Azure Stack HCI
A hyperconverged infrastructure operating system delivered as an Azure service that provides security, performance, and feature updates.
301 questions
This browser is no longer supported.
Upgrade to Microsoft Edge to take advantage of the latest features, security updates, and technical support.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3EB%3C/text%3E%3C/svg%3E)
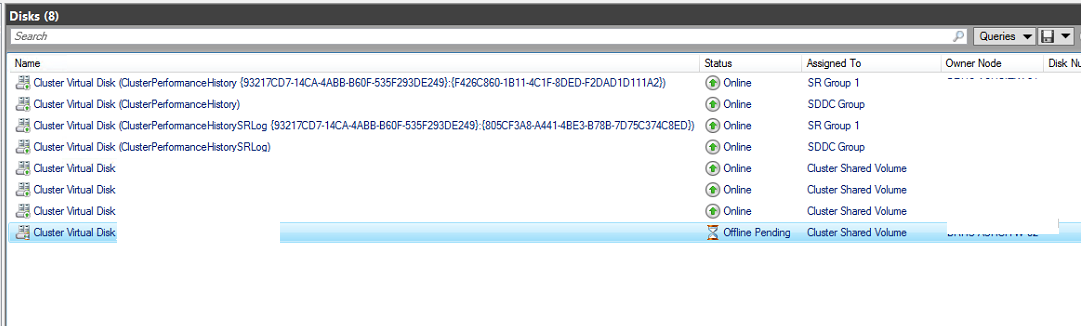
We have a brand new 4x node identical physical Stretched Azure Stack HCI Cluster. 2 Nodes per site. We are on v21H2
When we attempt to change the owner node of a CSV volume from one node to the next (in the same site), we occasionally see the the CSV volume go offline & the status move from Online to Offline Pending. After about 10 - 15 mins of the volume being in the Offline Pending state, the cluster service of the node will restart & the CSV volume ownership is moved to the node that we wanted initially & the volume is accessible.
This is happening randomly on all nodes, which makes it harder to diagnose.
This Stretched Azure Stack HCI Cluster is currently in pre-production, so has no guests hosted at the moment.
Cluster validation report runs successfully, the only warning's are related to the ClusterPerformanceHistory volumes not using default settings - which is not something we have adjusted.
Any pointers on how to pinpoint/dragonise this issue would be greatly apricated.
' cx='32' cy='32' r='32' /%3E%3Ctext x='50%25' y='55%25' dominant-baseline='middle' text-anchor='middle' fill='%23FFF' %3ETH%3C/text%3E%3C/svg%3E)
Hi @Brad ,
There are a lot of possibilities here that are difficult to answer without knowing the full setup of the environment. However, I will attempt to give you some information that can help you troubleshoot the cause of this issue.
First, I would ensure the nodes are all fully up-to-date with the latest patches. This will help to ensure you aren't running into any issues that may have already been resolved.
Next, I would confirm your networking is properly set up between sites. We frequently see stretched configurations that are not designed as per our best practice. These configurations have caused numerous issues with stretched clusters, so it is worth taking the time to verify. Most of the common misconfigurations we see include multiple paths between sites, SR traffic using unintended NICs, attempting to use a stretched L2 network for the cluster hosts (this is OK for the VM traffic though) and bandwidth bottlenecks between sites. The requirements can be found here - https://video2.skills-academy.com/en-us/azure-stack/hci/concepts/host-network-requirements#stretched-clusters
Another thing to consider, does this issue happens without SR configured? If so, this is a simpler configuration to troubleshoot. If not, this could point to a possible issue with the stretch configuration. If you are using a Synchronous replication, you could attempt to try Asynchronous replication to see if it changes the behavior as well.
As for data to collect, the best would be the SDDC diagnostics - https://github.com/PowerShell/PrivateCloud.DiagnosticInfo. This would give you the best overall data as you could review the cluster and SR logs for clues to what is happening. Look at the logs on the node you are attempting to move the resource from first. Hopefully this can lead you to an answer, but if you need additional help, I would suggest opening a case where we can deep dive into the logs with you further.
Hope this helps!
Trent
Hi @Trent Helms - MSFT ,
Can you please provide me with a link to a real world end-to-end deployment guide of a stretched cluster? Every other HCI vendor has one, can't find one from Microsoft.
OS Version on each of the four nodes is: 10.0.20348.
The CSV volume that went offline in the example in my OP was not configured for replication to the other site. It was a site specific two way mirrored volume. We had configured SR to use dedicated pNics via Set-SRNetworkConstraint command for the ClusterPerformanceHealth replication group.
Since I have posted this question I have done the following:
Still have the same problem. I need community help as every time I've logged a support case with Microsoft in the past (not related to Azure Stack HCI) they ALWAYS tell me to rebuild the server, which is garbage.
Hi @Brad ,
Thank you for the update. The link provided (https://video2.skills-academy.com/en-us/azure-stack/hci/concepts/host-network-requirements#stretched-clusters) is the best guide we have for implementing stretch clusters in Azure Stack HCI.
As for the analysis, the cluster log would be the best place to start. Reproduce the issue then gather the cluster log from the nodes. It will take some time, but using a tool such as Notepad++, you can filter the logs down somewhat to find the offending volume. Take time to read through the logs to see if it will give you a clue as to what is taking so long in the process. From that outcome, it can point you to what to look for next.
I am sorry for any past experiences you have had when logging support cases. I can assure you with Azure Stack HCI support, we work with you to troubleshoot the actual issue. We also do what we can to verify the environment is fully stable before resolving your case. If you haven't logged a case with this support team, I would ask that you give us a chance to change your mind.
Hope this helps!
Trent