Azure AI Bot Service
An Azure service that provides an integrated environment for bot development.
779 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ES%3C/text%3E%3C/svg%3E)
I want to create a webpage with a conversational 2D AI avatar using cognitive services with custom portrait image. Is it possible with Azure ?
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EYM%3C/text%3E%3C/svg%3E)
Hello @SpandanB
Thanks for reaching out to us, I think you want to do a AI avatar which will act the conversation? Is this correct?
If yes, you can connect the two APIs to accomplish the target - Azure OpenAI and Azure Speech.
For conversational, the first part will be a chat bot, which you can leverage Language Service or OpenAI Service.
For Avatar, you can consider Text to Speech feature.
If yes, please check on below document about how to make a "conversational" avatar, it can be 3D or 2D.- https://techcommunity.microsoft.com/t5/ai-azure-ai-services-blog/azure-ai-speech-announces-public-preview-of-text-to-speech/ba-p/3981448
What is text to speech avatar?
The text to speech avatar system is a text to speech feature with vision capabilities, that allow customers to create synthetic videos of a 2D photorealistic avatar speaking. The Neural text to speech Avatar models are trained by deep neural networks based on the human video recording samples, and the voice of the avatar is provided by text to speech voice model.
Why do we build avatars? There are two main reasons:
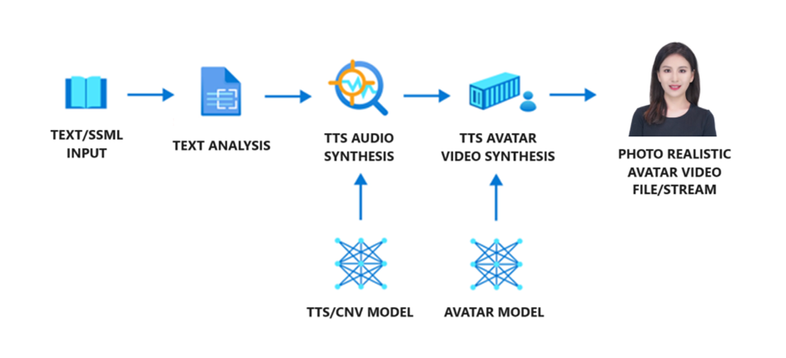
There are three components in an avatar content generation workflow: text analyzer, the TTS audio synthesizer, and TTS avatar video synthesizer. To generate avatar video, text is first input into the text analyzer, which provides the output in the form of phoneme sequence. Then, the TTS audio synthesizer predicts the acoustic features of the input text and synthesize the voice. These two parts are provided by text to speech voice models. Next, the Neural text to speech Avatar model predicts the image of lip sync with the acoustic features, so that the synthetic video is generated.
Below is an overview of the workflow:
Please take a look and have a try, I hope this helps.
Regards,
Yutong
-Please kindly accept the answer if you feel helpful to support the community, thanks a lot.