Hadoop for .NET Developers: Understanding HDFS
NOTE This post is one in a series on Hadoop for .NET Developers.
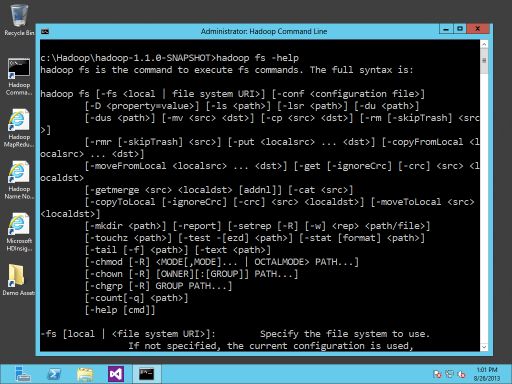
From a data storage perspective, you can think of Hadoop as simply a big file server. Through the name node, the Hadoop cluster presents itself as a single file system accepting basic Linux file system commands such as ls, rmr, mkdir, and others. To see the list of available commands with explainations and syntax, you can launch the Hadoop command prompt (a shortcut to which is placed on the desktop with the default HDInsight install) on your desktop development environment and issue the following command:
hadoop fs -help
Here are some of the results of this command:
Data are loaded to the Hadoop file system as files and can be loaded either manually or programmatically. The steps involved with each are addressed in the next few posts of this blog series.
When a file is loaded into a Hadoop cluster using HDFS, the file is broken up into blocks. The default size of a block is 64MB though HDFS does not allocate a full block when a partial block is needed. To illustrate this, consider a 100MB file being loaded to HDFS. Assuming a default configuration, this file would be broken into a 64MB block and a 36MB.
These blocks are stored on the data nodes and distributed in a manner that attempts to balance the placement of blocks across the cluster. The name node keeps track of which blocks comprise which files and on which data nodes these blocks are stored. To the user, none of this is apparent so that the file system presents a given file as if it were a singular entity within the file system regardless of the number of blocks involved and their placement on the data nodes.
To avoid data loss, blocks are replicated between data nodes when multiple data nodes are present. By default, blocks are stored in triplicate across the data nodes so that the loss of a data node should not result in the loss of data. As data nodes fail or are removed from the cluster, affected blocks are replicated to maintain triple redundancy across the remaining data nodes.