Ax 2012 - RecordInsertList - Performance series (Part 1)
Introduction
From MSDN:
This class allows you to insert more than one record into the database at a time, which reduces communication between the application and the database.
Records are inserted only when the kernel finds the time appropriate, but they are inserted no later than the call to the insertDatabase. add and insertDatabase methods. The RecordInsertList.add and RecordInsertList.insertDatabase methods return the accumulated number of records that are currently inserted, which allows you to keep track of when the records are actually inserted.
The array insert operation automatically falls back to classic record-by-record inserts when non-SQL based tables are used (for example, temporary tables), or when the insert method on the table is overridden (unless it is explicitly discarded).
RecordInsertList is similar to RecordSortedList, but it has built-in client/server support (it automatically packs data from one tier to another when needed), and it lacks the sort order features that are available in RecordSortedList.
In my words:
The RecordInsertList class supports inserting many records of a given type into the database at once, avoiding the overhead that could happen if we have a loop that inserts a single record per iteration.
When the insertDatabase method is called, Dynamics Ax Runtime packs the buffers to be inserted and send them to SQL Server. At SQL Server, the package is extracted and SQL Server will insert them record by record. Since many buffers are being packed together, we save a lot of round trips from AOS to SQL Server. The number of packages will be calculated accordingly to the size and quantity of the records to be inserted and to Ax server buffer size. If the insert or the aosValidateInsert methods are overriden at the table, then, insertDatabase will execute the "record by record" insert. The package approach will also not be employed if the table has a container field or a memo field. Nevertheless, during the instantiation of the RecordInsertList, either the insert and the aosValidateInsert can be skipped. Please, be very careful when skipping these methods.
The usage is pretty straight forward. First of all, you need to instantiate the a RecordInsertList specifying the table id of the table where the records will be inserted. Then, add the buffers at the list using the add method. Finally, call the insertDatabase method in order to insert all the records at once.
Example
Suppose that we have a table called MyInvoice with 4 fields: CurrencyCode, InvoiceAmount, Qty and InvoiceId. Given to a requirement, we need to insert 10k registers into the database. Inserting thousands of registers into the database during the daily activities of ours customers may be painfull since they need to share server resources with tens, may be hundreds, of other users.
Slow mode
We could add 10k records into this table through the below loop. The insert statement is being called at the end of each iteration. This is really expensive!!!
static void insertIntoMyInvoiceThroughLoop(Args _args)
{
int i;
MyInvoice myInvoiceRecord;
int startTime, endTime;
startTime = WinAPI::getTickCount();
for (i = 0; i < 10000; ++i)
{
// Initializing the buffer with dummy values
myInvoiceRecord.InvoiceAmount = (i + 1) * 100;
myInvoiceRecord.CurrencyCode = 'REA';
myInvoiceRecord.Qty = (i + 1) * 10;
myInvoiceRecord.InvoiceId = int2str(i + 1);
// Record by record insert operation
myInvoiceRecord.insert();
}
endTime = WinAPI::getTickCount();
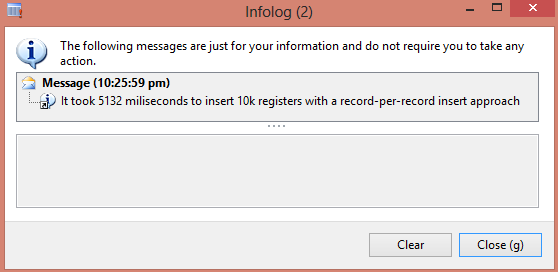
info(strFmt('It took %1 miliseconds to insert 10k registers with a record-per-record insert approach',
endTime - startTime));
}
After running this job on my test machine for a couple of times, the time spent was around 5 seconds, as you can see on the infolog window below.
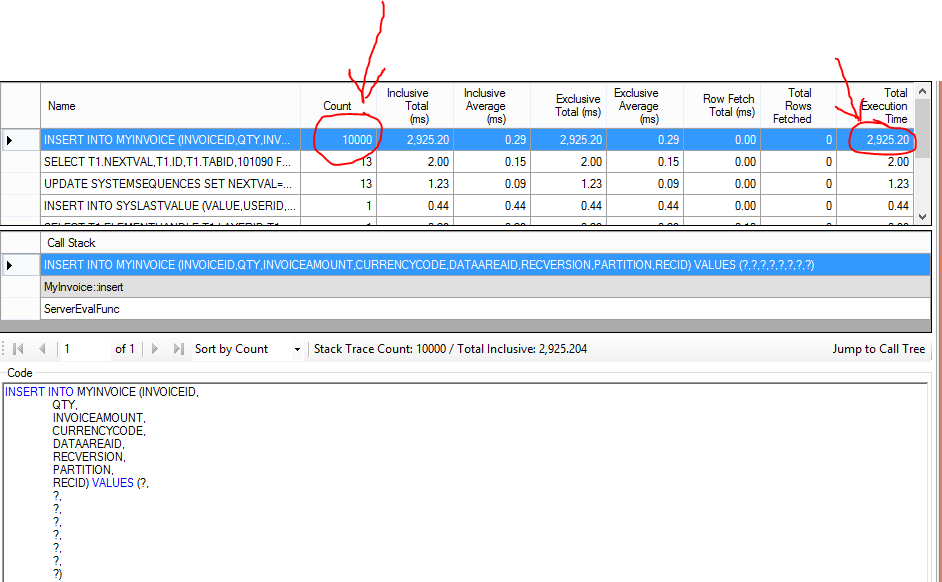
We should also take a look at Trace Parser in order to realize what is going on behind the scenes. Notice that the insert statement has been executed 10k times and the job spent almost 3 seconds just with these statements. Trace Parser is a powerful tool that makes very easy for developers to assess performance and to find bottlenecks. For the sake of simplicity, I will not give any details about Trace Parser in this post.
Fast mode
If you are not comfortable with such amount of time, we could enjoy RecordInsertList. At the end of each iteration, the buffers are just added to the collection. Finally, when all the buffers have been added to the collection, the insertDatabase method is called. The below job shows the usage.
static void insertIntoMyInvoiceByRecordInsertList(Args _args)
{
int i;
MyInvoice myInvoiceRecord;
int startTime, endTime;
// This collection will store the records that must be inserted into the database
RecordInsertList invoicesToBeInserted = new RecordInsertList(tableNum(MyInvoice));
startTime = WinAPI::getTickCount();
for (i = 0; i < 10000; ++i)
{
// Initializing the buffer with dummy values
myInvoiceRecord.InvoiceAmount = (i + 1) * 100;
myInvoiceRecord.CurrencyCode = 'REA';
myInvoiceRecord.Qty = (i + 1) * 10;
myInvoiceRecord.InvoiceId = int2str(i + 1);
// Instead of inserting the record into the database, we will add
// it to the RecordInsertList array
invoicesToBeInserted.add(myInvoiceRecord);
}
// After fulfilling the array with the elements to be inserted, we are
// read to execute the insert operation
invoicesToBeInserted.insertDatabase();
endTime = WinAPI::getTickCount();
info(strFmt('It took %1 miliseconds to insert 10k registers with a RecordInsertList approach',
endTime - startTime));
}
Now, infolog presents a pretty better value.
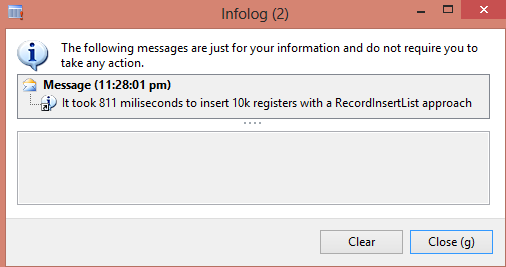
Again, it worths analyzing Trace Parser results. The insert statement was executed just 141 times and the job spent 297 miliseconds to insert the 10k registers into the database.
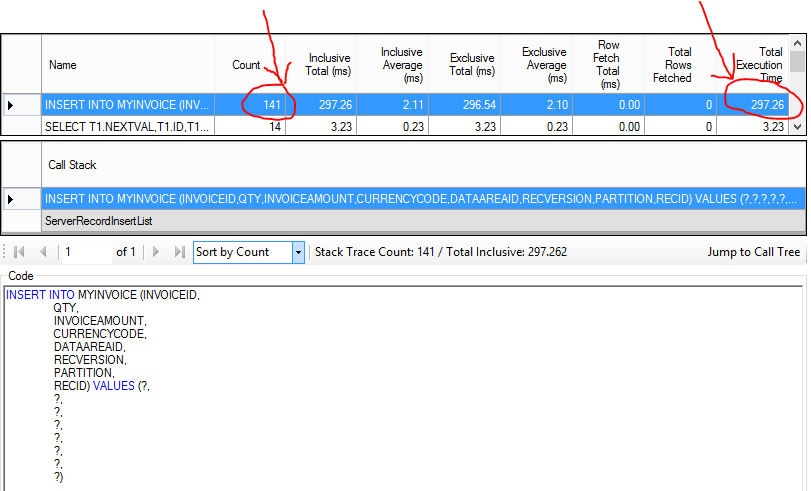
What happens when the insertDatabase inserts a register that causes a failure?
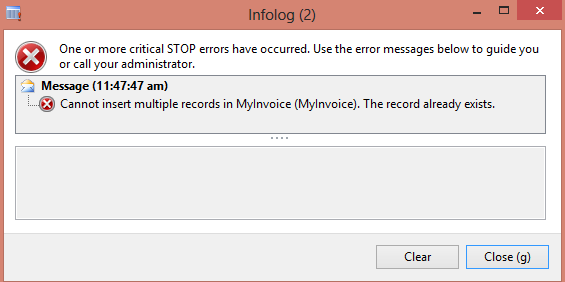
If some of the insert statements fail, we have no clue about which insert statements were correctly executed.
For example, I have inserted a register with the invoiceId equals to '100'. So, one of the insert statements must fail because it will also try to insert a record with the '100' value for this field.
An infolog error message will popup to inform about the problem and if query the db, some of the records were indeed inserted.
static void insertByRecordInsertListWithFailures(Args _args)
{
int i;
MyInvoice myInvoiceRecord;
// This collection will store the records that must be inserted into the database
RecordInsertList invoicesToBeInserted = new RecordInsertList(tableNum(MyInvoice));
// this record will cause a failure due to a dupplicated invoiceid. This field must be unique
myInvoiceRecord.InvoiceId = '100';
myInvoiceRecord.InvoiceAmount = 0;
myInvoiceRecord.Qty = 0;
myInvoiceRecord.CurrencyCode = 'REA';
myInvoiceRecord.doInsert();
for (i = 0; i < 10000; ++i)
{
// Initializing the buffer with dummy values
myInvoiceRecord.InvoiceAmount = (i + 1) * 100;
myInvoiceRecord.CurrencyCode = 'REA';
myInvoiceRecord.Qty = (i + 1) * 10;
myInvoiceRecord.InvoiceId = int2str(i + 1);
// Instead of inserting the record into the database, we will add
// it to the RecordInsertList array
invoicesToBeInserted.add(myInvoiceRecord);
}
invoicesToBeInserted.insertDatabase();
}
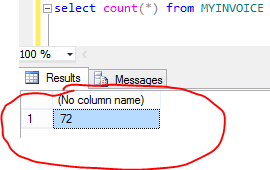
Sql server shows that 71 registers have been inserted by the insertDatabase method, plus the one insert that we did at the beginning of the method
Summary
This post demonstrated how to boost bulk insert operations through RecordInsertList class. Avoid doing adopting an insert per iteration approach. Besides improving the performance, the usage of this helper class will not scratch good OO design. Be aware about the behavior when a failure occurs.
The attached xpo Project contains the code of this post.
My next post of the Ax Performance series will highlight the scenario where the insert method has been overriden and we try to use the RecordInsertList.
PrivateProject_RecordInsertList.xpo
Comments
Anonymous
January 27, 2014
There is a problem I'm having with the RecordInsertList class and AX insert functionality. Allow me to elaborate. In a batch job we're filling two tables. Let's call them "Customers" and "CustomerProperties". CustomerProperties contains a RefRecId field referring to a RecId in Customers. Imagine a logic like the following: customersBuffer.FieldX = 'value'; customersBuffer.insert(); customerPropertiesBuffer.RefRecId = customersBuffer.RecId(); customerPropertiesBuffer.insert(); This works fine. Now, for performance reasons, we want to use two RecordInsertLists instead of doing record-by-record operations. Obviously, because of the way RecordInsertList works, there's no RecId available rightaway. Using the systemSequence class/table + the knowledge that the default RecId in any table is 5637144576 I wrote a class that inherits from RecordInsertList, accurately predicts the RecId that the future record will have, and returns it to the user, it works a bit like this: RecordInsertList_plus rilCust = new RecordInsertList_plus(tableNum(Customers)); RecordInsertList_plus rilProp = new RecordInsertList_plus(tableNum(CustomerProperties)); customersBuffer.FieldX = 'value'; rilCust.add(customersBuffer); customerPropertiesBuffer.RefRecId = rilCust.mostRecent().RecId; rilProp.add(customerPropertiesBuffer); This works fine - assuming that only one thread is writing to the Customers table. If this is not the case, then the "predicted" RecIds will most likely not match the actual RecIds that will be written to the table. To circumvent this, one might attempt to suspend RecId generation as long as the RecordInsertList is active and to remove the suspension in an override of the insertDatabase method. This, however, would cause other threads to crash (cause they won't set a RecId and thus violate the constraint set in SQL), plus if a programmer forgets to call the insertDatabase method and the RecordInsertList_plus goes out of scope, the suspension will remain active indefinitely. Both options are not desirable. What I actually want is the following: can AX, even if RecId suspension is not set, be stopped from generating a RecId when inserting a record if a RecId has already been set on it? I'm assuming this happens in the kernel, but you never know... Maybe what I want is entirely impossible.Anonymous
January 28, 2014
Hi Cedric Haegeman, May be you could employ the Unit of Work pattern. It has been introduced in Ax 2012 and it takes care of all these things. I have just written a post explaining how to use it. (see the 5th post of the performance series) Please, let me know if this pattern didn t help you. TksAnonymous
January 29, 2014
Well, I'm using AX2009 (I'm trying to increase performance of MS's preprocessing upgrade scripts), but the UnitOfWork post was still very valuable information, many thanks! I'll have to investigate if something similar can be done in AX2009.Anonymous
January 30, 2014
Hi Cedric, have you executed trace parser? May be there are other places where you can safely tune the code. Trace parser is now available for Ax 2009 as well. Suspending recid generation may not be very safe. Tks.Anonymous
March 20, 2014
hi, good post!! i have a doubt about error message "The record already exists", if i dont set constraint to unique index, why the kernel throw it? thanks for your comments.Anonymous
March 23, 2014
Thank you for your comment Esat. You are totally right, the unique constraint must exist at the table, so that the kernel can throw this message.Anonymous
November 20, 2014
I don't like systems that have no clear framework for business logic integrity .. E.g. in reqtrans (master planning) in ax2012 a bulk insert is used, but that enforces you to develop logic in multiple places since e.g. insert() method is not called from bulk insert and there fields are set that don't need to be set in the classes code, but in central place. What you see in this approach, you spread business logic, which is at all time killing for maintainability and predictability.... Maybe unit of work solves this issue, but there should be basic integrity layer that ensures mandatory business logic cannot be bypassed ... There will definitely be a guideline for this, but I also see that many people don't follow guidelines and just do what they feel is ok. If you are allowed to use bulk insert and bulk insert does not use insert() method then standard ax should in my perception not put mandatory business logic in insert method! bcz that is bypassed in case of bulk insert.Anonymous
March 03, 2016
Thanks Savio for the nice explanation...!!!