Understanding Azure Tables comparing with Relational SQL Tables (on-premise/SQL Azure)
Background
Windows Azure Storage is a storage option provide by Windows Azure. Using this technology will bring all the benefits of Windows Azure such as High Availability, Scalability, Security, etc. Azure tables were specially designed to store non-relational data that needs some structure, but highly scalable. All the values of Azure tables are stored as Key-Value pairs which makes it a highly scalable storage option.
When someone starts to learn about windows azure table storage, the first thing that will come to his mind will be “Why do we need this when we have Sophisticated Relational SQL Server Tables?”
Therefore, the best way to understand about Windows Azure Tables will be, start thinking about a relational SQL table and learn the differences.
A comparison of Relational SQL Table and Azure Storage Table
Relation SQL table |
Azure Storage table |
Can have Relationships between tables |
There are no relationships between tables. Follows NoSQL Concepts |
Has Rows of values |
Considered as Entities |
Strictly defined Columns & enforces data integrity |
There is no Concept of Columns, instead values are stored as key-value pairs |
Each row has fixed amount of columns |
Each entity can have Zero or more properties |
Each data/value will have a data type which corresponds to the column definition |
Each data/value are independent & can have different data types |
No build-in System columns |
3 System properties for each entity (PartitionKey, RowKey, Timestamp) |
Merging data from multiple sources that has different formats – may need to be converted programatically |
Have the option of saving data in a different formats. Example: Source 1: 01/01/2001 Source 2: “2001” (only the year as a String) |
Ability to Query – TSQL |
Limited Query options |
Can apply indexes to any column |
Can’t do that. Is only available for PartitionKey & RowKey built-in |
Geographically redundant price (as of 2014-Mar-09) - $9.99 upto 1 GB per Month |
Cheaper - $0.095 per GB per Month |
When comparing only on-premise SQL |
More Availability |
SQL Azure Max Capacity (as of 2014-Mar-09) – 150 GB |
200 TB |
**
**
Azure Storage Table Concept
**

**
In an Azure storage table a collection of Properties (key-values pairs) will form an Entity. Those entities will be meaningfully grouped in to partitions using PartitionKeys. Ultimately, the collection of entities that were grouped in to partitions will form the Azure Storage Table.
Understanding Entity
An entity has 3 system properties:
- PartitionKey – means of partitioning entities for load balancing with the rule of thumb “Data that need to be Queried together, must be kept together”
- RowKey – This is a key that helps to uniquely identify an entity that belongs to a partition. So, RowKey together with PartitionKey will make an Entity unique in a given azure table.
- TimeStamp – When you first create an entity, the Date & Time of creation will be recorded in this property. And later if you do any change to that entity, the value will get updated with the last updated date & time.
Those system properties are built-in indexed and it is recommended to use these properties as identity columns so it is efficient. Non-system values can not be indexed.
The paritionKey together with RowKey will form unique entities:** **
**  **
**
** **
**
**
Understanding Properties by example
Example 1: No fixed Schema for storing values
In a relation SQL table all those values that is entered under column “Age” will be bound to the limitations defined in the column definition/design such as Data type, maximum length, unique key, etc.

Now lets try to store those values in an Azure Storage Table. Now, those values are not bound to a particular column. (there is no concept of columns)
Each and every values are stored as key-value pairs. Unlike in relational SQL tables, those values can be of different data types as well.

This design has enable some new scenarios that were not possible before.
For example, lets say we store date values in relational SQL table we have to store them in a standard format. But in SQL Azure table, we can store the date as string for some entities if needed.
Example 2:
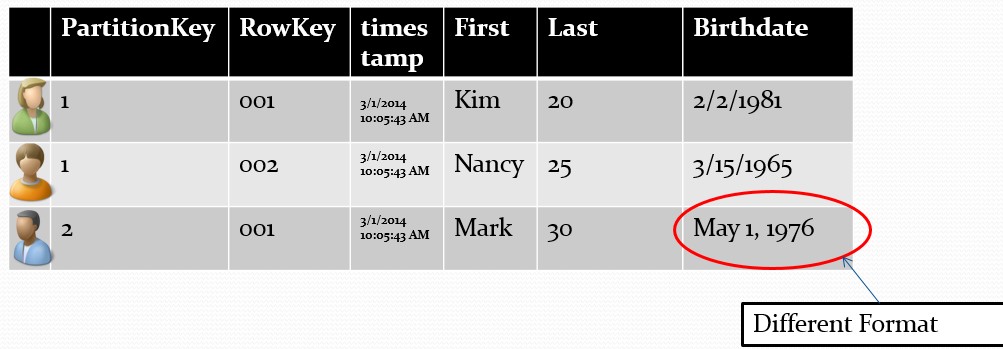
There is a requirement to create a simple consolidated search engine of products that are referred from two different eCommerce stores. Store 1 stores Product Expiry Dates as DateTime data type (1900-01-01 00:00:00) . On the other hand, Store 2 stores only Year and Month, but as Strings (“1900/June”). If we are doing this using relational SQL, we will have to assume a default date for Store 2 (may be logically incorrect according to the product type) and programatically convert each and every date stored either as a separate column or do it when querying. But, we can push products from both the stores to Azure tables without any of these effort. (Store 1 values stored as DateTime, Store 2 values stored as String)
Moreover, if we take a particular entity, it can have Zero or more properties.
Example 3:

In the above example,
- First entity will have Zero properties
- Third entity will have 3 properties (“First”,”Last”,”Birthdate”)
- Second entity will have 4 properties (“First”,”Last”,”Birthdate”, “Sport”); the property “Sport” only belongs to the second entity and will not be applicable for other entities unless other entities have explicitly defined a property with the same name.
- PartitionKey together with RowKey will form unique entity in Azure storage table. Although first & second entities have the RowKey “001” since they have different ParitionKeys they will be unique inside the table.
Properties supports following data types:
- Binary
- Bool
- DateTime
- Double
- GUID
- Int32
- Int64
- String
Partitions
Azure storage tables are partitioned by the system property called “PartitionKey”.
Entities that were partitioned with the same paritionKey will belong to the same load balancing group. On other words, anything within the same partition will live in the same server (same storage machine), so they can be queried/accessed faster.
So, as a rule of thumb when we design for Azure Storage tables we need to remember that “Data that need to be queried together, must be kept together in the same partition”.
Since, we can not index non-system properties, the key idea of azure table is that design it in a way so that we make use of the concept of partitioning for load balancing. So, the art of choosing how to partition entities will depend on the requirements, transactions, and mainly on what kind of Queries that we are going to use on the azure table.
Following are some examples of how developers have used azure tables and how they have partitioned according to different requirements:

In this part of the table, we can we the entities have been partitioned using their document name.
the different versions of the same document are stored using different RowKeys.
In this case, all the versions of a particular document will be stored together. So, retrieving the versions of the same document will be very fast.

As you can see ParitionKey or RowKey doesn't have to be a GUID or Integer they can be any data type. In the following example, Name is considered as the RowKey.
Following is a good example that describes how independent that values are stored for each entity as properties.

Key things to remember
In summary, when we design for azure storage tables with the concept of partitions, following are some key concerns:
- First of all, Know what you cannot do with Azure storage tables. It is not a replace for relational SQL tables. It can either reside independently or it can work together with relational SQL tables to form a system that stores data. The later case is the obvious.
- Know what are the transactions. It is important to know what are the entities that are going to be updated together.
- Know your Queries. It is important to know what are the entities that are going to be queried/accessed together.
- Therefore, depending on the above concerns, we have to partition data.
- Sometimes, if we design our tables to server some key queries, it may not possibly cater some other queries, which we will have to look for workarounds. In Relational SQL we have really good guides and best practices. In contrast, there is less direct guidance on designing such NoSQL based tables. So, its more of an Art!