SSIS : Importing FlatFiles with Varying Number of Columns Across Rows
Business Case
The core idea of this article traces back to a scenario which was faced in one of our recent projects.
We had a requirement for a system which could process incoming flat files. The metadata of the files will be fixed. All sounded straightforward until the last part.The file was generated by a automated process so it was not certain what will be the maximum number of columns. A good majority of the columns were optional so not many rows had any value. This made it difficult to set the mappings at design time as the connection manager couldn't parse out a full list of columns. It was not easy to determine the maximum number of columns manually as files were huge.
This article explains how number of columns can be determined at design time and mappings can be set for a file with varying number of columns across rows.
Illustration
Consider a sample file with data as below
123,Test,data
345,row2,data2,test2
554,row3,data3
788,row4,data4,with,all,columnvalues
655,row5,data5,with2,column2
If you analyze this file carefully its rows are having unequal number of columns. To make illustration simpler I've just given a file with 6 columns maximum but in the actual case file had much more columns.
If you try to use this file as a source inside a data flow task and use a standard connection manager it will parse the file data as below
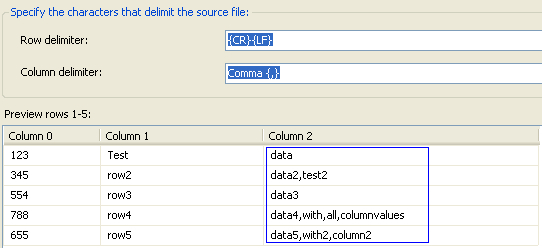
Notice the highlighted portion. You can see that the connection manager interprets the columns based on delimiters present in first row ie in the example as 3 columns with 3rd column containing values of rest of columns merged together. However the sample file actually has a maximum number of 6 columns with the 3rd row containing values for all the columns.
The challenge is how to make flatfile connection manager interpret the column values correctly.
This can be handled using two approaches which we can see in detail below
Approach 1: Using a Staging Table and Doing T-SQL String Parsing
This is the easier approach if you have the rights to create and can afford a staging table. The steps involved will be the below
Create a data flow task with flat file source and OLEDB destination tasks.
The flat file connection manager would be configured with row delimiter as {CR}{LF} and no column delimiter. This would make sure it returns the entire row contents of the file as a single column as shown below.
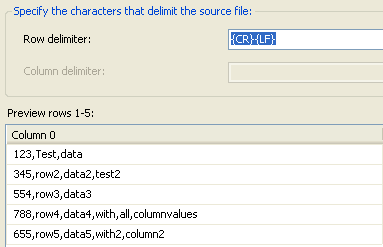
This is then used to populate the staging table.
Once staging table is populated you can use a procedure which will parse the rows, get the column information from them and populate the destination table with the data. The procedure logic would be as below
CREATE PROC ParseVaryingColumnFileData
AS
DECLARE @MaxRows int
SELECT @MaxRows = MAX(LEN([Column 0]) - LEN(REPLACE([Column 0],',','')))
FROM dbo.StagingTableVaryingCol
DECLARE @ColList varchar(8000)
;With Number(N)
AS
(
SELECT 1
UNION ALL
SELECT 1
UNION ALL
SELECT 1
),Num_Matrix(Seq)
AS
(
SELECT ROW_NUMBER() OVER(ORDER BY (SELECT 1))
FROM Number n1
CROSS JOIN Number n2
CROSS JOIN Number n3
CROSS JOIN Number n4
CROSS JOIN Number n5
)
SELECT @ColList = STUFF((SELECT ',[' + CAST(Seq AS varchar(10)) + ']' FROM Num_Matrix WHERE Seq <=@MaxRows FOR XML PATH('')),1,1,'')
DECLARE @SQL varchar(max)='INSERT DestinationTable SELECT '+ @ColList + '
FROM
(
SELECT *
FROM dbo.StagingTableVaryingCol t
CROSS APPLY dbo.ParseValues(t.[Column 0],'','')f
)m
PIVOT(MAX(Val) FOR ID IN ('+ @ColList + '))P'
EXEC(@SQL)
GO
The procedure will parse out the values from column onto multiple columns using a string parsing UDF and then pivoting it dynamically based on the maximum number of columns present in the file. the UDF used for parsing (ParseValues) can be found in the below link
The full package will look like below
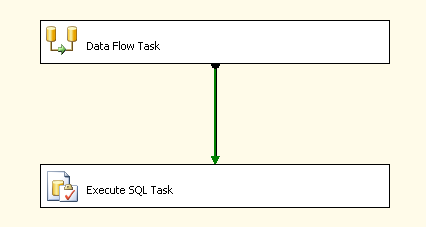
The tasks will include a data flow task to get file data transferred to a staging table with a single column followed by the execute sql task which will invoke the above procedure to parse the column values out from the staging table and insert in to the columns of your destination table
However one problem in implementing the above approach is that not always you will have the rights to create staging table as you may just be given access to do DML activities in the db.
Fortunately you can have an alternate approach without using a staging table
Approach 2: Using Data Flow Task to Fix Inconsistent Column Count and Parsing the File
This approach would involve using two data flow tasks. The first data flow task is intended to smooth out the file metadata issues by making column count consistent. The fixed file can then be easily parsed using another data flow task which will transfer the data to the destination table.
The first data flow task looks like this
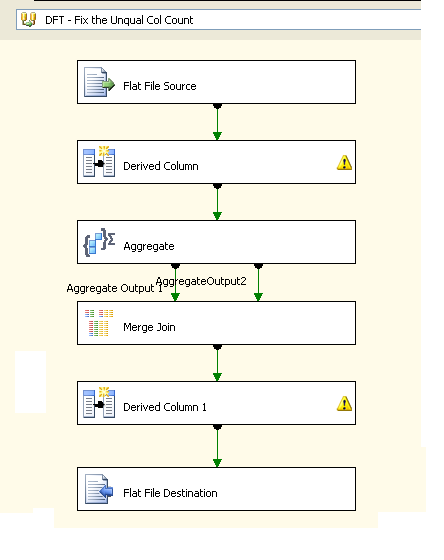
The data flow task will have the following components
Flat file source - For connecting to the source text file
Derived Column - This is for adding two additional columns one a dummy column which is used for simulating cross join and another one to calculate the number of columns in each row. This is done by calculating the number of delimiters present and adding 1 to it
Aggregate Transform - This is required for finding the maximum number of columns within the file. There's also a dummy grouping output created to get cross join the count value against each of the rows in the input file.
Merge Join - A merge join transform would used to do cross join simulated using an inner join operation on a dummy field. This will help us to return the maximum column count value along with each data row
Derived Column - This derived column task will pad the data rows with delimiter characters to make number of columns consistent and equal to the max column count returned by the aggregate transform. This will make it easier for the subsequent data flow task to parse the file out correctly identifying all the column values.
Flat File Destination - This will save the modified file for use by the second data flow task. The saved file will be having a consistent metadata including placeholders for all the missing columns.
The second data flow would be a starightforward one with Flat File source and OLEDB destination using the modified file as the source and your required destination table.
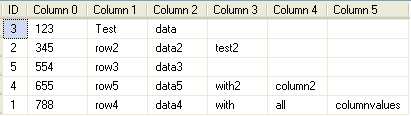
Once the package is successfully executed go and check the destination table and you'll find that all the data got correctly populated to the columns as shown below.
Summary
As shown by the approaches above, you will be able to handle cases where file metadata is inconsistent and load the data correctly to the tables. Based on the scenario you can go for approach 1 or 2.
Approach 1 has the advantage of doing the core steps inside relational database itself which would be better performing for large datasets. Usage of asynchronous transformations in SSIS like aggregate etc should be avoided when possible as it can cause performance bottleneck for large data. But wherever you have the restriction imposed due to security policies etc which prohibit you from creating staging tables you may go for approach 2.