Care and Feeding of Predictive Maintenance Solutions
This post is authored by John Ehrlinger, Data Scientist at Microsoft.
Microsoft has recently launched Azure Machine Learning services (AML) to public preview. The updated services include a Workbench application plus command-line tools to assist in developing and managing machine learning solutions through the entire data science life cycle. An Experimentation Service handles the execution of ML experiments and provides project management, Git integration, access control, roaming, and sharing of work. The Model Management Service allows data scientists and dev-ops teams to deploy predictive models into a wide variety of environments. Model versions and lineage are tracked from training runs to deployments while being stored, registered, and managed in the cloud.
Once AML Workbench is installed, the app connects to a Gallery of prebuilt real world data science scenario projects to help new users explore Azure ML, as well as give users a jump start on their specific data science scenarios.
The AML gallery currently contains two predictive maintenance example scenarios:
- A PySpark implementation using a random forest of decision trees classifiers:
/en-us/azure/machine-learning/preview/scenario-predictive-maintenance - A deep learning approach using an LSTM classifier:
/en-us/azure/machine-learning/preview/scenario-deep-learning-for-predictive-maintenance
This post is written specifically to prepare users interested in using their own data to deploy customized predictive maintenance scenarios. We will discuss the prerequisites to building and requirements for maintaining an intelligent, ML predictive maintenance solution. We will define what predictive maintenance means and discuss data requirements for creating a solution. We also discuss the end result of the product and how to maintain your operationalized ML solution.
This article focuses on the details of defining and understanding the target of the predictive maintenance solution, the failure events we'd like to prevent. We will ignore the feature variables which the model will use to predict the target, which has been covered in the Cortana Intelligence predictive maintenance playbook. These feature variables are typically the easier part of a predictive maintenance solution that are collected to monitor operating conditions. Even though outside the scope of this article, it is still important to use subject matter experts in guiding which features can be helpful in predicting the target in order to build an effective predictive maintenance solution.
Equipment Maintenance
To understand predictive maintenance, we first contrast it with other maintenance strategies. There are three general classes of equipment maintenance strategies, each with a specific set of benefits and drawbacks.
1. Reactive Maintenance
Reactive maintenance is a replace after failure strategy. This strategy ensures that each component has the maximum possible service life but could cause down time or safety issues when the component does fail.
The following figure details the life of a set of 50 devices (stacked along the y-axis) and the service life time is aligned along the x-axis. Each device fails at some point in time denoted by the red "x", ending the devices service life. It's obvious that this strategy maximizes device life (utilization), but at the cost of failures at unknown time.
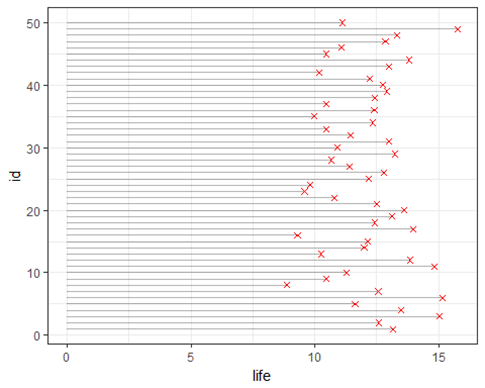
Reactive Maintenance strategy
A reactive maintenance strategy is acceptable when there is little safety risk, or if the device failure is not catastrophic, causing more expensive damage. This is typically the strategy we use for home items and even some auto parts.
In industrial scale reactive maintenance settings, it may be valuable to the business to add an ML solution that notifies the business when a failure may have occurred. A common approach would be to use anomaly detection, an unsupervised method designed to detect when a device is behaving differently than expected. These different behaviors may be related to the failure type of interest. An anomaly detection solution can be more accurate than simple rule base failure detection methods and is useful when notification could be used to prevent more expensive failures or outages.
2. Preventative Maintenance
Preventative maintenance replaces components on a specific schedule, regardless of remaining useful service life. This strategy minimizes downtime and maximizes safety by setting the replacement schedule to minimize component failures. Preventative maintenance can additionally control some maintenance costs since the maintenance schedule and costs are known a priori.
Using the same devices in the previous figure, imagine we instituted a preventative maintenance strategy of replacing devices at a service life time of 10 (indicated by the vertical dashed line). The following figure shows how this strategy can prevent a large number of failures. However, many of these devices could have been in service much longer. It is also still possible to miss some failures.
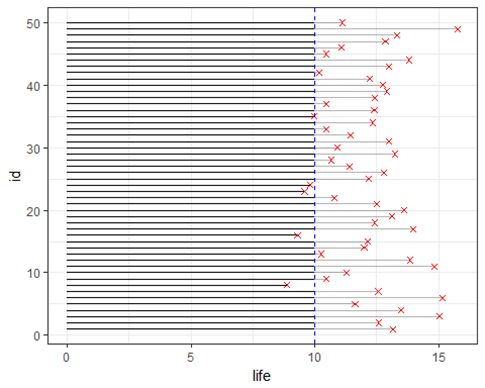
Preventative Maintenance strategy
The preventative maintenance schedule time may be chosen by determining how many failures are tolerable for the business, either using cost, customer safety or some combination of related factors. In our example case, we allow about 10% of the devices to fail. We could shorten the acceptable service life, if we wanted to ensure no failures, or lengthen it, if we were tolerant of more failures.
3. Predictive Maintenance
The goal of the predictive maintenance strategy is to both maximize the useful service life of equipment and prevent failures at the same time. Instead of replacing components on a fixed service life schedule, a perfect preventative maintenance schedule would move the maintenance schedule to a "just–in–time" approach.
The following figure shows how a perfect preventative maintenance strategy could replace any device directly before a failure, maximizing component life, and minimizing failure events.
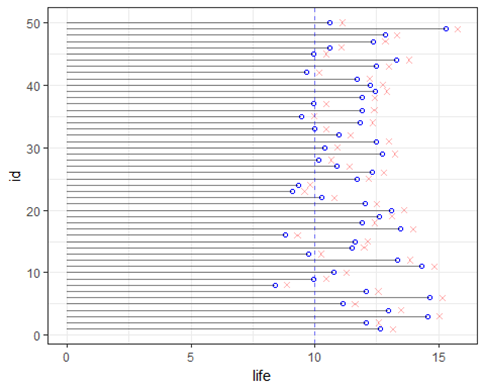
Predictive Maintenance strategy
Where reactive and preventative maintenance strategies require some initial thought, once the strategy is in place, maintaining the strategy requires little effort. Predictive maintenance strategies, in contrast have assumptions and consequences during and after implementation. The remainder of this article will address some of these concerns.
Predictive Maintenance Requirements
A predictive maintenance ML strategy is a supervised learning process, meaning we have data detailing the full life history of a series of devices. We use this data to characterize how other devices, unseen but assumed to be identical, would behave over their service life.
In order to ensure you have the complete life history of your set of training devices, a supervised ML method will require at least the following:
- Component life history: The model needs to know when each component was placed into service (this is ), and any periods when it was removed to properly account for service life hours.
- Component Maintenance history: A failure is often only noted during a maintenance visit, which complicates determining exactly when the failure occurred. Maintenance records may also be useful by knowing when a technician inspected the device. We can use this information to infer the device was actually working correctly. This information can then be used to improve the accuracy of the predictive maintenance model.
- Event history: To predict failures, the data must contain examples of those failures. A rule of thumb is that your data should contain on the order of 10-30 events per feature you'd like to resolve. This means that your data should contain at least 300 examples of the failure types you are interested in predicting to build a reasonable ML solution. More examples will result in better, more generalizable predictive maintenance solutions.
In general, you will have a mix of devices that have failed, and those that are still in service. Or you may have devices that have failed for the specific reason you are interested in, collected with devices that have failed for other reasons. In both cases, using all the available devices both having and not having failures of interest will help the ML solution discern between the different device behaviors.
Predictive Maintenance Deployment
The examples in the AML gallery describing how to build a predictive maintenance solution. Microsoft has also published many documents targeted to other platforms:
- Azure Machine Learning – using PySpark in a predictive maintenance real-world scenario.
- Predictive Maintenance Modeling Guide using R in the Azure ML Studio.
These documents detail the details of feature engineering, ML experimentation, and deployment of a predictive maintenance web service. We refer you to these and other solution approaches referenced therein for the approach that most closely matches your requirements.
Once you have deployed your web service, what will you get and how can the solution guide business decisions?
The predictive maintenance ML solutions are time series (sequential predictions at regular intervals) classification (failure/healthy) models. Classification models can return either the resulting binary answer (fail/healthy), or a probability that the device will fail. The time series approach specifies the failure may occur within a specified window of time.
With the binary return value (fail/healthy), the model can return a set of devices that should be maintained within the time window. With the probability, the model can return a ranked list of devices at risk of failure, where the order indicates devices most probable imminent failures. The decision between these result choices should be driven by the underlying business strategy.
The deployment idea is to periodically run the full population of devices currently in service through the ML web service to score each device. The scored results can be used to either deploy maintenance events, or guide the human in the loop, a maintenance subject matter expert, to make more inform choices on where to deploy limited maintenance resources.
Predictive Maintenance Maintenance
A frequent request centers on retraining the predictive maintenance model. When using standard time series models, the approach is to retrain continually, using the current set of observed data to predict forward in time. In this way, the model is continually being updated to capture changes in behavior not seen in training the original model.
In predictive maintenance settings, retraining our model becomes difficult. To see why, remember that the goal of the predictive maintenance solution is to remove components before they fail. The issue becomes clear by examining the predictive maintenance figure above. If we created a perfect model, the solution would remove all failure events from the population. Since having the failure events is critical to training the supervised method, retraining a predictive maintenance solution would actually degrade the model, since there is now no new information from which the model can learn.
Also note that by removing the failure events, we can't infer when the device would have truly failed. This is also the main problem when attempting to transition away from a preventative maintenance strategy. The preventive maintenance figure indicates we have removed the ability to know when the device will actually fail. Because of this, once a predictive or preventive maintenance strategy has been deployed, changes to the system must be carefully weighed. As your business moves from away reactive maintenance, new restrictions on changes possible in the future are imposed.
- Removing either an implemented predictive or preventive strategy will certainly lead to an increase in the number of failures.
- Because predictive and preventive maintenance are designed specifically to change the predicted quantity, any data collected during this implementation must be interpreted with that information in mind. This is similar to knowing the maintenance history when building the solution to begin with.
- The solution implementation makes retraining impossible (under a strict definition), because we would need to know that the failures we prevented were true failures and this information is no longer available.
This does not mean that we cannot improve on the solutions once implemented. One option would be to build and deploy an initial predictive maintenance solution and continue to collect failure data. We cannot hope to deploy a perfect solution that captures all failures. Instead, we assume that the model has captured the most likely failure modes, and by collecting more data, we can add an additional model to capture the next level of failures. Each subsequent model would be additive in nature and ranking of failures can be combined to further reduce the failure rate.
An alternative strategy would be to deploy the model on one population of devices and continue to collect data in a separate population. In fact, sometimes serving the model to one population of devices is straight forward as companies may have different types of maintenance contracts with different end customers operating the same or similar devices – one set of customers may continue with a no-maintenance contract plan where failure data could still be able to be collected. A new model could then be tested on the combined population to verify the captured failures predicted by the original model. If the level of prediction is acceptable within some measure, the business could then decide to replace the original model.
It could also be possible to add a test-to-failure protocol to either verify model predictions, or to extend service life beyond a preventative service life time frame. This would incur the additional expense of bench test operations which could easily out pace any financial advantage of an ML maintenance strategy. This trade off would have to be quantitatively determined based on business criteria and operating expenses.
Conclusion
In this age of Artificial intelligence (AI) for everyone, much thought has been given to how to build and deploy ML solutions. This article details some of the work required both before and after the ML solution has been developed.
- What data is required? Am I ready to develop an ML solution? Have I captured enough failure events to build a useful predictive maintenance solution?
- What will be the actual product delivered? Once I have a solution, how can I use this to improve my maintenance strategy?
- What should we do after we have brought these solutions into our business practice? How can I improve my solution going forward?
This article was written specifically for predictive maintenance settings when the goal of the model is to remove the events the model is predicting. However, many of these ideas are just as useful for any machine learning solution you are planning on bringing into your business practice.
Use intelligence when deploying an Artificial Intelligence solution into your business practice.
John
@JohnEhrlinger | LinkedIn