On the Design of (and Sequencing for) Connection Groups
I constantly stress to my customers that significant assessment and planning revolving around the design and implementation of connection groups is essential to a successful lifecycle for virtual environments. One of the primary challenges with connection groups is that while understanding the mechanics of setting them up is quite easy; it is the sequencing thereof (as well as the understanding of how applications are affected by them) that is challenging.
I approach connection groups from a packaging and integration perspective. With that approach, I must plan out my strategy PRIOR to sequencing as retrofitting previous sequenced applications for connection groups can be quite risky and I recommend avoiding it.
Connection Group Architecture
I am not going to do too much diving into this point because there is already good information available. But a connection group is a virtual environment that contains more than one virtual package. All of the packages share the same virtual environment where the VFS and tokenized paths merge and the registries are converged. This gives sequencing engineers the flexibility to maintain packages independently and removes the redundancy of adding the same application several times onto a machine. Simple Concept. How about Execution?
Targeting
The first thing you need to reconcile will be targeting. Connection groups, like packages, can be targeted to users or to machines (globally published.) But targeting cannot overlap. All packages within a connection group must align. If a connection group target is per user, member packages must be published per user. If a connection group target is machine, member packages must be published to the machine.
Test Strategy
A connection group needs to be tested operationally and functionally by incorporating the connection group and package publishing life cycle into your QA\UAT application testing. Creating Connection groups in stand-alone mode allows for more seamless testing. It can also be automated using PowerShell. The general flow for this is as follows:
- Add and Publish packages
- If possible, test the functionality of the individual applications.
- Manually create the connection group XML descriptor document (to be used in stand-alone testing to verify functionality independent of delivery system.)
- Add and Enable connection group
- Test applications
- Disable and Remove connection group
- Unpublish and Remove packages
The Easy Part – the CG Descriptor
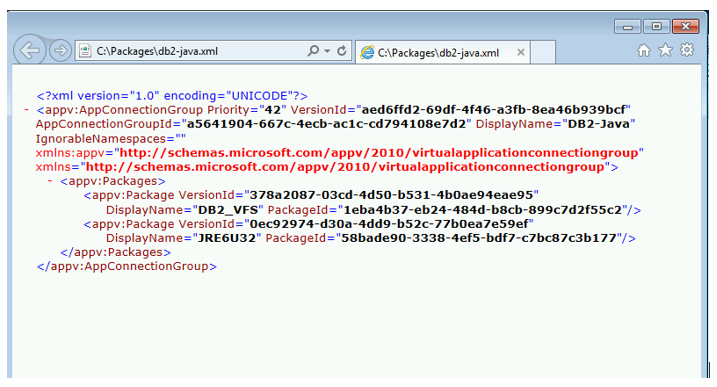
Creating connection group descriptor documents is a pretty easy process. All you need to do is supply a unique GUID for the connection groups VersionID and AppConnectionGroupId. The packages PackageId and VersionId fields come from the packages themselves. You then list the individual packages under the <appv:Packages> element in order of convergence priority. When you create connection groups using the management server or through SCCM, you are simply automating this very process. For more detail on this descriptor document and the format, please refer to the following Technet article: https://technet.microsoft.com/en-us/library/jj870811.aspx
The Hard Part: Actual Sequencing for Connection Groups
The Technet article above also mentions supported scenarios for using connection groups. Connection Groups are great in that they facilitate the use of primary applications virtualized separately from plug-in or add-in applications to be brought together. You can also use connection groups to leverage run-times or middleware without having to package everything together creating a servicing nightmare. The use of converging primary applications with add-ins and plug-ins is one of the most desired use cases of connection groups – HOWEVER, they can be the most difficult to implement if you do not understand how the add-in is loaded and used by the application. This is important information because it will govern how you sequence the application.
Not Every Application Loads an Add-in the same way.
Each type of load method will govern how we sequence. In earlier blog posts, we even learned that Office Add-ins are even registered or loaded differently depending on the addin.
(See the following: https://blogs.technet.com/b/gladiatormsft/archive/2013/07/25/app-v-on-that-failed-office-add-in.aspx
Most add-ins load because they are registered to load. Some add-ins load because there’s a variable or a search path. In some cases, they load because the add-in simply exists in a special directory. Understanding how the plug-in or add-in loads (and it’s format) will affect how you engineer your connection groups.
File Convergence
Only VFS Folders and tokenized paths merge. Pure and simple. If you suspect you will use an application or a plug-in within a connection group, you will need to sequence your application a specific way when it comes to selecting a PVAD (Primary Virtual Application Directory) and an installation directory. Unlike the former DSC (Dynamic Suite Composition) where the opposite was true, non-VFS folders do NOT merge. You will need to fully VFS the packages, that is, provide incorrect ‘Primary Virtual Application Path’ (PVAD) while sequencing the packages. This puts all the files of the package under VFS folder and nothing ends up in the root folder. For example, use C:\<PACKAGE_NAME> as the PVAD and install to its regular tokenized path (i.e. C:\Program Files, etc.) If the application does not normally install to a tokenized path, make sure you install to a different folder then the PVAD.
Registry Behavior across Connection Groups
Registry keys will merge across connection groups however the data and value overlap will be ruled by order within the connection group. To clear up potential issues with conflicts due to registry opacity configuration where key information may not resolve properly, I would consider placing virtualized plug-in/add-in information (where the add-ins were registered) ahead in the list inside the connection group descriptor document to ensure the right configuration wins out. This is especially important not only when it comes to add-ins but when it comes to VFS file convergence where you may have duplicate directories across multiple packages.
In the next few posts, I will discuss case studies on different types of applications.