Azure HDInsight
An Azure managed cluster service for open-source analytics.
210 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EDR%3C/text%3E%3C/svg%3E)
I have a HDInsight cluster and I want to create hive databases and tables (and load data into them) using Jupyter Notebook.
Can anyone explain how can I do that? Is there any type of example notebooks explaining that?

Hello @Diogo Rodrigues ,
Welcome to the Microsoft Q&A platform.
Azure HDInsight Spark clusters provide kernels that you can use with the Jupyter Notebook on Apache Spark for testing your applications. A kernel is a program that runs and interprets your code. The three kernels are:
Once you create the Azure HDInsight Spark cluster.
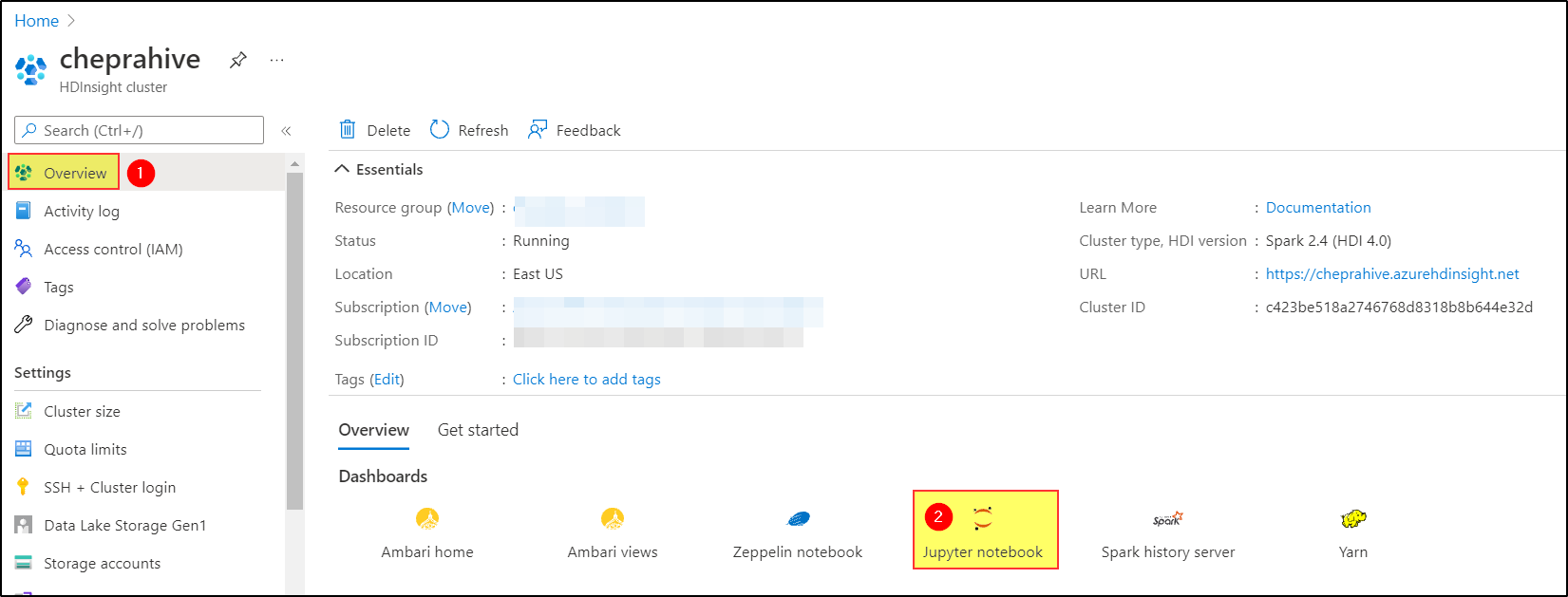
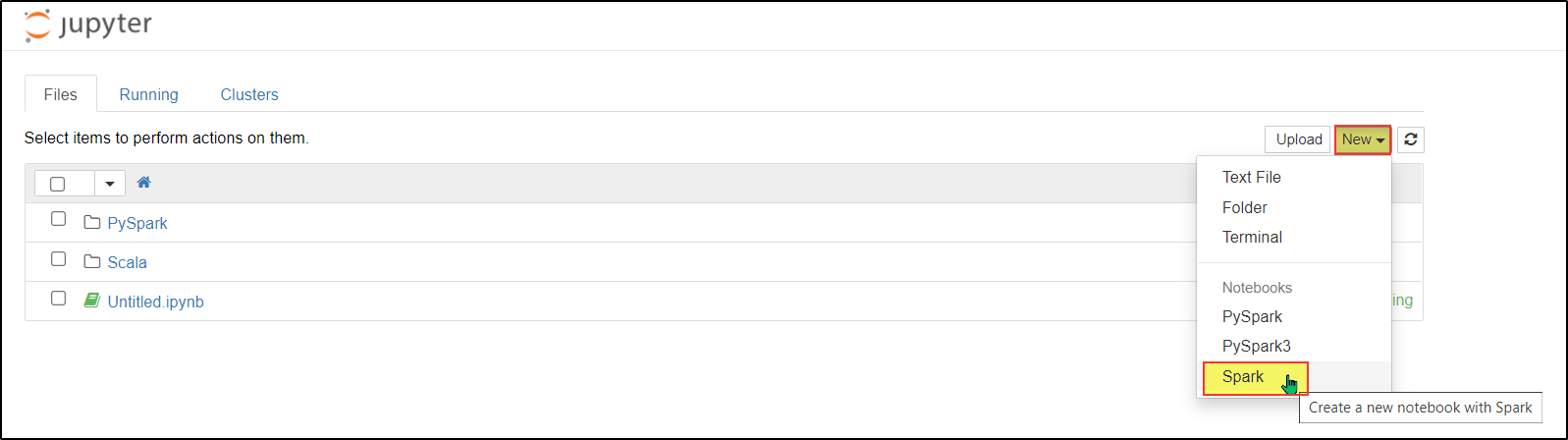
Now you can create hive databases and tables using Jupyter Notebook.
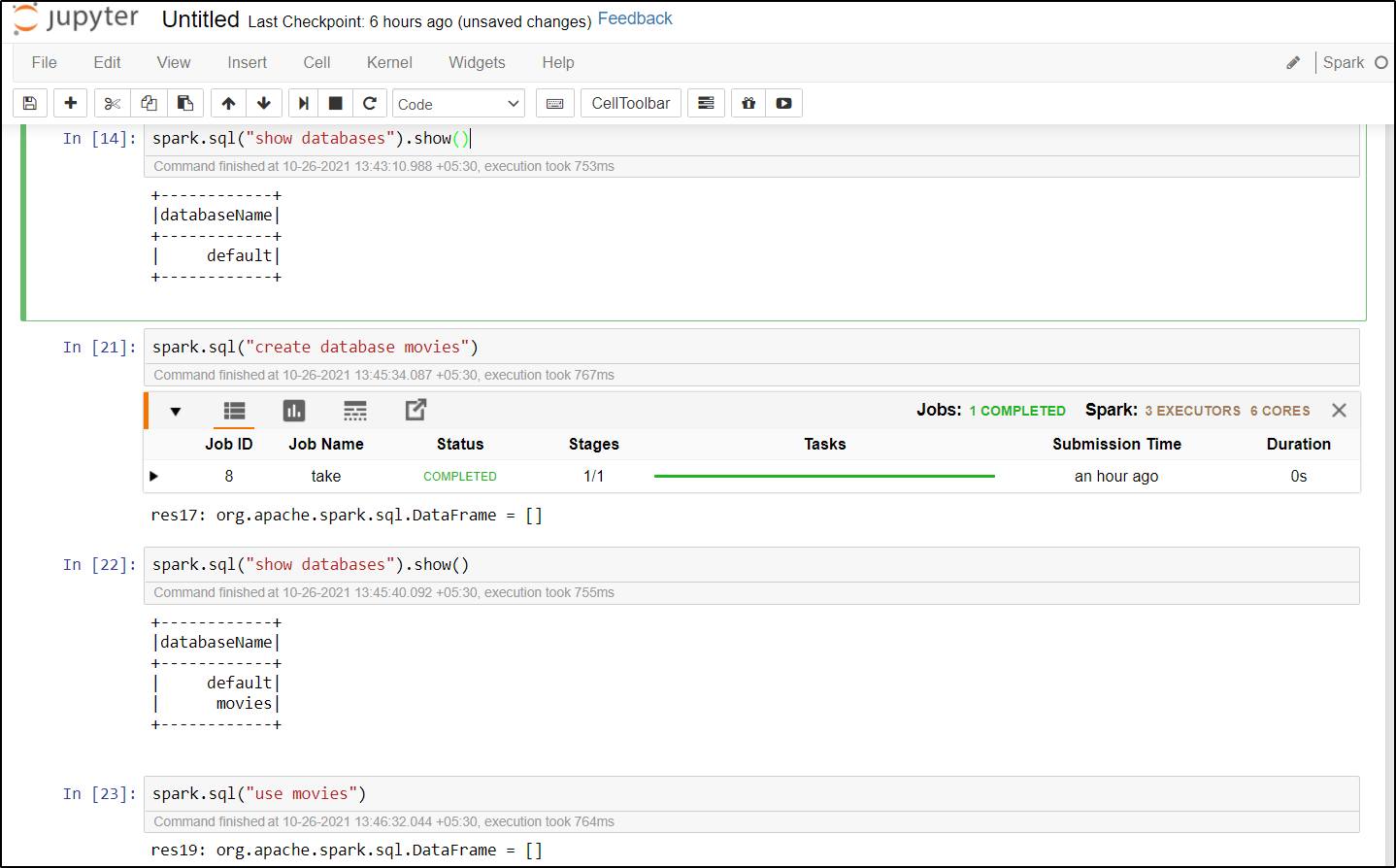
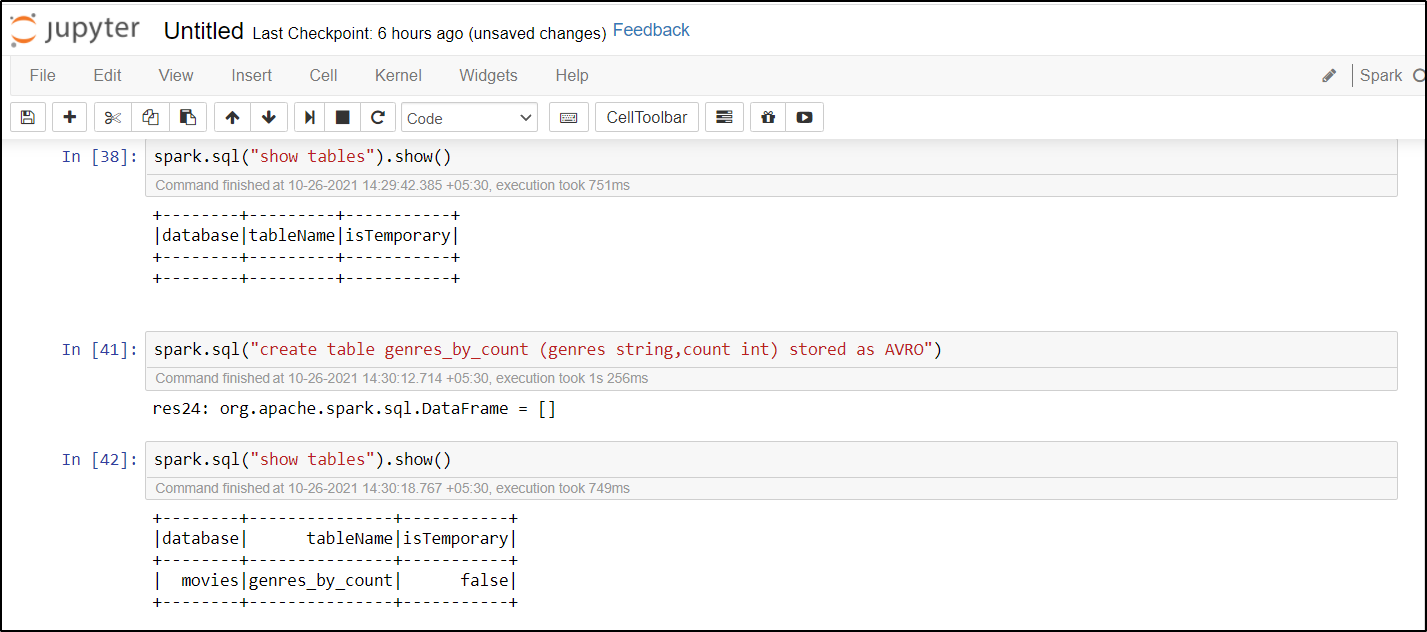
For more details refer to Kernels for Jupyter Notebook on Apache Spark clusters in Azure HDInsight.
And also please refer to the Hive manual for details on how to create tables and load/insert data into the tables.
Hope this will help. Please let us know if any further queries.
------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
Hello @PRADEEPCHEEKATLA-MSFT ,
Thank you for the reply.
I followed your tutorial and came to the same results inside the Jupyter Notebook kernel.
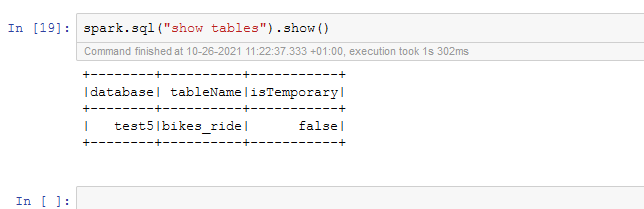
Unfortunately, when checking for the created database and table inside Hive I face the same problem I was having, no trace of the newly created database and table as you can see in the photo below.
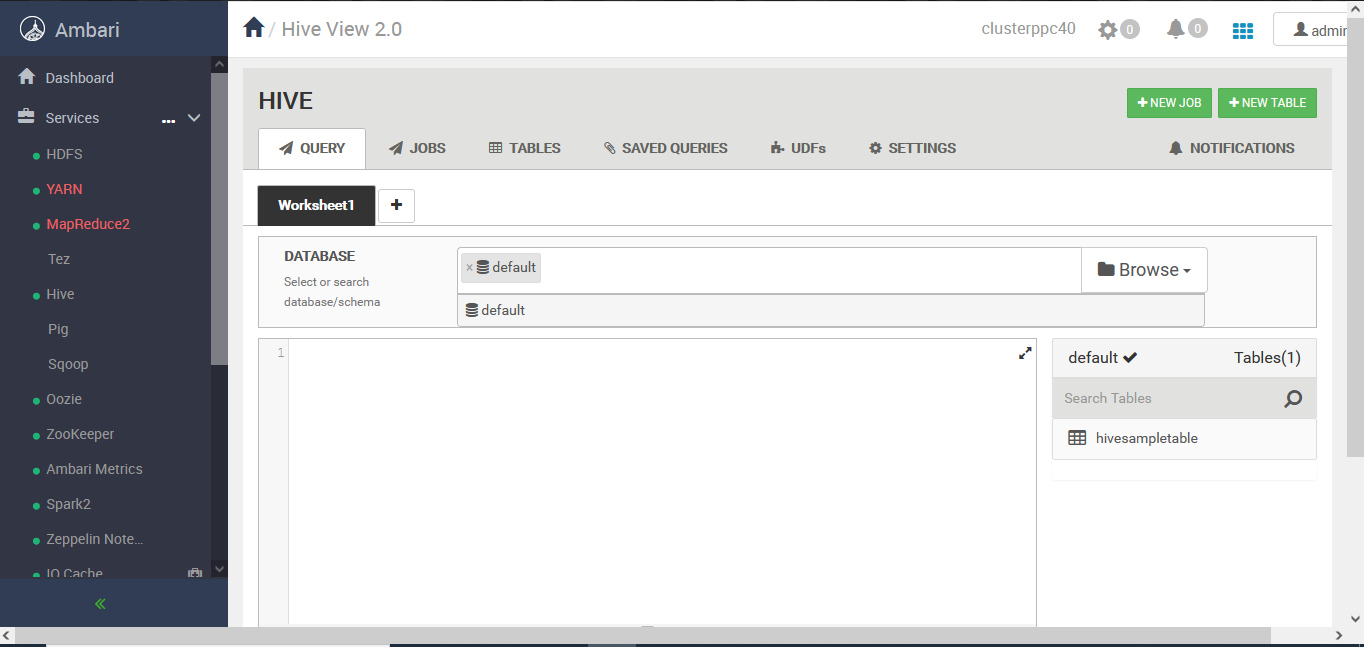
Do you have any suggestions of what could be the problem here?
Thank you.
Hello @Diogo Rodrigues ,
Could you please select Browse and see if you are able to find the database which you have created?
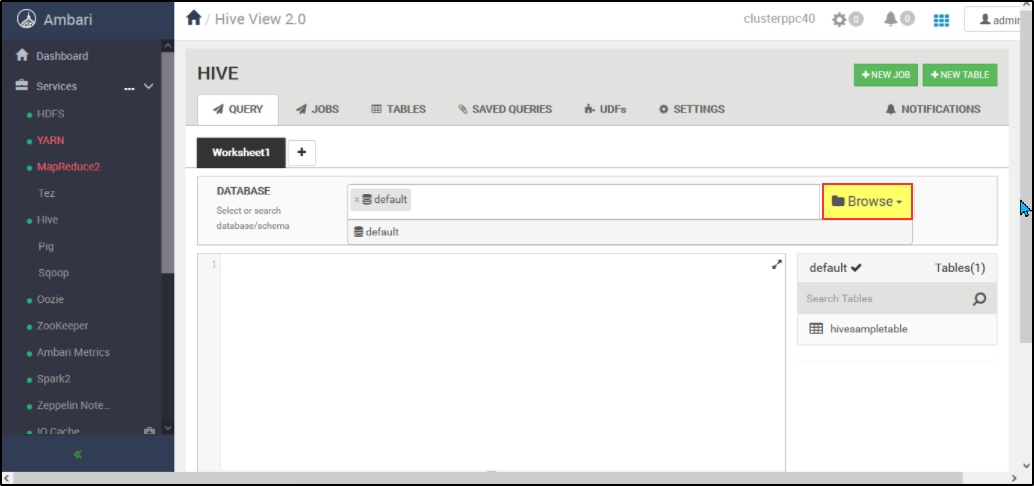
Hello @PRADEEPCHEEKATLA-MSFT ,
I already did what you suggested, as you can see in the image it only shows the default database.
Hello @Diogo Rodrigues ,
Thanks for more details.
We are reaching out to the internal team to get more details on this ask. I will be update you once I hear back from the team.
Hello @Diogo Rodrigues ,
This issue looks strange. For a deeper investigation and immediate assistance on this issue, if you have a support plan you may file a support ticket.