Does SQL Server Backup Operation use Parallelism ?
Introduction
In this article we will investigate whether SQL Server backup operation can use Parallelism internally when executed. The question becomes even more interesting when you realise the query hint MAXDOP has no affect when used in a backup query.
Does this means SQL Server backup operation cannot use parallelism?
Let's explore this.
Note
This article uses Undocumented Trace flags 3213 and 3605. Undocumented means Microsoft(MS) does not support
these commands and also advises not to use this on production servers. You can use it under guidance of MS engineers.
The trace flags were used to show internal behavior of backup command. Please don't use this command on production databases.
Demystifying Whether Backup Uses Parallelism
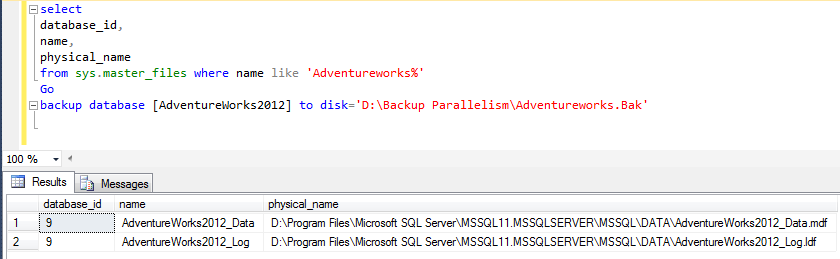
Let's try to take a backup of an adventure works database with a single data file and backup to a single drive. To gain further information about the backup process we can enable trace flags 3213 and 3605. The trace flag 3213 would give internal information about backup and 3605 will dump trace information into the errorlog.
select
database_id,
name,
physical_name
from sys.master_files where name like 'Adventureworks%'
Go
go
dbcc traceon(3213, 3605, -1)
GO
backup database [AdventureWorks2012] to
disk='D:\Backup Parallelism\Adventureworks.Bak'
 =
=
When you run backup, immediately run the below query in another query window. Yes, sys.sysprocesses was deliberately used to prove certain facts. Microsoft suggests using DMV sys.dm_exec_requests to see current executing sessions. Sys.dm_exec_requests only shows currently executing sessions
select
spid,
status,
cmd
from sys.sysprocesses where cmd='Backup Database'
Below is result from the query
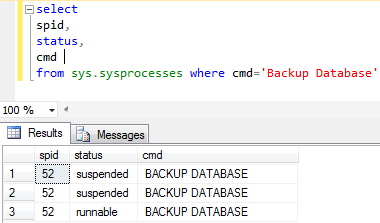
You can see 3 threads into picture one runnable and two suspended. So our backup operation initiated 3 threads.
Lets query errorlog using sp_readerrorlog because we used trace flag so few information related to backup would be dumped in errorlog.
Backup/Restore buffer configuration parameters
Memory limit: 249MB
BufferCount: 7
Sets Of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 7 MB
Tabular data device count: 1
Fulltext data device count: 0
Filestream device count: 0
TXF device count: 0
Filesystem i/o alignment: 512
Media Buffer count: 7
Media Buffer size: 1024KB
From this you can see the buffers and memory SQL Server used.
If you read this Blogs.msdn article it says when a backup starts it creates a series of buffers, allocated from the memory outside the buffer pool. The target is commonly 4MB for each buffer resulting in approximately 4 to 8 buffers. Details about the calculation are located in this support article
The buffers are transitioned between the free and data queues.
The reader pulls a free buffer, fills it with data and places it on the data queue.
The writer(s) pull filled data buffers from the data queue, process the buffer and return it to the free list.
You get a writer per backup device, each retrieving from the data queue.
In our backup operation one thread was reading data from disk and filling the buffers created. The number of threads initiated to read data would be equal to number of drives SQL Server has to read data from. Therefore there is one thread for one data file. For example if we have four data file on different disks there would be 4 threads reading it from disk and populating the buffer.
The second thread was reading data from buffers and writing it to disk. Again since we had only one disk one thread was initiated.
Lets do the same process but with another data file in the Adventure works database and back up to two drives. We will also enable Undocumented Trace flag 3605 to see what internally happens when SQL Server executes the backup
Backup/Restore buffer configuration parameters
Memory limit: 249MB
BufferCount: 14
Sets Of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 14 MB
Tabular data device count: 2
Fulltext data device count: 0
Filestream device count: 0
TXF device count: 0
Filesystem i/o alignment: 512
Media Buffer count: 14
Media Buffer size: 1024KB

As we can see one more thread appeared in Sys.sysprocesses output so we can see that now threads are initiated as per disk drives from where SQL Server has to read data.
Now lets remove the new added data file and create Multiple backup files and see how is the behavior.
dbcc traceon(3213, 3605, -1)
GO
backup database [AdventureWorks2012] to
disk='D:\Backup Parallelism\Adventureworks.Bak',
Disk='D:\Backup Parallelism\Adventureworks.Bak1',
Disk='D:\Backup Parallelism\Adventureworks.Bak2'
Below is output of sys.sysprocesses when backup was taken with multiple files.
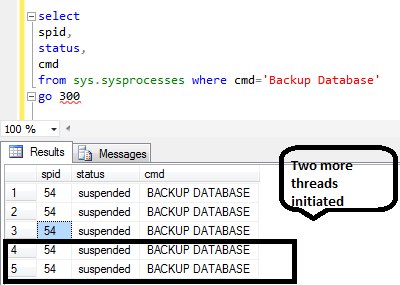
Its quite clear that SQL Server initiated TWO MORE threads for the two extra backup files we were creating. Please note all these backup files were getting dumped on the same D DRIVE.
This experiment proves that SQL Server initiated multiple threads. To be more accurate SQL Server initiated ONE THREAD PER BACKUP FILE to complete the backup operation so SQL Server does uses Parallelism.
You may well be thinking this is all very well but how does this work. IS QUERY PARALLELISM or Multiple threads(parallelism) used?
Let's see what the errorlog has to say about this backup operation.
Memory limit: 249MB
BufferCount: 17
Sets Of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 17 MB
Tabular data device count: 1
Fulltext data device count: 0
Filestream device count: 0
TXF device count: 0
Filesystem i/o alignment: 512
Media Buffer count: 17
Media Buffer size: 1024KB
You can see the difference in Media buffer count and Total buffer space (as compared to previous output).
Now lets add a data file to adventure works database but the location of new file would be on C drive. Currently both data and log files are on D drive. After adding we will take backup with multiple backup files some placed on D drive and some on C drive. This is just to show how many threads are created when you have multiple data file and multiple backup files
Execute below query
dbcc traceon(3213, 3605, -1)
GO
backup database [AdventureWorks2012] to
disk='D:\Backup Parallelism\Adventureworks.Bak',
Disk='D:\Backup Parallelism\Adventureworks.Bak1',
Disk='C:\Backup Paralleism\Adventureworks.Bak2',
Disk='C:\Backup Paralleism\Adventureworks.Bak3'
Below is the result of sys.sysprocesses query

We can see that there are 6 threads created all together. Four for the 4 backups files we created and two for reading data files from different disk. Lets see what errorlog has to say
Memory limit: 249MB
BufferCount: 22
Sets Of Buffers: 1
MaxTransferSize: 1024 KB
Min MaxTransferSize: 64 KB
Total buffer space: 22 MB
Tabular data device count: 1
Fulltext data device count: 0
Filestream device count: 0
TXF device count: 0
Filesystem i/o alignment: 512
Media Buffer count: 22
Media Buffer size: 1024KB
Above proves that Backup does creates multiple threads if it has to read from multiple files and write backup to multiple devices.
Now to prove whether backup uses query parallelism we would try to generated Query plan of a backup operation. To do that you need to select generated actual execution plan in SSMS. But you would notice no plan would be generated.
No plan is generated because no Operators, like seek,scan,join, etc are involved. Its very important to note that Parallelism is not for Query but for the operators involved in the query since we have no operators in backup operation SQL Server in any case would not use parallelism in case of backup.
It should also be noted that backup involves reading data from some disks and writing it on some disk so actually query does not have to go phase of generating a query plan out of many possible plan. The query plan will always be trivial.
Does MAX Degree Of Parallelism Affects Backup
Max degree of parallelism does not affects backup in any way. One can try to disable parallelism by following method
sp_configure 'show advanced options',1
go
reconfigure
go
sp_configure 'max degree of parallelism',1
go
Now lest run query and see output from sys.sysprocesses

Now we can see that even when parallelism is disabled backup spawned multiple threads. So backup operation does not involves query parallelism. Maxdop only affects queries that are driven by the query execution portion of the query processor.
Conclusion
Backup and restore operation uses PARALLELISM only when you have files on multiple drives/ mount point. Backup Operation DOES NOT USES PARALLEISM which is governed by SQL Server optimizer.
If database files are on multiple disks backup operation would initiate on thread per device drive to read the data. In same way if restore is done on multiple drives/mount points backup operation would initiate one thread per drive/mount point
Even if you are dumping multiple copies of backup on same drive we would have one thread per backup file
The parallelism associated with backup is related to the stripes. Each stripe gets its own worker thread and that is really the only part of backup/restore that one should consider as parallel operations.