Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,045 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ERK%3C/text%3E%3C/svg%3E)
Hi,
I have a headerless file which I am reading in the spark.read to create a data frame now I want to get the value of the 5th column from the file.File is comma seperated. How to achieve it. I know it is possible in the T-SQL but not sure how to achieve it in Spark SQL.
Example of the file
myname,1/4/1977,xyz,50,60
Now I want to get the value of 60.
Regards
Rajaniesh
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello Rajaniesh ,
The below piece of code should do the trick . Please do let me know how it goes .
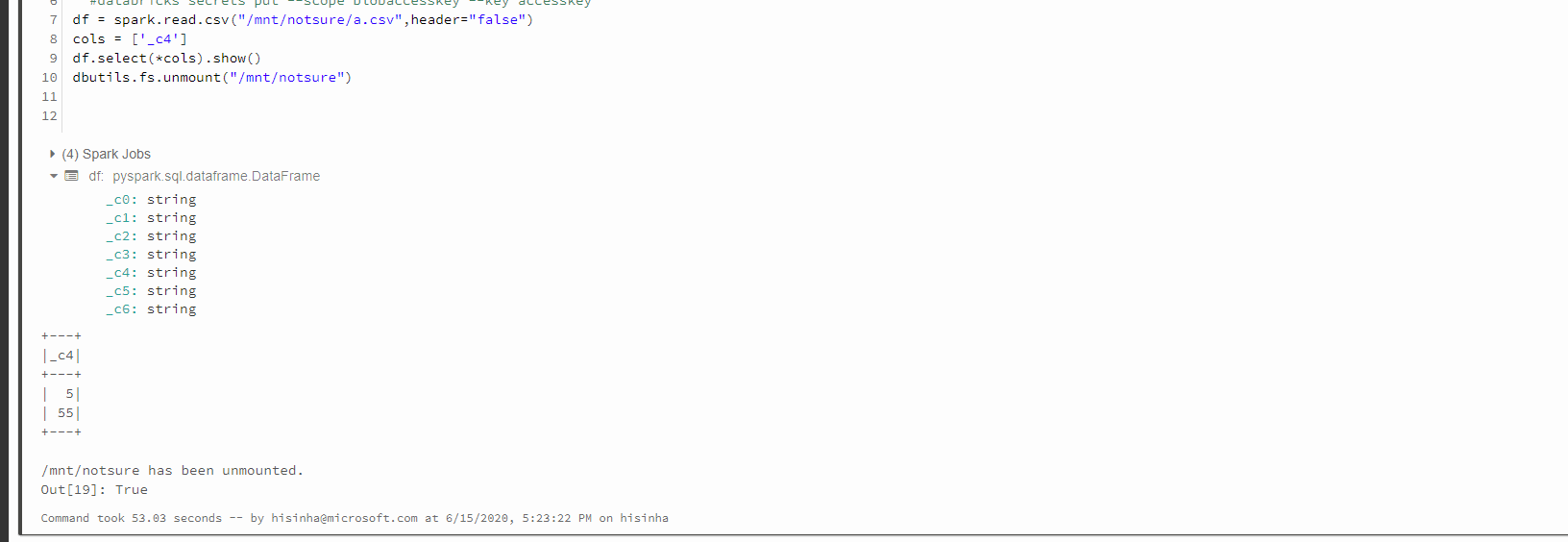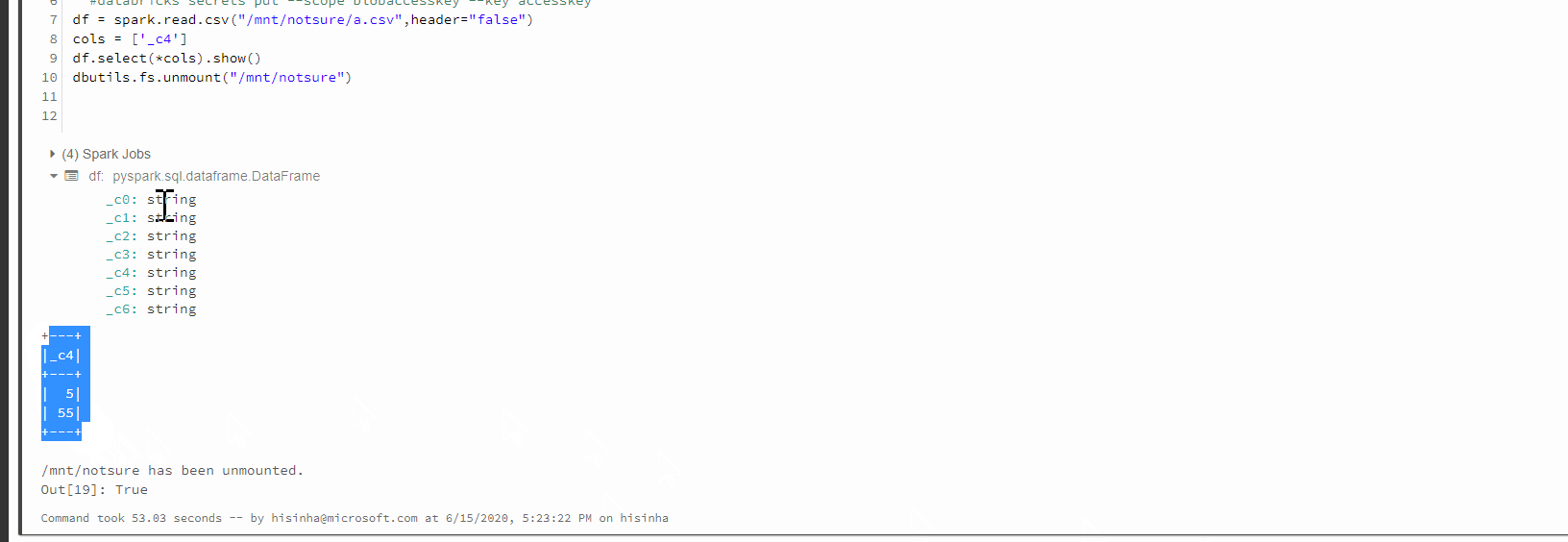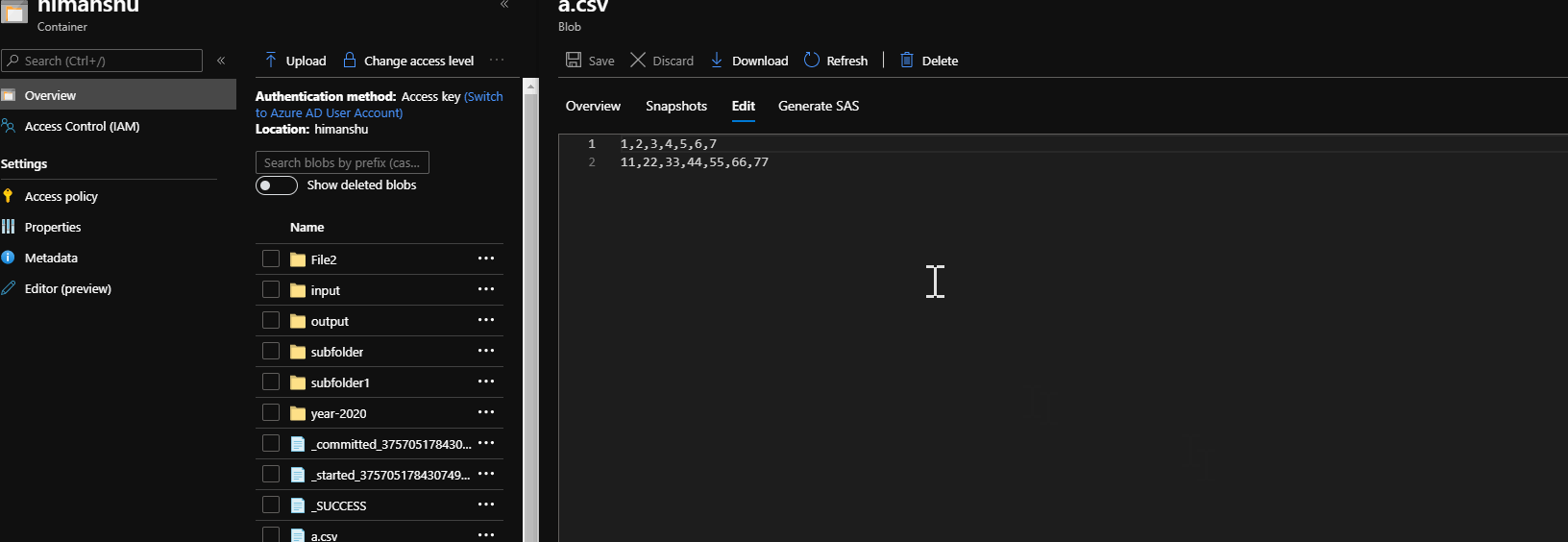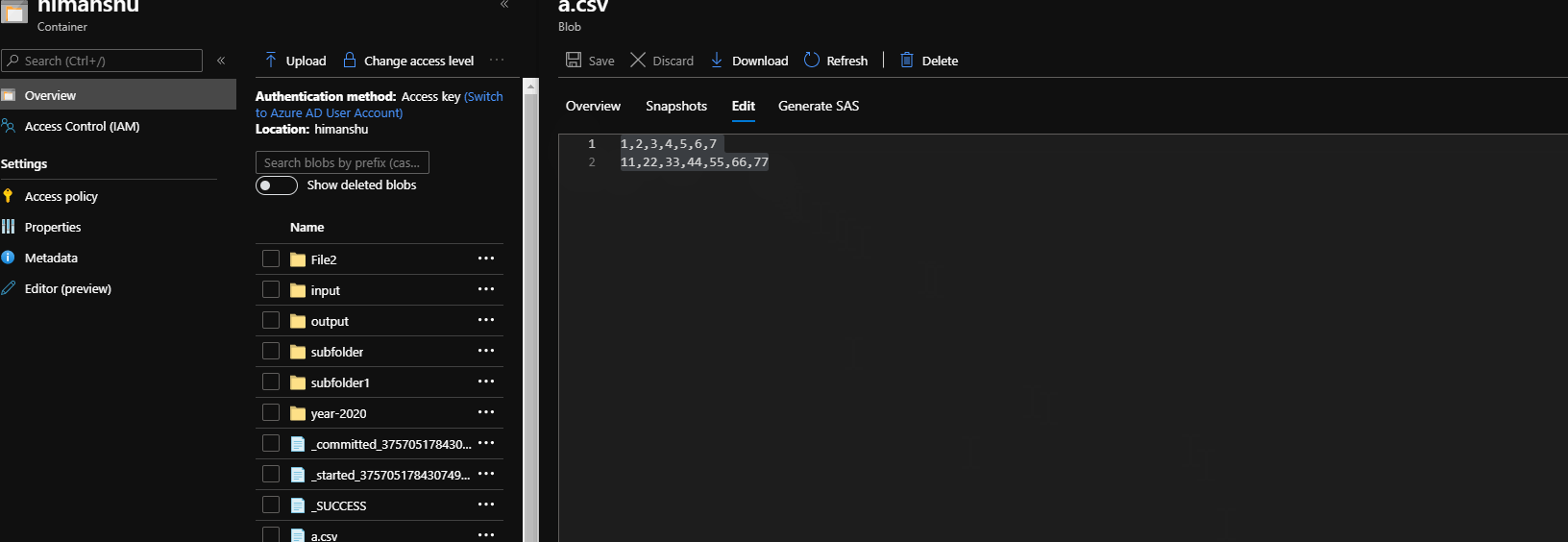
cols = ['_c4']
df.select(*cols).show()
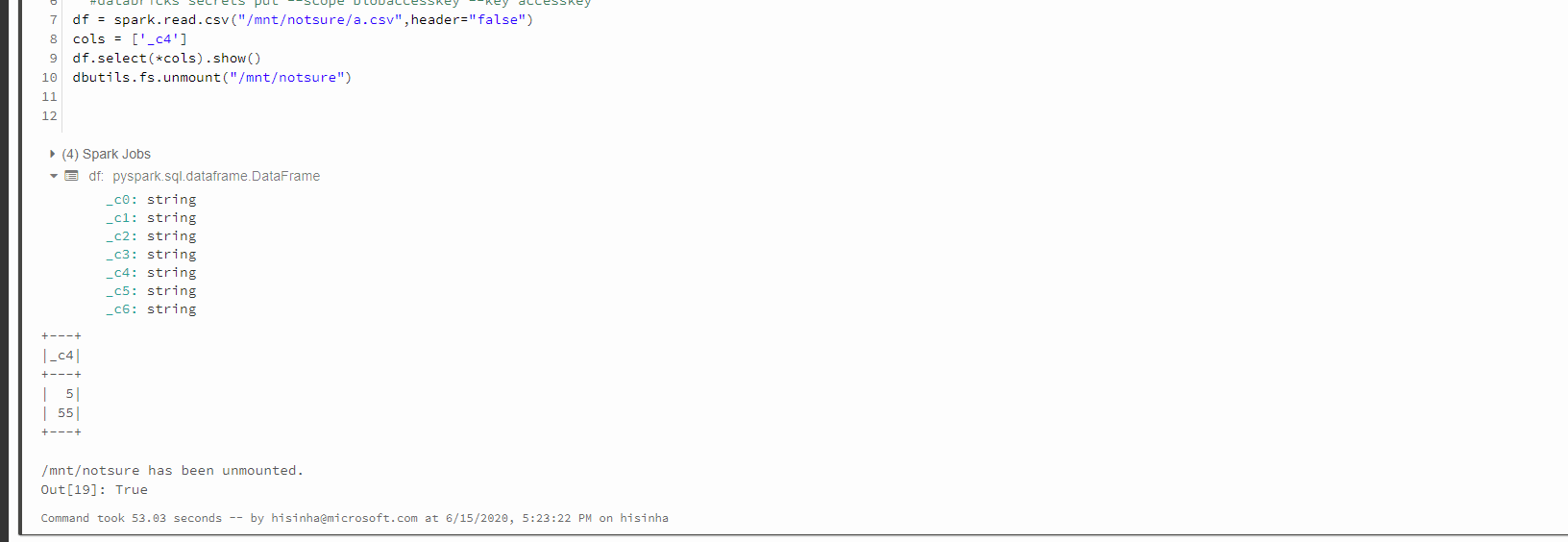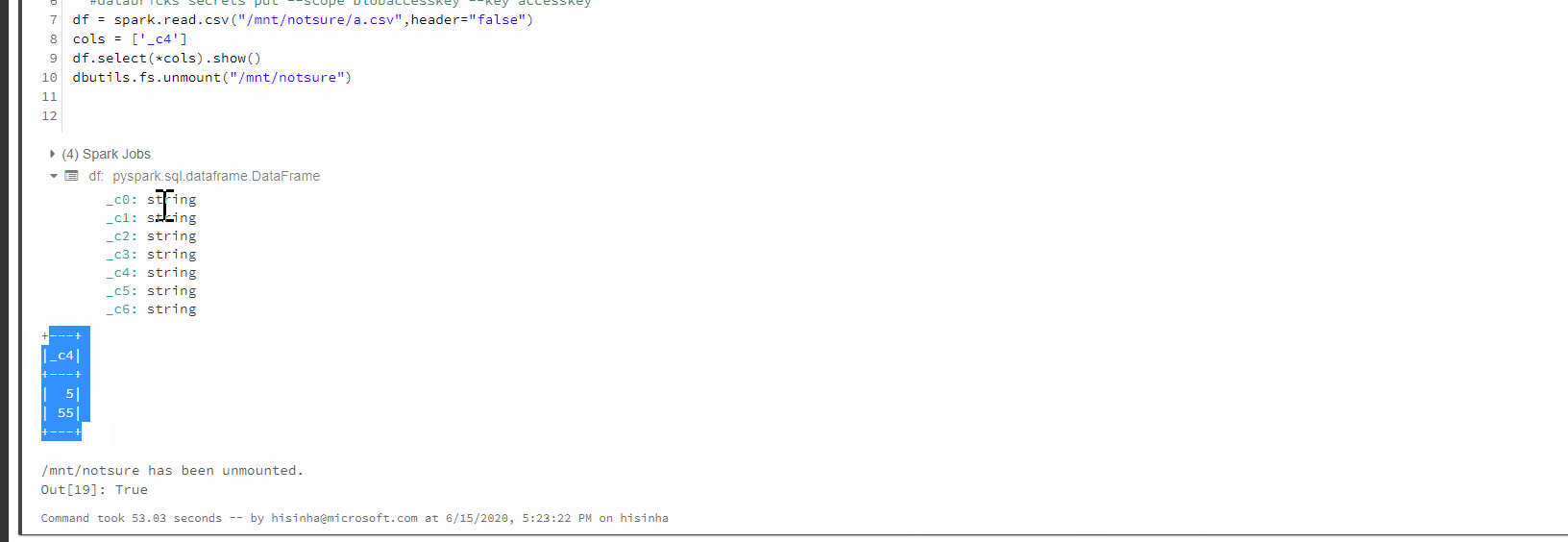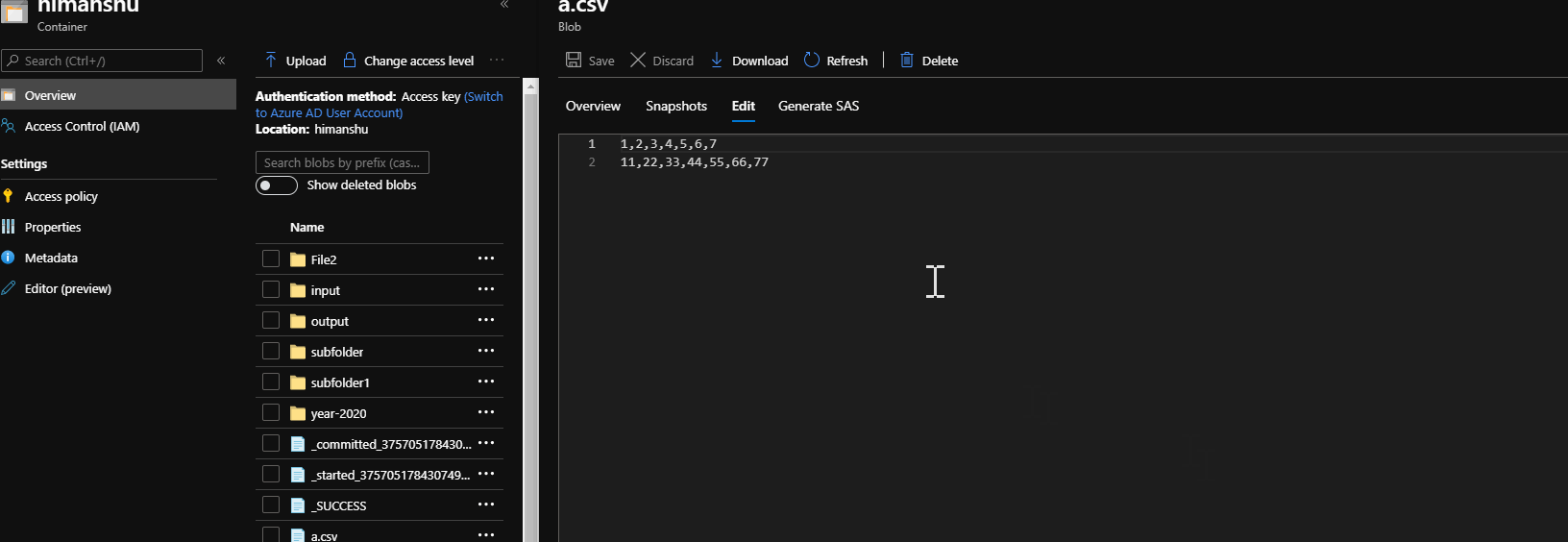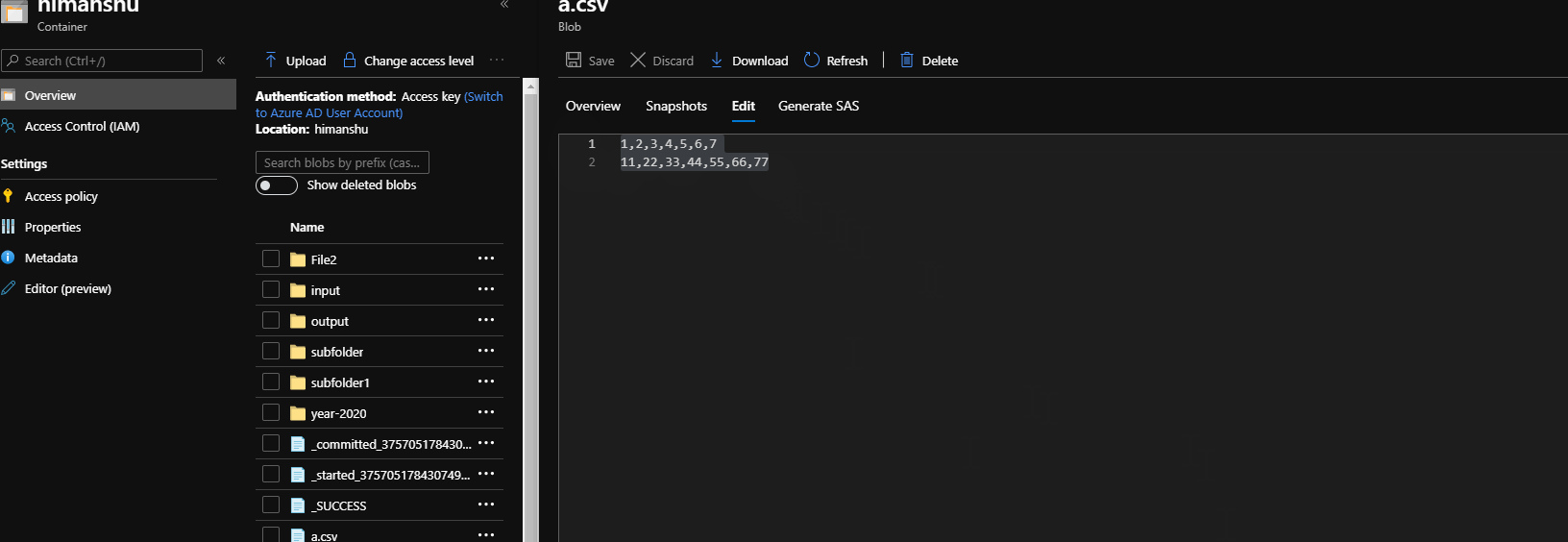
Himanshu
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members
Hello @Rajaniesh,
I think the below piece of code should do the trick . Please do let us know how it goes .
cols = ['_c4']
df.select(*cols).show()
Himanshu
Please do consider to click on "Accept Answer" and "Up-vote" on the post that helps you, as it can be beneficial to other community members
cool thanks Himanshu,
Now if I want to add customer header for this headerless file how do we do that?
Regards
Rajaniesh
Thanks Rajaniesh ,
Can i sincerely request you to please open a new question? That way the question becomes more discoverable to the community .
Thanks
HImanshu
sure it makes sense

One way to do it would be to read it with "schema" option and assign some arbitrary names to your columns, e.g. col_1, col_2, and then reference it by that name.
Also I think Spark will do it for you even if you don't use the schema option, not sure what the pattern would be.