BizTalk Server: Grouping and Sorting Operations Inside BizTalk Maps Using the Muenchian Method
Introduction
Grouping is a common problem in XSLT style sheets, and is really simple to accomplish using XSLT 2.0 however, using XSLT 1.0 can be a challenger trying to accomplish the end result and at the same time keep your eyes on performance.
Making available instruction like xsl:for-each-group for iteration across a series of groups and with the possibility for setting criteria for grouping: group-by, group-adjacent, group-starting-with, or group-ending-with, XSLT 2.0 makes grouping really easy and optimized. **The main problem is that BizTalk Server only supports XSLT 1.0! **
One of the more challenging things to do in XSL 1.0 is grouping and sorting operation. XSLT 1.0 lets you sort elements, however, it will force you to jump through several hoops to do anything extra with the groups that result from the sort. To accomplish this we need to use custom XSLT and there is no simple syntax to write this type of XPath query in XSL 1.0.
When grouping nodes, we also think in sort things to get them into a certain order, then we group all items that have the same value for the sort key (or keys). We'll use xsl:sort for this grouping, then use variables or functions like key() or generate-id() to finish the job.
Using preceding-sibling expression
The preceding-sibling axis contains all the preceding siblings of the context node; if the context node is an attribute node or namespace node, the preceding-sibling axis is empty.
Basically, the expression checks the value of every preceding-sibling and returns True when none of the preceding-sibling elements have the same value that we are validating or False otherwise. This expression is used in conjunction with xsl:for-each element.
The xsl:for-each element will loop through the first occurrence of each unique grouping value and the preceding-sibling expression will validate the previous existence, emulating this way the existence of a list of unique values.
The following is a list of resources that explain how to accomplish this:
This algorithm is not efficient for large messages, but work well for ‘normal’ messages. For large messages Muenchian method is generally more efficient than using preceding-sibling.
The trouble with this method is that it involves two XPaths that take a lot of processing for big XML sources. Searching through all the preceding siblings with the 'preceding-siblings' axis takes a long time if you're near the end of the records. Similarly, getting all the elements with a certain value involves looking at every single element each time. This makes it very inefficient.
Using the Muenchian method
Oracle's lead XML Technical Evangelist Steve Muench developed an approach for performing the previous functions in a more efficient way using keys (xsl:key element), and this became so popular that it's known as the "Muenchian Method." Keys work by assigning a key value to a node and giving you easy access to that node through the key value. If there are lots of nodes that have the same key value, then all those nodes are retrieved when you use that key value. Effectively, this means that if you want to group a set of nodes according to a particular property of the node, then you can use keys to group them together..
You can find a really fine explanation by Jeni Tennison here: Grouping Using the Muenchian Method
How to use the Muenchian Method in your BizTalk Transformations
There is an astonishing post by Chris Romp about Muenchian Grouping and Sorting in BizTalk Maps, which was possibly one of the first approach to use this technique in BizTalk Maps... but first, let's put the problem in context:
Note: The solutions that I will explain are based on Chris Romp sample, so I will explain the requirements and put part of the Chris Romp here.
Let's say we have an input schema that contains the sales order information. However, for each line, we repeat the sales header info (in this case it's just "OrderID," but typically this would include customer info, order date, etc.) again and again:
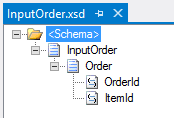
However, in our destination schema, we want to group the line data for each header, and we want to sort it, too. Here's the destination schema we need to use.

For accomplished this requirements, we have two solutions:
- Using an external custom XLS file (Chris Romp solution)
- Or try to implement Muenchian Method inside the Mapper (my solution) without losing BizTalk Mapper functionalities.
Using an external custom XLS file
I will not reproduce the entire content of the Chris Romp post, because you can read the entire post here: Muenchian Grouping and Sorting in BizTalk Maps, but basically you need to:
- Create a new BizTalk map, and then steal its XSLT to use as a template. This way we know the namespaces and such are correct.
- Right-click on the map and choose "Validate," then steal the output ".xsl" file.
- Then click on the functoid grid on the graphical map, and set the Custom XSL Path property to your saved .xsl file.

Within the custom XSLT, we're going to be implementing the Muenchian Method technique to solve this problem.
Just below the <xsl:output> block of our XSLT, we're going to create a key value for this grouping. This creates an index, which the transform engine can use to loop through each unique value of that key.
<xsl:key name="groups" match="Order" use="OrderID"/>
From there, at the top of where we're going to start our /Orders branch, we can modify the "for-each" block to loop through our key instead of source nodes, like we might typically do.
<xsl:for-each select="Order[generate-id(.)=generate-id(key('groups',OrderID))]">
If we want to apply sorting, we can add:
<xsl:sort select="OrderID" order="ascending"/>
Finally we loop through the "groups" key we created before and output our data:
<xsl:for-each select="key('groups',OrderID)">
The custom XSLT will look something like this:
<ns0:orders>
<xsl:key name="groups" match="Order" use="OrderId"/>
<!-- This will loop through our key ("OrderId") -->
<xsl:for-each select="Order[generate-id(.)=generate-id(key('groups',OrderId))]">
<!-- And let's do some sorting for good measure... -->
<xsl:sort select="OrderId" order="ascending"/>
<Order>
<OrderId><xsl:value-of select="OrderId/text()" /></OrderId>
<Items>
<!-- Another loop... -->
<xsl:for-each select="key('groups',OrderId)">
<ItemId><xsl:value-of select="ItemId" /></ItemId>
</xsl:for-each>
</Items>
</Order>
</xsl:for-each>
</ns0:orders>
However, this approach has one huge limitation, by creating and configures Custom XSL Path we lose all mapping features.
So how can we use Muenchian Grouping without losing Map features?
Muenchian Method inside the Mapper (my solution) without losing BizTalk Mapper functionalities
First approach
My First approach: Was try to put an Inline XSLT functoid and put all the XSL inside:
- Drag-and-drop a Scripting Functoid to the map without any input and link this functoid to the Order record on the destination schema.

Double-click in the Scripting Functoid, select the "Scripting Functoid Configuration" tab
Select the script type as: Inline XSLT and past the following code to the Inline script window.
<xsl:key name="groups" match="Order" use="OrderId"/> <!-- This will loop through our key ("OrderId") --> <xsl:for-each select="Order[generate-id(.)=generate-id(key('groups',OrderId))]"> <!-- And let's do some sorting for good measure... --> <xsl:sort select="OrderId" order="ascending"/> <Order> <OrderId><xsl:value-of select="OrderId/text()" /></OrderId> <Items> <!-- Another loop... --> <xsl:for-each select="key('groups',OrderId)"> <ItemId><xsl:value-of select="ItemId" /></ItemId> </xsl:for-each> </Items> </Order> </xsl:for-each>
The problem with that approach is that gives an error:
- XSLT compile error at (9,8). See InnerException for details. ‘xsl:key’ cannot be a child of the ‘ns0:OutputOrder’ element.
So, to avoid this error we need to separate “<xsl:key name=”groups” match=”Order” use=”OrderId”/>” expression from the rest of the XSL (see second approach)
Second Approach
The second approach: Was to try to separate “<xsl:key name=”groups” match=”Order” use=”OrderId”/>” expression from the rest of the XSL so that we can use this technique inside the BizTalk Mapper and avoid this way to use an external custom XSL file. To accomplish that we need to:
- Add two Scripting Functoids to the map
- The first Scripting Functoid will not have any kind of inputs or output and will serve to create the concept of a global variable, in this case a key that assigns each Order a key value that is the OrderId given in the record.
In the first, configure to an “Inline XSLT Call Template” and put key expression.
<xsl:key name="groups" match="Order" use="OrderId"/>
- The second Scripting Functoid will not have any kind of inputs and link this functoid to the Order record on the destination schema
In the second Scripting Functoid, configure to an “Inline XSLT” and the rest of the XSL.
<!-- This will loop through our key ("OrderId") --> <xsl:for-each select="Order[generate-id(.)=generate-id(key('groups',OrderId))]"> <!-- And let's do some sorting for good measure... --> <xsl:sort select="OrderId" order="ascending"/> <Order> <OrderId><xsl:value-of select="OrderId/text()" /></OrderId> <Items> <!-- Another loop... --> <xsl:for-each select="key('groups',OrderId)"> <ItemId><xsl:value-of select="ItemId" /></ItemId> </xsl:for-each> </Items> </Order> </xsl:for-each>

If we test the map with the following input file:
<ns0:InputOrder xmlns:ns0="http://MuenchianGrouping.InputOrder">
<Order>
<OrderId>1</OrderId>
<ItemId>1001</ItemId>
</Order>
<Order>
<OrderId>1</OrderId>
<ItemId>1002</ItemId>
</Order>
<Order>
<OrderId>1</OrderId>
<ItemId>1003</ItemId>
</Order>
<Order>
<OrderId>2</OrderId>
<ItemId>1001</ItemId>
</Order>
<Order>
<OrderId>3</OrderId>
<ItemId>1000</ItemId>
</Order>
</ns0:InputOrder>
We will see the desired final output, but this time implemented inside the BizTalk Mapper without losing any Mapper functionality:
<ns0:OutputOrder xmlns:ns0="http://MuenchianGrouping.OutputOrder">
<Order>
<OrderId>1</OrderId>
<Items>
<ItemId>1001</ItemId>
<ItemId>1002</ItemId>
<ItemId>1003</ItemId>
</Items>
</Order>
<Order>
<OrderId>2</OrderId>
<Items>
<ItemId>1001</ItemId>
</Items>
</Order>
<Order>
<OrderId>3</OrderId>
<Items>
<ItemId>1000</ItemId>
</Items>
</Order>
</ns0:OutputOrder>
But can we improve (a little more) this solution? (See final approach)
Final Approach
When leading with large files, speed processing is vital. The classical Muenchian grouping use generate-id(), however,using generate-id() is slowest that using count() function, and shows worst scalability. Probably the reason is poor generate-id() function implementation. In other words, count() function performs is much better.
Here some performance stats that I found in Oleg Tkachenko's blog post:
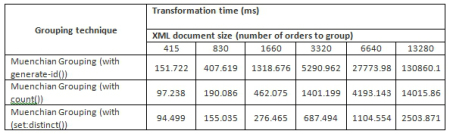
The graph view works better:
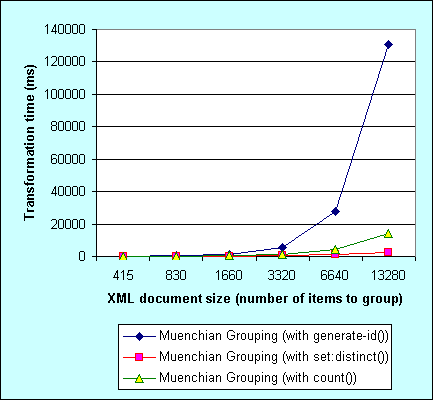
So to improve Muenchian a little more we have to use count() function instead of generate-id():
Go to the second Scripting Functoid and change the foreach statement to use this new syntax:
<xsl:for-each select="Order[count(. | key('groups',OrderId)[1]) = 1]">
Conclusion
Both, Chris Romp and mine (of course mine was inspired by Chris Romp solution), are great solutions and both can be implemented in different scenarios. However, and this is my personal opinion, I try to avoid using external XSL files. Even if using custom-XSLT will have much better performance because it’s clean code without junky XSLT code produce by the compiler, I only recommend do the all map problem with only custom-XSLT if you are dealing with huge message and High Performance is our or one of the primary requirements, for me this is the only exception to the rule, otherwise you should use the BizTalk Mapper and have a mix of Custom-XSLT and functoids, why?
- Maintainability and Readability: I don’t agree that very large transformations can be difficult to read and maintain in BizTalk Mapper because you can also because we can also use a custom XSLT to solve and simplify more elaborate and complex rules, and again in this case we have the best of both worlds. And they can be really easy to read and understand if you apply some of the best practices in organization and documentation inside maps.
- Level of effort:
- For a new BizTalk developer to troubleshoot and/or change an existing map it will more easy to do using BizTalk Mapper rather than troubleshoot and/or change and entire custom-XSLT file without a visual representation.
- Also, when working with developers from other teams of business users the visual aspect can make it easy to work with them to develop the mappings
- Overview. If a new BizTalk developer opens up a map and see only a blank page without any functoid, he will probably think that someone forgot to check in the latest version in the source safe or simply forgot to implement this map! And after some hours he will understand that there is defined in properties of the map an external file with all your transformation rules. Really annoying!
Code Samples
All of this sample can be found and downloaded in Microsoft Code Gallery:
And Chris Romp's SkyDrive:
See Also
Read suggested related topics:
- BizTalk Server: BizTalk Mapper Patterns
- Muenchian Grouping and Sorting in BizTalk Maps
- BizTalk Training – Mapping – Muenchian Grouping and Sorting in BizTalk Maps without losing Map functionalities
- BizTalk Training – Mapping – How to implement multi-level Muenchian grouping in BizTalk Maps
- How to speed up Muenchian grouping in .NET
Another important place to find a huge amount of BizTalk related articles is the TechNet Wiki itself. The best entry point is BizTalk Server Resources on the TechNet Wiki.