Azure AI Speech
An Azure service that integrates speech processing into apps and services.
1,675 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EE2%3C/text%3E%3C/svg%3E)
Hi,
I have a fairly large dataset of plain text names (300,000+) which I'd like to train a custom model for. I don't have pronunciation or audio form of the names, only plain text.
My previous attempts to train a custom model with a sample of these names failed to deliver better results over the base model.
What would be the best way to go about this, assuming that creating the audio version of all the names is time and cost prohibitive?
Thank you

@evisnetnim-2 I believe you tried to create a custom model for voice using some of the transcripts and corresponding audio but the model created from training did not end up as satisfactory.
If the base models or neural voices are something that works, you can try the audio content creation tool from the studio even with large data. Since you have names as your data in plain text you can calculate the number of characters from all these files and then paste them in the audio content creation tool in text format where the limitation is of 20000 characters in one file.
If we assume each name has around 10 characters then each file in the tool would contain 2000 names and this needs to be repeated for 150 times. Once the names are pasted in one file you could hit the play button this will create audio for all the text in the file. Once this action is complete you can export the files.
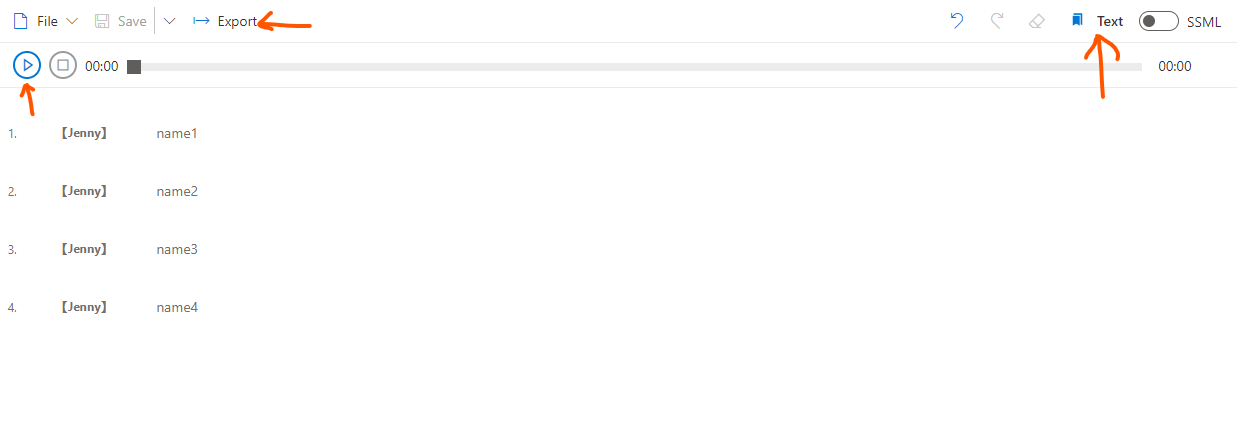
During the export there is an option to export to local disk, choose the following options and download.
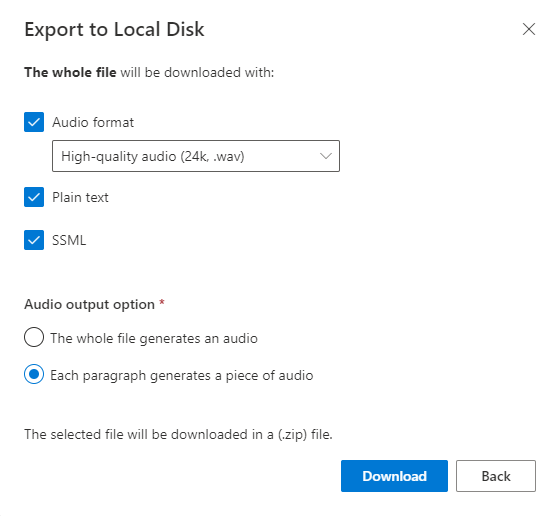
This should download a zip file with the audio files, plain text, SSML and summary.
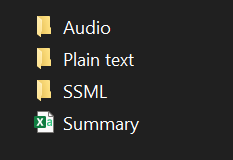
The audio files should be in the order in which you pasted them in the file and each file corresponds to an audio of the name.
You can now rename these files with the same names as pasted in the audio content creation tool. You can create a script to rename these files from the audio folder. I think this SO post could help to create one as the question is similar to this scenario.
You can now repeat this scenario for another set of names. The process is still a bit time consuming but if you can get this to work the first time it should not take a lot of time to complete the rest.
There could be a limitation with the pricing tier of your speech service if you exceed the number of characters as per plan and the availability of some neural voices would need approval from the speech service team for your subscription.
I hope this helps.
Thank you for your answer, @romungi-MSFT !
We ended up doing essentially what you've recommended, only via API so it's more flexible and we have a tool we can reuse.
I now have a different issue which I'll probably open a ticket about, but just in case you are aware of it already:
As you can imagine, using only 4 of 5 files makes for an incomplete dataset, which in my case results in an unusable model.
Any tips? Thanks!
@evisnetnim-2 I assume this is a scenario to create a custom speech model. Since all the 5 zip files uploaded successfully I would assume they are validated for any formatting issues. Do you see the same error when you try to train a model only with the 5th dataset? If there is no error you can try using the model trained with the 4 datasets as baseline model and train a new model with this 5th dataset. This is probably a CI/CD scenario for automation but can also be triggered from the studio.
If the training still fails with the 5th dataset then I would assume a support case will help you get more details on what is causing this issue.
Thank you for your quick reply.
I couldn't identify any single dataset which could be the culprit - any combination of 4 datasets works, only if I add the 5th will it throw an error. I even tried to split a random dataset into smaller chunks, didn't help. It seems like it has an issue with the number of files inside the .zips / or with the total duration of the audio?
I'll try your suggested iterative approach, training with 4 datasets and retraining with the 5th. One question though - I can't seem to select an already trained model as the new base model, only the default MS base model. Does a custom model need to be deployed in production in order to use it as a new base model?
I have tested the scenario and it seems like the baseline models published by the service are only populated in the drop down to create a new model. Models created by user are not available to retrain in this scenario.