Microservices - Isolated Data & State
New technology adoption can be unnerving and can face strong opposition. Often doing things differently introduces a feeling of trepidation in the team as there is perceived risk in the possibility of unknown complications. When looking at the attributes defined in Gaurav Aroraa's post: Introduction to microservices, one attribute tends to terrify monolithic application developers:
Isolated Data & State - each service owns its data and its state.
This post explores this microservice attribute.
What does isolated data and state mean?
In Service Oriented Architecture (SOA), it was not that uncommon to see well designed services matching business operations or entities at the service level but not at the repository level. For example, a customer service and an order service might be hosted separately but both use a shared database. For example, what if the order service exposes an endpoint for getting all orders where a customer surname is "Smith":
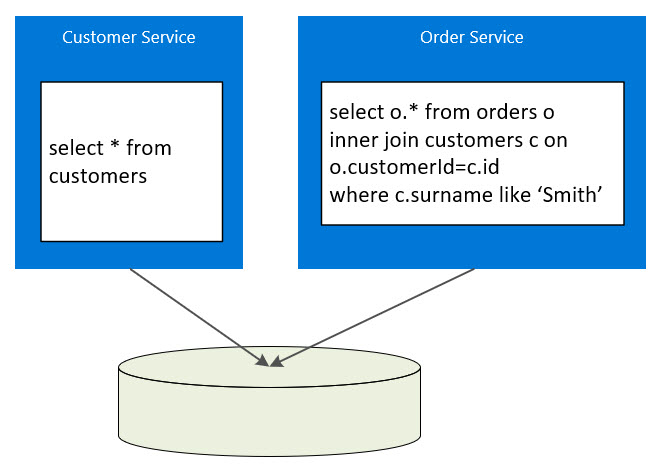
Why is this so bad?
Well, good and bad are not really the correct terms to use. In certain scenarios you might not want to isolate your data, but as soon as the data is no longer isolated, then the independence of these services is broken. The main issue with data dependence involves change to the shared repository data model. When change happens with a shared data model, all dependent systems could require an immediate update.
Note: It is possible to implement a bespoke migration process using versioned views over the underlying database schema but this technique is not as widely accepted as service level versioning. Service level versioning is a pattern where more than one version of an service (i.e. API) is available allowing for clients of the service to continue operating without the need to upgrade immediately.
Note: Some repository technologies, like schema-on-read repositories (e.g., NoSQL), could handle a change to schema with more resilience than schema enforced repositories (e.g, RDBMS databases like SQL Server), but there is still the risk with a shared repository that a change made for one application could have an impact on another application.
The microservice way
There are several ways to approach data isolation when data between microservices overlap. A design goal should be to minimize this overlap but sometimes this is not possible to avoid. This is especially true with identity data (e.g., user identity). Here are some common approaches to how this can be handled.
Inter service dependency
The first introduces inter service dependency at the service level (referred to by Gaurav as a paradigm shift) by introducing a service call in the Order Service to first fetch all customers that match the surname "Smith". The advantage of inter service dependency over shared data and state stems from change. A change to a shared repository is more challenging to handle than a service. With a good service level versioning practice, services can be updated without impacting clients by either supporting older versions of a service or not changing the service contract. The image below illustrates this:
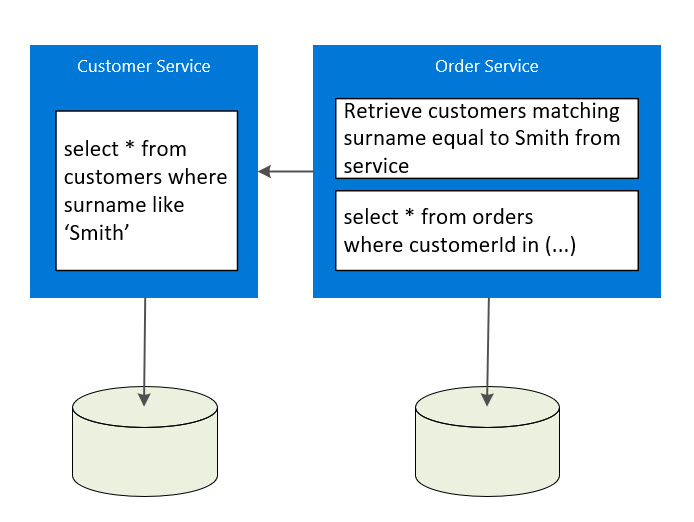
Not my problem approach
The second requires the client of the order service to supply a list of ids for customers with the surname "Smith". This usually is attractive to developers but this has drawbacks as it tends to produce many granular services that do not match the business domain. This might be right for certain environments but could lead to the development of unnecessary endpoints as it introduces a disconnect from business requirements and tends to produce a collection of CRUD services. Again, this might be the right approach for certain situations but the aim of microservices is not to produce a table per service but to produce services that match a particular business domain.
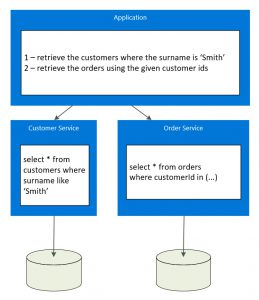
Data Replication
Another approach is to replicate data across multiple repositories. This tends to be achieved using an event based approach where this is a master repository, for example a customer database, and it posts events when an update, add or delete is made. The event is broadcasted (published) and interested applications (subscribers) receive the event and apply the change to their local database. This event based approach ensures the data becomes consistent between the different repositories.
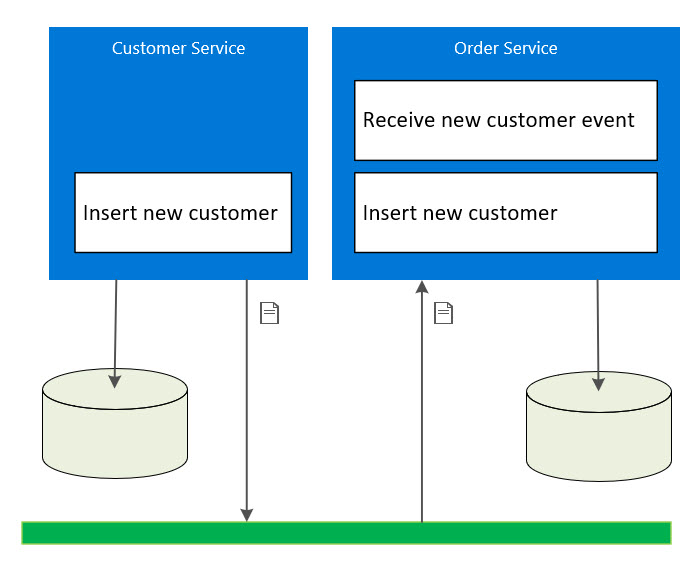
Note: Additional effort is required to proactively verify the state of replicated repositories in case a failure or user error causes the databases to become inconsistent.
Note: Replication can take many forms including data sync between databases.
Transactions
Another important concept to consider is how transactions should be handled. In this post, a transaction covers two or more changes involving two or more microservices. Take a new customer order for example involving the customer service which holds their account balance and the order service which handles the order from creation to provisioning. There are several approaches to this and this post will highlight two common patterns involving compensating transactions and entity status.
Compensating Transactions
This tends to involve some form of orchestration either in one of the services or controlled by an application or integration engine. In the customer order example, let's illustrate this using BizTalk. The following image shows how an order is first created in the Order Service and then the funds are removed from the Customer Service. If the debit is not successful then the created order is deleted from the Order Service.
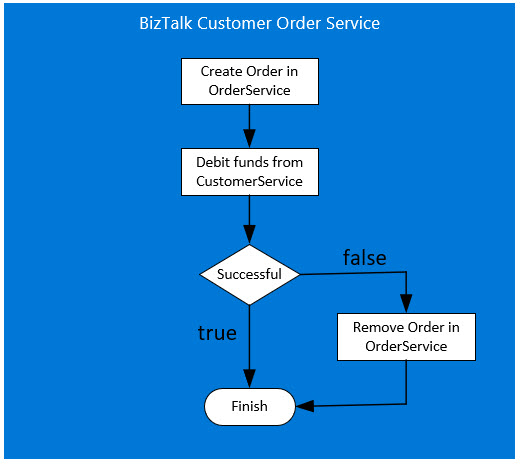
Entity Status
Status fields on entities can also be used to track an entity through different phases of a workflow. For example, the entity Order in the Order Service could have a status field managing different states from pending (created but not paid) to provisioning (paid) to provisioned (sent to customer). The following image shows the customer service controlling the transaction by managing the sate of the order:
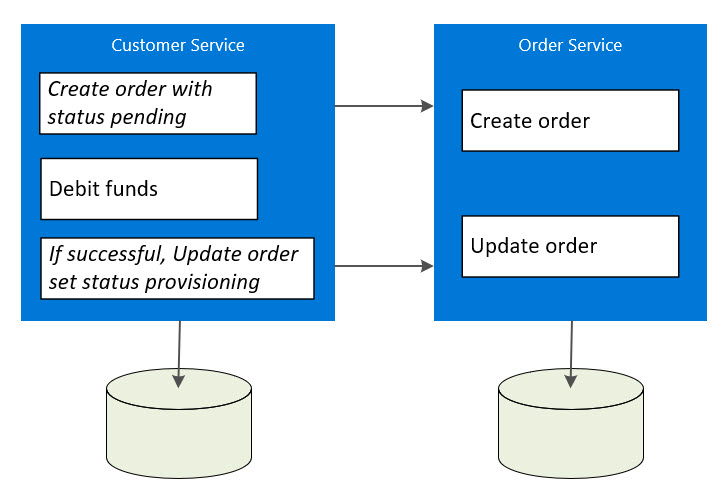
References and additional resources
Here is a collection of resources worth a review. Please post in the comments additional viewpoints and references of interest.
Two important patterns for microservice isolated data: Database per service and Saga.
A post by Sergei Petunin: A Guide to Transactions Across Microservices
Part of a microservice series by Christian Posta: The Hardest Part About Microservices: Your Data
Comments
- Anonymous
April 18, 2018
Keep it coming :) - Anonymous
January 25, 2019
The diagrams really help us compare the different approaches. Great article, and I love how it leads us to more resources.