Azure SQL Data Sync Test Drive and First Impressions
Azure SQL Data Sync is a service of Azure SQL Database that enables you to synchronize relational data you select across multiple cloud databases and SQL Server instances, in uni-directional or bi-directional way. This service is already in public preview, then you don't need to enable, it is already here but you will pay for the databases you will create. Version covered in this post is 2.0, last important refresh of previous long incubated V1 version. The reason I decided to test this feature, and that's why is attractive for me, is that in the Microsoft SQL Server universe, both on-premises and cloud, there is no multi-master concept: doesn't matter how many SQL Server database cluster nodes, replicas, Availability Group instances you have, you still have to write data to a single instance that is your master. There is only one exception using SQL Server box product, that is Data Replication feature, using Merge or Peer-to-Peer topologies. In these limited cases, you can submit your transactions to different multiple writable masters that will (slowly) replicate data each other. It is important to understand that all these technologies, including Azure SQL Data Sync, do not provide strong consistency, they do not provide distributed synchronous transactions between multiple writable masters. Instead, data replication is asynchronous, will have some latency, it does not follow original transaction order, conflicts may happen, and application must be able to tolerate this or designed to work with it.
Then, in which scenarios Azure SQL Data Sync would be useful? Whenever you need to replicate or synchronize data between different Azure SQL databases and SQL Server data sources, requiring multiple writable masters, where application does not rely on strong consistency and synchronous replication, you may want to consider this feature. Distributing data across regions and/or environments, for example in different Azure datacenters, or between on-premises and the cloud, are also valid scenarios. Reference data like list of customers, product catalogs and object directories are good real examples. Conversely, Azure SQL Data Sync is not appropriate if your application requires strong data consistency, is not appropriate to replicate a multi-terabyte OLTP database with millions of transactions per second, is not appropriate to build disaster recovery architectures, or to support migrations.
Limitations
Currently, this feature comes with some limitations you need to be aware, full details are reported in the article below, I reported here the main ones for your convenience:
Sync data across multiple cloud and on-premises databases with SQL Data Sync
/en-us/azure/sql-database/sql-database-sync-data
- Replication time: there is no SLA on replication latency.
- Limitations on service and database dimensions: max number of endpoints in a single sync group is 30, max 500 tables in a Sync Group, max 100 columns per table, max row size is 24MB, maximum replication frequency is 5 minutes.
- Performance Impact: Data Sync uses insert, update, and delete triggers to track changes. It creates side tables in the user database. These activities have an impact on your database workload, so assess your service tier and upgrade if needed.
- Eventual Consistency: since Data Sync is async, transactional consistency is not guaranteed. Microsoft guarantees that all changes are made eventually, and that Data Sync does not cause data loss.
- Unsupported data types: FileStream, SQL/CLR UDT, XMLSchemaCollection (XML supported), Cursor, Timestamp, HierarchyID.
Since this feature is still under development, additional capabilities will be available in the near future, top desired ones from my test are:
- Higher sync frequency, less than actual 5 minutes.
- Automatic management of table schema changes.
- Custom script (or procedures) to manage data synchronization conflicts.
- Include a graphical map, in the "Sync to other databases" ? page in the Azure Portal, reporting the Members and Hub in the "Sync Group" ?, healthy status and some replication performance numbers.
Overview
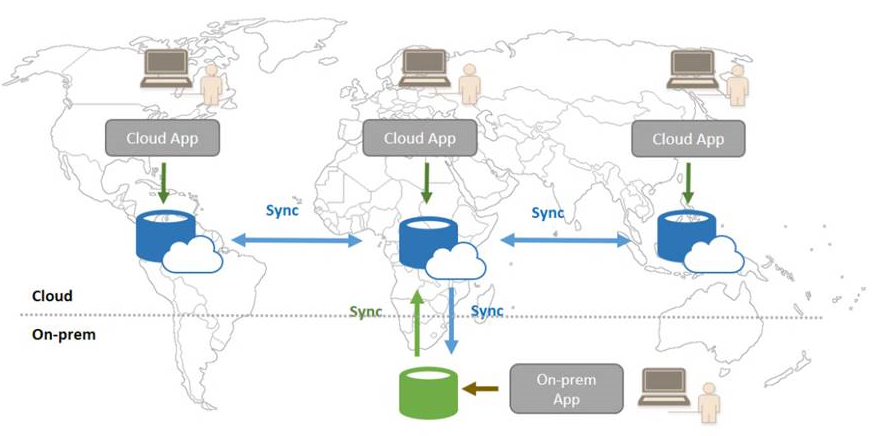
Before starting my drive test, we first need to introduce the basic concept of "Sync Group" ?, better to start with a nice picture:

"Sync Group" ? is a logical object that describe your synchronization topology, then including the list of your databases and tables, and common settings that are shared across all members in the group. Replication path follow a "Hub & Spoke" ? model where each "Spoke" (Member) synchronize separately with the "Hub" ?. Now let's go through a complete end-to-end provisioning experience, explaining details in each step.
First artifact you need to create is a kind of configuration database called "Sync Metadata Database" ?: it will contain all necessary metadata to maintain your "Sync Group?" (can be used for more than one), for a specific subscription, in a specific region. When enabling database sync, if not existing, you will be asked to create a new one. Microsoft recommends that you create a new, empty database to use: setup creates tables in this database and runs a frequent workload, there is no minimum recommendation for the service tier and size, but you need to be careful especially if you will use the same one for many databases and "Sync Group".
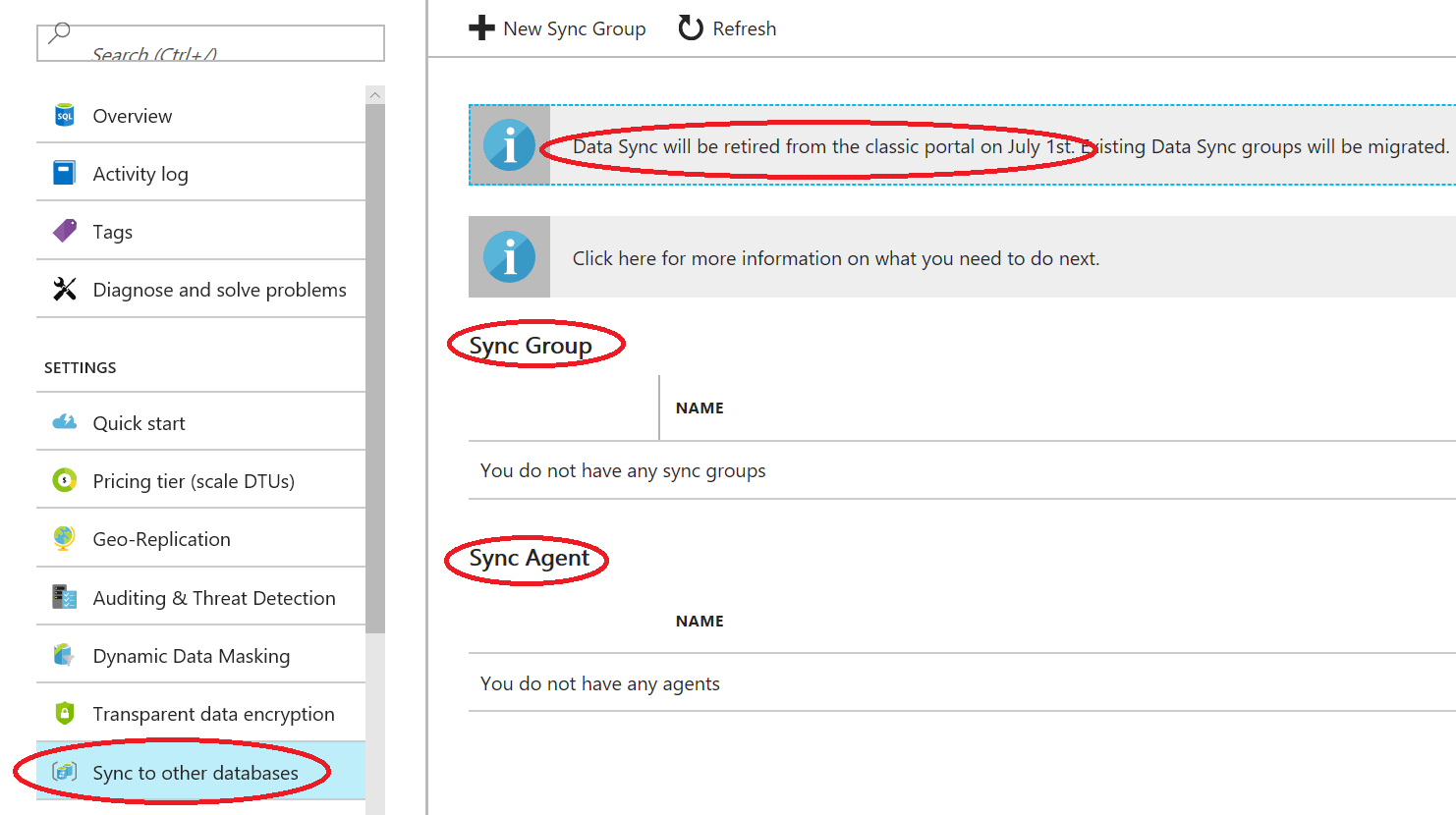 NOTE: As you can see, support in the old Azure Portal has been just retired from July 1st, 2017. If you have older version of Azure SQL Data Sync, please refer to the article below for migration as soon possible.
NOTE: As you can see, support in the old Azure Portal has been just retired from July 1st, 2017. If you have older version of Azure SQL Data Sync, please refer to the article below for migration as soon possible.
Migrating to Azure SQL Data Sync 2.0
https://azure.microsoft.com/en-us/blog/migrating-to-azure-data-sync-2-0
The way you access this feature is clearly telling you that Azure SQLDB is the central hub, you can also have "Spoke" ? from on-premises, SQL Server installed in Azure VMs (or from other Cloud providers) or other Azure SQL DB databases. Then, to start you need to open the new Azure Portal and point to one of your Azure SQL DB database, then click on "Sync to other databases": as you can see in the picture above, if there is no existing "Sync Group"?, you will be asked to create a new one.

In the first blade of the procedure, there are the most important settings for your new "Sync Group" ?:
- "Sync Metadata Database": as explained before, you can create brand new or re-use an existing one in the same region. For convenience, and since this is a test, I will use the same Azure SQL DB database also for the "Hub"? These are the requirements for the Sync database:
- Azure SQL Database of any service tier
- Same region as the "Hub" ? database of a "Sync Group"
- Same subscription as "Sync Group"?
- One per region in which you have a "Sync Group"? ("Hub" ? Database)
- "Automatic Sync"?: you can decide here if you want automatic system initiated data sync activity, or if you prefer manual triggering instead. In the former case, you will need to select a schedule, and then a frequency; in the latter case instead, you will need to use API to start the synchronization on-demand. It is worth noting that the maximum frequency you can set is 5 minutes, but the UI is showing you the possibility to select "Seconds"? unit measure. I can only guess here that in the future more frequent syncs will be possible.
- "Conflict Resolution": this is very important because will determine which data update your application can afford to lose in case of conflict: which update you want to discard if, inside the same sync cycle, the same record (determined by table Primary Key) is updated on both the "Hub" and the "Member"? Please note that this parameter is at the entire "Sync Group" level and cannot be changed without destroying and re-creating the entire structure.
If you are asking about custom script, or stored procedure, to resolve replication conflict, as happens in SQL Server Replication feature, then the answer is NO: at the moment, this is not possible, but it has been asked already to the owning Product Group, then stay tuned.
Now, let us move to the second step, as you can see in the picture below. First, you can add "Members"? database from other subscriptions (and logical servers) but must be under the same Azure Active Directory (AAD) tenant, then also from other regions if you want. Second, the interface here does not allow you to create new empty databases on the fly, you have to have already created them.
Third, and probably most important, what here is called "Sync Directions"?: remember, the data synchronization architecture and scheme here is "Hub & Spokes"?, and is directional, then you need to decide how data will spread inside the "Sync Group". It is important to keep in mind that synchronization tasks happen separately, and in parallel, for each pair formed by "Hub"? and "Member"? databases. Direct consequence is that you cannot assume the order by which each "Member" ? will be updated. In case of bi-directional replication, first data is downloaded from the Hub, then data is uploaded from the member to the hub.
IMPORTANT: A single database can be a "Member" ? in different "Sync Group", but in this case, you need to pay attention and avoid creating circular references as shown in the picture below. Currently Azure SQL Data Sync does *not* automatically manage this, and then you may end up in an infinite replication loop that will never terminate.

Adding On-Premises Members
Procedure to add a SQL Server instance and databases, from on-premises or from a VM in Azure, is almost identical from an Azure SQL Data Sync perspective: you have to download an agent, called "Sync Agent Gateway" ?, and install inside the network environment. While is possible to install the agent locally on the SQL Server box, it is not recommended for two reasons: first, you may not want to install something directly on the production machine: secondly, the agent is not cluster-aware then if using SQL Server Failover Cluster Instance (FCI), it is not supported nor will work in case of node failure. SQL Server 2005 SP2 and higher versions are supported.
Regarding the connectivity and security, is the agent that will initiate the outbound connection to the Azure SQLDB "Hub"? and "Metadata Sync" ? databases, then there is no need to open firewall port TCP 1433 to allow inbound traffic to your protected network. Now, you can copy the URL to download the agent and use it to download and install locally to your network (or Azure Virtual Network). It is worth remembering that inside Azure VNET, by default a Virtual Machine has full open outbound connectivity to the Internet: if you plan to use Network Security Groups (NSG) to restrict, please be aware of this port requirement.

SQL Azure Data Sync Agent
https://www.microsoft.com/en-us/download/details.aspx?id=27693

Be aware of the following pre-requisites before installing the agent, and please note that the 32bit version is explicitly required. In this case, installation order matters also.

Once installed you must run the configuration tool before being able to use it: provide the key generated in the Azure Portal, then supply the credentials to access the Sync Metadata Database.
Once registered the SQL Server instance and database, using either SQL Authentication or Windows Integrated, you should see something like the picture below. You can test the connection to the Azure SQLDB hub, to the local SQL Server instance, you can change the Agent Key and upgrade eventually the agent version. You can use the same agent to sync multiple SQL Server local instances.

Finally, you can go back to the Azure Portal and complete the member database configuration.

My Test Configuration
At the end, the Sync Group configuration I created is reported below:
- Hub
- Logical Azure SQLDB server igor-sqlsrv1 in West Europe, hub database name is igor-synchub-we, created in Subscription1.
- Members
- Logical Azure SQLDB server igor-sqlsrv1 is in West Europe, member database name igor-sqldb1, created in Subscription1.
- Logical Azure SQLDB server igor-sqlsrv2 is in North Europe, member database name igor-sqldb2, created in Subscription1
- Logical Azure SQLDB server igor-sqlsrv3 is in West Europe, member database name igor-sqldb3, created in Subscription2
- igor-sql2016vm1 is a VM with SQL Server 2016 installed in West Europe, member database name is igor-sqldb4, created in Subscription1
- Conflict Detection: Hub wins
- Data Directions & Conflict Detection
- Bi-directional Sync for member database igor-sqldb1
- From the Hub for member database igor-sqldb2
- To the he Hub for member database igor-sqldb3
- From the Hub for member database igor-sqldb4
Here is the picture from the Azure Portal related to the member list:

Enable Data Replication
Now is finally arrived the time to select which tables to include in our Sync Group replication topology. You can start clicking on the big Tables icon in the Azure Portal:

Depending on the replication direction, initial database to choose for selecting table may vary, in this case let us proceed from the Hub Database where I created a simple table called Table1. In order to be considered as a valid selection, a table *must* have a Primary Key (PK), this is required to locate changed items and manage conflicts. I also created another table called Table2 but as you can see, is not suitable for Azure SQL Data Sync replica since does not contain a PK. You are allowed to select specific columns you want to replicate, by default everything is selected, PK *must* be included.
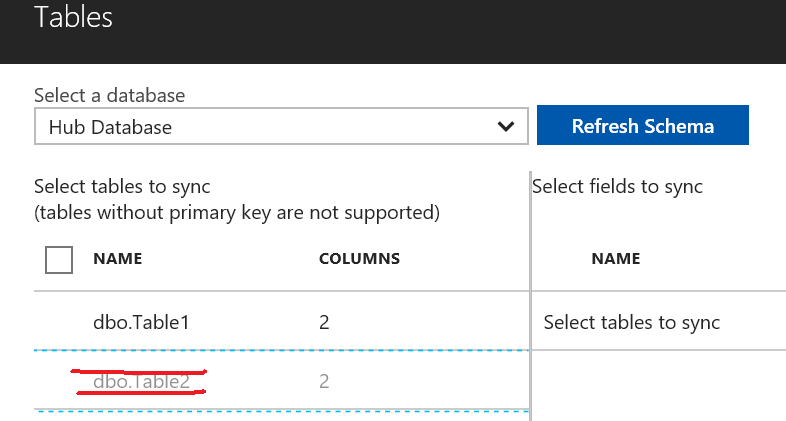 NOTE: I tried to find a way to horizontally select the rows to sync, but apparently there is no way to include a WHERE filter or insert a custom SELECT to specify which rows to include in the mechanism. I also tried to create a VIEW with a WHERE clause on the base table, but the GUI interface did not allow me to select.
NOTE: I tried to find a way to horizontally select the rows to sync, but apparently there is no way to include a WHERE filter or insert a custom SELECT to specify which rows to include in the mechanism. I also tried to create a VIEW with a WHERE clause on the base table, but the GUI interface did not allow me to select.
Finally, with at least one table added into the Sync Group, data flow is now active.

Once confirmed the tables that you want to include, Azure SQL Data Sync will do immediately create the database tables in *all* database Members, if not existing already (see later for more details) despite the replication direction you selected. For example, for member database igor-sqldb3, as you can read in the configuration section above, I selected To the he Hub, then from the Member upward, but the table has been created also here. What is important noting is that only the schema has been replicated, no data has been pulled down from the Hub database.

Once schema is applied to all Member databases, you will see that the button Sync is enabled: data replication will happen based on the frequency you specified, and that can be changed in the Sync Group? properties, but you can always force manual start if desired. This operation can be obviously also invoked using REST API and future PowerShell module.
Schema Changes
At this point, would be interesting to understand if this mechanism is tolerant to schema changes of the tables included in the Sync Group. Let us try to add, for example, a new (NULL-able) column named Value2 to Table1, insert a new row, fix (NULL) values with new default:
USE [igor-synchub-we]
GO
ALTER TABLE [dbo].[Table1] ADD [Value2] BIGINT DEFAULT (0)
GO
INSERT [dbo].[Table1] VALUES (2,'Added Column 2',0)
GO
UPDATE [dbo].[Table1] SET [Value2] = 0 WHERE [Value2] IS NULL
GO
SELECT * FROM [dbo].[Table1]
GO
Looking to the logs in the Azure Portal, this modification has been safely processed, two changes in rows have been detected:

Looking to all Member databases, row changes are replicated (Download: 2 changes applied) but now the schema change, all the existing rows do not have the additional column we introduced, but the mechanism continue to work without errors. My experiment is not finished yet, let us try to introduce the schema change using the Azure Portal interface and see what will happen:
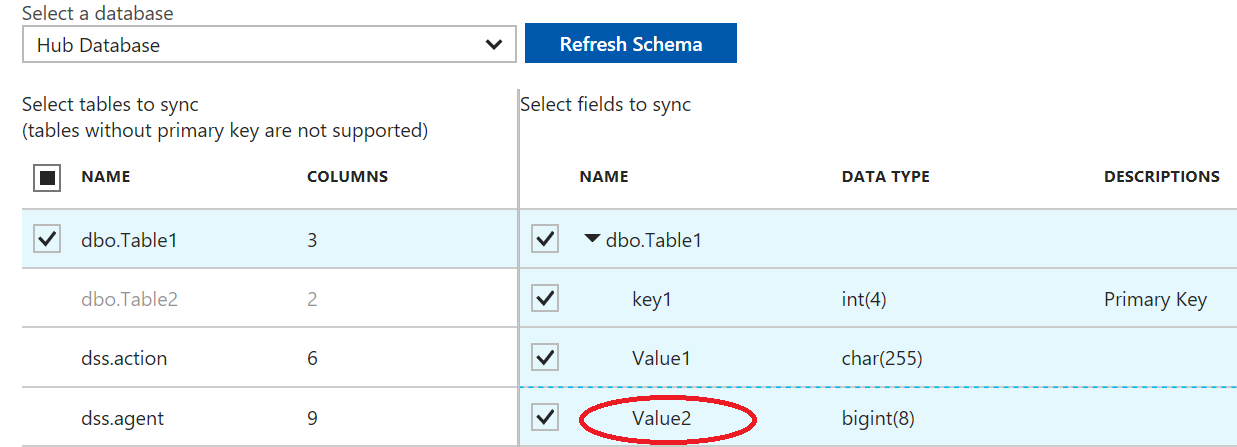
Apparently, the operation is succeeded, but looking at the error log, several error messages raised:
Database re-provisioning failed with the exception SqlException Error Code: -2146232060 - SqlError Number:207, Message: Invalid column name 'Value2'. SqlError Number:207, Message: Invalid column name 'Value2'. For more information, provide tracing ID ‘d94e2fcf-eed2-4f92-8ae3-88721d956cc1’ to customer support.
Ok, schema modification will not be propagated by the Azure SQL Data Sync, then the only remaining option is to remove the table from the Sync Group, apply the schema change to all Members, then adding back the table, including the additional new column. Please remember that this feature is still in preview.
Regarding error log, in the main blade for Data Sync Group, there is no way to select or download error messages, you should use general Azure Activity Log to achieve this task:

Finally, what happens if a table with the same name exists already, in the Member target database, when included in the sync set? In this case, synchronization mechanism will *not* overwrite it, but will apply necessary changes, for example will create TRIGGERS to manage data replication. This is powerful since you may want to customize the table structure with additional columns, constraints, indexes or triggers: be careful because you have this flexibility, but these changes must not interfere with the synchronization logic. During my tests, I verified that TRIGGER, FOREIGN KEY and CHECK constraints are not replicated downstream to the other databases in the Sync Group, then if you want or need them, you have to modify the target DBs manually.
Database Internals
Azure SQL Data Sync modifies the schema of your database adding object schemas, tables, triggers and stored procedures. This is very important to consider before enabling this mechanism because will alter your database structure and may conflict with your application. Let us take a small journey inside these modifications.
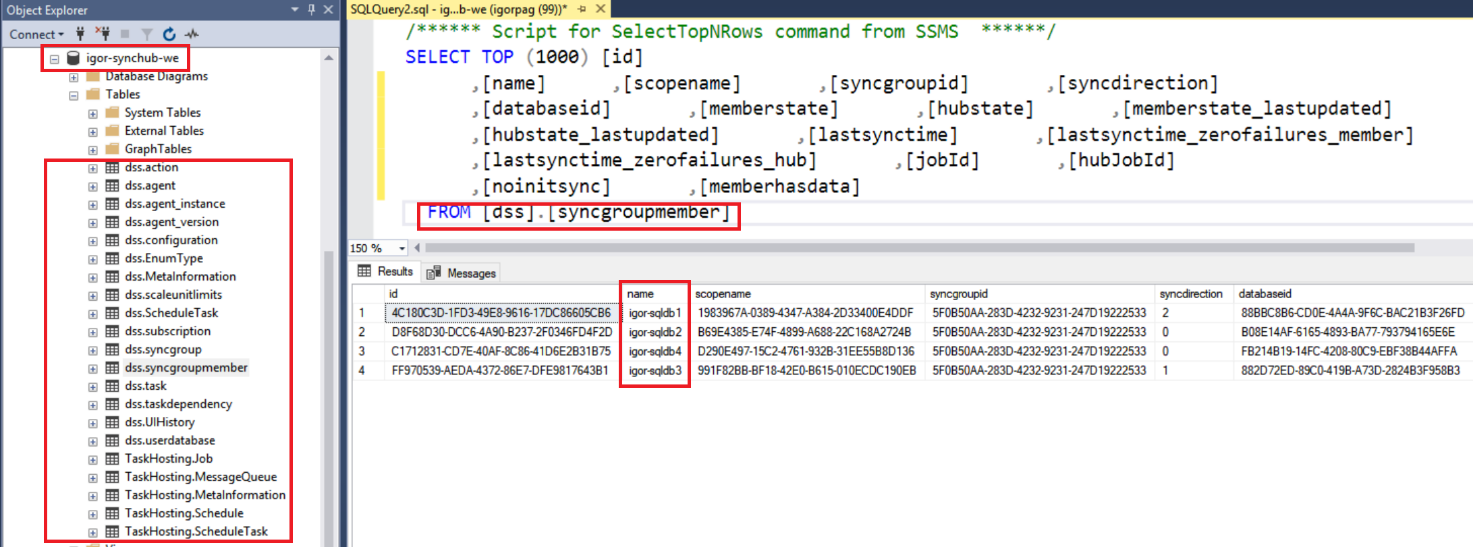
If you have minimal SQL Server experience, you can look very easily at the tables created by Azure SQL Data Sync setup inside the Hub Database, under the new dss and TaskHosting objects schemas. Obviously, you can look and do your read-only queries, but you should not alter in any way any content of these tables, otherwise you may destroy your Sync Group.
If you try to do the same inspection on the Member databases, you will see similar tables added to support data synchronization, but a different smaller set under DataSync schema, you can observe in the red rectangle below.
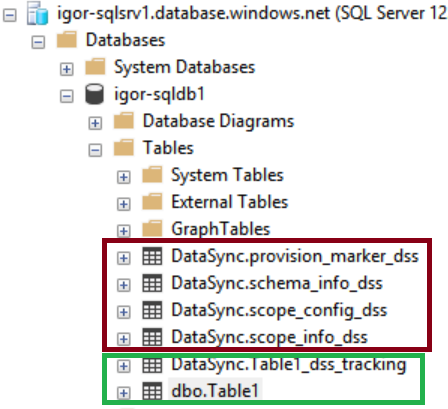
Those tables are always present, but the DataSync.Table1_dss_tracking is special: this kind of shadow table is created for every user table (in this case Table1) enabled for data sync, purpose is to accumulate changes in the rows of the original table. How this table is populated with data? If you give a look to the structure of Table1 and dependencies, you will discover this:
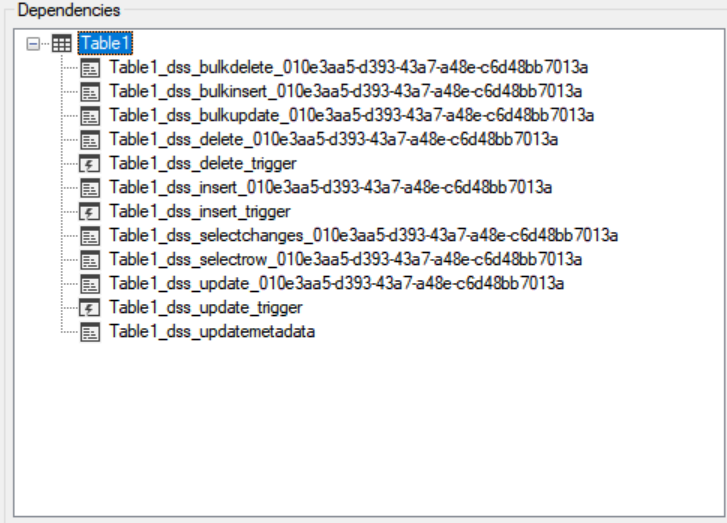
There are stored procedures defined for DELETE, INSERT and UPDATE and bulk-logged versions, and there are triggers (after-trigger type) defined for DELETE, INSERT and UPDATE operations. If you examine the code for INSERT trigger Table1_dss_insert_trigger you will see that the core is a T-SQL MERGE statement that will detect inserted row, then will upsert data in the shadow table [DataSync].[Table1_dss_tracking] :
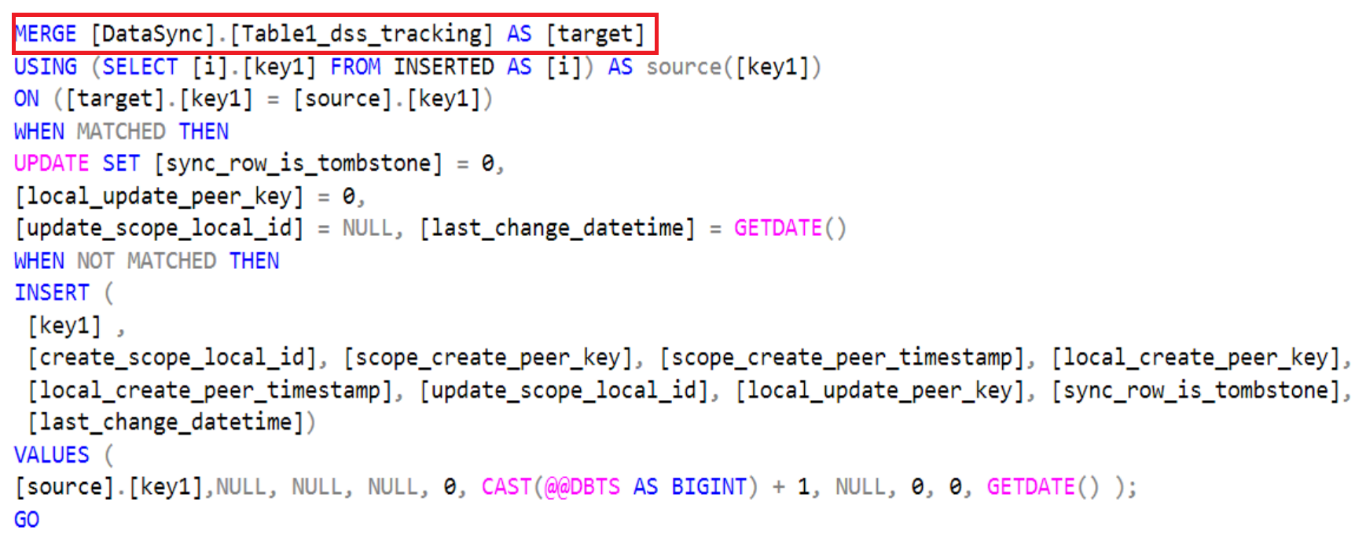
The INSERT clause is very interesting: as you can see above, the shadow table is *not* accumulating the entire row (all column values), but only the Primary Key (PK) along with some metadata information, including timestamp of the last modification. If you are a DBA, you will recognize here something similar to Change Tracking, not really Change Data Capture, well known SQL Server box product features. The tracking records will not be deleted immediately. Tracking records for deleted rows will be removed after a retention period of 45 days. There are optimizations that can avoid using the tracking tables during initial sync, after the initial sync all the changes are going to be tracked in the tracking tables. Index fragmentation may happen, you can refer to this article to reorganize the index. It is worth noting that in case of multiple updates to the same row, there will be only one record in the shadow table including the PK and timestamp of the latest update.

Finally, table [dss].[configuration] is very interesting since it contains main configuration parameters for the current Data Sync Group. I found very interesting, in the Hub Database, the table [dss].[configuration] , specifically parameter SqlSyncProviderBatchSizeInMB with value (24): it seems that Azure SQL Data Sync max batch size is 24MB and max 50,000 rows per batch, when applying data modifications to synched tables.
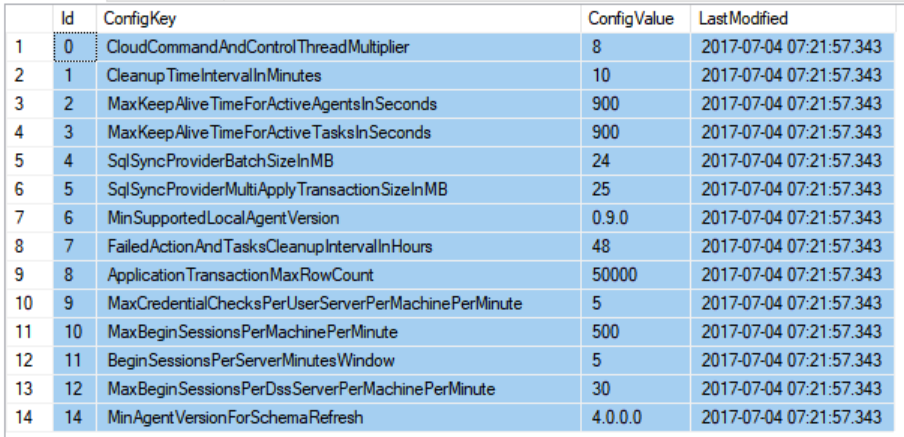
What I expected to find here is something indicating how long a database can be disconnected before being marked ad offline, that is not synchronized anymore. I do not see in the list above, but downloading the full documentation in PDF format from here, I found that the limit is 45 days:
SQL Data Sync (Preview) removes databases that have been offline 45 days or more (as counted from the time the database went offline) from the service. If a database is offline for 45 days or more and then comes back online its status is set to Out-of-Date.
What is totally missing also from the online documentation, at the moment, is more details on the retry mechanism and how long it will last.
Programmability
Today, you can play with Azure SQL Data Sync using the new Azure Portal interface. You can find the REST API specifications at the link below; PowerShell support is coming soon and will be available for the general availability of this feature.
Download the SQL Data Sync REST API documentation

Final Remarks
For the latest announcement on Azure SQL Data Sync, see the blog post below, more will come when Product Group team will announce general availability:
Azure SQL Data Sync Refresh
https://azure.microsoft.com/en-us/blog/azure-sql-data-sync-refresh
Regarding pricing, it has not disclosed yet, but you will pay for sure for all your databases, including Sync Metadata Database and Hub Database, depending on the service tier you selected. If replicating data across Azure regions, you will be charged for this traffic. If you have also on-premises members, only egress traffic exiting from Azure will be counted, igress traffic will not.
Full Azure SQL Data Sync documentation can be downloaded from here in PDF format.
If you want to post feedbacks and ideas for this feature, you can use the link below, Product Group will look at it and post a response.
How can we improve SQL Data Sync?
https://feedback.azure.com/forums/217535-sql-data-sync
Thanks for your patience, hope you appreciated this content.
You can follow me on Twitter using @igorpag.
Regards.