Azure Data Factory
An Azure service for ingesting, preparing, and transforming data at scale.
10,566 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERN%3C/text%3E%3C/svg%3E)
Greetings:
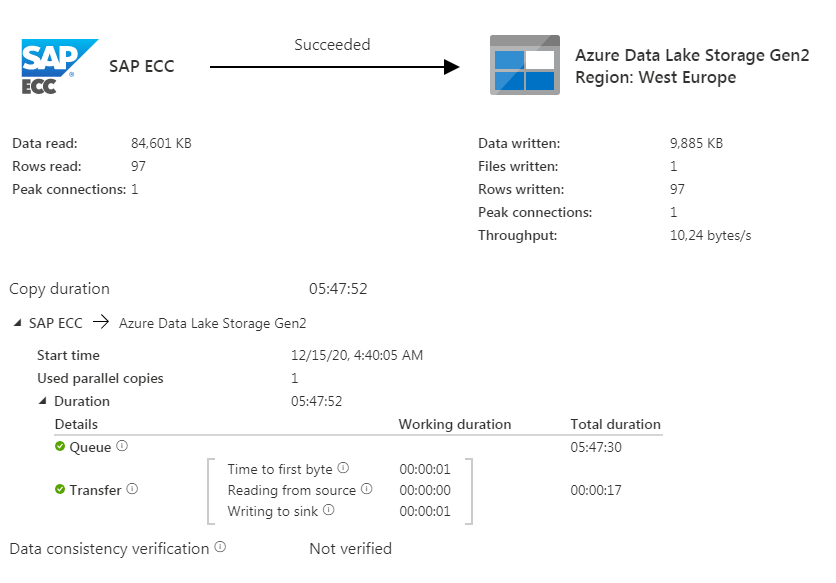
It happens occasionally, "copy data" activity gets stucked in "Queue" state for a long time. I send an example.
What can I do to troubleshoot it? Is there a solution?
Thank you.
Regards.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hi @Rubén Souto ,
Welcome to Microsoft Q&A Platform. Thanks for posting the query. I looked at similar issues from customers and observed that one of the below reasons can be a root cause for the issue.
If above changes did not help in resolving the issue, please share report id along with pipeline run id with us. In the integration runtime configuration manager, please click on diagnostics icon, reproduce the error and then click on ‘Send logs’. Please share report id with us to enable viewing logs.

Ref: issue
Looking forward for your response!
Thank you very much, i'll try the solutions and let you know.
Hi @Rubén Souto ,
We have not received a response from you. Are you still facing the issue? If you found a solution, would you please share it here with the community? Otherwise, let us know above details and we will continue to engage with you on the issue.
Increasing the value of "Limit Concurrent Jobs" from 6 to 10 initially reduced a lot the number of cases, but last 2 days it's getting worse. Should I increase it more? I'm not sure about the performance issues this action could trigger.
FYI we are running around 180 "copy data" activities with SAP ECC connector every night. We use a "foreach" activity, allowing up to 3 parallel runs.

So I believe you are right pointing to a concurrency issue, but... apparently the settings are right.
Now I'm gonna update IR, activate Logging function and let you know.
Thank you very much.
Thanks @Rubén Souto for sharing the update. As per the document, when the processor and available RAM aren't well utilized, but the execution of concurrent jobs reaches a node's limits, scale up by increasing the number of concurrent jobs that a node can run. If the node capacity also exceeds i.e., when issue persists after increasing the limit, then scale-out approach as suggested i.e., to increase nodes is preferred.
Looking forward for your update on the issue!
Hi @Rubén Souto ,
We have not received a response from you. Please suggest if above shared details are helpful. Otherwise, let us know and we will continue to engage with you on the query.
Hi @Rubén Souto ,
We still have not heard back from you. Following up to check if above shared details are helpful. Otherwise, let us know and we will continue to engage with you on the query.