten Texel zum Blickbereich ist nur möglich, wenn wir davon ausgehen, dass das Pixel dasselbe Dreieck wie D betrifft.
Die Tiefe ist bekannt für das Texel, das mit der Licht-Raum-Position korreliert. Die Tiefe ist für die benachbarten Texel in der Tiefenkarte unbekannt.
Auf hoher Ebene verwendet diese Technik die ddx- und ddy-HLSL-Vorgänge, um die Ableitung der Lichtraumposition zu ermitteln. Dies ist nichttrivial, da die abgeleiteten Vorgänge den Farbverlauf der Lichtraumtiefe in Bezug auf den Bildschirmraum zurückgeben. Um dies in einen Farbverlauf der Lichtraumtiefe in Bezug auf den Lichtraum umzuwandeln, muss eine Konvertierungsmatrix berechnet werden.
Erklärung mit Shadercode
Die Details des restlichen Algorithmus werden als Erklärung des Shadercodes angegeben, der diesen Vorgang ausführt. Dieser Code befindet sich im CascadedShadowMaps11-Beispiel. Abbildung 13 zeigt, wie die Koordinaten der Lichtraumtextur der Tiefenkarte zugeordnet werden und wie die Ableitungen in X und Y verwendet werden können, um eine Transformationsmatrix zu erstellen.
Abbildung 13: Matrix zwischen Bildschirmraum und Lichtraum
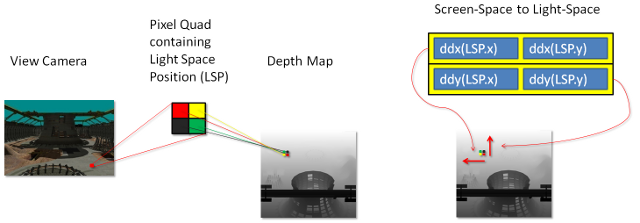
Die Ableitungen der Lichtraumposition in X und Y werden verwendet, um diese Matrix zu erstellen.
Der erste Schritt besteht darin, die Ableitung der Licht-Sicht-Raum-Position zu berechnen.
float3 vShadowTexDDX = ddx (vShadowMapTextureCoordViewSpace);
float3 vShadowTexDDY = ddy (vShadowMapTextureCoordViewSpace);
Direct3D 11-Klassen-GPUs berechnen diese Ableitungen, indem sie 2 × 2 Quad pixel parallel ausführen und die Texturkoordinaten vom Nachbarn in X für ddx und vom Nachbarn in Y für ddy subtrahieren. Diese beiden Ableitungen bilden die Zeilen einer Matrix von 2 × 2. In ihrer aktuellen Form könnte diese Matrix verwendet werden, um benachbarte Pixel im Bildschirmbereich in Lichtraumneigungen zu konvertieren. Die Umkehrung dieser Matrix ist jedoch erforderlich. Eine Matrix, die benachbarte Lichtraumpixel in Bildschirmraumneigungen transformiert, ist erforderlich.
float2x2 matScreentoShadow = float2x2( vShadowTexDDX.xy, vShadowTexDDY.xy );
float fInvDeterminant = 1.0f / fDeterminant;
float2x2 matShadowToScreen = float2x2 (
matScreentoShadow._22 * fInvDeterminant,
matScreentoShadow._12 * -fInvDeterminant,
matScreentoShadow._21 * -fInvDeterminant,
matScreentoShadow._11 * fInvDeterminant );
Abbildung 14. Lichtraum zum Bildschirmbereich

Diese Matrix wird dann verwendet, um die beiden Texel oberhalb und rechts vom aktuellen Texel zu transformieren. Diese Nachbarn werden als Offset vom aktuellen Texel dargestellt.
float2 vRightShadowTexelLocation = float2( m_fTexelSize, 0.0f );
float2 vUpShadowTexelLocation = float2( 0.0f, m_fTexelSize );
float2 vRightTexelDepthRatio = mul( vRightShadowTexelLocation,
matShadowToScreen );
float2 vUpTexelDepthRatio = mul( vUpShadowTexelLocation,
matShadowToScreen );
Das von der Matrix erstellte Verhältnis wird schließlich mit den Tiefenableitungen multipliziert, um die Tiefenoffsets für die benachbarten Pixel zu berechnen.
float fUpTexelDepthDelta =
vUpTexelDepthRatio.x * vShadowTexDDX.z
+ vUpTexelDepthRatio.y * vShadowTexDDY.z;
float fRightTexelDepthDelta =
vRightTexelDepthRatio.x * vShadowTexDDX.z
+ vRightTexelDepthRatio.y * vShadowTexDDY.z;
Diese Gewichtungen können jetzt in einer PCF-Schleife verwendet werden, um der Position einen Offset hinzuzufügen.
for( int x = m_iPCFBlurForLoopStart; x < m_iPCFBlurForLoopEnd; ++x )
{
for( int y = m_iPCFBlurForLoopStart; y < m_iPCFBlurForLoopEnd; ++y )
{
if ( USE_DERIVATIVES_FOR_DEPTH_OFFSET_FLAG )
{
depthcompare += fRightTexelDepthDelta * ( (float) x ) +
fUpTexelDepthDelta * ( (float) y );
}
// Compare the transformed pixel depth to the depth read
// from the map.
fPercentLit += g_txShadow.SampleCmpLevelZero( g_samShadow,
float2(
vShadowTexCoord.x + ( ( (float) x ) * m_fNativeTexelSizeInX ) ,
vShadowTexCoord.y + ( ( (float) y ) * m_fTexelSize )
),
depthcompare
);
}
}
PCF und CSMs
PCF funktioniert nicht für Texturarrays in Direct3D 10. Um PCF zu verwenden, werden alle Kaskaden in einem großen Texturatlas gespeichert.
Derivative-Based Offset
Das Hinzufügen der auf Derivat basierenden Offsets für CSMs stellt einige Herausforderungen dar. Dies ist auf eine abgeleitete Berechnung innerhalb einer divergenten Strömungssteuerung zurückzuführen. Das Problem tritt aufgrund einer grundlegenden Art und Weise auf, wie GPUs funktionieren. Direct3D11-GPUs arbeiten mit 2 × 2 Quads von Pixeln. Um eine Ableitung durchzuführen, subtrahieren GPUs im Allgemeinen die Kopie einer Variablen des aktuellen Pixels von der Kopie derselben Variablen des benachbarten Pixels. Die Vorgehensweise variiert von GPU zu GPU. Die Texturkoordinaten werden durch kartenbasierte oder intervallbasierte Kaskadenauswahl bestimmt. Einige Pixel in einem Pixelquad quad wählen eine andere Kaskade als die restlichen Pixel aus. Dies führt zu sichtbaren Nähten zwischen Schattenkarten, da die derivatbasierten Offsets jetzt völlig falsch sind. Die Lösung besteht darin, die Ableitung auf Lichtansichtstexturkoordinaten durchzuführen. Diese Koordinaten sind für jede Kaskade identisch.
Auffüllung für PCF-Kernel
PCF-Kernel indexieren außerhalb einer kaskadierten Partition, wenn der Schattenpuffer nicht aufgefüllt ist. Die Lösung besteht darin, den äußeren Rand der Kaskade um die Hälfte der Größe des PCF-Kernels zu polstern. Dies muss im Shader implementiert werden, der die Kaskade auswählt, und in der Projektionsmatrix, die die Kaskade so groß rendern muss, dass der Rahmen beibehalten wird.
Varianzschattenzuordnungen
VSMs (weitere Informationen finden Sie unter Varianzschattenkarten von Donnelly und Lauritzen) aktivieren die direkte Schattenzuordnungsfilterung. Bei verwendung von VSMs kann die gesamte Leistungsfähigkeit der Texturfilterhardware genutzt werden. Es können trilineare und anisotrope Filter (Abbildung 15) verwendet werden. Darüber hinaus können VSMs direkt durch Konvolution verschwommen werden. VSMs haben einige Nachteile. Zwei Kanäle mit Tiefendaten müssen gespeichert werden (Tiefe und Tiefe quadratisch). Wenn sich Schatten überlappen, ist lichtblutend. Sie funktionieren jedoch gut mit niedrigeren Auflösungen und können mit CSMs kombiniert werden.
Abbildung 15. Anisotrope Filterung

Algorithmusdetails
VSMs arbeiten, indem die Tiefe und die Tiefe quadratisch zu einer Zweikanal-Schattenkarte gerendert werden. Diese zweikanalige Schattenkarte kann dann wie eine normale Textur verschwommen und gefiltert werden. Der Algorithmus verwendet dann Chebychevs Ungleichheit im Pixelshader, um den Anteil der Pixelfläche zu schätzen, der den Tiefentest bestehen würde.
Der Pixelshader ruft die Tiefen- und Tiefenquadratwerte ab.
float fAvgZ = mapDepth.x; // Filtered z
float fAvgZ2 = mapDepth.y; // Filtered z-squared
Der Tiefenvergleich wird durchgeführt.
if ( fDepth <= fAvgZ )
{
fPercentLit = 1;
}
Wenn der Tiefenvergleich fehlschlägt, wird der Prozentsatz des Leuchtpixels geschätzt. Die Varianz wird als Mittelwert von Quadraten minus quadratischem Mittelwert berechnet.
float variance = ( fAvgZ2 ) − ( fAvgZ * fAvgZ );
variance = min( 1.0f, max( 0.0f, variance + 0.00001f ) );
Der Wert fPercentLit wird mit Chebychevs Ungleichheit geschätzt.
float mean = fAvgZ;
float d = fDepth - mean;
float fPercentLit = variance / ( variance + d*d );
Lichtbluten
Der größte Nachteil von VSMs ist leichte Blutungen (Abbildung 16). Lichtblutungen treten auf, wenn sich mehrere Schattenrollen entlang der Kanten verschließen. VSMs schattieren die Schattenränder basierend auf Tiefenunterschieden. Wenn sich Schatten überlappen, besteht ein Tiefengefälle in der Mitte eines Bereichs, der schattiert werden soll. Dies ist ein Problem bei der Verwendung des VSM-Algorithmus.
Abbildung 16. VSM-Lichtblutung

Eine Teillösung für das Problem besteht darin, das fPercentLit auf eine Leistung zu erhöhen. Dies hat den Effekt, dass die Unschärfe gedämpft wird, was zu Artefakten führen kann, bei denen die Tiefenunterschiede gering sind. Manchmal gibt es einen magischen Wert, der das Problem lindert.
fPercentLit = pow( p_max, MAGIC_NUMBER );
Eine Alternative zum Erhöhen des Leuchtprozentwerts auf eine Leistung besteht darin, Konfigurationen zu vermeiden, bei denen sich Schatten überlappen. Selbst stark abgestimmte Schattenkonfigurationen haben mehrere Einschränkungen für Licht, Kamera und Geometrie. Leichte Blutungen werden auch durch die Verwendung von Texturen mit höherer Auflösung verringert.
Layered Variance Shadow Maps (LVSMs) lösen das Problem auf Kosten des Zerbrechens des Frustums in Ebenen, die senkrecht zum Licht sind. Die Anzahl der erforderlichen Zuordnungen wäre recht groß, wenn auch CSMs verwendet werden.
Darüber hinaus diskutierte Andrew Lauritzen, Co-Autor des Artikels zu VSMs und Autor eines Artikels über LVSMs, die Kombination exponentieller Schattenkarten (ESMs) mit VSMs, um der Lichtmischung in einem Beyond3D-Forum entgegenzuwirken.
VSMs mit CSMs
Das Beispiel VarianceShadow11 kombiniert VSMs und CSMs. Die Kombination ist ziemlich einfach. Das Beispiel folgt denselben Schritten wie im CascadedShadowMaps11-Beispiel. Da PCF nicht verwendet wird, werden die Schatten in einer zweistufigen trennbaren Konvolution verschwommen. Ohne PCF kann das Beispiel auch Texturarrays anstelle eines Texturatlas verwenden. PCF für Texturarrays ist ein Direct3D 10.1-Feature.
Farbverläufe mit CSMs
Die Verwendung von Farbverläufen mit CSMs kann eine Naht entlang der Grenze zwischen zwei Kaskaden erzeugen, wie in Abbildung 17 dargestellt. Die Beispielanweisung verwendet Ableitungen zwischen Pixeln, um Informationen zu berechnen, z. B. die Mipmap-Ebene, die vom Filter benötigt wird. Dies verursacht insbesondere bei der Mipmap-Auswahl oder der anisotropen Filterung ein Problem. Wenn Pixel in einem Quad verschiedene Verzweigungen im Shader aufweisen, sind die von der GPU-Hardware berechneten Ableitungen ungültig. Dies führt zu einer zerklüfteten Naht entlang der Schattenkarte.
Abbildung 17. Nähte an Kaskadenrändern durch anisotrope Filterung mit abweichender Strömungssteuerung

Dieses Problem wird gelöst, indem die Ableitungen auf die Position im Lichtblickraum berechnen; Die Lichtansichtsraumkoordinate ist nicht spezifisch für die ausgewählte Kaskade. Die berechneten Ableitungen können durch den Skalierungsteil der Projektionstexturmatrix auf die richtige Mipmap-Ebene skaliert werden.
float3 vShadowTexCoordDDX = ddx( vShadowMapTextureCoordViewSpace );
vShadowTexCoordDDX *= m_vCascadeScale[iCascade].xyz;
float3 vShadowTexCoordDDY = ddy( vShadowMapTextureCoordViewSpace );
vShadowTexCoordDDY *= m_vCascadeScale[iCascade].xyz;
mapDepth += g_txShadow.SampleGrad( g_samShadow, vShadowTexCoord.xyz,
vShadowTexCoordDDX, vShadowTexCoordDDY );
VSMs im Vergleich zu Standardschatten mit PCF
Sowohl VSMs als auch PCF versuchen, den Anteil der Pixelfläche zu nähern, der den Tiefentest bestehen würde. VSMs arbeiten mit Filterhardware und können mit trennbaren Kernels verschwommen werden. Trennbare Faltungskerne sind in der Implementierung erheblich billiger als ein vollständiger Kernel. Darüber hinaus vergleichen VSMs eine Lichtraumtiefe mit einem Wert in der Lichtraum-Tiefenkarte. Dies bedeutet, dass VSMs nicht die gleichen Offsetprobleme wie PCF haben. Technisch gesehen sind VSMs die Stichprobentiefe über einen größeren Bereich und führen eine statistische Analyse durch. Dies ist weniger präzise als PCF. In der Praxis leisten VSMs eine sehr gute Arbeit beim Mischen, was dazu führt, dass weniger Offset erforderlich ist. Wie oben beschrieben, ist der größte Nachteil von VSMs leichte Blutungen.
VSMs und PCF stellen einen Kompromiss zwischen GPU-Computeleistung und GPU-Texturbandbreite dar. VSMs erfordern weitere Berechnungen, um die Varianz zu berechnen. PCF erfordert mehr Texturspeicherbandbreite. Große PCF-Kernels können durch texturierte Bandbreite schnell eng werden. Da die GPU-Berechnungsleistung schneller wächst als die GPU-Bandbreite, werden VSMs die praktischere der beiden Algorithmen. VSMs sehen auch mit Schattenkarten mit niedrigerer Auflösung aufgrund von Blending und Filterung besser aus.
Zusammenfassung
CSMs bieten eine Lösung für das Perspektivaliasingproblem. Es gibt mehrere mögliche Konfigurationen, um die erforderliche visuelle Genauigkeit für einen Titel zu erhalten. PCF und VSMs werden häufig verwendet und sollten mit CSMs kombiniert werden, um aliasing zu reduzieren.
Referenzen
Donnelly, W. und Lauritzen, A. Variance Schattenkarten. In SI3D '06: Proceedings of the 2006 symposium on Interactive 3D graphics and games. 2006. S. 161–165. New York, NY, USA: ACM Press.
Lauritzen, Andrew und McCool, Michael. Mehrschichtige Varianzschattenkarten. Proceedings of graphics interface 2008, 28.–30. Mai 2008, Windsor, Ontario, Kanada.
Engel, Woflgang F. Abschnitt 4. Kaskadierte Schattenkarten. ShaderX5 , Advanced Rendering Techniques, Wolfgang F. Engel, Ed. Charles River Media, Boston, Massachusetts. 2006. S. 197–206.