CopyQueueLength is displayed incorrectly in an Exchange 2007 Standby Continuous Replication environment
I recently ran into an issue in which the value for CopyQueueLength was displayed incorrectly from the Exchange Management Shell in an Exchange 2007 Standby Continuous Replication (SCR) environment. Here is the sample output from the Get-StorageGroupCopyStatus cmdlet:

We see a similar result from the Test-ReplicationHealth cmdlet:

Oddly enough, though, the SummaryCopyStatus is Healthy for the storage groups in question, as shown in the results of the Get-StorageGroupCopyStatus cmdlet. If we then check the CopyQueueLength via Performance Monitor, we find it looks normal:
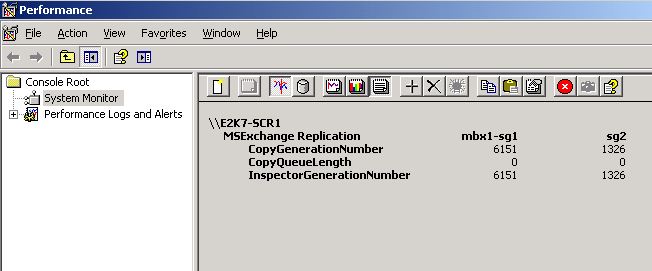
Notice anything interesting here? CopyQueueLength is at zero, as you might expect from a storage group in Healthy status, but notice the CopyGenerationNumber. The value displayed here matches what we show as the CopyQueueLength from the Shell. If we then take a look at the transaction log folder on the SCR target, we see that the last log copied matches this value (6151 decimal = 1807 hex):
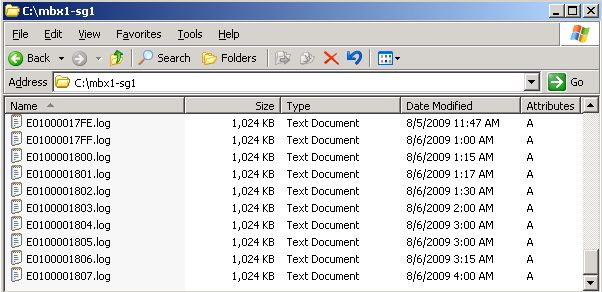
This shows that our logs are copying successfully and we already know that our storage groups are in Healthy SummaryCopyStatus, so this indicates that we have an issue with the way CopyQueueLength is being calculated in the Exchange Management Shell. This number is calculated by subtracting the Inspector Generation Number from the Latest Log Generation Number. We see in the Perfmon counter above that Inspector Generation Number is correct, but for some reason we are still calculating it incorrectly.
So far, I have only seen this issue in a specific set of circumstances, which are easily reproduced, as follows:
- Disable SCR by running Disable-StorageGroupCopy with the -StandbyMachine parameter.
- Leave the database and logs for the storage group in place on the SCR target (in other words, do nothing).
- Enable SCR by running Enable-StorageGroupCopy with the -StandbyMachine parameter, specifying the same SCR target as before.
You might do this in the real world if you wanted to change the ReplayLagTime parameter on the SCR copy of a storage group, since there is no other way to change it. In this scenario, we would not initially be copying any logs from the SCR source, which seems to be causing the Microsoft Exchange Replication Service some sort of issue. I have seen this issue correct itself over some time, once the ReplayLagTime has passed. To resolve the issue right away, you can restart the Microsoft Exchange Replication Service on the SCR target. The problem can be avoided altogether by deleting the database and logs from the SCR target so that the target is reseeded when you re-enable SCR.
As of now, there is no permanent fix to this issue, but it is continuing to be researched.
For more information on configuring Standby Continuous Replication, see this link: Managing Standby Continuous Replication
Comments
Anonymous
January 01, 2003
Hello, Thanks for this post. It got me out of a big pile of Dog-doo today. We had this issue occur with us running Exchange 2007 SP1 with SCR. I set up our storage group 2 with SCR and got it all happy. I then did some mailbox juggling and cleared out our storage group 1 . I Deleted SG01 and recreated it. I then enabled SCR on SG01 which caused SG02 CopyQueueLength to sky rocket. Again thanks for the post. Much obliged. JacobAnonymous
April 14, 2011
If you have lots of storage groups replicating between two servers, and you do this to just one of them, they all go into the same state.