Azure Data Lake Storage
An Azure service that provides an enterprise-wide hyper-scale repository for big data analytic workloads and is integrated with Azure Blob Storage.
1,466 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EBS%3C/text%3E%3C/svg%3E)
Hi All,
We have a requirement given below. Please help us with technical details ASAP. Diagram of our flow already attached
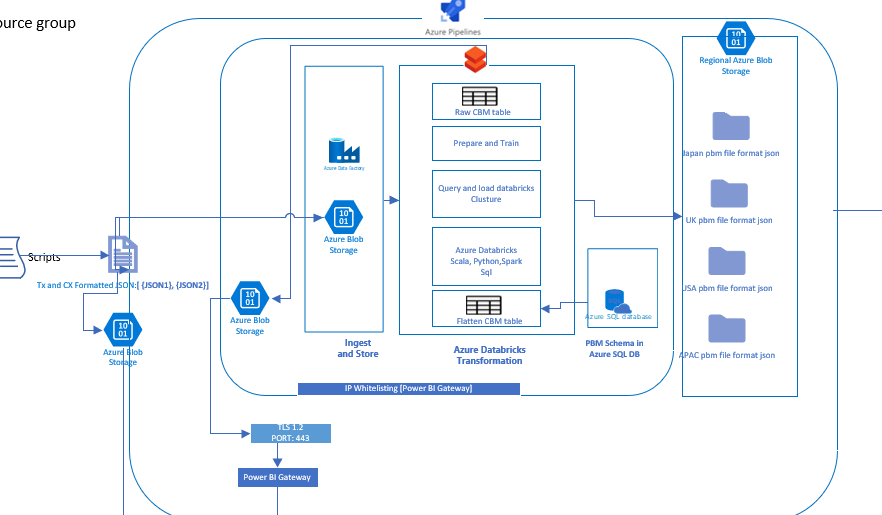
Thanks & Regards,
Sujata
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EHM%3C/text%3E%3C/svg%3E)
Hello @Birajdar, Sujata ,
Thanks for the ask and using Microsoft Q&A platform .
Dataframe not being persisitent is my design and I think thats one of the key reason why operations on the ADb is faster then Hadoop . But then if you want you can always write some audit data in the storage blob to keep an eye on the status . if you are concerned that if there is an compute issues while the processing is happeing the whole design of head/worker should take of that . I do understand that since you are transferring 50 million records you definitely do not want hit any error at the later part of the processing which makes you redo the whole thing again .
If I were you I could have invested in validation script to validate/transform the the data and find out the odd data records ( if any ) . Also the you can take the advantage of the many workers running on Adb when you partition the data . Please look at the input blobs and see if you partition on container / date etc .
Also I see that you are wrting the data to different region ( end goal ) , I suggest you to start with the region with least data , it can work as a trial for your validation scripts \ runbook and also you will eastablish the baseline on how much it will take .
Please do let me know how it goes .
Thanks
Himanshu
-------------------------------------------------------------------------------------------------------------------------
 or upvote
or upvote  button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how
button whenever the information provided helps you. Original posters help the community find answers faster by identifying the correct answer. Here is how