A Fixed-Width Extractor for Azure Data Lake Analytics
I have a fixed-width text file I'd like to use with Azure Data Lake Analytics (ADLA). ADLA reads files using extractors. As of today, ADLA comes out of the box with three extractors: one for comma-delimited text, another for tab-delimited text and a general purpose extractor for delimited text. Examples on GitHub demonstrate the mechanics for writing custom ADLA extractors and include working versions of JSON and XML extractors. Using these examples as a starting point, I've managed to hack together a custom extractor for fixed-width text files. I'll use this post to walk you through the code I've assembled in hopes that this helps someone else who needs to build a custom ADLA extractor of their own.
First, I'll walk you through my scenario in a bit more detail. I've setup an ADLA account (called brysmi) and have associated it with an Azure Data Lake Store (ADLS) account (also called brysmi). In the ADLS account, I've created a folder off the root called fixedwidth and in it I've placed my fixed-width file. (Details on creating an ADLS account and loading files to it are found here.) This file (downloadable here) consists of three lines of fixed width text:
12345678
12345678
12345678
Admittedly, this isn't the most exciting file out there but the simple structure allows me to very easily verify my extractor is working correctly. To do that, I need to submit a U-SQL script to ADLA which calls up my custom extractor, telling it how to read the fixed-width lines into columns, and then send that data to an output file using a delimited format. The U-SQL code I'll use looks like this:
USE DATABASE [master];
REFERENCE ASSEMBLY [FixedWidthExtractor];
@tbl =
EXTRACT
col1 int,
col2 float,
col3 decimal,
col4 byte[]
FROM "/fixedwidth/input.txt"
USING new MyCustomExtractors.FixedWidthExtractor (
new SQL.MAP<string, string> {
{"col1","3"},
{"col2","2"},
{"col3","1"},
{"col4","2"}
}
);
OUTPUT @tbl
TO "/fixedwidth/output.txt"
USING Outputters.Csv();
The first line of this script tells ADLA to USE objects referenced in its master database. You can think of this as a structure for keeping logical reference to objects in the ADLA/ADLS environment. In that master database, I've registered an assembly (DLL) which holds the extractor code - I'll cover that part towards the bottom of this post - so that the REFERENCE statement points ADLA at that registered object.
In the next block, I tell ADLA to extract four fields FROM my input file USING an extractor class that's defined in my referenced assembly. To that class, I am passing a parameter typed as an ADLA type called a SQL.MAP which holds ordered key-value pairs identifying the columns to read from a line of text and the number of characters associated with each. Note that the columns in map are ordered the same as those in the EXTRACT statement's column list. Note also that column widths are passed in as strings; while SQL.MAP appears to accept integer values for the value part of its pairs, passing anything other than a string was causing errors.
In the last block of U-SQL script, I have ADLA send the parsed data to a comma-delimited text file. Nothing fancy here; I just want to see how the parsing worked.
If all that made sense, then let's take a look at the code for the assembly. I've written this using the Azure Data Lake Tools for Visual Studio 2015, leveraging the Class Library (For U-SQL Application) project type:
{kind=link}
Before going any further, I need to point out that I am not even a mediocre C# developer. I'm going to screw up terminology and probably point out things that no true developer would either need pointing out or find interesting. And, yes, there are probably a bazzilion ways the code could be written more efficiently. With that out of the way, let's proceed.
The first thing I want to point out is the namespace and class definitions. It's important to note these because when you call the extractor in the EXTRACT statement, you need to instantiate the extractor using the new keyword followed by namespace.class.
namespace MyCustomExtractors
{
public class FixedWidthExtractor : IExtractor
{
… //coding magic happens here
}
}
Under the class definition, I define the method by which the class is instantiated. I have three parameters, two of which are optional. The optional parameters, encoding and row_delim, are used to identify the encoding and row-delimiter for the text file. These receive default values of UTF8 and carriage-return+line-feed if not otherwise specified. The SqlMap, i.e. col_widths, is the only required parameter and hopefully it is pretty well understood given the explanation earlier in this post.
public FixedWidthExtractor(SqlMap<string, string> col_widths, Encoding encoding = null, string row_delim = "\r\n")
{
this._encoding = ((encoding == null) ? Encoding.UTF8 : encoding);
this._row_delim = this._encoding.GetBytes(row_delim);
this._col_widths = col_widths;
}
The class we're defining implements the IExtractor interface. As such it exposes an IEnumerable method that ADLA depends upon to send file contents to it and receive structured data back. By overriding this method, we now have the means to insert the custom logic needed to process the fixed-width file.
public override IEnumerable<IRow> Extract(IUnstructuredReader input, IUpdatableRow output)
{
... //more code magic here
}
The input variable passed into IEnumerable by ADLA is a reference to our input file. To read data from that file, a stream is opened and information passing over that stream is split using our specified row-delimiter. Each row is interpreted as a string using the specified encoding and assigned to the variable line.
public override IEnumerable<IRow> Extract(IUnstructuredReader input, IUpdatableRow output)
{
foreach (Stream currentline in input.Split(this._row_delim))
{
using (StreamReader lineReader = new StreamReader(currentline, this._encoding))
{
string line = lineReader.ReadToEnd();
… //the good stuff is coming here
}
}
}
With a line of text now assigned to the line variable, it can be parsed into columns. Iterating over the SqlMap holding the column names and widths, each column is parsed from the line. Based on data types read from the column-list in the U-SQL EXTRACT statement and imposed on the output object passed to the IEnumerable method by ADLA, strings parsed from the line are cast to appropriate types and assigned to the output. Once the last column is parsed, the row in the output object is made read-only, freeing it to send data to ADLA.
//read new line of input
int start_parse = 0;
//for each column
int i = 0;
foreach (var col_width in this._col_widths)
{
//read chars associated with fixed-width column
int chars_to_read = int.Parse(col_width.Value);
string value = line.Substring(start_parse, chars_to_read);
//assign value to output (w/ appropriate type)
switch (output.Schema[i].Type.Name)
{
case ("String"):
output.Set(i, value);
break;
case ("Int32"):
output.Set(i, Int32.Parse(value));
break;
... //shortened for readability
default:
throw (new Exception("Unknown data type specified: "+output.Schema[i].Type.Name));
}
//move to start of next column
start_parse += chars_to_read;
i++;
}
//send output
yield return output.AsReadOnly();
With all the needed code in place, I build the project as I would any other. Now I come to the challenge of registering it with ADLA. To do this, I open Server Explorer in Visual Studio (found under the View menu if not already visible). I connect to my Azure account, expand the Data Lake Analytics node, and locate the ADLA account I've already created.
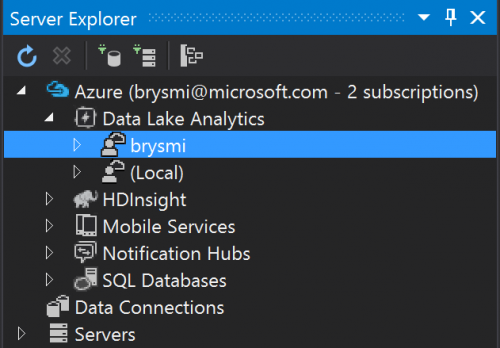
Expanding the ADLA account and then the U-SQL Databases node under it, I come to the master database. Expanding that database, I find a folder for Assemblies. Right-clicking that folder and selecting Register Assembly, I launch a dialog for registering the assembly I just compiled.
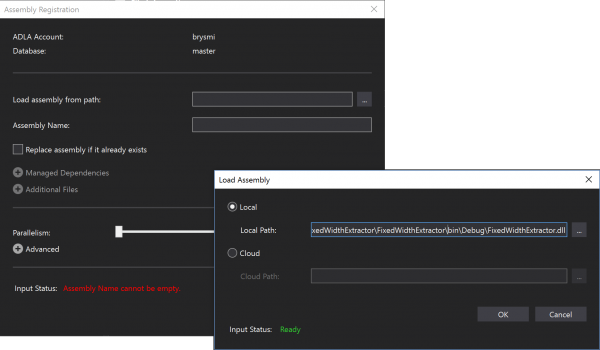
In the dialog, I click on the button next to the Load assembly from path: textbox. In the pop-up, I select local click on the associated button to locate the DLL compiled with my project. By default, this will be under the bin\Debug subfolder under the project folder. The .pdb file as well as the Microsoft.Analytics.Interfaces.dll and Microsoft.Analytics.Types.dll files are ignored.
Once the file is located, I click OK to return to the original dialog and then Submit to upload the assembly and register it with ADLA. The process takes a little time to complete but I encounter a Job View screen displaying all green marks when successfully completed.
Refreshing and then expanding the Assemblies folder in Server Explorer, I now see the assembly registered. Note the name as displayed in Server Explorer as this is the name used in the REFERENCE ASSEMBLY U-SQL statement.
At this point, everything is in place for a test run of the extractor. To run the U-SQL script leveraging the Visual Studio interface, I simply create a new U-SQL project. In the U-SQL Script view, I double check the script is pointed to my ADLA account (as highlighted in the image below) and click Submit.
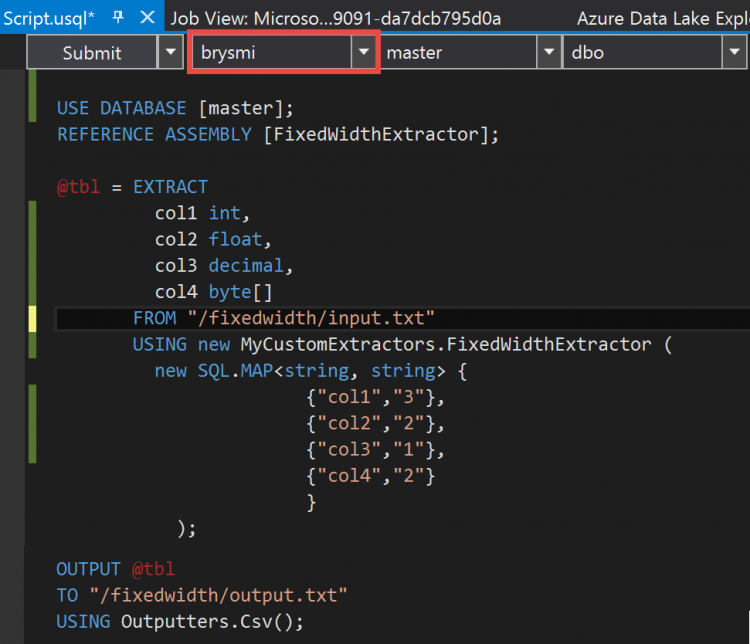
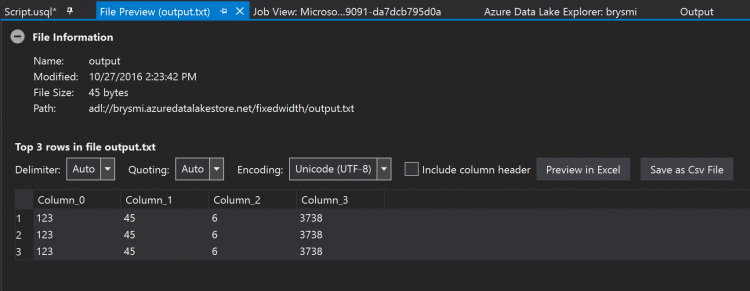
As before, I receive a Job View screen but this one will display a bit more info. Once successfully completed, I use the Server Explorer to return to my ADLA account. I expand the Storage Accounts item, right-click the ADLS storage account and select Explorer. In the Explorer window, I navigate to the folder holding the output file. Right-clicking the output file and selecting Preview opens a window where I can see the file is parsed per my instructions. (Note, I asked the extractor to parse the last two characters in the string as a byte array. Converting this back to text results in the characters shown in the screenshot below.)
 rere
rere