SQL Server 2012 Database Partitioning
Introduction
Partition is a division or grouping of data by rows. Table partitioning has been around since
SQL Server 2005. For more information about table partition please see this TechNet link.
This case study aims to showcase some of the partitioning enhancements in SQL Server 2012.
Real World Scenario
You are a database administrator for 'Crosswind'. Crosswind operates globally in more than 78
countries around the world. You are in charge of maintaining the customer master reference table
of the company.
As a member of Crosswind business intelligence team, you are assigned to partition the
Customer master table using the following fields: Region, Country, 'Isactive'. Region refers to
EMEA, APAC, SEA. 'Country' refers to countries in the region and 'Isactive' field refers
to whether the customer is active or not.
Functionally 'Customer' table will act as a master reference table and
will be replicated as a whole to the entire company around the world
and to any of Crosswind corporate partner.
The rationale behind the three composite fields partitioning are as follows:
- Regional data should stay together for regional replication.
- Country data should stay at least adjacent to each other for country's
delivery center replication. - Non-active data will contain historical changes and will be barely used by the system.
- Partition metadata will be used for metrics purposes.
5. Insert, update and delete shall be contained in the country's two partitions
Data governance has been put in place and data will be reviewed prior to being loaded into
the customer dimension.
Spoiler
Table Partitioning supports only one column and you are required to partition into three columns.
A new partitioning wizard is introduced in SQL Server 2012. You cannot use partition switching
if you have a 'misaligned' index.
Follow The Sun
The sun sets in every country at different times around the globe. At sundown on every delivery
center, delivery reports have to be built. Crosswind will build their customer data prior to
report generation.
Step by Step Procedure on How to Implement Partitioning for this Case study
Here's a high-level approach to the problem at hand.
1. You can only create a partition in one column. However, to implement partitioning with the same effect you can build a calculated column
2. Create partition function.
3. Create partition scheme.
Create Partition Function
Let's create a partition function using this script:
CREATE PARTITION FUNCTION customer_partfunc (Varchar(20))
AS RANGE LEFT
FOR VALUES (
'APAC-USA-1',
'APAC-USA-0',
'EMEA-GERMANY-1',
'EMEA-GERMANY-0')
Create Partition Scheme using this Script
Let's create partition Scheme using this script:
CREATE PARTITION SCHEME customer_partscheme
AS PARTITION customer_partfunc
TO ([PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY],[PRIMARY] )
Create the Customer Table
Let's Create the table using this script:
CREATE TABLE [dbo].[DimCustomer](
[CustomerKey] [int] NOT NULL,
[Companyname] [varchar](50) NULL,
[country] [varchar](10) NULL,
[region] [varchar](10) NULL,
[isactive] [bit] NULL,
[partitionKey] [varchar](20) NULL, -- simulate calculated column for now
CONSTRAINT [PK_dimCustomer] PRIMARY KEY clustered
(
[CustomerKey] ASC
) ON [PRIMARY]
)
Configure the Partition Using the Partition Wizard.
Let's use the partition wizard to configure the partition. Partition Wizard is a new feature
for partitioning in SQL Server 2012.
Right-click the table and go to storage.
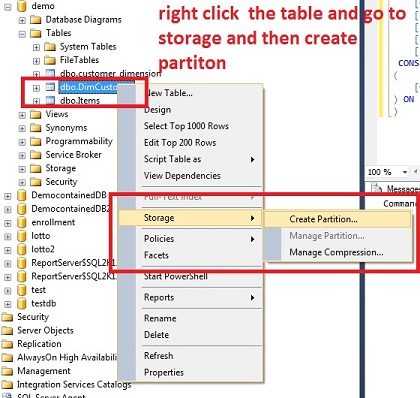
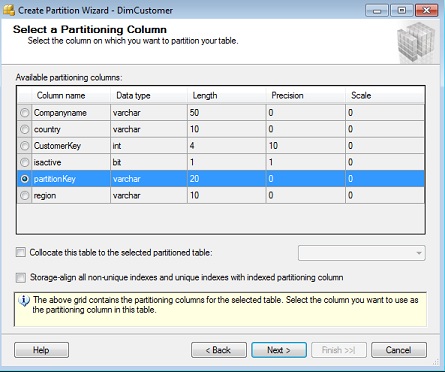
Choose the Partition Column
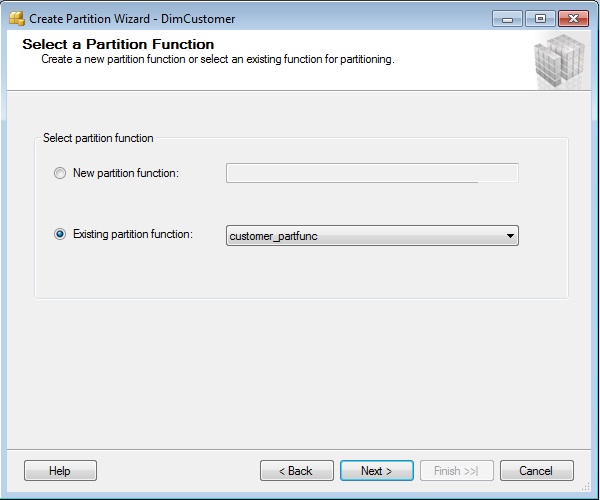
Choose the Existing Partition Function
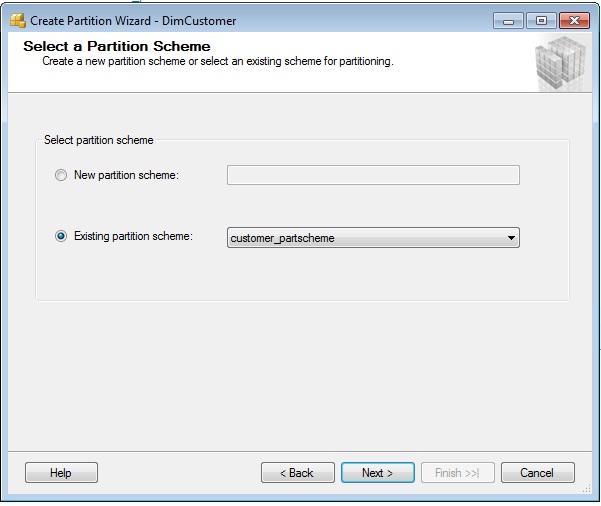
Choose the existing partition scheme
Map the partition to file groups.
File groups are used to strategize storage. Basically you can store each partition into different file groups which is basically the driving reason for partitioning. However this case study is not intended for file group management and scalability. We wrote this article to exploit other possible use of partition other than the normal mapping to file groups.
We will not do anything here but notice that SQL Server 2012 has arranged partition key in ascending alphabetical order. We will not make use of filegroup mapping for now.
Please take note that partitioning values are range based rather than equal match based.
In this case study, however, we worked around that. This is an equal match partition and a humanly readable one.
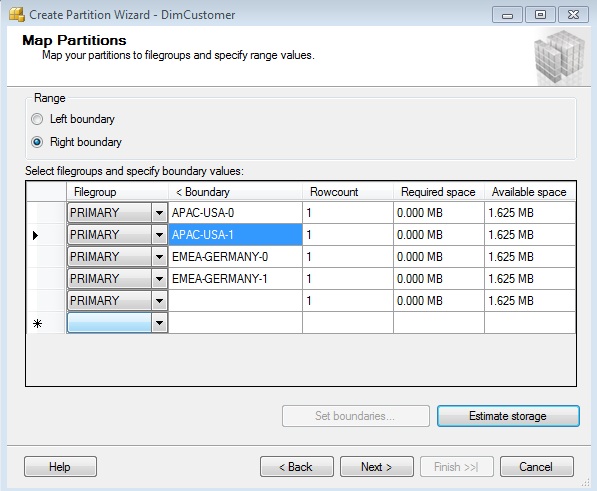
Click Next to apply the partition to the table using the wizard.
Create the Staging table
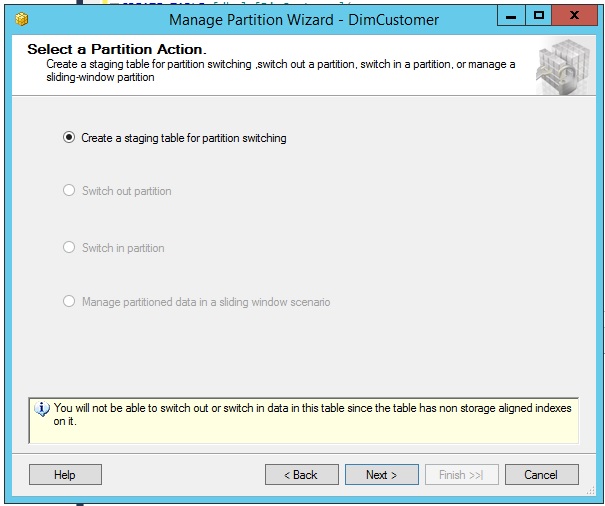
This is where things are going to be easy and you do want your boss to know about this. Build the staging tables using point and click in the partition wizard.
Run partition wizard to manage the partition
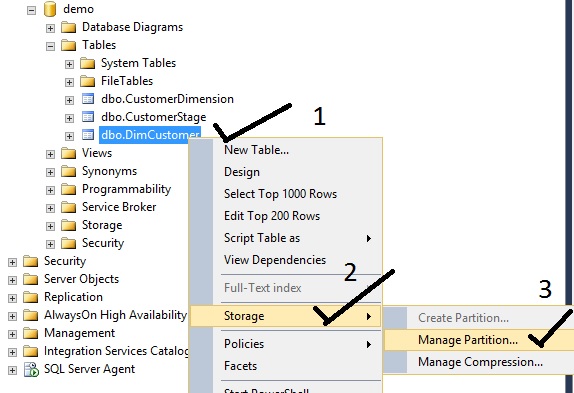
Create the staging table for the first partition
Supply the staging table name.
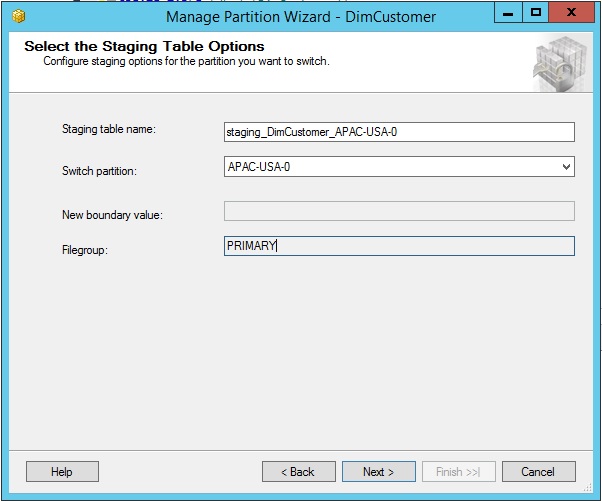
Click Next to create the staging table.
Examine the staging database
Notice that a partitioning check constraint is automatically created for you.

Supply the Sample data
The next step is to supply the sample data.

How do we load the data?
While this is a partition case study everybody expects to load the data using partition switching.
If we partition switch the country data that will basically do a customer refresh for that country.
To load the data we will basically insert if it is new and update if it is existing. or much easier enough
we will merge the data from the 'partition stage' into the partition using the 'customerkey'.
What index shall we apply?
We will need to apply a clustered index on the partition key.
Credits
Maulyn de Guzman - For offline editing
People who participated in the discussion threads
References:
Create Partitioned Tables and Indexes
Partitioned Tables and Indexes