Azure Databricks
An Apache Spark-based analytics platform optimized for Azure.
2,047 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ER%3C/text%3E%3C/svg%3E)
hi,
i have a requirement to move parquet files from aws s3 into azure then convert to csv using adf.
i tried to download that few files on to my local file system and tried to copy via copy activity within adf.
The files are in this format part-00000-bdo894h-fkji-8766-jjab-988f8d8b9877-c000.snappy.parquet
im getting below errors for two different files that i tried.
File is not a valid parquet file.
Parquet file contained column 'XXX', which is of a non-primitive, unsupported type.
Can any one suggest some ways to achieve this? can we implement by just using adf or do i need databricks activity where we can use spark to transform those files?
thanks

Hello @reddy ,
Welcome to the Microsoft Q&A platform.
You can simply move data from aws s3 to Azure Storage account and then mount azure storage account to databricks and convert parquet file to csv file using Scala or Python.
Why The files are in this format part-00000-bdo894h-fkji-8766-jjab-988f8d8b9877-c000.snappy.parquet
By default, the underlying data files for a Parquet table are compressed with Snappy. The combination of fast compression and decompression makes it a good choice for many data sets.
Using Spark, you can convert Parquet files to CSV format as shown below.
df = spark.read.parquet("/path/to/infile.parquet")
df.write.csv("/path/to/outfile.csv")
For more details, refer “Spark Parquet file to CSV format”.
File is not a valid parquet file.
I would suggest you to checkout the file format. Make sure you are passing valid parquet file format.
Parquet file contained column 'XXX', which is of a non-primitive, unsupported type?
You may experience this error message, when you pass the columns which are unsupported data type in parquet files.
You may checkout the file contained column “XXX” data type and make sure you are using the supported data type.
These are the supported data type mappings for parquet files.
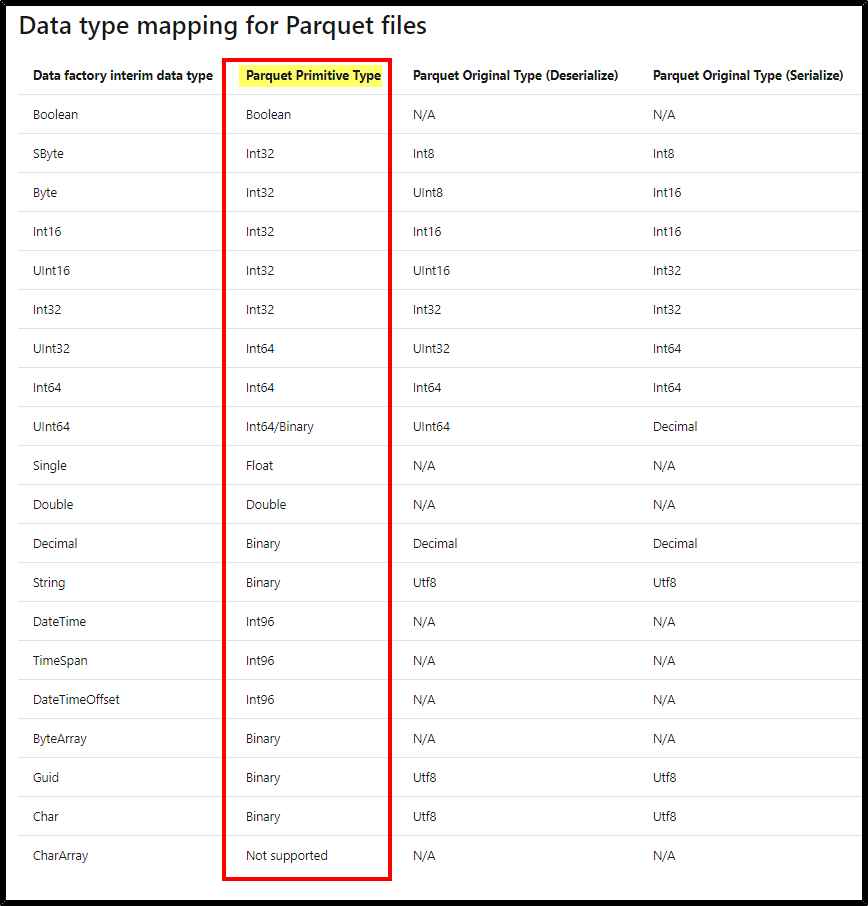
For more details, refer “ADF – Supported file formats - Parquet”.
Hope this helps. Do let us know if you any further queries.
----------------------------------------------------------------------------------------
Do click on "Accept Answer" and Upvote on the post that helps you, this can be beneficial to other community members.
Thanks for reply.
When i try to copy from aws to azure using copy activity after adding source file path, it detects the file format as parquet but throws error saying
Parquet file contained column 'XXX', which is of a non-primitive, unsupported type.
so in previous step, i checked the box binary copy after that it allowed me to copy the file.
I want to understand what this does, is the file going to be in same parquet format in destination if we do this way?
Is there any other method of copying files from aws to azure, I want to do this on schedule basis and incremental load. Can you please suggest?
Thanks`
Hey @reddy ,
Make sure the parquet file contained column 'XXX' contains parquet primitive type data type. Please checkout the above image for supported data types as parquet primitive type.
Hello @reddy ,
Just checking in to see if the above answer helped. If this answers your query, do click “Accept Answer” and Up-Vote for the same. And, if you have any further query do let us know.
Take care & stay safe!
Hello @reddy ,
Following up to see if the above suggestion was helpful. And, if you have any further query do let us know.
Take care & stay safe!